Unicode字符的兼容性问题--长得一样的汉字怎么会有多个编码?
昨天半夜帮同学排查问题,明明是一样的汉字,但是字符串比较结果却是False
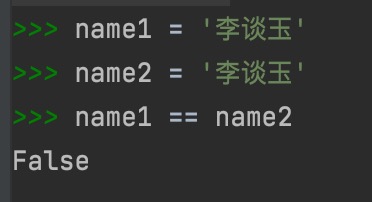
检查了半天,发现是utf-8的编码不同,对方的Mac电脑的Pycharm把这两个编码不同的汉字显示的完全一样

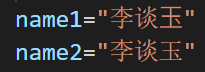
玉 玉
你的电脑上看得出来这两个字的区别么?
但是在我的电脑(Windows10+VisualStudioCode)上显示的就很明显
问题产生的原因
(转自https://www.qqxiuzi.cn/wz/zixun/1717.htm):
---------------------------------------------------------------------------------------------------------------------------------------
Unicode 之初收录汉字遵循两个基本原则:表意文字认同原则和字源分离原则。
所谓表意文字认同原则,即“只对字,不对形”编码,将同一字的不同字形(即异体字,不适用繁简体)合并。例如“房”字的第一笔,在中日韩的写法都不同,但它本身是同一个字,只给一个编码,而写法的不同交由字体进行区分。
字源分离原则,是指一个字源中同时收录了同一个字的不同字形,则给予两个字形分别编码。例如:“戶”、“户”、“戸”三个字。
基于这两个原则,Unicode 能大幅减少收录汉字的数量。然而这两个原则是相互对立的,字源分离原则破坏了认同原则中的“只对字,不对形”编码之原则,使某些汉字获得两个或多个编码,亦遭受不少批评。例如“値”和“值”。
所以,在 Unicode 1.0 收录了 20915 个汉字(20902个基本汉字 + 汉字〇 + 12个兼容表意汉字)之后,字源分离原则被放弃。此后,同一字源中不同写法的汉字,正统的编入正式编码区,而异体字则编入“兼容表意文字区”。
Unicode 12.1 兼容表意文字编码区域:
0号平面 F900-FAFF 中日韩兼容表意文字 (CJK Compatibility Ideographs)
2号平面 2F800-2FA1F 中日韩兼容表意文字增补 (CJK Compatibility Ideographs Supplement)
------------------------------------------------------------------------------------------------------------------------------------------
启示:
1,尽量不要使用Unicode字符集中的兼容表意文字编码区域,这一点在从OCR文档中复制文字时要尤其注意,在写代码时遇到字符串尽量Ctrl+C Ctrl+V
2,使用合适的代码字体,有助于你看出字符中的细微差别
3,尽量不要使用Unicode字符作为键值
default_name = default_name.replace("⽣", "生") default_name = default_name.replace("⼩", "小") default_name = default_name.replace("⽟", "玉") default_name = default_name.replace("⼤", "大") default_name = default_name.replace("⽉", "月") default_name = default_name.replace("⽜", "牛") default_name = default_name.replace("⾼", "高") default_name = default_name.replace("⼉", "儿") default_name = default_name.replace("⼆", "二") default_name = default_name.replace("⾦", "金") default_name = default_name.replace("⽂", "文") default_name = default_name.replace("⼭", "山") default_name = default_name.replace("⾹", "香") default_name = default_name.replace("⾉", "艮") default_name = default_name.replace("⽴", "立") default_name = default_name.replace("⼋", "八") default_name = default_name.replace("⽥", "田") default_name = default_name.replace("⽕", "火") default_name = default_name.replace("⼦", "子")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号