Python实践(1):使用爬虫将小说保存为txt文件
本文将介绍如何利用Python编写爬虫程序将想看的小说以txt格式保存到电脑上
涉及的知识:爬虫,html,正则表达式
本文将以《安娜·卡列尼娜》小说在线阅读_列夫·托尔斯泰 (sbkk8.com)这个网站为例,其他的网站代码格式略有不同,但爬取的思路类似
(1)找到想看的小说的章节选择页面,将该页面另存下来

(2)用文本编辑器打开下载的html文件,如果结构太乱难以阅读,可使用html格式化工具将html代码进行制表符缩进格式化,我常使用的是HTML格式化 、HTML压缩- 站长工具 (sojson.com)
(3)找到所有向小说正文页面跳转的链接,查看网页源代码并获得这些链接
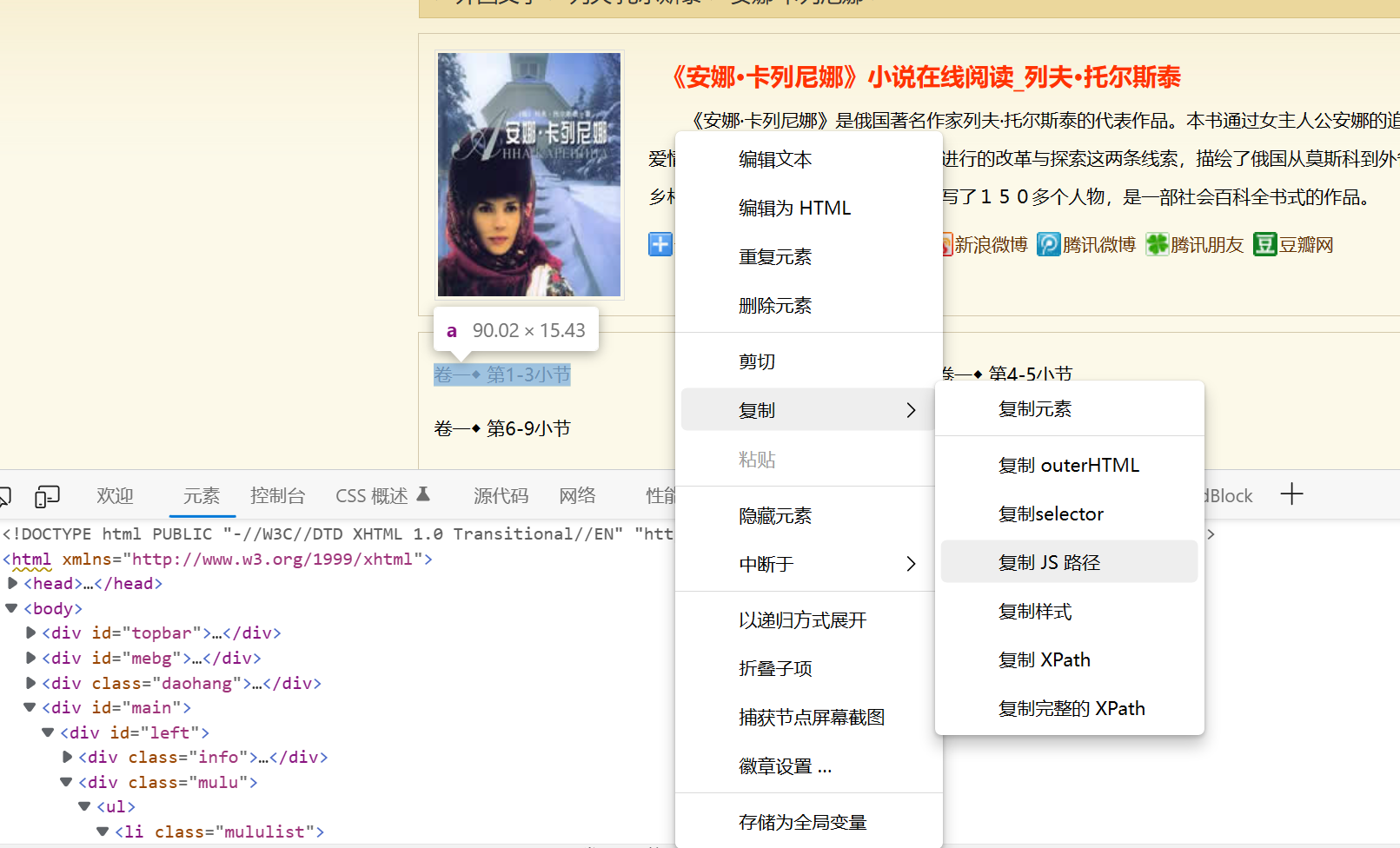
以Edge为例,在网页元素上右键单击,选择"检查",调出控制台,再右键单击想选取的html元素,选择"复制"->"复制JS路径",复制该元素的路径
进行网页的爬取,注意,这一步因为网页格式的不同需要多次调试,为了节约远端服务器响应资源,也为了防止自己的电脑因为访问过于频繁被远端服务器拉进黑名单,建议将网页下载到本地后调试
下列代码用于将目录页面中所有指向正文的网址提取出来
# !/usr/bin/python # -*-coding:utf-8-*- import requests from bs4 import BeautifulSoup def getContent(path): Encoding='gbk' # 设置相应的字符集,如果出现乱码,可尝试更换为utf-8 if(path[0:7]=="http://"): #从网络获取 response = requests.get(path) response.encoding = Encoding return response.text else: #从本地获取 return open(path,encoding=Encoding).read() # dist="http://book.sbkk8.com/waiguo/anna_kalienina/" dist="./《安娜·卡列尼娜》小说在线阅读_列夫·托尔斯泰.html" data = getContent(dist) soup = BeautifulSoup(data,"html.parser") f=open("urls.txt","w",buffering=1) for i in range(1,68): chapters=soup.select("#left > div.mulu > ul > li:nth-child("+str(i)+") > a") print(chapters[0].get('href')) f.write(chapters[0].get('href')+'\n')
导出的链接保存在urls.txt文件中
(4)爬取正文
依次读取urls.txt文件中存储的网址,并获取其文字内容,写入到文件中.
注意,网址要过滤掉行末的回车,否则会404
# !/usr/bin/python # -*-coding:utf-8-*- import requests from bs4 import BeautifulSoup import time def getContent(path): Encoding='gbk' # 设置相应的字符集,如果出现乱码,可尝试更换为utf-8 if(path[0:4]=="http"): #从网络获取 response = requests.get(path) response.encoding = Encoding return response.text else: #从本地获取 return open(path,encoding=Encoding).read() f=open("urls.txt","r",buffering=1) urls=map(lambda x:x.replace(' ','').replace('\r','').replace('\n',''),f.readlines()) f2=open("安娜·卡列尼娜_列夫·托尔斯泰.txt","w",buffering=1) for u in urls: time.sleep(1) data=getContent(u) soup = BeautifulSoup(data,"html.parser") title=soup.title.string content=soup.select("#content")[0].get_text() print(title) print(content) f2.write(title+'\n') f2.write(content+'\n')
这一步为访问服务器设置时间间隔,同样是出于节约远端服务器响应资源并防止自己的电脑被拉进黑名单的考虑
对于结构不同的网站,将代码略微修改即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号