腾讯云+Ollama部署远程访问大模型api
Ollama是个极为方便的大模型框架
1.腾讯云上选购合适的云服务器,为了方便拉取模型,地区建议选择北美(计费模式选择按量计费是为了省钱,老板有钱的话随意)

架构选择异构计算
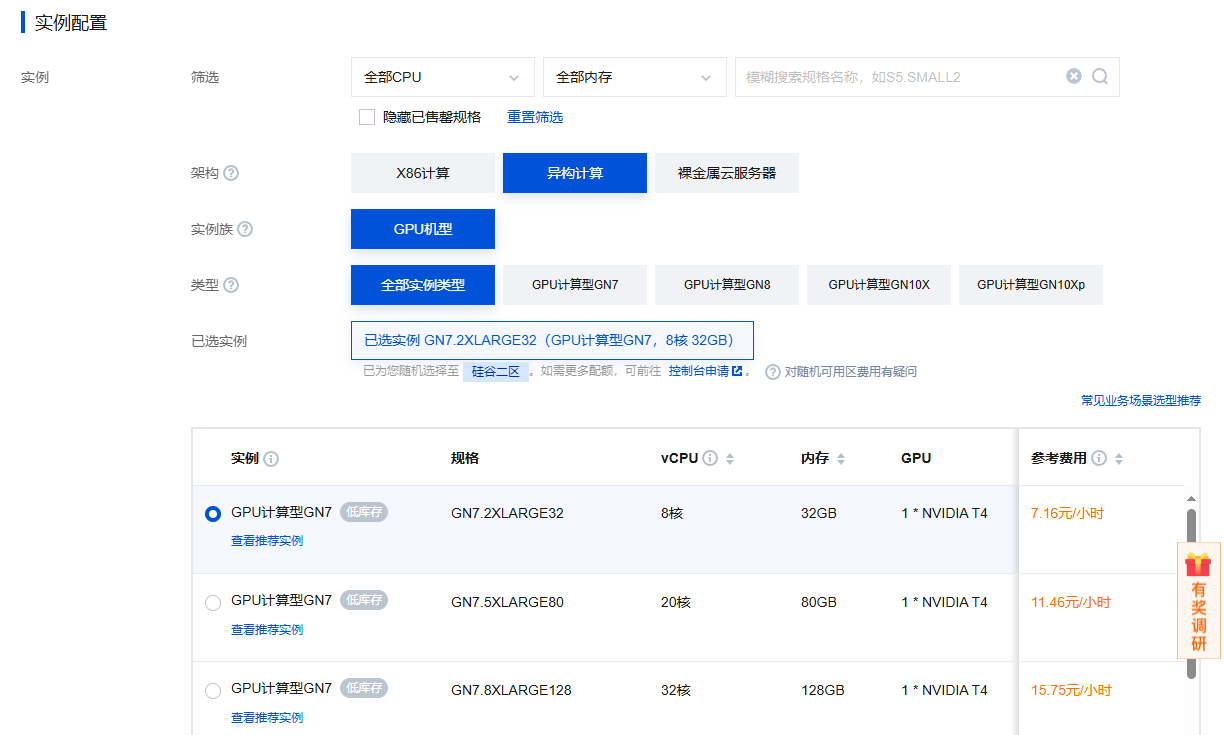
镜像选择Ubuntu22.04,驱动版本默认就行,云硬盘默认50G即可
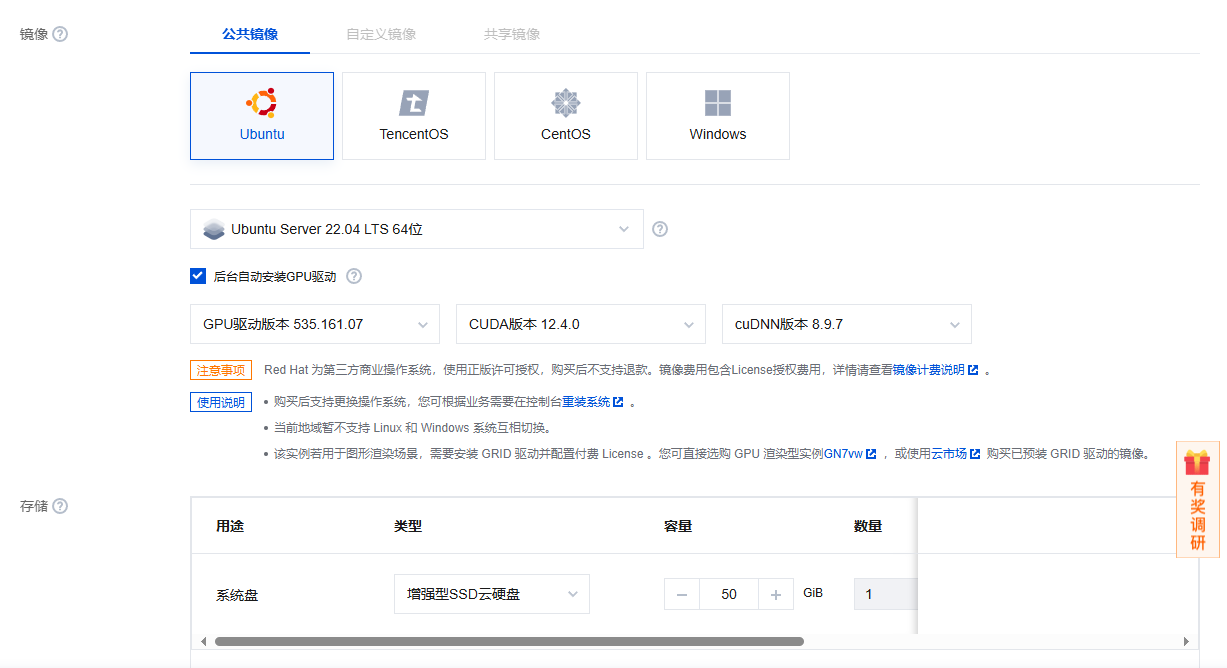
网络默认分配即可,一定要选择分配独立公网IP,否则无法远程访问
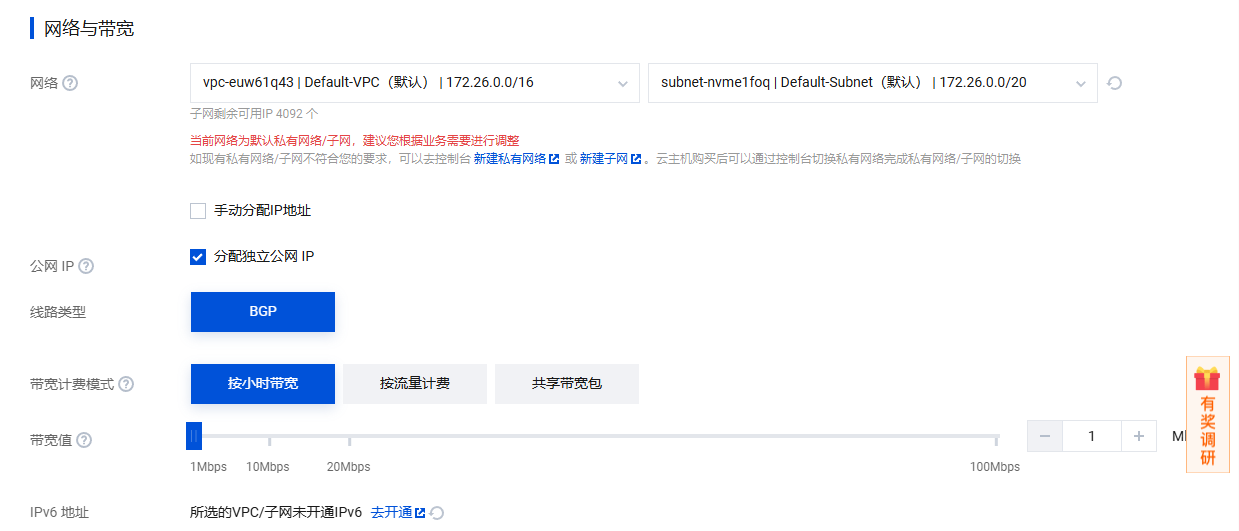
事前需要建立一个安全组,方便起见放通全部流量即可,在此处选择此安全组
选择完成后,等待服务部署完成.
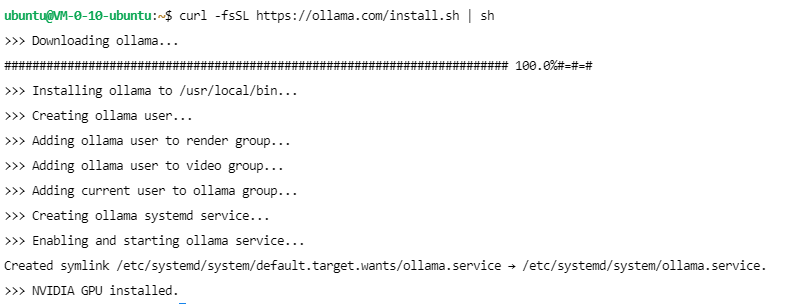
2.在云服务器界面登录进刚刚部署好的云服务器,等待安装显卡驱动的脚本自动执行完成后,使用如下脚本安装Ollama
curl -fsSL https://ollama.com/install.sh | sh

3.Ollama默认只监听本地11434端口,按如下方法更改设置令Ollama监听外部请求
sudo nano /etc/systemd/system/ollama.service

在Service下方(光标处)添加如下字段,
Environment="OLLAMA_HOST=0.0.0.0:11434"
按Ctrl+S保存,Ctrl+X退出
然后重新读取配置文件并重启Ollama服务
sudo systemctl daemon-reload
sudo systemctl restart ollama
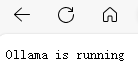
4.在本地使用浏览器访问服务器IP地址:11434,(服务器地址可在腾讯云后台查看,注意是公网地址),出现如下页面则表示Olamma启动成功
5.但此时只安装好了Olamma框架,还没有模型,需要按需拉取模型,此处以llama3为例

6.然后在本地编写代码向服务器以网络请求的方式与大模型会话
import requests
url = 'http://服务器公网IP地址:11434/api/chat'
data = {
"model": "llama3",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"stream": False
}
response = requests.post(url, json=data)
print(response.text){
"model":"llama3",
"created_at":"2024-06-17T06:33:07.6957739Z",
"message":{
"role":"assistant",
"content":"Hello! It's nice to meet you. Is there something I can help you with, or would you like to chat?"
},
"done_reason":"stop",
"done":true,
"total_duration":5919808133,
"load_duration":5114879071,
"prompt_eval_count":12,
"prompt_eval_duration":205646000,
"eval_count":26,
"eval_duration":557299000
}7.不需要时可在腾讯云后台将服务器关机以停止计费,节约费用
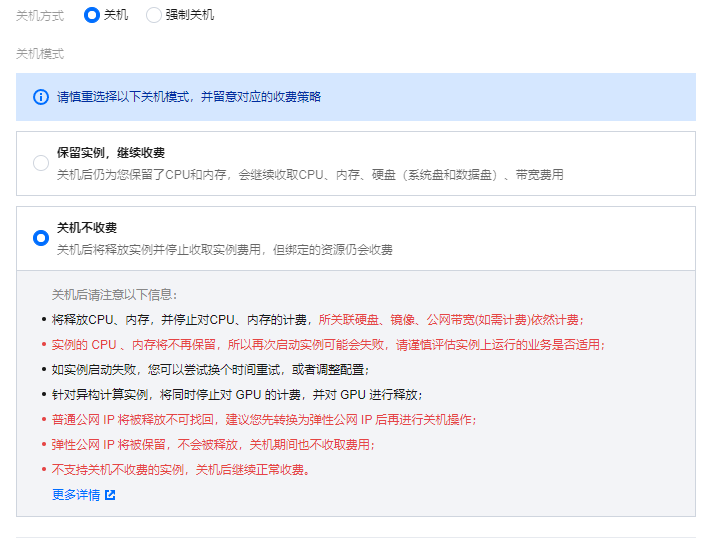
我买的硅谷的实例,配置都选的最便宜的,每小时7块多,关机后每小时2毛左右
主要参考资料:
解锁大模型的力量:我的本地部署到远程访问之旅 – WeiYoun
服务器部署开源大模型完整教程 Ollama+Gemma+open-webui - 哔哩哔哩 (bilibili.com)
Llama3本地部署及API接口本地调试,15分钟搞定最新Meta AI开源大模型本地Windows电脑部署_llama3 本地部署-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号