
pdfplumber提取pdf中的文字内容全都挤在一起,没有空格怎么办?
问题:
用如下的代码
import pdfplumber
pdfFile=r'pdf1.pdf'
outputFile='Extract'+pdfFile.split('.')[0]+'.txt'
with pdfplumber.open(pdfFile) as pdf:
with open(outputFile,'w',encoding='utf-8',buffering=1) as txt_file:
for page in pdf.pages:
text = page.extract_text()#提取文本
print(text)
txt_file.write(text)提取出来的文字输出之后是这样,怎么办?
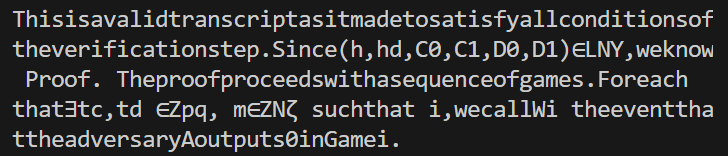
一句话回答:
调低x_tolerance参数(默认为3)
import pdfplumber
pdfFile=r'pdf1.pdf'
outputFile='Extract'+pdfFile.split('.')[0]+'.txt'
with pdfplumber.open(pdfFile) as pdf:
with open(outputFile,'w',encoding='utf-8',buffering=1) as txt_file:
for page in pdf.pages:
text = page.extract_text(x_tolerance=1)#提取文本
print(text)
txt_file.write(text)
参考资料:pdfplumber中文文档 https://github.com/hbh112233abc/pdfplumber/blob/stable/README-CN.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号