Datawhale AI 夏令营-天池Better Synth多模态大模型数据合成挑战赛-baseline复现与理解总结(更新中)

在大数据、大模型时代,随着大模型发展,互联网数据渐尽且需大量处理标注,为新模型训练高效合成优质数据成为新兴问题。“天池 Better Synth - 多模态大模型数据合成挑战赛”应运而生,旨在探究合成数据对多模态大模型训练的影响及高效合成方法策略,推动多模态大模型数据合成创新。比赛关注图片理解任务,要求在给定种子数据集和计算量约束下,通过高效方法生成更优数据以训练模型。竞赛使用 Data-Juicer 系统助力参赛者,NVIDIA 的相关开源库让选手能探索高效合成大量优质数据。“Better Synth”是系列赛第四场,为专业人员提供舞台,引领多模态大模型开源共享发展。
天池Better Synth多模态大模型数据合成挑战赛
对应比赛链接:https://tianchi.aliyun.com/competition/entrance/532251/
赛季 1:2024-08-26
多模态数据合成的意义和作用在于:
- 解决互联网数据不足和处理标注难题,为大模型训练提供新的数据来源。
- 推动探索高效的数据合成方法与策略,促进多模态大模型数据合成的创新发展。
- 助力实现对图像理解多模态大模型的高效训练,发挥“数据-模型”协同研发的优势。
- 为数据工程师和机器学习专家提供展示能力和交流创新的平台,引领行业开源共享发展。
例如,通过高效合成数据,可以避免因互联网数据枯竭而导致模型训练受限;
新的合成方法能大幅提高数据质量和可用性,如生成更准确、丰富的图像数据用于训练图像理解模型;
数据合成的创新还能促进不同领域专家的合作与交流,共同推动行业进步。
比赛内容
Better Synth 是一项以数据为中心的挑战赛,考察如何合成与清洗图文数据以在多模态大模型上取得更优的图片理解能力。
本次比赛基于 Mini-Gemini 模型进行训练,只关注于预训练(模态间对齐)阶段的数据合成与清洗,指令微调阶段为固定数据集。为了选手更高效地迭代数据合成方案,本次比赛选用 MGM-2B 规模的模型作为比赛模型。
主办方提供候选种子数据集,要求参赛者基于种子数据集进行数据合成与清洗,产出一份基于种子数据集的更高质量、更多样性的数据集,并在给定计算约束下进行训练。主办方提供开发套件,要求参赛者在统一的框架和参数设置下进行模型训练和任务评测,公平对比数据导致的性能差异。数据集产出流程中必须包含“合成”的过程,未包含的方案会被认为是无效方案。
线上赛与线下赛将提供不同的种子数据集,并且线下赛将基于线上赛参与排名的模型继续训练。
线上赛与线下赛过程中种子数据集与模型训练的信息差异如下表所示:
| 比赛约束 | 线上赛 | 线下赛 |
|---|---|---|
| 比赛模型 | MGM-2B | MGM-2B |
| 种子数据集数据量(预训练阶段) | 400k | 10k |
| 预训练数据量约束 | 200k | 5k |
| 指令微调数据量约束 | 240k | 6k |
使用的评估数据benchmark 为:
| MMBench | TextVQA | |
|---|---|---|
| 介绍 | MMBench系统地开发了一个全面的评估管道,主要包括两个要素。第一个要素是精心策划的数据集,在评估问题和能力的数量和种类方面超过现有的类似基准。第二个元素引入了一种新的CircularEval策略,并结合了ChatGPT的使用。该实现旨在将自由形式的预测转换为预定义的选择,从而促进对模型预测的更鲁棒评估。MMBench是一个系统设计的客观基准,用于鲁棒地评估视觉语言模型的各种能力。 | TextVQA 要求模型读取并推理图像中的文本,以回答有关文本的问题。具体而言,模型需要整合图像中存在的一种新文本形式,并对其进行推理以回答 TextVQA 问题 |
| 统计数据 | 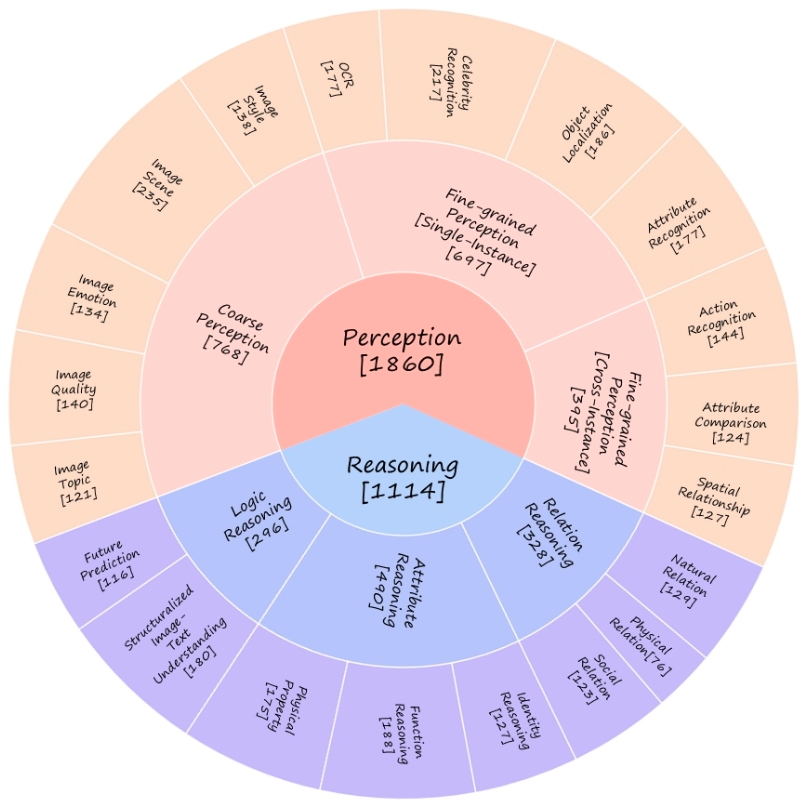 |
来自 OpenImages的28,408 张图片 45,336 个问题,53,360个真实答案 |
| Paper | Paper | Paper |
| Datasets | Datasets | Datasets |
baseline 介绍
跑通整个 baseline,这里主要分为以下几步:
- 1、解决算力资源&配置环境
- 2、处理多模态大模型数据
- 3、训练模型并推理评估
其中涉及到多模态大模型的一些知识点和前置知识,直接在下面对应位置进行补充和注解。
*baseline对应手册:从零入门多模态大模型数据合成
1、解决算力资源&配置环境
这里的算力资源平台方案,可以选择:
-
阿里云PAI-DSW试用:https://free.aliyun.com/?productCode=learn (这个是笔者试跑成功的)
开通PAI-DSW 试用 ,可获得5000算力时!有效期3个月!
如果已经开通试用或试用已过期,可以跳过此步骤,使用魔搭免费GPU额度或寻找其他的算力方案
- 注意多模态数据合成方向无法通过魔搭免费GPU执行
-
autoDL:https://www.autodl.com/home
-
openbayes:https://openbayes.com/
由于配置baseline环境较为复杂,此处提供了以下可用的镜像地址:
- 阿里云镜像链接:dsw-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-training-algorithm/data-juicer-better-synth:0.0.1
- autodl镜像链接(社区镜像):datawhalechina/self-llm/Better-Synth
以上【baseline 手册】已经将环境基本配置介绍详细,直接无脑follow即可。
2、处理多模态大模型数据
由于考虑到云服务器启用实例耗时以及所产生的费用,可以先使用cpu环境的配置下载好所需的数据以及模型,
此外这里列出对应步骤的耗时以及是否需要使用gpu,用来作为参考,如下表:
| 步骤 | 耗时(minute/h) | 是否需要使用GPU |
|---|---|---|
| 2.1 下载赛事所属文件包 | 2mintue内 | 否 |
| 2.2 下载多模态base模型及数据集 & 相关依赖软件 | 约 1h,具体看网速 | 否 |
| 2.3 下载BLIP2图片描述(Image caption)模型 | 约 0.5-1h,具体看网速 | 否 |
| 2.4 数据处理与合成 | 约 20-30minute | 是 |
根据上表,可以考虑在【 2.4数据处理与合成】步骤时,保存配置,修改配置为GPU,并重启实例进入。
- 镜像地址:registry.cn-shanghai.aliyuncs.com/pai-ai-test/pai-eas:data-juicer-better-synth-v0.2
| ecs.gn7i-c32g1.8xlarge | 1 * NVIDIA A10 | 32 vCPU | 188 GiB | 1 * 24 GiB | 16 Gbps | ¥ 14.640 / 14.640 |
|---|
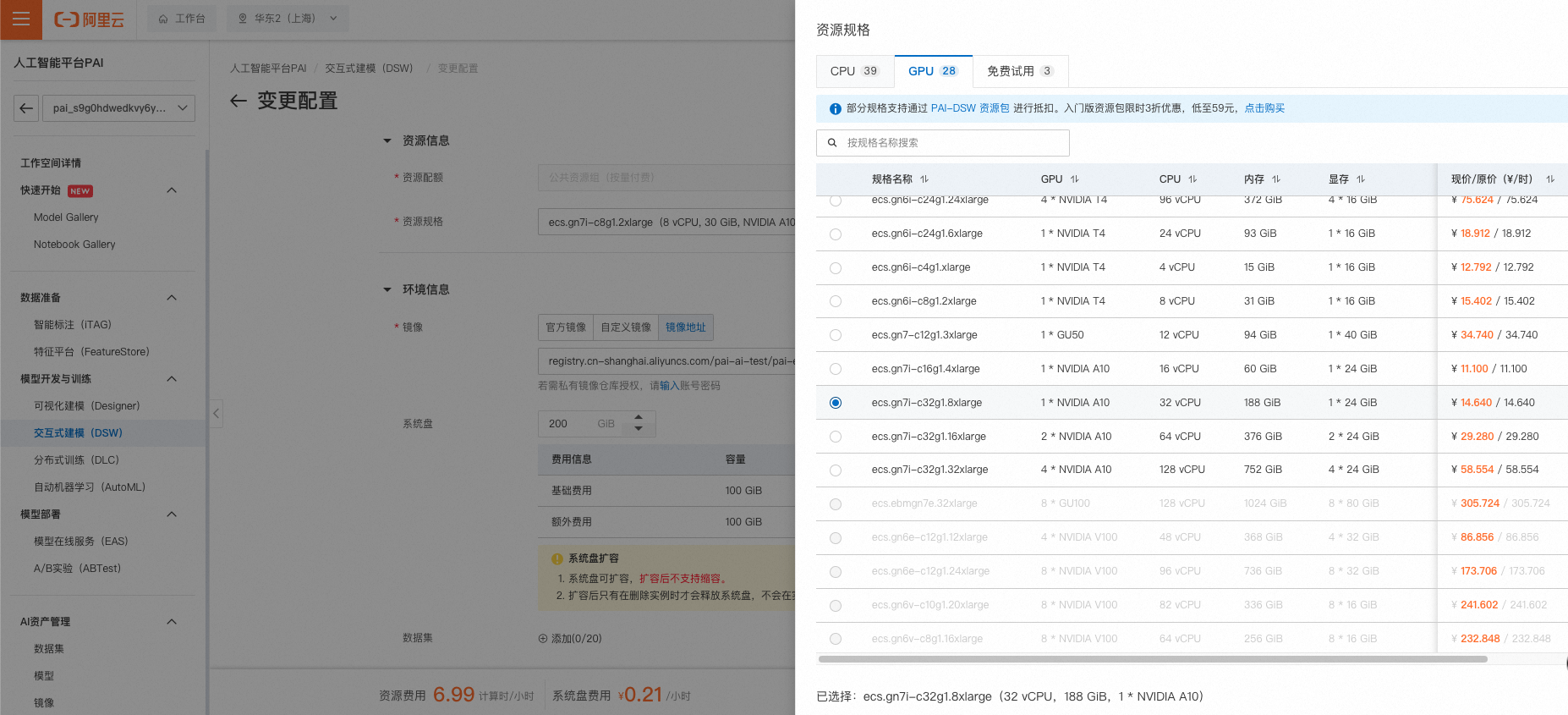
温馨提示:由于baseline运行需求,我们需要
- 额外扩充磁盘空间,至少需要增加50G,需0.1元每小时,
- 在后面的模型训练和评测阶段,需要跑大概3小时,至少需要100G+以上的内存,需要至少购置阿里云188G内存的GPU规格,大概需要15元每小时
- 还可自行寻找其他同等算力(如 autodl、openbayes),需要自行通过文件包中的
install.sh安装环境
2.1 下载赛事开发套件
主办方提供统一的开发套件 dj_synth_challenge.tar.gz,参赛者下载解压后会得到如下文件目录:
dj_synth_challenge
├── install.sh ########## 请勿修改 ##########
├── download.sh ########## 请勿修改 ##########
├── solution
│ ├── readme.txt
│ ├── requirements.txt
│ └── ...
├── toolkit
│ ├── training ########## 请勿修改 ##########
│ ├── data-juicer
| └── train_gemma_v2b_336_hr_768_stage_1.sh ########## 只允许修改脚本中标明可修改的参数 ##########
├── input ########## 下载数据集时自动创建,请勿修改 ##########
├── output
└── README.md
datawhale团队根据上面的官方套件,做了一个优化版的 baseline,可以直接复现。
直接在终端中,克隆这个 repo仓库即可,得到与开发套件对应的better版代码。
git clone https://www.modelscope.cn/datasets/Datawhale/better_synth_challenge_baseline.git
展开上面这个目录树如下:
better_synth_challenge_baseline
├── 10k_quick_baseline.ipynb # 10k数据快速跑通baseline-notebook版
├── README.md
├── download.sh # 下载本赛事做数据合成的数据集
├── download_blip.py # 下载BLIP图片描述模型
├── input # 模型输入: 下载完成的数据集,包括图片和标签
├── install.sh # 依赖环境安装
├── output # 模型输出
├── solution # 解决方案-配置
│ ├── image_captioning.yaml
│ ├── readme
│ └── requirements.txt
├── submit # 结果提交
│ └── output
│ ├── eval_results # 评估结果
│ └── training_dirs # 训练目录
│ ├── MGM-2B-Finetune-image_recaption # mini-gemini微调(提交日志即可)
│ └── MGM-2B-Pretrain-image_recaption # mini-gemini预训练(提交日志即可)
└── toolkit # 工具套件
├── eval # 评估脚本
│ ├── mmbench.sh # 评估mmbench数据集
│ └── textvqa.sh # 评估textvqa数据集
├── train_mgm_2b_stage_1.sh # 训练脚本
└── training # 以下为mini-gemini训练所需代码,无需修改
├── LICENSE
├── README.md
├── cog.yaml
├── hostfile
├── hostfile_4
├── mgm
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-310.pyc
│ │ ├── constants.cpython-310.pyc
│ │ ├── conversation.cpython-310.pyc
│ │ ├── mm_utils.cpython-310.pyc
│ │ └── utils.cpython-310.pyc
│ ├── constants.py
│ ├── conversation.py
│ ├── eval
│ │ ├── MMMU
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── eval
│ │ │ │ ├── README.md
│ │ │ │ ├── answer_dict_val.json
│ │ │ │ ├── configs
│ │ │ │ │ └── llava1.5.yaml
│ │ │ │ ├── convert_to_test.py
│ │ │ │ ├── eval.py
│ │ │ │ ├── example_outputs
│ │ │ │ │ ├── llava1.5_13b
│ │ │ │ │ │ ├── Accounting
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Agriculture
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Architecture_and_Engineering
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Art
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Art_Theory
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Basic_Medical_Science
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Biology
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Chemistry
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Clinical_Medicine
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Computer_Science
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Design
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Diagnostics_and_Laboratory_Medicine
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Economics
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Electronics
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Energy_and_Power
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Finance
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Geography
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── History
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Literature
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Manage
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Marketing
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Materials
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Math
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Mechanical_Engineering
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Music
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Pharmacy
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Physics
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Psychology
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Public_Health
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ ├── Sociology
│ │ │ │ │ │ │ └── output.json
│ │ │ │ │ │ └── total_val_output.json
│ │ │ │ │ ├── llava1.5_13b_val.json
│ │ │ │ │ └── qwen_vl
│ │ │ │ │ ├── Accounting
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Agriculture
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Architecture_and_Engineering
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Art
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Art_Theory
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Basic_Medical_Science
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Biology
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Chemistry
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Clinical_Medicine
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Computer_Science
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Design
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Diagnostics_and_Laboratory_Medicine
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Economics
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Electronics
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Energy_and_Power
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Finance
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Geography
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── History
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Literature
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Manage
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Marketing
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Materials
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Math
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Mechanical_Engineering
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Music
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Pharmacy
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Physics
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Psychology
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Public_Health
│ │ │ │ │ │ └── output.json
│ │ │ │ │ ├── Sociology
│ │ │ │ │ │ └── output.json
│ │ │ │ │ └── total_val_output.json
│ │ │ │ ├── main_eval_only.py
│ │ │ │ ├── main_parse_and_eval.py
│ │ │ │ ├── print_results.py
│ │ │ │ ├── run_llava.py
│ │ │ │ └── utils
│ │ │ │ ├── data_utils.py
│ │ │ │ ├── eval_utils.py
│ │ │ │ └── model_utils.py
│ │ │ └── image.png
│ │ ├── MathVista
│ │ │ ├── calculate_score.py
│ │ │ ├── extract_answer.py
│ │ │ ├── prompts
│ │ │ │ └── ext_ans.py
│ │ │ └── utilities.py
│ │ ├── __pycache__
│ │ │ ├── model_vqa_loader.cpython-310.pyc
│ │ │ └── model_vqa_mmbench.cpython-310.pyc
│ │ ├── eval_gpt_review.py
│ │ ├── eval_gpt_review_bench.py
│ │ ├── eval_gpt_review_visual.py
│ │ ├── eval_mmbench.py
│ │ ├── eval_pope.py
│ │ ├── eval_science_qa.py
│ │ ├── eval_science_qa_gpt4.py
│ │ ├── eval_science_qa_gpt4_requery.py
│ │ ├── generate_webpage_data_from_table.py
│ │ ├── m4c_evaluator.py
│ │ ├── model_math_vista.py
│ │ ├── model_qa.py
│ │ ├── model_vqa.py
│ │ ├── model_vqa_loader.py
│ │ ├── model_vqa_mmbench.py
│ │ ├── model_vqa_qbench.py
│ │ ├── model_vqa_science.py
│ │ ├── qa_baseline_gpt35.py
│ │ ├── run_llava.py
│ │ ├── summarize_gpt_review.py
│ │ └── webpage
│ │ ├── figures
│ │ │ ├── alpaca.png
│ │ │ ├── bard.jpg
│ │ │ ├── chatgpt.svg
│ │ │ ├── llama.jpg
│ │ │ ├── swords_FILL0_wght300_GRAD0_opsz48.svg
│ │ │ └── vicuna.jpeg
│ │ ├── index.html
│ │ ├── script.js
│ │ └── styles.css
│ ├── mm_utils.py
│ ├── model
│ │ ├── __init__.py
│ │ ├── builder.py
│ │ ├── consolidate.py
│ │ ├── language_model
│ │ │ ├── __pycache__
│ │ │ │ ├── mgm_gemma.cpython-310.pyc
│ │ │ │ ├── mgm_llama.cpython-310.pyc
│ │ │ │ ├── mgm_mistral.cpython-310.pyc
│ │ │ │ └── mgm_mixtral.cpython-310.pyc
│ │ │ ├── mgm_gemma.py
│ │ │ ├── mgm_llama.py
│ │ │ ├── mgm_mistral.py
│ │ │ └── mgm_mixtral.py
│ │ ├── llava_arch.py
│ │ ├── mgm_arch.py
│ │ ├── multimodal_encoder
│ │ │ ├── __pycache__
│ │ │ │ ├── builder.cpython-310.pyc
│ │ │ │ ├── clip_encoder.cpython-310.pyc
│ │ │ │ ├── eva_encoder.cpython-310.pyc
│ │ │ │ └── openclip_encoder.cpython-310.pyc
│ │ │ ├── builder.py
│ │ │ ├── clip_encoder.py
│ │ │ ├── eva_encoder.py
│ │ │ └── openclip_encoder.py
│ │ ├── multimodal_projector
│ │ │ ├── __pycache__
│ │ │ │ └── builder.cpython-310.pyc
│ │ │ └── builder.py
│ │ └── processor
│ │ ├── __pycache__
│ │ │ └── video_processor.cpython-310.pyc
│ │ └── video_processor.py
│ ├── serve
│ │ ├── __init__.py
│ │ ├── cli.py
│ │ ├── controller.py
│ │ ├── examples
│ │ │ ├── extreme_ironing.jpg
│ │ │ ├── monday.jpg
│ │ │ ├── waterview.jpg
│ │ │ └── woolen.png
│ │ ├── gradio_web_server.py
│ │ ├── model_worker.py
│ │ ├── register_worker.py
│ │ ├── sglang_worker.py
│ │ └── test_message.py
│ ├── train
│ │ ├── __pycache__
│ │ │ ├── llava_trainer.cpython-310.pyc
│ │ │ └── train.cpython-310.pyc
│ │ ├── llama_flash_attn_monkey_patch.py
│ │ ├── llama_xformers_attn_monkey_patch.py
│ │ ├── llava_trainer.py
│ │ ├── train.py
│ │ ├── train_mem.py
│ │ └── train_xformers.py
│ └── utils.py
├── predict.py
├── preprocess
│ ├── check_global_batch_size.py
│ └── check_sample_number.py
├── pyproject.toml
└── scripts
├── convert_gqa_for_eval.py
├── convert_mmbench_for_submission.py
├── convert_mmvet_for_eval.py
├── convert_seed_for_submission.py
├── extract_mm_projector.py
├── gemma
│ └── train
│ ├── stage_1_2_full_gemma_v2b_336_hr_768.sh
│ └── stage_2_full_gemma_v2b_672_hr_1536.sh
├── merge_lora_weights.py
├── zero2.json
├── zero2_offload.json
└── zero3.json
106 directories, 202 files
根据以上目录树中,toolkit/training/eval中的MMMU可知,这里可选模型包括:llava1.5_13b、qwen_vl,并且给出了对应的example_outputs,由于baseline选用的是llava,以Accounting任务为例,这里主要考察多模态对于视觉计数的能力,其对应 json格式为:
[
{
"id": "validation_Accounting_1",
"question_type": "multiple-choice",
"answer": "B",
"all_choices": [
"A",
"B",
"C",
"D"
],
"index2ans": {
"A": "$6",
"B": "$7",
"C": "$8",
"D": "$9"
},
"response": "D"
},
这是一个多选题,ABCD分别对应着计算对象的个数。
2.2 下载多模态base模型及数据集 & 相关依赖软件
确认上面的套件下载无误之后,下一步需要进行下载多模态模型所需要的base 模型以及对应的数据集,
这里需要注意的是,下载前需要先进行必要的更新和工具下载
- (1) 依赖安装与工具下载
apt update
apt install axel zip file
pip install modelscope
- (2) 开始下载数据和模型!
主要注意的是,这里的 download 脚本,就已经包含了同时下载数据集和模型的过程。
cd better_synth_challenge_baseline
bash download.sh
下面是运行时保存的日志:
- 1、下载 gemma-2b的模型
[1] Downloading base models for training...
Initializing download: http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/models/gemma-2b-it.tar.gz
File size: 12.3927 Gigabyte(s) (13306509417 bytes)
Opening output file gemma-2b-it.tar.gz
Starting download
[100%] .......... .......... .......... ........
Downloaded 12.3927 Gigabyte(s) in 2:23 minute(s). (90263.70 KB/s)
gemma-2b-it/
gemma-2b-it/.gitattributes
gemma-2b-it/tokenizer_config.json
gemma-2b-it/tokenizer.json
gemma-2b-it/model-00002-of-00002.safetensors
gemma-2b-it/model-00001-of-00002.safetensors
gemma-2b-it/model.safetensors.index.json
gemma-2b-it/tokenizer.model
gemma-2b-it/gemma-2b-it.gguf
gemma-2b-it/generation_config.json
gemma-2b-it/config.json
gemma-2b-it/README.md
gemma-2b-it/special_tokens_map.json
- 2、下载 clip-vit模型,型号为clip-vit-large。
Initializing download: http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/models/clip-vit-large-patch14-336.tar.gz
File size: 1.97914 Gigabyte(s) (2125088520 bytes)
Opening output file clip-vit-large-patch14-336.tar.gz
Starting download
Downloaded 1.97914 Gigabyte(s) in 13 second(s). (151008.30 KB/s)
clip-vit-large-patch14-336/
clip-vit-large-patch14-336/.gitattributes
clip-vit-large-patch14-336/tokenizer_config.json
clip-vit-large-patch14-336/tokenizer.json
clip-vit-large-patch14-336/vocab.json
clip-vit-large-patch14-336/tf_model.h5
clip-vit-large-patch14-336/preprocessor_config.json
clip-vit-large-patch14-336/merges.txt
clip-vit-large-patch14-336/config.json
clip-vit-large-patch14-336/README.md
clip-vit-large-patch14-336/special_tokens_map.json
clip-vit-large-patch14-336/pytorch_model.bin
- 3、下载openclip模型,型号为openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup。
Initializing download: http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/models/openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup.tar.gz
File size: 2.43756 Gigabyte(s) (2617314734 bytes)
Opening output file openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup.tar.gz
Starting download
Downloaded 2.43756 Gigabyte(s) in 1:04 minute(s). (39712.34 KB/s)
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/.gitattributes
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/README.md
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/merges.txt
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/open_clip_config.json
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/open_clip_pytorch_model.bin
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/open_clip_pytorch_model.safetensors
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/special_tokens_map.json
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/tensorboard/
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/tensorboard/events.out.tfevents.1675704018.ip-26-0-128-115.2929104.0
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/tensorboard/events.out.tfevents.1675789101.ip-26-0-128-115.3586099.0
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/tensorboard/events.out.tfevents.1675842516.ip-26-0-129-137.3277246.0
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/tokenizer.json
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/tokenizer_config.json
openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup/vocab.json
- 4、下载 seed 种子数据集,用于 pretrain 阶段,大小为 446.138(MB)
[2] Downloading seed datasets...
Initializing download: http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/pretrain_stage_1_10k.tar.gz
File size: 446.138 Megabyte(s) (467810052 bytes)
Opening output file pretrain_stage_1_10k.tar.gz
Starting download
Downloaded 446.138 Megabyte(s) in 4 second(s). (96324.16 KB/s)
pretrain_stage_1_10k/
pretrain_stage_1_10k/ALLaVA-4V/
pretrain_stage_1_10k/ALLaVA-4V/allava_laion/
pretrain_stage_1_10k/ALLaVA-4V/allava_laion/images/
pretrain_stage_1_10k/ALLaVA-4V/allava_laion/images/24529.jpeg
pretrain_stage_1_10k/ALLaVA-4V/allava_laion/images/48153.jpeg
pretrain_stage_1_10k/ALLaVA-4V/allava_laion/images/77682.jpeg
pretrain_stage_1_10k/ALLaVA-4V/allava_laion/images/77973.jpeg
pretrain_stage_1_10k/images/
- 5、下载用于微调的数据集。大小为1.9(GB)
Downloaded 91.9325 Megabyte(s) in 1 second(s). (54326.22 KB/s)
[3] Downloading finetuning datasets...
Initializing download: http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/finetuning_stage_1_12k.tar.gz
File size: 1.94169 Gigabyte(s) (2084872773 bytes)
Opening output file finetuning_stage_1_12k.tar.gz
Starting download
Downloaded 1.94169 Gigabyte(s) in 20 second(s). (99369.70 KB/s)
finetuning_stage_1_12k/
finetuning_stage_1_12k/ALLaVA-4V/
finetuning_stage_1_12k/ALLaVA-4V/allava_laion/
finetuning_stage_1_12k/ALLaVA-4V/allava_laion/images/
- 6、下载用于评估的数据集。大小为6.678(GB)
Downloaded 13.5933 Megabyte(s) in 0 second(s). (16912.15 KB/s)
[4] Downloading evaluation datasets
Initializing download: http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/eval_stage_1.tar.gz
File size: 6.67806 Gigabyte(s) (7170513165 bytes)
Opening output file eval_stage_1.tar.gz
Starting download
eval_stage_1/textvqa/llava_textvqa_val_v051_ocr.jsonl
eval_stage_1/mmbench/
eval_stage_1/textvqa/train_images/c6b479c0bd06a220.jpg
eval_stage_1/textvqa/train_images/4f1638b1427ec355.
... ...
eval_stage_1/mmbench/.ipynb_checkpoints/
eval_stage_1/mmbench/.ipynb_checkpoints/eval-mmbench-checkpoint.py
eval_stage_1/mmbench/mmbench_dev_20230712.tsv
下面是下载到电脑上的种子数据预览:
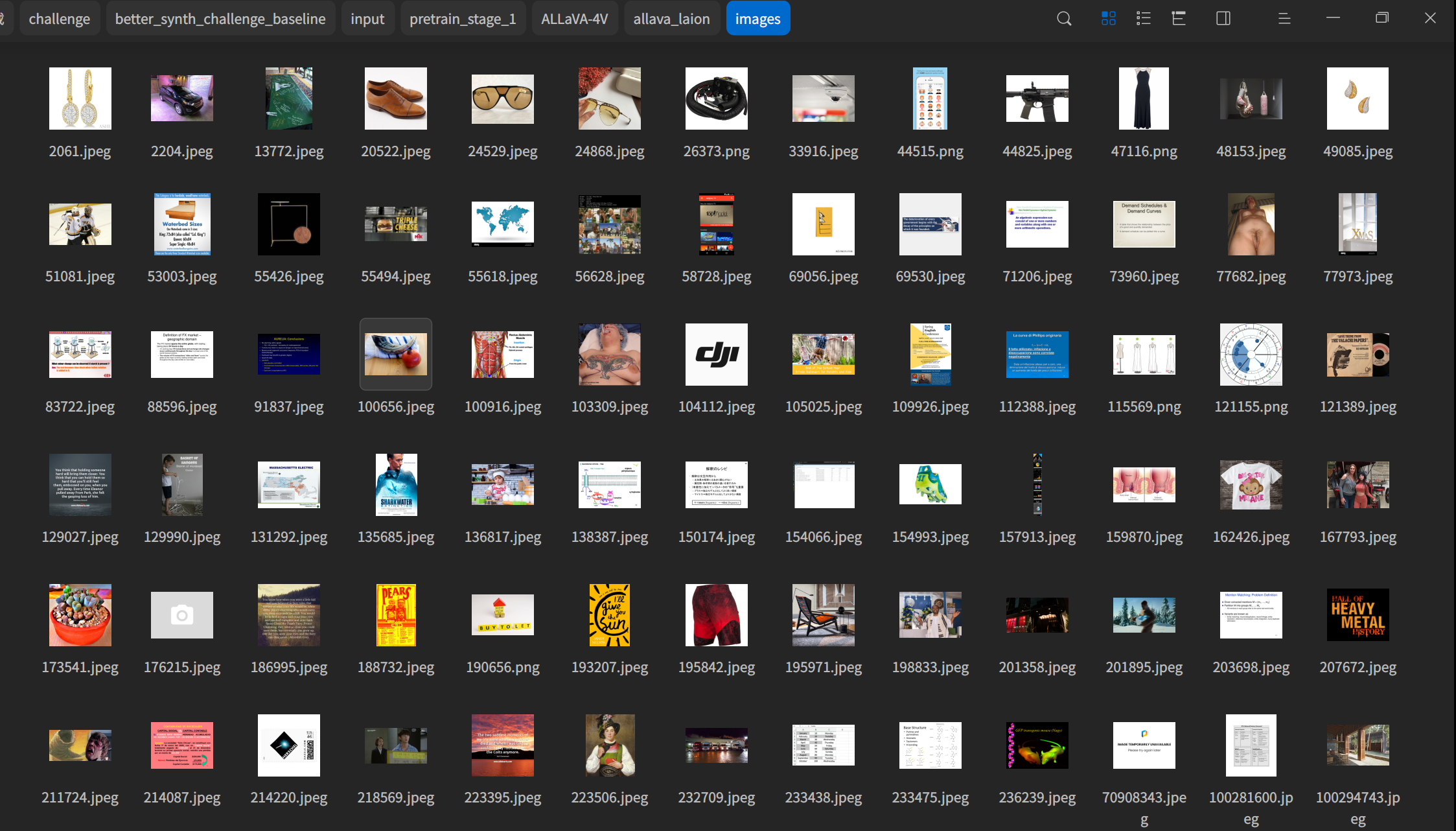
2.3 下载BLIP2图片描述(Image caption)模型
这个步骤运行前,请确认:
如果是其他环境,需要将文件中的
'/mnt/workspace/'修改为
'/root/autodl-tmp/'或其他
better_synth_challenge_baseline文件夹所在的对应的路径
执行完成以上步骤后 ,复制如下命令,在终端中执行
python download_blip.py
### 下载BLIP模型,大概需要20分钟
from modelscope import snapshot_download
model_dir = snapshot_download('goldsj/blip2-opt-2.7b',
cache_dir='/mnt/workspace/better_synth_challenge_baseline/models',
revision='master')
# 如果是在autoDL上,需要修改download_blip.py文件,将下载路径对应修改为
# cache_dir='/root/autodl-tmp/better_synth_challenge_baseline/models'
BLIP2模型介绍
由于大模型的训练成本比较昂贵。BLIP 2 旨在从冻结的图像编码器和冻结的大语言模型中引导多模态视觉语言模型的训练。
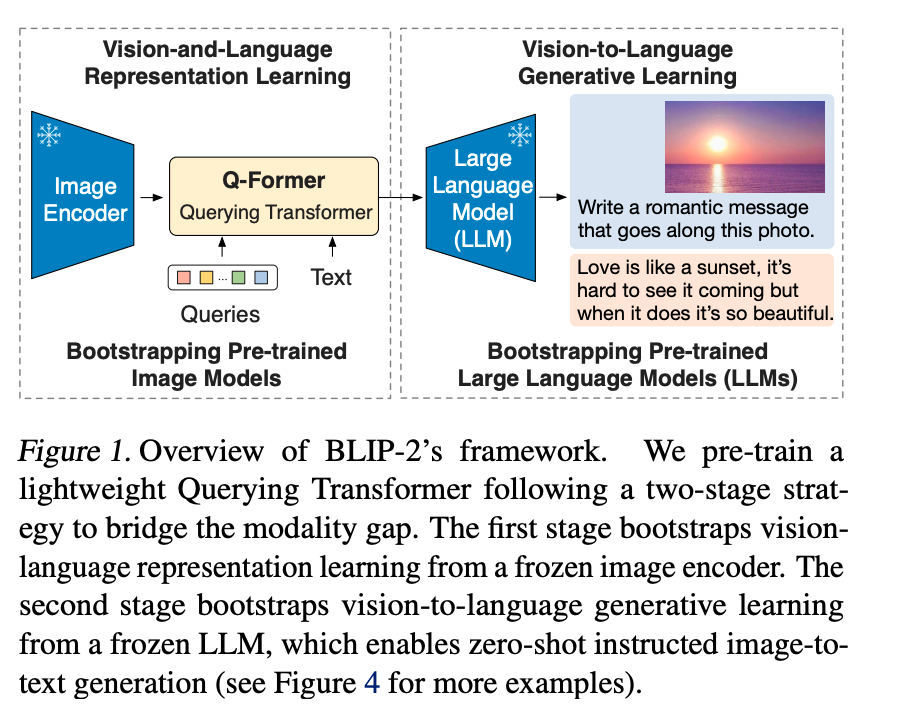
通过一个轻量级的 Q-Former 模块来弥补模态之间的差距,它分为两个阶段学习:
- 从冻结的图像编码器中引导视觉语言的表征学习。
- 从冻结的语言模型中引导视觉到语言的生成学习。
它们的模型训练好之后,能够在遵循 prompt 的情况下实现 zero-shot 的图像到文本的生成。其贡献如下:
- 通过 Q-Former 有效的利用了冻结的单模态模型,且弥补了跨模态的差距。Q-Former 以两阶段的方式进行训练,分别为:视觉表征学习阶段、语言生成学习阶段。
- 在 LLM 的加持下,BLIP 2 可以遵循文本指令进行 zero-shot 的图像到文本的生成,从而实现视觉知识推理、视觉对话等新兴能力。
- 由于使用了 Q-Forme 且冻结了单模态大模型,BLIP 2 的计算效率更高,训练参数也得以减少。
2.4 数据处理与合成
Data-Juicer 是一个一站式多模态数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。
它的特点为:
- 广泛的算子:配备50+核心算子(OP),包括Formatters,Mappers,Filters,Deduplicators及以上。
- 专用工具包:丰富的专用工具包,如Text Quality Classifier、Dataset Splitter、Analysers、Evaluators等,可提升您的数据集处理能力。
- 系统&可重复使用:为用户提供可重复使用的config recipes和OPs系统库,旨在独立于特定数据集,模型或任务运行。
- 数据闭环:允许使用自动生成报告功能进行详细的数据分析,以便更深入地了解数据集。再加上及时的多维自动评估功能,它支持LLM开发过程中多个阶段的反馈循环。
- 全面的处理配方:提供数十种pre-built data processing recipes用于预训练,CFT,en,zh等场景。
官方准备了 Jupyter Notebook 帮助参赛者快速熟悉比赛流程,可以进行使用体验,以更加熟悉 dj 的用法!
huggingface 中也有对应的演示与介绍可以进行体验。
Data-Juicer提供了一些配置文件,让用户可以轻松了解各种功能的配置方法,快速重现不同数据集的处理流程。
下面正式开始进行 image caption 的数据合成!
dj-process --config solution/image_captioning.yaml
下面的 yaml 配置文件中,设置了datasets 数据集的原始路径和导出路径,并且指定process过程为image_captioning_mapper的 mapper任务,同时将img2seq的模型设置为前面使用 download_blip的 blip-opt的模型进行数据合成。
dataset_path: input/pretrain_stage_1_10k/mgm_pretrain_stage_1_10k.jsonl
export_path: output/image_captioning_output/res_10k.jsonl
np: 1
process:
- image_captioning_mapper:
hf_img2seq: '/mnt/workspace/better_synth_challenge_baseline/models/goldsj/blip2-opt-2___7b' # You can replace this path to a local downloaded HF model
keep_original_sample: false # we only need the recaptioned captions
其过程日志如下:
2024-08-12 03:01:03.078 | INFO | data_juicer.config.config:config_backup:618 - Back up the input config file [/mnt/workspace/better_synth_challenge_baseline/solution/image_captioning.yaml] into the work_dir [/mnt/workspace/better_synth_challenge_baseline/output/image_captioning_output]
2024-08-12 03:01:03.089 | INFO | data_juicer.config.config:display_config:640 - Configuration table:
╒═════════════════════════╤══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╕
│ key │ values │
╞═════════════════════════╪══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╡
│ config │ [Path_fr(solution/image_captioning.yaml, cwd=/mnt/workspace/better_synth_challenge_baseline)] │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ hpo_config │ None │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ data_probe_algo │ 'uniform' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ data_probe_ratio │ 1.0 │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ project_name │ 'hello_world' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ executor_type │ 'default' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ dataset_path │ '/mnt/workspace/better_synth_challenge_baseline/input/pretrain_stage_1_10k/mgm_pretrain_stage_1_10k.jsonl' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ export_path │ '/mnt/workspace/better_synth_challenge_baseline/output/image_captioning_output/res_10k.jsonl' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ export_shard_size │ 0 │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ export_in_parallel │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ keep_stats_in_res_ds │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ keep_hashes_in_res_ds │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ np │ 1 │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ text_keys │ 'text' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ image_key │ 'images' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ image_special_token │ '<__dj__image>' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ audio_key │ 'audios' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ audio_special_token │ '<__dj__audio>' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ video_key │ 'videos' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ video_special_token │ '<__dj__video>' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ eoc_special_token │ '<|__dj__eoc|>' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ suffixes │ [] │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ use_cache │ True │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ ds_cache_dir │ '/root/.cache/huggingface/datasets' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ cache_compress │ None │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ use_checkpoint │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ temp_dir │ None │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ open_tracer │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ op_list_to_trace │ [] │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ trace_num │ 10 │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ op_fusion │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ process │ [{'image_captioning_mapper': {'accelerator': None, │
│ │ 'audio_key': 'audios', │
│ │ 'caption_num': 1, │
│ │ 'cpu_required': 1, │
│ │ 'hf_img2seq': '/mnt/workspace/better_synth_challenge_baseline/models/goldsj/blip2-opt-2___7b', │
│ │ 'image_key': 'images', │
│ │ 'keep_candidate_mode': 'random_any', │
│ │ 'keep_original_sample': False, │
│ │ 'mem_required': 0, │
│ │ 'num_proc': 1, │
│ │ 'prompt': None, │
│ │ 'prompt_key': None, │
│ │ 'text_key': 'text', │
│ │ 'video_key': 'videos'}}] │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ percentiles │ [] │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ export_original_dataset │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ save_stats_in_one_file │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ ray_address │ 'auto' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ debug │ False │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ work_dir │ '/mnt/workspace/better_synth_challenge_baseline/output/image_captioning_output' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ timestamp │ '20240812030102' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ dataset_dir │ '/mnt/workspace/better_synth_challenge_baseline/input/pretrain_stage_1_10k' │
├─────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ add_suffix │ False │
╘═════════════════════════╧══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╛
2024-08-12 03:01:03.090 | INFO | data_juicer.core.executor:__init__:47 - Using cache compression method: [None]
2024-08-12 03:01:03.090 | INFO | data_juicer.core.executor:__init__:52 - Setting up data formatter...
2024-08-12 03:01:03.112 | INFO | data_juicer.core.executor:__init__:74 - Preparing exporter...
2024-08-12 03:01:03.112 | INFO | data_juicer.core.executor:run:151 - Loading dataset from data formatter...
Generating jsonl split: 0 examples [00:00, ? examples/s]
Generating jsonl split: 10000 examples [00:00, 538732.77 examples/s]
2024-08-12 03:01:03.903 | INFO | data_juicer.format.formatter:unify_format:185 - Unifying the input dataset formats...
2024-08-12 03:01:03.903 | INFO | data_juicer.format.formatter:unify_format:200 - There are 10000 sample(s) in the original dataset.
Filter: 0%| | 0/10000 [00:00<?, ? examples/s]
Filter: 90%|#################1 | 9000/10000 [00:00<00:00, 76513.57 examples/s]
Filter: 100%|##################| 10000/10000 [00:00<00:00, 76327.38 examples/s]
2024-08-12 03:01:04.036 | INFO | data_juicer.format.formatter:unify_format:214 - 10000 samples left after filtering empty text.
2024-08-12 03:01:04.037 | INFO | data_juicer.format.formatter:unify_format:237 - Converting relative paths in the dataset to their absolute version. (Based on the directory of input dataset file)
Map: 0%| | 0/10000 [00:00<?, ? examples/s]
Map: 14%|### | 1389/10000 [00:00<00:00, 13811.61 examples/s]
Map: 28%|######1 | 2804/10000 [00:00<00:00, 14006.38 examples/s]
Map: 49%|##########7 | 4887/10000 [00:00<00:00, 13932.16 examples/s]
Map: 70%|###############3 | 6966/10000 [00:00<00:00, 13895.66 examples/s]
Map: 90%|###################8 | 9000/10000 [00:00<00:00, 13685.91 examples/s]
Map: 100%|#####################| 10000/10000 [00:00<00:00, 13750.58 examples/s]
2024-08-12 03:01:04.766 | INFO | data_juicer.format.mixture_formatter:load_dataset:137 - sampled 10000 from 10000
2024-08-12 03:01:04.768 | INFO | data_juicer.format.mixture_formatter:load_dataset:143 - There are 10000 in final dataset
2024-08-12 03:01:04.768 | INFO | data_juicer.core.executor:run:157 - Preparing process operators...
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/torch/_utils.py:776: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
Loading checkpoint shards: 50%|########5 | 1/2 [00:45<00:45, 45.85s/it]
Loading checkpoint shards: 100%|#################| 2/2 [01:10<00:00, 33.39s/it]
Loading checkpoint shards: 100%|#################| 2/2 [01:10<00:00, 35.26s/it]
2024-08-12 03:02:15.933 | INFO | data_juicer.core.executor:run:164 - Processing data...
2024-08-12 03:02:15.933 | DEBUG | data_juicer.utils.process_utils:setup_mp:30 - Setting multiprocess start method to 'forkserver'
2024-08-12 03:02:15.945 | WARNING | data_juicer.utils.process_utils:calculate_np:70 - The required cuda memory of Op[image_captioning_mapper] has not been specified. Please specify the mem_required field in the config file, or you might encounter CUDA out of memory error. You can reference the mem_required field in the config_all.yaml file.
2024-08-12 03:02:15.946 | DEBUG | data_juicer.ops.base_op:runtime_np:195 - Op [image_captioning_mapper] running with number of procs:1
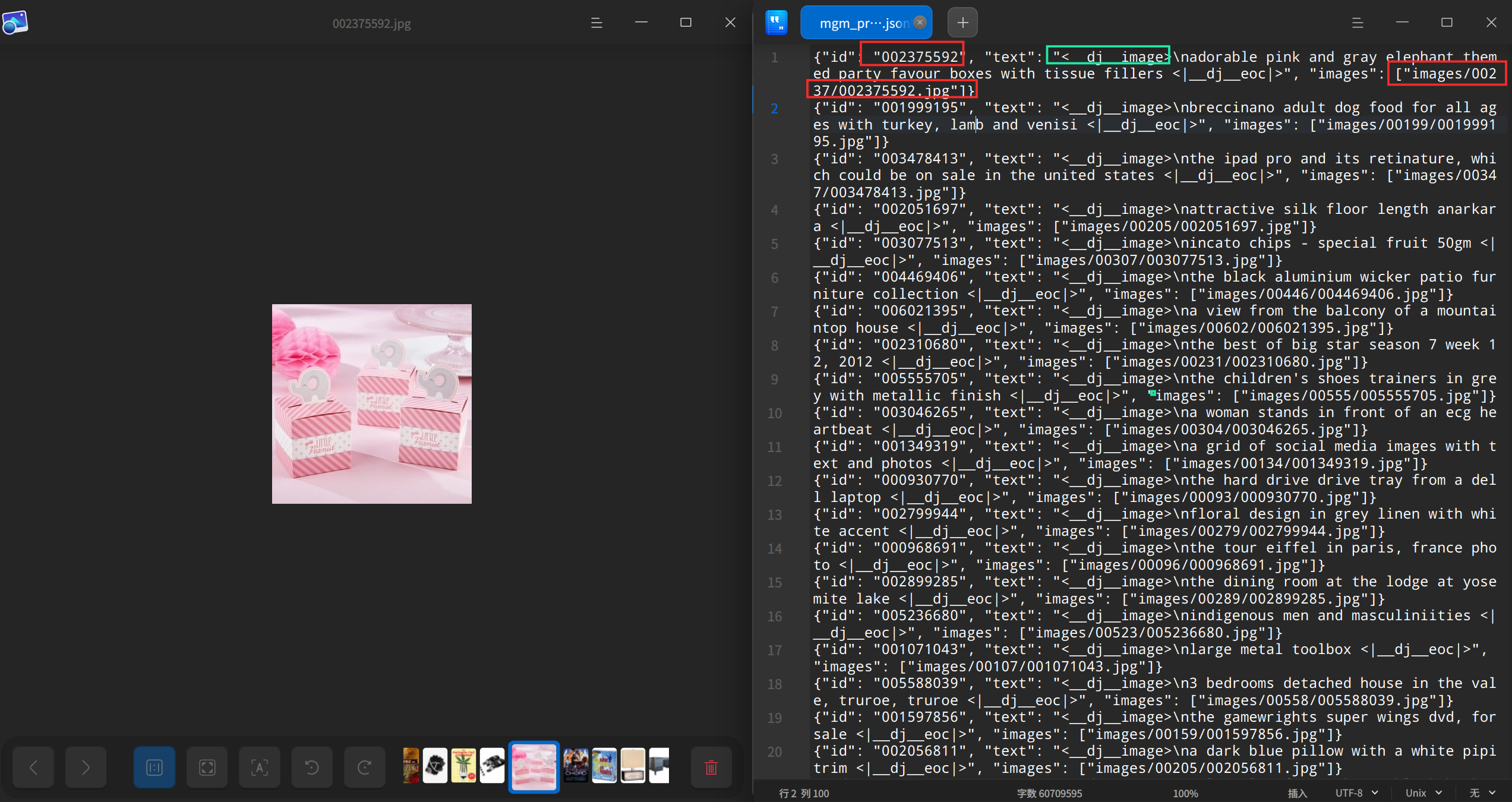
最后,我们会得到什么样的结果呢?
下面是res_10k.jsonl的结果示例:可以发现在 text 内容前面有添加"<__ dj __image>"的前缀,这说明生成的是dj 格式的。
{"id":"006092514","text":"<__dj__image> time bombs are used in minecraft\n <|__dj__eoc|>","images":["\/mnt\/workspace\/better_synth_challenge_baseline\/input\/pretrain_stage_1_10k\/images\/00609\/006092514.jpg"]}
{"id":"003743290","text":"<__dj__image> illustration vector set of floral decorative tags for banners\n <|__dj__eoc|>","images":["\/mnt\/workspace\/better_synth_challenge_baseline\/input\/pretrain_stage_1_10k\/images\/00374\/003743290.jpg"]}
为了更便于理解,这里列出了dj(data_juicer)数据格式的数据预览:
3、训练模型并推理评估
3.1 执行模型训练 & 推理测评
这个步骤运行前,请确认:
- 如果是阿里云环境,需要使用镜像:dsw-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-training-algorithm/data-juicer-better-synth:0.0.1
- 如果是其他环境,需要将
toolkit/train_mgm_2b_stage_1.sh文件中的'/mnt/workspace/'
修改为
'/root/autodl-tmp/'或其他
better_synth_challenge_baseline文件夹所在的对应的路径- 如果执行过
bash install.sh,则无需执行下方的git clone ``https://github.com/modelscope/data-juicer.git命令
重启实例后,复制如下命令,在终端中执行
cd better_synth_challenge_baseline/toolkit
git clone https://github.com/modelscope/data-juicer.git
bash train_mgm_2b_stage_1.sh
这是一个用于训练和推理深度学习模型的bash脚本。下面是每一部分的详细解释:
- 首先,定义了一些可以编辑的变量,包括实验名称、预训练数据集、预训练数据集图片路径、训练参数(例如每个GPU的批量大小、梯度累积步数、数据加载器的工作进程数等)、日志和检查点参数(例如日志记录步数、检查点保存步数、保存检查点的总限制等)以及推理参数(例如推理使用的GPU索引)。
- 然后,脚本获取当前脚本所在的目录,并设置原始数据集的路径。
- 接着,脚本检查预训练和微调阶段的全局批量大小是否正确。如果不正确,脚本会打印错误信息并退出。
- 脚本检查数据集样本数量是否超过最大样本数,如果超过,就将数据集裁剪到最大样本数。
- 然后,脚本将数据集从dj格式转换为llava格式。
- 接下来,脚本进行模型的训练,包括预训练和微调两个阶段。在这两个阶段,脚本使用deepspeed库进行训练,并设置了一系列训练参数,例如模型路径、数据路径、图像文件夹、学习率、权重衰减、预热比例、学习率调度器类型等。
- 训练完成后,脚本进行模型推理,包括对TextVQA和MMBench两个基准测试的推理。
- 最后,脚本将自身复制到输出目录,并打印训练和推理完成的信息,以及训练检查点和推理结果的存储位置。
#!/bin/bash
############################################################################
########################### Editable Part Begins ###########################
############################################################################
# exp meta information
EXP_NAME=default
PRETRAIN_DATASET=../output/image_captioning_output/res_10k.jsonl
PRETRAIN_DATASET_IMAGE_PATH=../input/pretrain_stage_1_10k
# training args
# pretraining
# make sure PRETRAIN_BATCH_SIZE_PER_GPU * PRETRAIN_GRADIENT_ACCUMULATION_STEPS * num_gpus = 256
# **NOTICE**: the default setting is for 1 GPU
PRETRAIN_BATCH_SIZE_PER_GPU=4
PRETRAIN_GRADIENT_ACCUMULATION_STEPS=64
PRETRAIN_DATALOADER_NUM_WORKERS=4
# finetuning
# make sure FINETUNE_BATCH_SIZE_PER_GPU * FINETUNE_GRADIENT_ACCUMULATION_STEPS * num_gpus = 128
# **NOTICE**: the default setting is for 1 GPU
FINETUNE_BATCH_SIZE_PER_GPU=4
FINETUNE_GRADIENT_ACCUMULATION_STEPS=32
FINETUNE_DATALOADER_NUM_WORKERS=4
# log and ckpt
LOGGING_STEP=1
CKPT_SAVE_STEPS=100
TOTAL_SAVE_CKPT_LIMIT=1
# inference args
# inference for some benchmarks supports multi-gpus
INFER_CUDA_IDX="0"
############################################################################
############################ Editable Part Ends ############################
############################################################################
SCRIPT_DIR=$(cd "$(dirname "$0")" && pwd)
ORIGINAL_DATASET_ALL=$SCRIPT_DIR/../input/pretrain_stage_1_10k/stage_1.json
# check the global size
PRETRAIN_PASS=`python $SCRIPT_DIR/training/preprocess/check_global_batch_size.py $PRETRAIN_BATCH_SIZE_PER_GPU $PRETRAIN_GRADIENT_ACCUMULATION_STEPS 256`
if [ "$PRETRAIN_PASS" = "False" ]; then
echo "[ERROR] The global batch size of pretraining stage is not 256! Please check and retry."
exit
fi
FINETUNE_PASS=`python $SCRIPT_DIR/training/preprocess/check_global_batch_size.py $FINETUNE_BATCH_SIZE_PER_GPU $FINETUNE_GRADIENT_ACCUMULATION_STEPS 128`
if [ "$FINETUNE_PASS" = "False" ]; then
echo "[ERROR] The global batch size of finetuning stage is not 128! Please check and retry."
exit
fi
# check number of dataset samples
MAX_SAMPLE_NUM=200000
SAMPLED_PRETRAIN_DATASET=$PRETRAIN_DATASET-200k.jsonl
python $SCRIPT_DIR/training/preprocess/check_sample_number.py $PRETRAIN_DATASET $SAMPLED_PRETRAIN_DATASET $MAX_SAMPLE_NUM
# convert dataset from dj format to llava format
# 转换dj格式的数据集为llava格式
PRETRAIN_DATASET_JSON=$SAMPLED_PRETRAIN_DATASET.json
python $SCRIPT_DIR/data-juicer/tools/multimodal/data_juicer_format_to_target_format/dj_to_llava.py $SAMPLED_PRETRAIN_DATASET $PRETRAIN_DATASET_JSON --image_special_token "<__dj__image>" --restore_questions True --original_llava_ds_path $ORIGINAL_DATASET_ALL
# train model
PRETRAIN_NAME=MGM-2B-Pretrain-$EXP_NAME
FINETUNE_NAME=MGM-2B-Finetune-$EXP_NAME
AUX_SIZE=768
NUM_TRAIN_EPOCHS=1
PRETRAIN_SAMPLE_NUM=200000
# 使用 deepspeed 进行zero2策略的训练PRETRAIN模型
mkdir -p $SCRIPT_DIR/../output/training_dirs/$PRETRAIN_NAME
deepspeed $SCRIPT_DIR/training/mgm/train/train_mem.py \
--deepspeed $SCRIPT_DIR/training/scripts/zero2_offload.json \
--model_name_or_path $SCRIPT_DIR/training/model_zoo/LLM/gemma/gemma-2b-it \
--version gemma \
--data_path $PRETRAIN_DATASET_JSON \
--image_folder $PRETRAIN_DATASET_IMAGE_PATH \
--vision_tower $SCRIPT_DIR/training/model_zoo/OpenAI/clip-vit-large-patch14-336 \
--vision_tower_aux $SCRIPT_DIR/training/model_zoo/OpenAI/openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup \
--mm_projector_type mlp2x_gelu \
--tune_mm_mlp_adapter True \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_size_aux $AUX_SIZE \
--bf16 True \
--output_dir $SCRIPT_DIR/../output/training_dirs/$PRETRAIN_NAME \
--num_train_epochs $NUM_TRAIN_EPOCHS \
--per_device_train_batch_size $PRETRAIN_BATCH_SIZE_PER_GPU \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps $PRETRAIN_GRADIENT_ACCUMULATION_STEPS \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps $CKPT_SAVE_STEPS \
--save_total_limit $TOTAL_SAVE_CKPT_LIMIT \
--learning_rate 1e-3 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps $LOGGING_STEP \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers $PRETRAIN_DATALOADER_NUM_WORKERS \
--lazy_preprocess True \
--report_to none \
2>&1 | tee $SCRIPT_DIR/../output/training_dirs/$PRETRAIN_NAME/pretrain.log
mkdir -p $SCRIPT_DIR/../output/training_dirs/$FINETUNE_NAME
# 使用 deepspeed 进行zero2策略的训练FINETUNE模型
deepspeed $SCRIPT_DIR/training/mgm/train/train_mem.py \
--deepspeed $SCRIPT_DIR/training/scripts/zero2_offload.json \
--model_name_or_path $SCRIPT_DIR/training/model_zoo/LLM/gemma/gemma-2b-it \
--version gemma \
--data_path $SCRIPT_DIR/training/data/finetuning_stage_1_12k/mgm_instruction_stage_1_12k.json \
--image_folder $SCRIPT_DIR/training/data/finetuning_stage_1_12k \
--vision_tower $SCRIPT_DIR/training/model_zoo/OpenAI/clip-vit-large-patch14-336 \
--vision_tower_aux $SCRIPT_DIR/training/model_zoo/OpenAI/openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup \
--pretrain_mm_mlp_adapter $SCRIPT_DIR/../output/training_dirs/$PRETRAIN_NAME/mm_projector.bin \
--mm_projector_type mlp2x_gelu \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_aspect_ratio pad \
--group_by_modality_length True \
--image_size_aux $AUX_SIZE \
--bf16 True \
--output_dir $SCRIPT_DIR/../output/training_dirs/$FINETUNE_NAME \
--num_train_epochs $NUM_TRAIN_EPOCHS \
--per_device_train_batch_size $FINETUNE_BATCH_SIZE_PER_GPU \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps $FINETUNE_GRADIENT_ACCUMULATION_STEPS \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps $CKPT_SAVE_STEPS \
--save_total_limit $TOTAL_SAVE_CKPT_LIMIT \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps $LOGGING_STEP \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers $FINETUNE_DATALOADER_NUM_WORKERS \
--lazy_preprocess True \
--report_to none \
2>&1 | tee $SCRIPT_DIR/../output/training_dirs/$FINETUNE_NAME/finetuning.log
# inference for submission
# TextVQA
echo "Infer on TextVQA..."
bash $SCRIPT_DIR/eval/textvqa.sh $FINETUNE_NAME $INFER_CUDA_IDX
# MMBench
echo "Infer on MMBench..."
bash $SCRIPT_DIR/eval/mmbench.sh $FINETUNE_NAME "mmbench_dev_20230712" $INFER_CUDA_IDX
# copy this script to output
cp $0 $SCRIPT_DIR/../output/train.sh
# info
echo "Training and Inference done."
echo "Training checkpoints are stored in output/training_dirs/$FINETUNE_NAME."
echo "Inference results are stored in output/eval_results/$FINETUNE_NAME."
3.2 打包构建符合提交要求的zip文件
复制如下命令,在终端执行即可,然后下载submit.zip文件!
vim sumbit_package.sh
better_synth_root_dir=/mnt/workspace/
cd submit
cp -r ${better_synth_root_dir}/better_synth_challenge_baseline/solution .
cp -r ${better_synth_root_dir}/better_synth_challenge_baseline/output/eval_results output/
cp -r ${better_synth_root_dir}/better_synth_challenge_baseline/output/train.sh output/
cp ${better_synth_root_dir}/better_synth_challenge_baseline/output/training_dirs/MGM-2B-Finetune-*/finetuning.log output/training_dirs/MGM-2B-Finetune-image_recaption/
cp ${better_synth_root_dir}/better_synth_challenge_baseline/output/training_dirs/MGM-2B-Pretrain-*/pretrain.log output/training_dirs/MGM-2B-Pretrain-image_recaption/
zip -r submit.zip solution output
3.3 提交分数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号