OpenMMLab AI实战营 第二课笔记 计算机视觉之图像分类算法基础
OpenMMLab AI实战营 第二课笔记


- OpenMMLab AI实战营 第二课笔记
- 图像分类与基础视觉基础
- 1.图像分类问题
- 2.模型设计
- 3.模型学习
- 4.MMClassification
- 5.参考材料
图像分类与基础视觉基础

1.图像分类问题

图像分类是根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。 它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域划归为若干个类别中的某一种,以代替人的视觉判读。 简单的说就是识别一张图中是否是某类/状态/场景,适合图中主体相对单一的场景,将下图识别为汽车的图片。
1.1 问题的数学表示

图片分类问题就是辨认输入的图片类别的问题,且图片的类别属于事先给定的一个类别组中。尽管这看起来很简单,但这是计算机视觉的一个核心问题,且有很广泛的实际应用。并且,有很多的计算机视觉的问题最终会化简为图片分类问题。
举例来说,假设有一个图片分类模型,它对于输入的三通道的图片会预测其属于四个标签(label)的概率(四个标签为 cat, dog,hat,mug)。下图所示的图片是一张248像素宽度,400像素高度的图片,并且有RGB三通道,那么这张图片可以用(3 * 248 * 400 )个数字表示,每个数字范围从 0到255,模型的任务就是接受这些数字,然后预测出这些数字代表的标签(label)。
1.2 视觉任务的难点

对于人类来说看懂图片是一件很简单的事情,但是对于机器来说这是一个非常难的事情,比如2个典型的难点:
- 特征难以提取
同一只狗在不同的角度,不同的光线,不同的动作下。像素差异是非常大的。就算是同一张照片,旋转90度后,其像素差异也非常大!
所以图片里的内容相似甚至相同,但是在像素层面,其变化会非常大。这对于特征提取是一大挑战。
- 需要计算的数据量巨大
手机上随便拍一张照片就是1000*2000像素的。每个像素 RGB 3个参数,一共有1000 X 2000 X 3=6,000,000。随便一张照片就要处理 600万 个参数,再算算现在越来越流行的 4K 视频。就知道这个计算量级有多恐怖了。
1.2.1 超越规则:让机器从数据中学习

CNN解决了上面的两大难题
CNN 属于深度学习的范畴,它很好的解决了上面所说的2大难点:
- CNN 可以有效的提取图像里的特征
- CNN 可以将海量的数据(不影响特征提取的前提下)进行有效的降维,大大减少了对算力的要求
1.2.2 机器学习的局限

- 机器学习算法善于处理低维、分布相对简单的数据
- 对于类别特征分布来说,同类数据特征距离远,异类距离近。
- 图像数据在几十万维的空间中以复杂的方式“缠绕”在一起,常规的机器学习算法难以处理这种复杂数据分布。
1.2.3 传统方法:设计图像特征

在计算机视觉研究和特征图像特征的早期阶段(1990s-2000),(数十万维)原始图像需要经过人工设计的算法进行特征提取与计算,从而转换为特征向量,再通过机器学习算法对特征向量进行分类处理。
至今为止特征没有万能和精确的定义。特征的精确定义往往由问题或者应用类型决定。特征是一个数字图像中“有趣”的部分,它是许多计算机图像分析算法的起点。因此一个算法是否成功往往由它使用和定义的特征决定。因此特征检测最重要的一个特性是“可重复性”:同一场景的不同图像所提取的特征应该是相同的。
人工设计图像特征检测与提取算法有,以下分类:
1.边缘检测
2.角检测
3.区域检测
4.脊检测
- 其中特征描述子有:SIFT、SURF、GLOH、HOG
方向梯度直方图(英語:Histogram of oriented gradient,简称HOG)是应用在计算机视觉和图像处理领域,用于目标检测的特征描述器。這項技术是用来计算局部图像梯度的方向信息的统计值。这种方法跟边缘方向直方图(edge orientation histograms)****、尺度不变特征变换(scale-invariant feature transform descriptors)以及形状上下文方法( shape contexts)有很多相似之处,但与它们的不同点是:HOG描述器是在一个网格密集的大小统一的细胞单元(dense grid of uniformly spaced cells)上计算,而且为了提高性能,还采用了重叠的局部对比度归一化(overlapping local contrast normalization)技术。
对于一个好的图像特征,至少要有以下要求:
- 1.能够极大简化数据表达
2.能够保留内容相关信息
1.3 深度学习
1.3.1 特征工程的天花板

- 在 ImageNet 图像识别挑战赛里,2010 和 2011 年的冠军队伍都使用了经典的视觉方法,基于手工设计的特征 + 机器学习算法实现图像分类,Top-5 错误率在 25% 上下
- 受限于人类的智慧,手工设计特征更多局限在像
素层面的计算,丢失信息过多,在视觉任务上的
性能达到瓶颈
1.3.2 从特征工程到特征学习

特征工程
特征工程本质是一项工程活动,它目的是最大限度地从原始数据中提取并加工特征以供模型或者算法使用。在传统机器学习领域流传着这样一句话: “数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”,从而可见特征工程的重要性。其实对于结构化数据建模,即使用深度学习模型,特征工程也是比模型本身要重要的特征学习
特征学习可以分为监督特征学习和无监督特征学习:
监督特征学习包括监督字典学习、神经网络、多层感知机;无监督特征学习包括无监督字典学习、主成分分析、独立成分分析、自编码器、矩阵分解和各种形式的聚类算法。
监督特征学习
监督字典学习
字典学习是从输入数据中学习一组代表元素的字典,其中每个数据都可以表示为代表元素的加权和。通过最小化带有L1正则项的平均误差来确定字典元素和权重,并保证权重稀疏。
监督字典学习利用输入数据和标签的隐含结构来优化字典元素。神经网络
神经网络是用来描述一系列学习算法,通过相互关联的节点构成的多层网络。它是受神经系统的启发,其中节点可以看做是神经元,边可以看成是突触。每个边都有相对应的权重,网络定义了计算规则,将数据从输入层传递到输出层。
多层神经网络可以用来进行特征学习,因为它们可以学习在隐藏层中的输出的表示
1.3.3 层次化特征的实现方式

层次化特征能够最大程度地保证提取图像特征信息,可实现的方式可以通过卷积和多头注意力来进行特征提取。
- 通过卷积进行层次化特征提取的结构就称为卷积神经网络,卷积后得到的结果是
- 1.特征和图像一样具有二维空间结构
- 2.后层特征为空间领域内前层特征的加权求和
- 通过多头注意力实现特征提取的结构就称为Transformer。
- 以上两种结构和方式均是神经网络目前应用比较广泛的方向,且各具有其代表性。
1.3.4 AlexNet的诞生&深度学习时代的开始

2012年,AlexNet横空出世。这个模型的名字来源于论文第一作者的姓名Alex Krizhevsky [1]。AlexNet使用了8层卷积神经网络,并以很大的优势赢得了ImageNet 2012图像识别挑战赛。它首次证明了学习到的特征可以超越手工设计的特征,从而一举打破计算机视觉研究的前状。
1.4 课程内容

- 1.模型设计
- 2.模型学习
2.模型设计
2.1.卷积神经网络

2.1 .1 AlexNet (2012)

AlexNet 模型包含 6 千万个参数和 65 万个神经元,包含 5 个卷积层,其中有几层后面跟着最大池化(max-pooling)层,以及 3 个全连接层,最后还有一个 1000 路的 softmax 层。为了加快训练速度,AlexNet 使用了 Relu 非线性激活函数以及一种高效的基于 GPU 的卷积运算方法。为了减少全连接层的过拟合,AlexNet 采用了最新的 “Dropout”防止过拟合方法,该方法被证明非常有效。
2..1.2 Going Deeper (2012~2014)

在AlexNet经过验证后,延伸出来的网络也开始往更深度、更深层的方向去发展。
- VGG-19:(19层) 准确率:92.7%
- GoogleLeNet:(22层)准确率:93.4%
2.1.3 VGG (2014)

VGG,它的名字来源于论文作者所在的实验室Visual Geometry Group [1]。VGG提出了可以通过重复使用简单的基础块来构建深度模型的思路。
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为3×3的卷积层后接上一个步幅为2、窗口形状为2×2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。我们使用
vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量num_convs和输出通道数num_channels。与AlexNet和LeNet一样,VGG网络由卷积层模块后接全连接层模块构成。卷积层模块串联数个
vgg_block,其超参数由变量conv_arch定义。该变量指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的一样。

2.1.4 GoogLeNet (Inception v1, 2014)

在2014年的ImageNet图像识别挑战赛中,一个名叫GoogLeNet的网络结构大放异彩 [1]。它虽然在名字上向LeNet致敬,但在网络结构上已经很难看到LeNet的影子。
GoogLeNet中的基础卷积块叫作Inception块,得名于同名电影《盗梦空间》(Inception)。
Inception块里有4条并行的线路。前3条线路使用窗口大小分别是1×1、3×3和5×5的卷积层来抽取不同空间尺寸下的信息,其中中间2个线路会对输入先做1×1卷积来减少输入通道数,以降低模型复杂度。第四条线路则使用3×3最大池化层,后接1×1卷积层来改变通道数。4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维上连结,并输入接下来的层中去。
Inception块中可以自定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。

2.1.5 卷积神经网络优化
2.1.5.1 精度退化问题

随着深度学习与神经网络的迭代发展,出现了众多了网络模型结构,但是随之出现的问题是,当模型层数增加到一定程度后,模型分类的正确率不增反而降低了。
2.1.5.2 实验的反直觉

精度退化问题看起来有些反直觉,但实验表明,当卷积退化为恒等映射时,深层网络与浅层网络相同,所以深度网络至少应具备不差于浅层网络的分类精度,这样深层网络的叠加才能发挥作用。
同时,也可以进一步得到一个猜想:虽然深层网络有潜力达到更高的精度,但常规的优化算法难以找到这个更优的模型,也即让新增加的卷积层拟合一个近似恒等映射,恰好可以让浅层网络变好一点。
2.1.5.3 残差学习的基本思路

- 让我们先思考一个问题:对神经网络模型添加新的层,充分训练后的模型是否只可能更有效地降低训练误差?
理论上,原模型解的空间只是新模型解的空间的子空间。也就是说,如果我们能将新添加的层训练成恒等映射f(x)=x,新模型和原模型将同样有效。由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。然而在实践中,添加过多的层后训练误差往往不降反升。即使利用批量归一化带来的数值稳定性使训练深层模型更加容易,该问题仍然存在。针对这一问题,何恺明等人提出了残差网络(ResNet)。它在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。残差建模:让新增加的层拟合浅层网络与深层网络之间的差异,更容易学习梯度可以直接回传到浅层网络监督浅层网络的学习没有引入额外参入,让参数更有效贡献到最终的模型中。

2.1.6 残差网络ResNet(2015)

ResNet沿用了VGG全\(3\times 3\)卷积层的设计。残差块里首先有2个有相同输出通道数的\(3\times 3\)卷积层。
每个卷积层后接一个批量归一化层和ReLU激活函数。
然后我们将输入跳过这2个卷积运算后直接加在最后的ReLU激活函数前。
这样的设计要求2个卷积层的输出与输入形状一样,从而可以相加。如果想改变通道数,就需要引入一个额外的\(1\times 1\)卷积层来将输入变换成需要的形状后再做相加运算。

ResNet可以有效的消除卷积层数增加带来的梯度弥散或梯度爆炸问题。
在ResNet-34结构中
- 结构共分为5级,每级包含若干残差模块,不同残差模块个数不同 ResNet 结构
- 每级输出分辨率减半,通道倍增
- 全局平均池化压缩空间维度
- 单层全连接层产生类别概率
ResNet通过改变学习目标,即由学习完整的输出变为学习残差,解决了传统卷积在信息传递时存在的信息丢失核损耗问题,通过将输入直接绕道传递到输出,保护了信息的完整性。此外学习目标的简化也降低了学习难度。

2.1.6.1 ResrNet中的两种残差模块

ResNet有两种残差模块,Basic block和Bottleneck block:
- Basic block
- Basic block为ResNet中的一种网络结构,BasicBlock包含了残差支路和一个short-cut支路,由于比传统卷积结构多了一个short-cut支路用于传递低层信息,使得网络能够训练地很深。
- BasicBlock架构主要使用了两个3*3的卷积,然后进行BN(BatchNorma2d),再将特征传递给ReLU。
- Bottleneck
Bottleneck由1x1,3x3,1x1 三个convolutions构成,其中1x1卷积层的作用是先减少再恢复维度,3x3层是较小输入/输出维度的瓶颈。Bottleneck用于特征降维,减少特征图的层数,减少参数量从而减少计算量。(一般在网络较深时才使用bottleneck结构,如ResNet18 ResNet34用BasicBlock,而ResNet50 ResNet101用Bottleneck)
2.1.6.2 ResNet的成就和影响力

《Deep Residual Learning for Image Recognition》在 2016 年拿下了计算机视觉顶级会议 CVPR 的最佳论文奖,相比 NeurIPS 最高热度论文《Attention is All You Need》,ResNet 的被引数多出了几倍。这一工作的热度如此之高,不仅是因为 ResNet 本身的久经考验,也验证了 AI 领域,特别是计算机视觉如今的火热程度。
2.1.6.3 ResNet是深浅模型的集成

对于神经网络结构来说,ResNet相当于是深层模型与浅层模型的集成,等同于多模型集成。
- 残差网络有 $O(2^𝑛) $个隐式的路径来连接输入和输出,每添加一个块会使路径数翻倍
2.1.6.4 残差连接让损失曲面更平滑

所谓残差连接指的就是将浅层的输出和深层的输出求和作为下一阶段的输入,这样做的结果就是本来这一层权重需要学习是一个对\(x\)到\(f(x)\)的映射。那使用残差链接以后,权重需要学习的映射变成了\(x->f(x)-x\) ,这样在反向传播的过程中,小损失的梯度更容易抵达浅层的神经元。其实残差连接可以看成一种特殊的跳跃连接。
2.1.6.5 ResNet的后续改进

关于ResNet的后续改进有这些系列
- ResNet B/C/D:残差模块的局部改进
- RseNext:使用分组卷积,降低参数量
- SEResNet:在通道维度引入注意力机制
2.2 更强的图像分类模型
除了以上的图像分类模型,目前研究学者在前人的基础上也发展出了更强更有效的图像分类模型,例如NAS、Vision Transformer、ConvNeXt等。
2.2.1 神经结构搜索 Neural Architecture Search (2016+)

对于深度学习说,超参数主要可为两类:一类是训练参数(如learning rate,batch size,weight decay等);另一类是定义网络结构的参数(比如有几层,每层是啥算子,卷积中的filter size等),它具有维度高,离散且相互依赖等特点。前者的自动调优仍是HO的范畴,而后者的自动调优一般称为网络架构搜索(Neural Architecture Search,NAS)。这些年来大热的深度神经网络,虽然将以前很另人头疼的特征提取自动化了,但网络结构的设计很大程度上还是需要人肉,且依赖经验。每年各AI顶会上一大批论文就是在提出各种新的更优的网络子结构。一个自然的诉求就是这个工作能否交给机器来做。
本质上网络架构搜索,和围棋类似,是个高维空间的最优参数搜索问题。
NAS的套路大多是这样的:先定义搜索空间,然后通过搜索策略找出候选网络结构,对它们进行评估,根据反馈进行下一轮的搜索
2.2.2 Vision Transformers (2020+)

2022 年,Vision Transformer (ViT) 作为卷积神经网络 (CNN) 的竞争替代品出现,卷积神经网络(CNN) 目前是计算机视觉领域的最先进技术,因此广泛用于不同的图像识别任务。ViT 模型在计算效率和准确性方面优于当前最先进的 (CNN) 近 4 倍。
CNN 和 ViT 的区别(ViT vs. CNN)
与卷积神经网络 (CNN) 相比,Vision Transformer (ViT) 取得了显着的效果,同时获得了更少的预训练计算资源。与卷积神经网络 (CNN) 相比 , Vision Transformer ( ViT ) 表现出普遍较弱的归纳偏差,导致在对较小数据集进行训练时增加对模型正则化或数据增强(AugReg) 的依赖。 ViT 是基于最初为基于文本的任务设计的转换器架构的可视化模型。
ViT 模型将输入图像表示为一系列图像块,就像使用文本转换器时使用的一系列词嵌入一样,并直接预测图像的类标签。当对足够的数据进行训练时,ViT 表现出非凡的性能,打破了类似的最先进 CNN 的性能,计算资源减少了 4 倍。
这些转换器在 NLP 模型方面具有很高的成功率,现在也应用于图像识别任务。CNN 使用像素阵列,而 ViT 将图像拆分为视觉标记。视觉变换器将图像分成固定大小的块,正确地嵌入每个块,并将位置嵌入作为变换器编码器的输入。
此外,在计算效率和准确性方面, ViT 模型的性能几乎是 CNN 的四倍。 ViT 中的自注意力层使得在整个图像中全局嵌入信息成为可能。该模型还学习训练数据以编码图像块的相对位置以重建图像的结构。
Transformer编码器包括:
- 多头自注意力层 (MSP):该层将所有注意力输出线性连接到正确的维度。许多注意力头有助于训练图像中的局部和全局依赖性。
- 多层感知器 (MLP) 层:该层包含一个带有高斯误差线性单元 (GELU) 的两层。
- Layer Norm (LN):这是在每个块之前添加的,因为它不包括训练图像之间的任何新依赖关系。因此,这有助于缩短训练时间并提高整体性能。 此外,每个块之后都包含残差连接,因为它们允许组件直接流过网络而不通过非线性激活。 在图像分类的情况下,MLP 层实现分类头。它在预训练时使用一个隐藏层,并使用一个线性层进行微调。
Read more at: https://viso.ai/deep-learning/vision-tr`ansformer-vit/
2.2.3 ConvNeXt (2022)

神经网络架构设计的创新在表征学习领域一直发挥着重要作用。卷积神经网络架构(ConvNet)对计算机视觉研究产生了重大影响,使得各种视觉识别任务中能够使用通用的特征学习方法,无需依赖人工实现的特征工程。近年来,最初为自然语言处理而开发的 transformer 架构因其适用于不同规模的模型和数据集,在其他深度学习领域中也开始被广泛使用。
ConvNeXt 架构的出现使传统的 ConvNet 更加现代化,证明了纯卷积模型也可以适应模型和数据集的规模变化。然而,要想对神经网络架构的设计空间进行探索,最常见方法仍然是在 ImageNet 上进行监督学习的性能基准测试。`2.3 图像分类 & 视觉基础模型的发展

2.4 轻量化卷积神经网络

2.4.1 卷积的参数量

深度模型轻量化方法主要分成五大类:
网络剪枝、网络量化、低秩分解、知识蒸馏和轻量化网络设计。
- 网络剪枝是指对训练好的模型进行参数去冗余,即剪去贡献较小的参数;
- 低秩分解是将原先稠密的满秩矩阵表示为若干个低秩矩阵的组合,低秩矩阵又可以分解为小规模矩阵的乘积,从而精简卷积过程;
- 网络量化是指使用位数更少的浮点数来存储网络参数, 使得网络占用存储空间得到减少,在工程应用中被广泛应用;
- 知识蒸馏也称教师-学生网络, 是将一个预先训练好的教师网络作为监督信号来训练一个简化的学生网络,使得轻量级的学生网络能够达到或接近教师网络的精度。
- 以上四种方法均是基于预先训练好的大网络,对大网络进行精简,另外一种常见的网络简化方法是轻量化网络设计,即直接重新设计一个简化的轻量级网络并从头进行训练,轻量化网络设计主要通过是优化网络结构,优化卷积方式等方法来减少参数量和计算量,降低网络的资源消耗,提升运行速度,如今最常见的轻量级网络主要有谷歌的 MobileNet 系列,旷世科技的 ShuffleNet 系列和 SqueezeNet 等。
专注于目标检测的轻量级网络主要是将用于分类的轻量级网络作为目标检测网络的骨干网络,对于轻量 级目标检测有许多进一步的改进,如 FGHDet,IR-YOLO,MTYOLO等
2.4.2 卷积的计算量(乘加次数)

对于卷积层而言,卷积层的可学习参数包括:卷积核+偏置值。
参数量计算公式:\(C^{'}\times(C\times K \times K + 1)= C^{'}CK^{2} + C^{'}\)
其中\(C^{'}\)为\(C\)通道的卷积核\(K\)个数
输出特征图每个通道上的每个值都是输入特征图和1个C通道的卷积核进行卷积的结果。
乘加次数计算公式:
\(H^{'} \times W^{'} \times C^{'} \times (C \times K \times K) = H^{'}W^{'}C^{'}CK^{2}\).
(HxWxC,分别表示高,宽和通道数。)FLOPs = paras * H * W
其中的H和W分别为feature map的尺寸。
区分FLOPS和FLOPs
- FLOPS 注意全部大写 是floating point of per second的缩写,意指每秒浮点运算次数。可以理解为计算速度,用来衡量硬件的性能。
- FLOPs 是floating point of operations的缩写,是浮点运算次数,理解为计算量,可以用来衡量算法/模型复杂度。
2.4.3 降低模型参数量和计算量的方法

结合以上的模型参数量和计算量计算公式,我们可以看到,变量通道数\(C^{'}\)和\(C\)以及卷积核尺寸\(K\)是与其正相关的。由此,若要降低模型参数量和计算量,那么也可以通过降低其变量相应的值来减少。
- 降低通道数\(C^{'}\)和\(C\)(平方级别).
- 减少卷积核的尺寸\(K\)(平方级别)
2.4.4 轻量化网络设计
下面来看一下,一些关于轻量化网络的设计实例。
2.4.4.1 GoogLeNet 使用不同大小的卷积核

GoogLeNet的基本思路:并不是所有特征都需要同样大的感受野,在同一层中混合使用不同尺寸的特征可以减少参数量。
2.4.4.2 ResNet 使用1×1卷积压缩通道数

使用\(1 \times 1\)卷积,用于压缩通道,降低计算开销。
2.4.4.3 可分离卷积

传统的卷积神经网络在计算机视觉领域已经取得了非常好的成绩,但是依然存在一个待改进的问题—计算量大。
当卷积神经网络应用到实际工业场景时,模型的参数量和计算量都是十分重要的指标,较小的模型可以高效地进行分布式训练,减小模型更新开销,降低平台体积功耗存储和计算能力的限制,方便部署在移动端。
因此,为了更好地实现这个需求,在卷积运算的基础上,学者们提出了更为高效的可分离卷积。
可分离卷积:空间可分离卷积和深度可分离卷积
(假设feature的size为[channel,height,width])
空间也就是指:[height,width]这两个维度组成的
深度也就是指:channel这一维度
空间可分离卷积
空间可分离卷积:将n×n的卷积分成1×n和n×1两步计算.
- 普通的3×3卷积在一个5×5的feature map上的计算方式如下图,需9×9次乘法。

空间可分离卷积计算方式如下图,(1)先使用3×1的filter,所需计算量为15×3;(2)使用过1×3的filter,所需计算量为9×3;总共需要72次,小于普通卷积的81次乘法。
从卷积来看,可将常规卷积分解为逐层卷积和逐点卷积,降低参数量和计算量。深度可分离卷积
Conventional Convolution
假设输入层为64×64像素的RGB图像。
常规卷积:每个卷积核是同时操作输入图片的每个通道。
卷积层的参数数量为4×3×3×3


- **Depthwise Convolution** - Depthwise Convolution:一个卷积核负责一个通道,卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。 卷积层参数数量为3×3×3 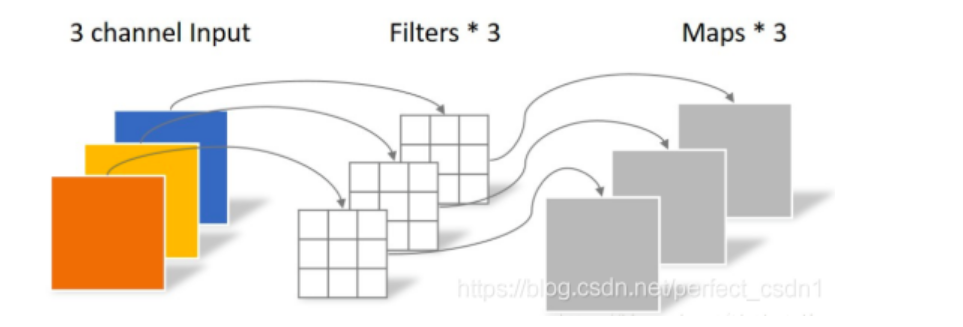 缺点: (1)无法扩展Feature map的通道数。 (2)未有效利用不同通道在相同空间位置上的feature信息。 - **Pointwise Convolution** Pointwise Convolution:与常规卷积运算相似,但卷积核尺寸为 1×1×M,M为上一层的通道数。 将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。 卷积层参数数量为1×1×3×4 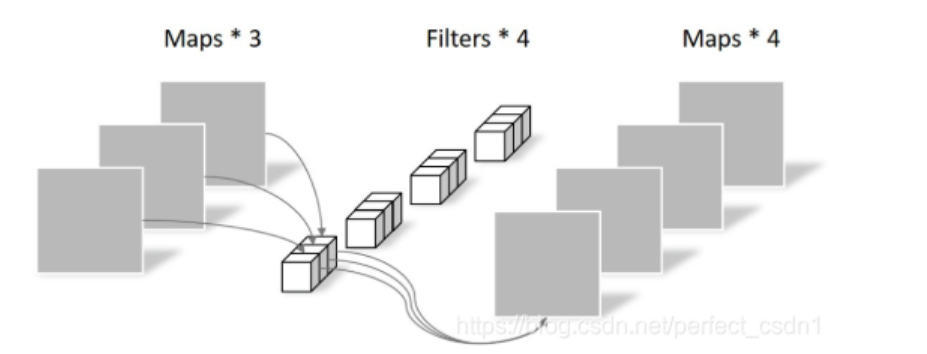
2.4.4.4 MobileNet V1/V2/V3 (2017~2019)

MobilenetV1
论文地址:1704.04861.pdf (arxiv.org)
- 引入了深度可分离卷积
- 直筒结构(网络结构)
MobileNetV1网络主要思路就是深度可分离卷积的堆叠。
MobilenetV2
论文地址:[1801.04381] MobileNetV2: Inverted Residuals and Linear Bottlenecks (arxiv.org)
上图中,MobilenetV2 unit包含stride=1和stride=2两种。
- 引入了bottleneck结构。
- 将bottleneck结构变成了纺锤型,即resnet是先缩小为原来的1/4,再放大,他是放大到原来的6倍,再缩小。
- 并且去掉了Residual Block最后的ReLU
MobilenetV3
论文地址:https://arxiv.org/abs/1905.0224上图中,MobilenetV3 unit包含stride=1和stride=2两种。
- 引入SE结构
- 修改网络尾部结构
- 修改channel数量
- 非线性变换的改变
2.4.4.5 ResNeXt 中的分组卷积

ResNeXt是ResNet和Inception的结合体,不同于Inception v4的是,ResNext不需要人工设计复杂的Inception结构细节,而是每一个分支都采用相同的拓扑结构。ResNeXt的本质是分组卷积,通过变量基数(Cardinality)来控制组的数量。
- ResNeXt将ResNet的bottleneck block中\(3 \times 3\)的卷积改为分组卷积,降低模型计算量。
- 可分离卷积为分组卷积的特殊情形,组数=通道数
2.5 Vision Transformers

2.5.1 注意力机制 Attention Mechanism

实现层次化特征:
后层特征是空间邻域内的前层特征的加权求和
权重越大,对应位置的特征就越重要在传统卷积中,卷积是可学习的参数,但与输入无关,只能建模局部关系,远距离关系只能通过多层卷积实现。
引入注意力机制后,权重可以是输入的函数,
可以不局限于邻域,显式建模远距离关系。
2.5.2 Why Attention

在深度学习领域,模型往往需要接收和处理大量的数据,然而在特定的某个时刻,往往只有少部分的某些数据是重要的,这种情况就非常适合Attention机制发光发热。
举个例子,上图展示了一个机器翻译的结果,在这个例子中,我们想将"who are you"翻译为"你是谁",传统的模型处理方式是一个seq-to-seq的模型,其包含一个encoder端和一个decoder端,其中encoder端对"who are you"进行编码,然后将整句话的信息传递给decoder端,由decoder解码出"我是谁"。在这个过程中,decoder是逐字解码的,在每次解码的过程中,如果接收信息过多,可能会导致模型的内部混乱,从而导致错误结果的出现。
2.5.3 实现 Attention

- input, output, query, key, value 均为 3D 特征图,特征维度未画出
- \(W_{key}\), \(𝑊_{query}\), \(𝑊_{value}\)是可学习参数,可由1×1的卷积实现
- query 和 key, value 如果出自同一个特征图则称为自注意力
2.5.4 Attention应用
2.5.4.1 多头注意力 Multi-head (Self-)Attention

使用不同参数的注意力头产生多组特征,沿通道维度拼接得到最终特征,从而构成Transformer Encoder 的核心模块
2.5.4.2 1D 数据上的 Attention

输入特征序列->自注意力层->输出特征序列。
2.5.4.3 Vision Transformer (2020)

- 将图像切分成若干 16×16 的小块,当作一列"词向量",经多层 Transformer Encoder 变换产生特征
- 图块之外加入额外的 token,用于 query 其他 patch 的特征并给出最后分类
- 注意力模块基于全局感受野,复杂度为尺寸的 4 次方
2.5.4.4 Swin Transformer (ICCV 2021 best paper)

Vision Transformer 的特征图是是直接下采样 16 倍
得到的,后面的特征图也是维持这个下采样率不变,
缺少了传统卷积神经网络里不同尺寸特征图的层次化
结构。所以,Swin Transformer 提出了分层结构
(金字塔结构)Hierarchical Transformer。同时,相对于 Vision Transformer 中直接对整个特征
图进行 Multi-Head Self-Attention,Swin
Transformer 将特征图划分成了多个不相交的区域
(Window),将 Multi-Head Self-Attention 计算
限制在窗口内,这样能够减少计算量的,尤其是在浅
层特征图很大的时候。

- 由于将 Multi-Head Self-Attention 计算限制在窗口内,窗口与窗口之间无法进行信息传递。所以, Swin Transformer 又提出了 Shifted Windows Multi-Head Self-Attention (SW-MSA) 的概念,即第 𝑙 + 1 层的窗口分别向右侧和下方各偏移了半个窗口的位置。那么,这就让信息能够跨窗口传递。

- 通过 4 个 Stage 构建不同大小的特征图
- 重复堆叠 Swin Transformer Block:这里的 Block 有两种结构,如图 (b) ,一个使用了 W-MSA 结
构,一个使用了 SW-MSA 结构。这两个结构成对使用,所以堆叠 Swin Transformer Block 的个数
都是偶数。
3.模型学习

3.1 模型学习的范式

我们使用模型学习的目标是,确定模型\(F_{\Theta}\)的具体形式后,找寻最优参数\(\Theta^{*}\) ,使得模型\(F_{\Theta^{*}}(X)\)给出准确的分类结果\(P(y|X)\).
实现模型学习的范式有两种:
- 范式一:监督学习
- 范式二:自监督学习

3.2 监督学习

3.2.1 监督学习介绍

监督学习是使用已知正确答案的示例来训练网络,每组训练数据有一个明确的标识或结果。 可以训练一个网络,让其从数据集中识别出对象的照片。以下就是在这个假设场景中所要采取的步骤。
- step1:数据集的创建和分类
- step2:数据增强
- step3:特征工程
- step4:构建预测模型和损失
- step5:训练
- step6:验证和模型选择
- step7:测试及应用x xx
3.2.2 交叉熵损失 Cross-Entropy Loss

交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。在信息论中,交叉熵是表示两个概率分布\(p\),\(q\)的差异,其中 \(p\)表示真实分布,\(q\)表示预测分布,那么\(H(p.q)\)就称为交叉熵:
\[H(p, q) = \sum_{i}p_{i} \cdot ln\frac{1}{q_{i}} = \sum_{i} ln_{q_{i}} \]交叉熵可在神经网络中作为损失函数,\(p\)表示真实标记的分布,\(q\)则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量 \(p\)与\(q\)的相似性。
交叉熵函数常用于逻辑回归(logistic regression),也就是分类(classification)。
3.2.3 优化目标 & 随机梯度下降

3.2.4 动量 Momentum SGD

3.2.5 基于梯度下降训练神经网络的整体流程

3.2.6 训练技巧的重要性

Tricks训练技巧
可以从上面这张表的对比数据看出,训练技巧的重要性。下面是一些训练技巧的总结:
Tips and tricks for Neural Networks: https://towardsdatascience.com/tips-and-tricks-for-neural-networks-63876e3aad1a
Tips For Using Dropout: https://machinelearningmastery.com/dropout-regularization-deep-learning-models-keras/
深度神经网络模型训练中的 tricks(原理与代码汇总):https://mp.weixin.qq.com/s/qw1mDd1Nt1kfU0Eh_0dPGQ
Tips and tricks for Neural Networks 深度学习训练神经网络的技巧总结(不定期更新)
https://blog.51cto.com/u_11466419/5508205
3.3 学习率与优化器策略

3.3.1 权重初始化

针对卷积层和全连接层,初始化连接权重\(W\)和偏置\(b\).
- 随机初始化
- 1.朴素方法
- 2.Xavier方法
- 3.Kaiming方法
- 用训练好的模型进行权重初始化
- 替换预训练模型的分类头,进行微调训练(finetune)。
3.3.2 学习率对训练的影响

学习率参数在训练过程中,可能会出现的情况有:学习率过低、学习率合适、学习率偏高、学习率过高。
上图是相应情况的曲线图。
- 另外需要考虑的是,在调整和设置学习率时,要考虑训练的方式和策略:
- 从头训练可使用较大的学习率,例如 0.01~0.1
- 微调通常使用较小学习率,例如 0.001~0.01
3.3.3 学习率策略
3.3.3.1 学习率策略:学习率退火 Annealing

在训练神经网络时,一般情况下学习率都会随着训练而变化,这主要是由于,在神经网络训练的后期,如果学习率过高,会造成loss的振荡,但是如果学习率减小的过快,又会造成收敛变慢的情况。
因此,如何调整学习率也是一个值得讨论的问题。目前,比较常见的学习率退火方式有如下几种:
- 按步长下降
- 按比例下降
- 按倒数下降
- 按余弦函数下降
3.3.3.2 学习率策略:学习率预热 Warmup

- 在mini-batch 梯度下降方法中,如果batch比较大的话,通常需要比较大的学习率
- 但在一开始的训练中,由于参数是随机初始化的,所以此时的梯度往往也很大
如果此时学习率也很大的话,训练将变得很不稳定- ——为了提高训练的稳定性,我们在最初几轮迭代时,采用较小的学习率,等梯度下降到一定程度之后,再恢复到初始的学习率
- 这种方法称为学习率预热 learning rate warmup
- 当预热过程结束的时候,再选择一种学习率衰减的方式来降低学习率
3.3.3.3 Linear Scaling Rule线性缩放原则

learning rate的设置应和batch_size的设置成正比,即所谓的线性缩放原则(linear scaling rule)。
- 经验性结论:针对同一个训练任务,当 batch size 扩大为原来的 𝑘 倍时,学习率也应对应扩大 𝑘 倍
- 直观理解:这样做可以保证平均每个样本带来的梯度下降步长相同
3.3.3.4 自适应梯度算法

自适应梯度算法的基本思路是,不同的参数需要不同的学习率,根据梯度的历史幅度自动调整学习率。
尽管自适应梯度算法的收敛速度更快,但其泛化性能却比SGD算法差。具体来说,自适应梯度算法在训练阶段的进展很快,但在测试数据上的表现很快就会停滞不前。但是SGD通常对模型性能的改善很慢,但可以获得更高的测试性能。对于这种泛化差距的一种经验解释是,自适应梯度算法倾向于收敛到尖锐的极小值,其局部地区的曲率较大,所以泛化性能较差,而SGD则倾向于寻找平坦的极小值,因此泛化较好。
3.4 正则化与权重衰减 Weight Decay

权重衰减weight decay,并不是一个规范的定义,而只是俗称而已,可以理解为削减/惩罚权重。从这个角度看,不论你用什么正则化方法,只要相当于削减了权重,那都可以称为\(weight dacay\)。
如果要给个定义,简单地更新权重,并每次从权重中再减去一点,形如下式,就叫权重衰减:不设\(dacay\)时,迭代时参数的更新过程可以表示为:
\[p= p - lr×d_p \]增加\(weight_dacay\)参数后表示为:
\[p = p - lr ×(d_p + p × dacay) \]这个\(p\)就叫衰减率。
3.5 早停 Early Stopping

早期停止是防止神经网络在训练时对数据过拟合的另一种机制。当我们看到训练和验证损失图开始发散时,就终止训练。这通常在以下两种情况下进行:
- 我们非常确定模型开始过拟合。
- 我们也确信,降低学习率和增加训练对模型没有帮助。
这实际上取决于机器学习研究人员如何使用这两者。在非常大的数据集上训练大型深度学习神经网络时,更常用的是使用学习率调整,使我们非常确定神经网络已经达到最优解。我们在这里不再深入讨论更多的理论细节。
3.6 模型权重处理
3.6.1 模型权重平均 EMA

一句话总结权重滑动平均(Exponential Moving Average)就是:Copy一份模型所有权重(记为\(Weights\))的备份(记为\(EMA_{weights}\)),训练过程中每次更新权重时同时也对\(EMA_{weights}\)进行滑动平均更新,训练阶段结束后用\(EMA_{weights}\)替换模型权重进行预测。
具体地,EMA的超参decay一般设为接近1的数,从而保证每次\(EMA_{weights}\)的更新都很稳定。每batch更新流程为:
\[Weights=Weights+LR*Grad \](模型正常的梯度下降)
\[EMA_{weights}=EMA_{weights}*decay+(1-decay)*Weights \](根据新\(weight\)更新\(EMA_{weights}\))
需要知道训练阶段无关\(EMA_{weights}\),它只在测试阶段时导入进行预测。
3.6.2 随机加权平均 Stochastic Weight Averaging

随机加权平均和快速几何集成非常近似,除了计算损失的部分。 SWA 可以应用于任何架构和数据集,而且都能产生较好的结果。
SGD倾向于收敛到loss的平稳区域,由于权重空间的维度比较高,平稳区域的大部分都处于边界,SGD通常只会走到这些平稳区域的边界。SWA通过平均多个SGD的权重参数,使其能够达到平稳区域的中心。
3.7 数据增强

3.7.1 数据增强 Data Augmentation

- 训练泛化性好的模型,需要大量多样化的数据,
而数据的采集标注是有成本的。- 图像可以通过简单的变换产生一系列"副本",扩
充训练数据集。- 数据增强操作可以组合,生成变化更复杂的图像
3.7.2 组合数据增强 AutoAugment & RandAugment

既然数据增强手段能够提高模型的泛化能力,那么我们自然希望通过一系列数据增强的组合获得最优的泛化效果,从而衍生出了一系列组合增强手段。
这里我们介绍其中最著名也最常用的两个手段,AutoAugment和RandAugment。
AutoAugment
AutoAugment: Learning Augmentation Policies from Data
AutoAugment 提出了一个具有较强可操作性的数据增强组合搜索方法。
- 1.使用一个 RNN 网络对数据增强空间进行采样,也就是选择一组数据增强策略和相应的参数。每组方法包含 5 个子策略组,每个子策略组包含连续的两个数据增强方法。
- 2.使用这一组数据增强策略训练某一个固定结构的神经网络,进而得到其对训练精度的增益。
- 3.将该增益作为强化学习的 reward,从而使用 Proximal Policy Optimization(PPO)强化学习算法对用于采样的 RNN 神经网络进行优化。
- 4.学习完成后,选择效果最好的 5 组策略,共计 25 个子策略组,综合而成最后的数据增强手段。
在实际使用时,对每张图片,都会随机应用这 25 个子策略组中的一组子策略进行处理。RandAugment
RandAugment: Practical automated data augmentation with a reduced search space
具体而言, RandAugment 设置了一个包含各种数据增强变换的集合,对每张图片,随机应用 K 个数据增强变换,每个变换的幅度都是预先设定的幅度(或者在预设幅度的基础上添加一个随机浮动)。
3.7.3 组合图像 Mixup & CutMix

Mixup
mixup: Beyond Empirical Risk Minimization在监督学习任务中,我们通常可以假设样本为随机变量 X,标签为随机变量 Y,我们希望做的是根据 X-Y 联合分布,优化出一个最佳的 f(x)。但现实中,我们根本无法获得 X-Y 的联合分布,具体到分类任务,也就是我们无法穷尽像素的组合与标签之间的关系,因而只能用一系列样本来拟合这一联合分布。
Mixup 这一增强手段的目的,也即在于优化 “用样本拟合联合分布” 这一步。它采用了一个十分简单的操作,将两张图片直接进行线性组合,对应的,标签也进行线性组合。其中,叠加在背景图片上的图片强度按照 Beta(a,a)分布随机采样获得,a 为超参数。
CutMix
原论文:CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
CutMix 和 Mixup 的思路一致,其目的都是为了优化“用样本拟合联合分布”的方法。但 CutMix 的作者认为,简单地将两张图片叠加是不自然的,对于分类任务虽然有一定的效果提升,但对检测等下游任务,都会导致性能的下降。
CutMix 与 Mixup 的不同之处在于,CutMix 通过裁取一张图片中的部分区域,以类似拼贴画的方式贴到另一张图片上,来实现图片的混合。其中,裁切图片的面积比例按照 Beta(a,a)分布随机采样获得,a 为超参数。
3.7.4 标签平滑 Label Smoothing

在进行多分类时,很多时候采用one-hot标签进行计算交叉熵损失,而单纯的交叉熵损失时,只考虑到了正确标签的位置的损失,而忽略了错误标签位置的损失。这样导致模型可能会在训练集上拟合的非常好,但由于其错误标签位置的损失没有计算,导致预测的时候,预测错误的概率比较大,也就是常说的过拟合。
标签平滑可以在一定程度上防止过拟合。
3.8 模型相关策略

3.8.1 丢弃层 Dropout

- 神经网络在训练时会出现共适应现象 (co-adaption),神经元之间产生高度关联,导致过拟合
- 训练时随机丢弃一些连接,破坏神经元之间的关联,鼓励学习独立的特征
- 推理时使用全部连接
- 常用于全连接层,通常不与 BN 混用
3.8.2 随机深度 Stochastic Depth

训练ResNet网络时,加入了随机变量 b(伯努利随机变量,只能取 0/1,取 0 的概率是 1−p,取 1 的
概率是 p),对整个 ResBlock 卷积部分做了随机丢弃。
- 如果 b = 1,则简化为原始的 ResNet 结构;
- 如果 b = 0,则这个 ResBlock 未被激活,降为恒等函数。
\[H_{l} = ReLU(b_{l}f_{l}H_{l-1}) + id(H_{l-1}) \]利用不同的深度训练,最终相当于潜在地融合了多个不同深度的网络,提升了性能。
3.9 自监督学习

3.9.1 自监督学习的常见类型

自监督学习主要有以下几种常见类型:
- 基于代理任务
- 基于对比学习
- 基于掩码学习
3.9.2 自监督学习的应用
3.9.2.1 Relative Location (ICCV 2015)

Relative Location的基本假设:模型只有很好地理解到图片内容,才能够预测图像块之间的关系
3.9.2.2 SimCLR (ICML 2020)

SimCLR的基本假设:如果模型能很好地提取图片内容的本质,那么无论图片经过什么样的数据增强操作,提取出来的特征都应该极为相似。
- SimCLR发现了:
- 数据扩充的组合在有效的预测任务中起着关键作用;
- 在表征和对比损失之间引入可学习的非线性变换,大大提高了学习表示的质量;
- 与有监督的学习相比,对比学习需要更大batch size和训练轮数。
3.9.2.3 Masked autoencoders (MAE, CVPR 2022)

- MAE的基本假设:模型只有理解图片内容、掌握图片的上下文信息,才能恢复出图片中被随机遮挡的内容。
本文表明,掩码自动编码器 (MAE) 是用于计算机视觉的可扩展自监督学习器。我们的 MAE 方法很简单:我们屏蔽输入图像的随机补丁并重建丢失的像素。它基于两个核心设计。首先,我们开发了一个非对称编码器-解码器架构,其中一个编码器仅对可见的补丁子集(没有掩码标记)进行操作,以及一个轻量级解码器,该解码器从潜在表示和掩码标记中重建原始图像。其次,我们发现屏蔽大部分输入图像(例如 75%)会产生重要且有意义的自我监督任务。结合这两种设计使我们能够高效且有效地训练大型模型:我们加速训练(3 倍或更多)并提高准确性。我们的可扩展方法允许学习具有良好泛化能力的高容量模型:例如,在仅使用 ImageNet-1K 数据的方法中,vanilla ViT-Huge 模型实现了最佳准确度 (87.8%)。下游任务中的迁移性能优于有监督的预训练,并显示出有前途的缩放行为。
3.10 总结

4.MMClassification

4.1 MMClassification 介绍

MMClassification 是一款基于PyTorch 的开源图像分类工具箱, 集成了常用的图像分类网络,将数据加载,模型骨架,训练调参,流程等封装为模块调用,便于在模型间进行转换和比较,也高效简洁的实现了参数调整。
4.2 Python 推理 API

4.2.1 下载配置文件和与训练权重
# 下载配置文件和与训练权重
$ mim download mmcls --config mobilenet-v2_8xb32_in1k --dest .
4.2.2 使用Python API 推理
# 使用Python API 推理
from mmcls.apis import init_model, inference_model, show_result_pyplot
model = init_model('mobilenet-v2_8xb32_in1k.py',
'mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth',
device='cuda:0')
result = inference_model(model, 'banana.png')
show_result_pyplot(model, 'banana.png', result)
# 推理结果result
{'pred_class': 'banana’,
'pred_label': 954,
'pred_score': 0.9999284744262695}
4.3 推理工具(需源码安装)

4.3.1 单张图像推理
# 单张图像推理
python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE}
4.3.2 在测试集上测试
# 在测试集上测试
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--metrics ${METRICS}] [--out
${RESULT_FILE}]
# 多机多卡
./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--metrics ${METRICS}] [--out
${RESULT_FILE}]
4.4 训练工具(需源码安装)

4.4.1 单卡训练
# 单卡训练
python tools/train.py ${CONFIG_FILE} [optional arguments]
4.4.2 单机、多机多卡训练
# 单机、多机多卡训练
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
4.4.3 使用任务调度器 Slurm 启动任务
# 使用任务调度器 Slurm 启动任务
[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
# 从 checkpoint 恢复训练
增加 --resume-from ${CHECKPOINT_FILE} 参数
4.5 使用 MIM 工具实现训练和测试

4.5.1 下载配置文件和预训练权重
mim download mmcls --config mobilenet-v2_8xb32_in1k --dest .
4.5.2 训练(支持单卡、多卡、Slurm 任务管理器)
mim train mmcls {参数同 mmcls 自己的 train.py}
mim train mmcls {参数同 mmcls 自己的 train.py} -G 4 –g 4 –p ${PARTITION} --launcher slurm
4.5.3 测试
mim test mmcls {参数同 mmcls 自己的 test.py} --gpus 4 --launcher pytorch
4.6 环境搭建

4.7 OpenMMLab 项目中的重要概念——配置文件

深度学习模型的训练涉及几个方面:
- 模型结构
- 数据集
- 训练策略
- 运行时
- 一些辅助功能

在 OpenMMLab 项目中,所有这些项目都涵盖在一个配置文件中,一个配置文件定义了一个完整的训练
过程
- model 字段定义模型
- data 字段定义数据
- optimizer、lr_config 等字段定义训练策略
- load_from 字段定义与训练模型的参数文件
config/metafile.yml

4.8 配置文件的运作方式

- 配置文件
- 模型库
- 数据文件
——> 内部模块——>工具
4.9 图像分类模型的构成

在MMClassification中,对于图像分类模型的构成,主要包含骨干网络(backbone)、颈部(neck)以及头部(head)。
4.10 图像分类模型构建

同时,分别针对主干网络、颈部和分类头,可以进行相应的配置,从而构建图像分类网络模型。
4.11 数据集构建

关于数据集,这里主要关注的是数据集是如何加载和配置的,可以通过参数进行设置。
4.12 定义数据加载流水线

data load pipeline
这里的数据加载流水线,可以根据训练或其他实际的需要,进行数据增强和归一化及转换Tensor等相关处理。
4.13 配置学习策略

网络模型定义完成,数据集构建并传入流水线中后,需要进行相应的学习策略设置。
- optimizer:优化器配置
- lr_config:学习率策略
- runner:运行器Runner
4.14 预训练模型库

如果需要基于预训练模型进行迁移学习的训练,可以去对应的Model ZOO里面下载。
5.参考材料
[1] OpenMMLab AI实战营课件
[2] 补充内容,部分来源于网络材料和论文刊物

 浙公网安备 33010602011771号
浙公网安备 33010602011771号