百度高效研发实战训练营-Step2
百度高效研发实战训练营Step2
2.1 代码的艺术
2.1.1《代码的艺术》目的解读
这门课程的目的主要有以下四点:
(1) 了解公司与学校写代码的不同
(2) 消除对于程序员这个职业的误解
(3) 建立对软件编程的正确认识
(4) 明确作为软件工程师的修炼方向
1、了解公司与学校写代码的不同
在公司写程序和在学校写程序有很大的不同,在学校写程序时,对代码的质量要求比较低,当进入公司之后,做的是工业级的产品,服务用户量可能会达到亿万级,所以与代码的质量要求比较高,一些伟大产品中的代码,甚至可能被称为是艺术品。
2、消除对于程序员这个职业的误解
很多人都对程序员这个职业有误解,认为程序员就是码农,认为程序员35岁之后会面临失业问题,还有人认为程序员未来的唯一出路是做管理,希望通过接下来的学习,可以对于程序员有一个新的认识,从而消除误解。
3、建立对软件编程的正确认识
在做一件事物时,我们常说要“知”“行”合一,即我们需要对这件事物有一个正确的认识,才会有正确的行动。同理,写出好代码的前提,是对软件编程有正确的认识。
4、明确作为软件工程师的修炼方向
明确作为软件工程师的修炼方向,艺术品是由艺术家创造的,艺术家的修炼是有方式方法的,同样软件工程师的修炼也是有方法的,希望通过接下里的内容,能够对软件工程师这个职业有一个全新的认识。
2.1.2 代码与艺术之间的关系
1、代码是可以被称为艺术的
我们知道,艺术是多种多样的、丰富多彩的。同时,艺术也是有多个层次的。
想象一下我们编写的代码,我们的脑海中也会有类似的感觉,艺术就是人类通过借助特殊的物质材料与工具,运用一定的审美能力和技巧,在精神与物质材料,心灵与审美对象的相互作用下进行的,充满激情与活力的创造性劳动,可以说它是一种精神文化的创造行为,是人的意识形态和生产形态的有机结合体。
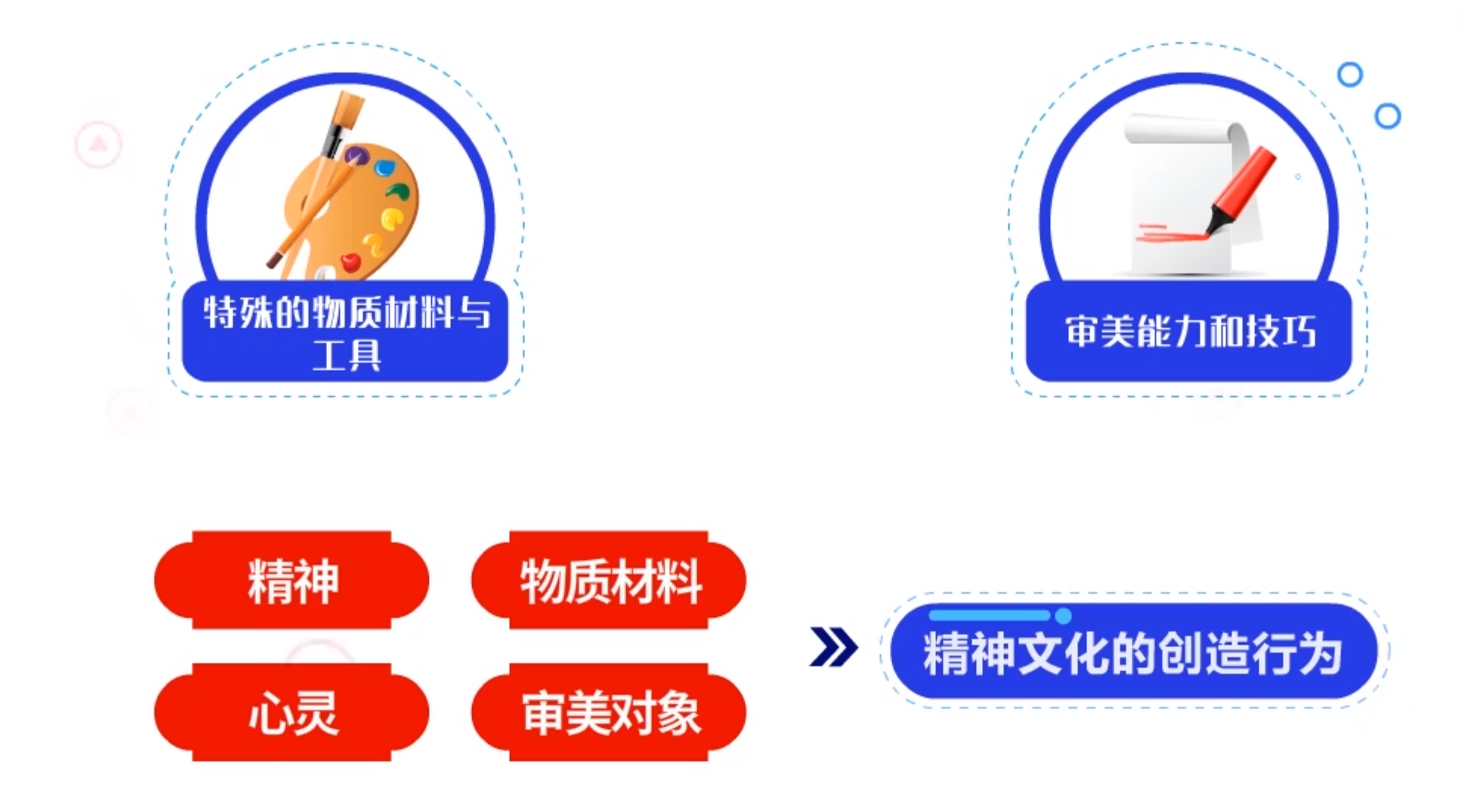
同样,写代码也要经历这样的一个过程,在编写代码的过程中,我们借助的物质是计算机系统,借助的工具是设计、编写、编译、调试、测试等,同样编写代码需要激情,而且编写代码是一件非常具有创造性的工作,总之,代码是人类智慧的结晶,代码反映了一个团队或一个人的精神。

代码是可以被称为艺术的!
2、艺术可以从不同的角度进行解读、研究与创造

达芬奇有多幅著名的画作,那著名的《蒙娜丽莎》这幅画来举例,站在观众的角度,可能只是在欣赏画中的人物微笑,但是对于画家来说,可能就会考虑画画的手法、构图、光线明暗、色彩对比等等方面。

同样,在《达芬奇自画像》这幅画作中,光有这个人物还不够,我们还要通过这个人物的个性与背景等等因素来揣摩这幅画作。

综上所述,在艺术方面,我们可以站在很多不同的角度进行解读,但是如果要成为一名创作者,我们需要的不仅仅是欣赏的能力,更重要的是从多角度进行解读、研究与创造的能力。
3、写代码如同艺术创作
写代码就如同艺术创作一般,并不是一件容易的事,写代码的内涵是:
- ①写代码这个过程,是一个从无序到有序的过程。
- ②写代码需要把现实问题转化为数学问题。在写代码的过程中,我们需要有很好的模型能力。
- ③写代码实际上是一个认识的过程。很多时候,编码的过程也是我们认识未知问题的过程。
- ④在写代码的过程中,我们需要综合的全方位的能力。包括把握问题的能力、建立模型的能力、沟通协助的能力、编码执行的能力等等。
- ⑤在写好代码之前,首先需要建立编码品味。品味是指我们首先要知道什么是好的代码,什么是不好的代码。这样我们才能去不断地调整自己的行为,然后去学习,去提高我们的编码能力,写出具有艺术感的代码。
2.1.3 软件工程师不等于码农
软件工程师不能只会写代码,更需要具有综合的素质。这个综合的素质包括:
(1)技术
技术能力是基础。包括但不限于编码能力、数据结构和算法能力、系统结构知识、操作系统知识、计算机网络知识、分布式系统知识等等。
(2)产品
要对产品业务有深刻的理解,需要了解产品交互设计、产品数据统计、产品业务运营等。
(3)其他
要了解一些管理知识,需要知识项目是怎么管理的,如何去协调多个人一起去完成一个项目,如何去协调多个人一起去完成一个项目。有一些项目需要具有很强的研究和创新方面的能力。
以上这些能力素质,是一个软件工程师需要具有的综合素质,要成为一个全部掌握这些素质的系统工程师,至少需要8~10年的时间,所以软件工程师绝对不是一个只会简单编写代码就可以的职业。
软件工程师不等于码农。
2.1.4 正确认识代码实践方面的问题
代码实践方面的问题,重点包括以下三个方面:
1、什么是好的代码,好的代码有哪些标准

好代码的标准是:
- 高效(Fast)
- 鲁棒(Solid and Robust)
- 简洁(Maintainable and Simple)
- 简短(Small)
- 可共享(Re-usable)
- 可测试(Testable)
- 可移植(Portable)
- 可监控(Monitorable)
- 可运维(Operational)
- 可扩展(Scalable & Extensible)
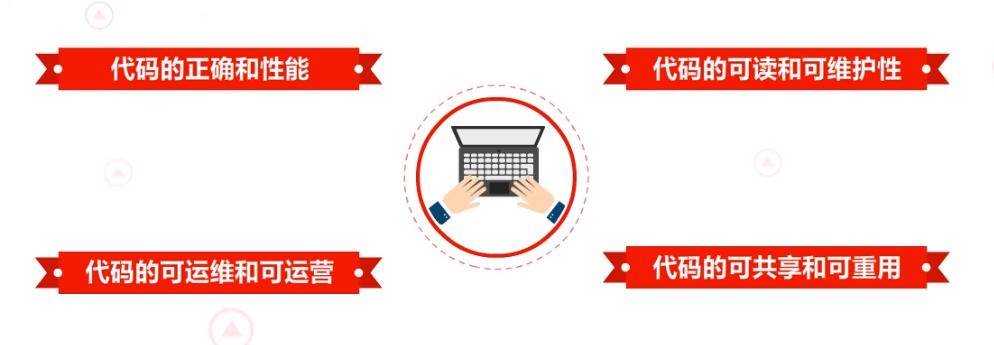
将以上十条标准进行总结精简,可以归纳为
- 1.代码的正确和性能
- 2.代码的可读和可维护性
- 3.代码的可运维和可运营
- 4.代码的可共享和可重用
了解完好代码的标准,接下来看一下不好的代码主要表现在哪些方面:

-
不好的函数名
比如在函数名中,加上my等单词,这属于很不专业的用法。 -
不好的变量名
比如看不出任何含义的a b c j k temp等变量名 -
没有注释或注释不清晰
没有注释的代码是非常难读懂的,注释不倾斜往往是因为文字功底或者描述能力欠缺,从而导致无法通过注释把代码的执行原理讲解清楚。 -
一个函数执行多个功能
比如LoadFfomFileAndCalculate()函数,它既执行了文件中去加载数据,还执行了计算功能。一般像这样的函数,我们建议把它切分成两个单独的函数。 -
不好的代码样式排版
代码样式排版在某种程度上体现了代码的一种逻辑,好的代码排版能增强代码的可读性和逻辑性,我们在写代码时,要规避不好的代码样式排版。 -
难以测试的代码
代码没法测试,就难以编写测试用例。
以上这些都是一些不好的表现。
2、好的代码从哪里来
代码不只是“写”出来的,实际上,在整个项目中,真正的编码时间约占项目整体时间的10%,好的代码是多个环节工作共同作用的结果。
这些环节包括:
- 1.在编码前,要进行需求分析和系统设计。
- 2.在编码过程中,要注意单元测试。
- 3.在编码后,要做集成测试,要上线,要持续运营/迭代改进。
一个好的系统/产品是以上过程持续循环的结果。
下面着重介绍一下重点环节:
-
1.认识需求分析和系统设计的重要性
需求分析和系统设计在软件开发中经常被忽略或轻视,但是这两点都是非常重要的环节,人们的直觉就是拿到一个项目就想尽快把它写出来并运行,感觉这样的路径是最快的,但是实际上在前期需求分析和系统设计投入更多的成本,会在后期节省更多的消耗。也即前期更多的投入,收益往往最大。
原因是,如果我们开始的设计做错的话,那么后期开发、测试、上线、调试这些成本都会被浪费掉。 -
2.清楚需求分析和系统设计的差别
需求分析和系统设计是有泾渭分明的区别的,为了避免这两者相互混杂,我们需要清楚需求分析和系统设计各自的内涵。
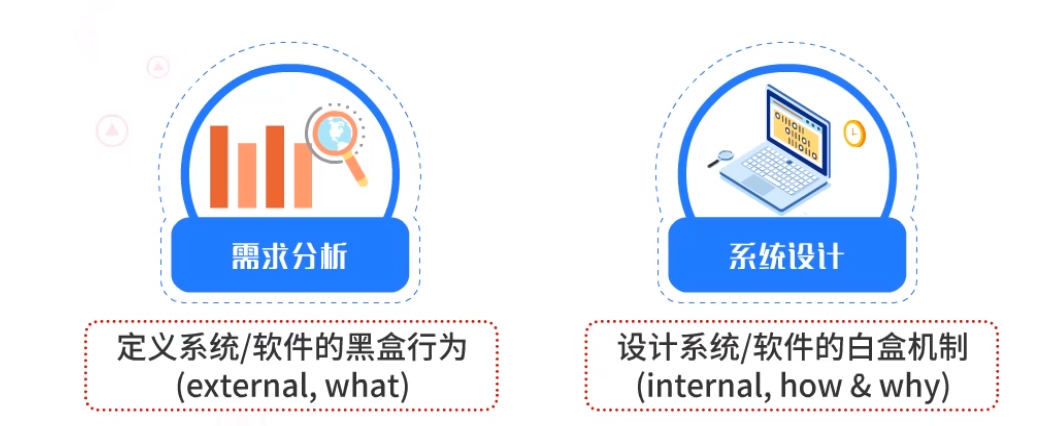
需求分析,主要是定义系统或软件的黑盒行为,即外部行为,比如系统从外部来看能够执行什么功能。
系统设计,主要是设计系统或软件的白盒机制,即内部行为,比如系统从内部来看是怎么做出来的,为什么这么做?
- 3.需求分析的注意要点
需求分析,主要有两个要点:
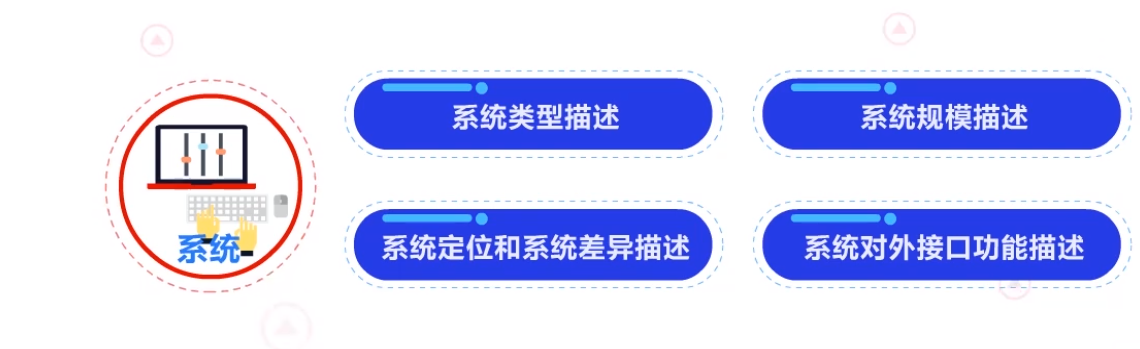
- 要点一:清楚怎么用寥寥数语勾勒出一个系统的功能。
每个系统都有自己的定位,我们可以从简洁的总体描述,展开到具体的需求描述。需求描述的内容,基本包括系统类型描述、系统规模描述、系统定位和系统差异描述、系统对外接口功能描述。
-
要点二:需求分析需要用精确的数字来描述,需求分析中会涉及到大量的数据分析,这些分析都需要精确的数字来进行支撑。
-
4.系统设计的注意要点
-
要点1:清楚什么是系统架构
系统架构(System Architectrue),在wiki上有一个英文定义,阐述了系统架构是一个概念的模型,它定义了系统的结构、行为、更多的视图,进一步解读系统架构。
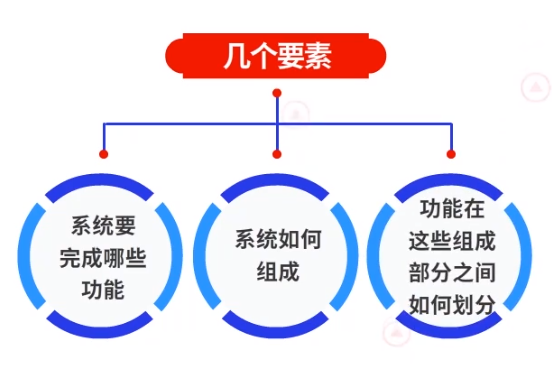
它的几个要素是,系统要完成哪些功能,系统如何组成,在这些组成部分之间如何划分。
-
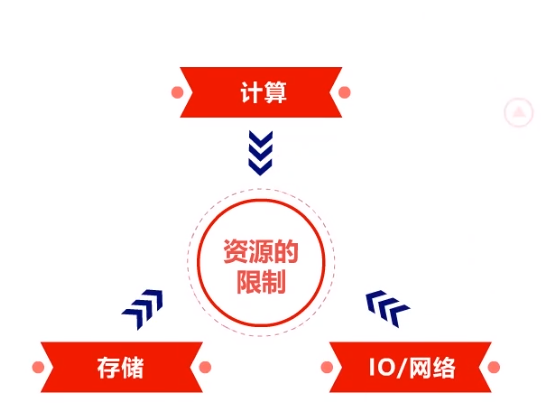
要点2:注意系统设计的约束
注意系统设计的约束,重点是资源的限制。比如计算的资源限制、存储的资源限制、IO/网络的资源限制等。
-
要点3:清楚需求是系统设计决策的来源
精确定义需求中的各个细节,以及量的定义,对系统设计的决策起着重要的作用。
-
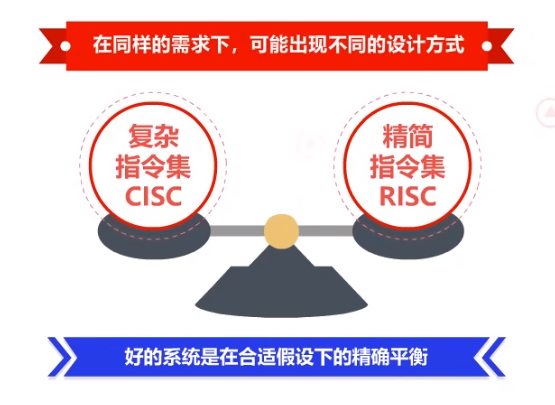
要点4:系统设计的风格与哲学
在同样的需求下,可能会出现不同的设计方式,其目的相同,设计不同。
比如复杂指令集和精简指令集的设计差异。
一个好的系统,是在合适假设下的精确平衡;一个通用的系统,在某些方面,不如专业系统的。
-
每个组件(子系统或模块)的功能都应该足够的专一和单一。(每个组件,是指子系统或模块等。)
-
功能的单一,是指复用和扩展的基础。
倘若不单一,未来就有很可能很难进行复用和扩展。 -
子系统或模块之间的关系,应该是简单而清晰的。
-
软件中最复杂的是耦合。
如果各系统之间的接口定义非常复杂,那么未来便很难控制系统的健康发展.
值得注意的是,使用全局变量就是在增加系统的耦合,从而增加系统的复杂性。所以在系统中,需要减少使用全局变量。 -
要点5:清楚接口的重要性
接口,英文名Interface,系统对外的接口比系统实现本身还要更加重要。
接口的设计开发不容忽视,接口主要包括:
1.模块对外的函数接口
2.平台对外的API
这些API很多是基于RPC或者是基于Web API来实现的
3.系统间通信的协议
4.系统间存在依赖的数据
比如:给另一个系统提供的词表
以上,这些都是接口,都需要去重视和很好的定义。
接口重要的原因在于:
1 接口定义了功能
如果定义的功能不正确,那么系统的可用性与价值便会大打折扣。2 接口决定了系统与系统外部之间的关系
相对于内部而言,外部关系确定后非常难以修改。因此接口的修改需要非常慎重且要考虑周全。
后期接口修改时,主要注意以下两点:
1 合理好用
新改的接口,应该是非常合理好用的,不能使调度方感觉我们做的接口非常难以使用。2 修改时需要向前兼容
新改的接口,应该尽量实现前项的兼容,不能出现当新接口上线时,其他程序无法使用的情况。
3、如何写好代码
关于具体怎么写代码,下面主要从两个维度来进行介绍:
(1)代码也是一种表达方式
在一个项目中,软件的维护成本远远高于开发成本,而且超过50%的项目时间都是用于沟通。常规意义的沟通方式,主要有面对面交流、Email邮件、文档或网络电话会议等。
但其实代码也是一种沟通方式,在计算机早期,我们使用机器语言或汇编语言,更多考虑代码如何更高效率地执行,然而,随着技术的进步,代码编译器逐渐完善,我们写代码时,更多的是要考虑如何让其他人看得懂、看得清楚。
于是编程规范就应运而生了,编程规范主要包含:
- 如何规范的表达代码
- 语言使用的相关注意事项
基于编程规范,看代码的理想场景是:
- 看别人的代码,感觉和看自己的代码一样。
- 看代码时能够专注逻辑,而不是格式方面。
- 看代码时不用想太多
(2)代码书写过程中的细节问题
关于代码数学过程中的细节问题,我们将从模块、类和函数、面向对象、模块内部组成、函数、代码注释、代码块、命名、系统的运营等。
(1)关于模块
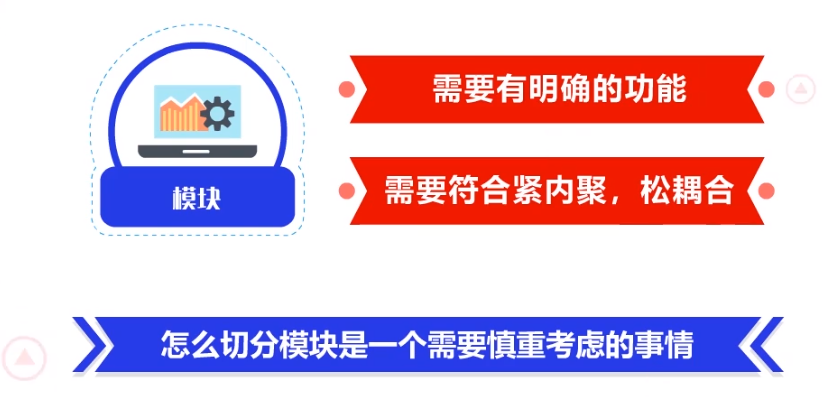
模块,是程序的基本组成单位。
在一个模块内,会涉及到它的数据,函数或类。
对于Python、Go、C语言这样的程序来说,一个后缀名为.py、.c、.go的文件就是一个模块。每一个模块需要有明确的功能,需要符合紧内聚、松耦合。
关于模块切分的是否合理,对于软件架构的稳定起着至关重要的作用。
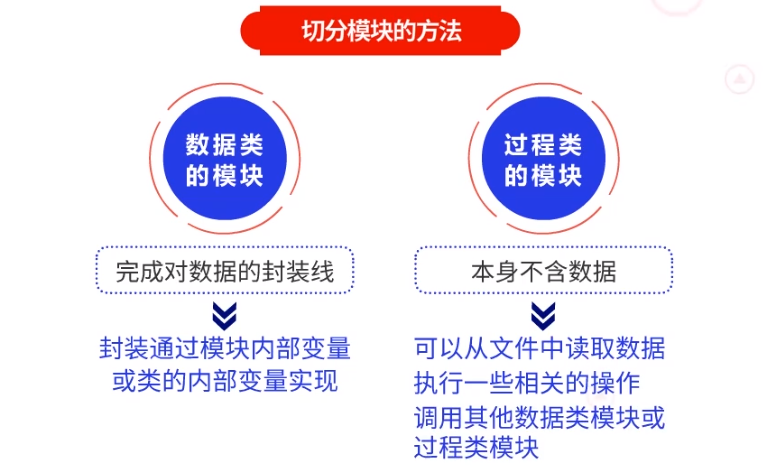
切分模块的方法,先区分数据类的模块和过程类的模块。
数据类的模块,主要是要完成对数据的封装,封装往往是通过模块内部变量,或类的内部变量来实现的。
过程类的模块,本身不含数据,可以从文件中去读取一个数据,或执行一些相关的操作。过程类模块,可以调用其他数据类模块或过程类模块。
编写程序时,我们需要注意减少模块间的耦合,从而有利于降低软件复杂性,明确接口关系。
(2)关于类和函数
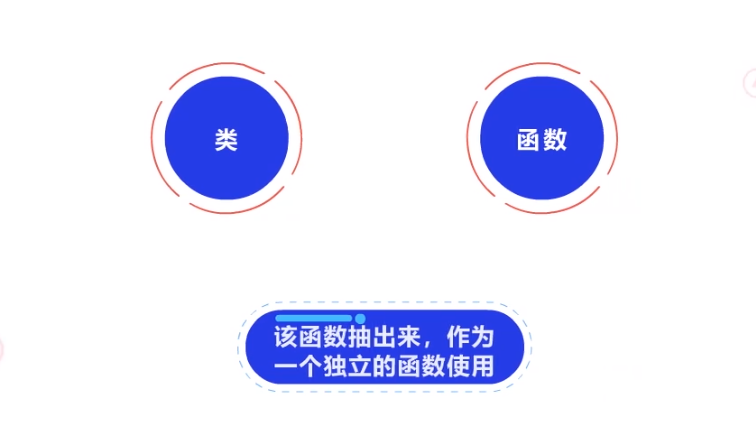
类和函数,是两种不同的类型,有它们各自适用的范围。
另外,遇见和类的成员变量无关的函数时,可以将该函数抽出来,作为一个独立的函数使用,这样便于未来的复用。
(3)关于面向对象
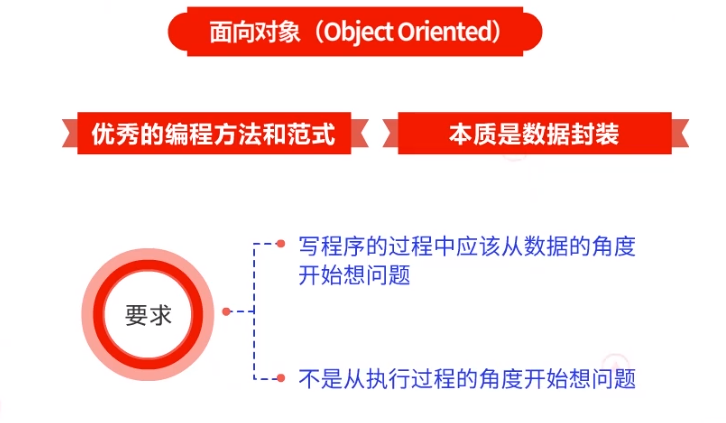
面向对象是一个优秀的编程方法和范式,但是真正理解的人并不多,面向对象的本质是数据封装,这就要求我们,在写程序的过程中应该从数据的角度开始想问题,而不是从执行过程的角度开始想问题。
同时,我们需要注意一个普遍的错误认知,即C语言是面向过程的,C++是面向对象的,实际上,C语言也是基于对象的,C和C++的区别,主要是没有多态和继承。
C++是一个经常被滥用的语言,因为C++有太强的功能,作为软件工程师,我们最重要的任务是去实现我们所需要的功能,语言只是一种解决问题的工具。
我们应该谨慎地使用多态和继承,如果一个系统中,类的继承超过三层,那么这个系统的复杂度便很难把握。
有这样一个悖论,很好的继承模型是基于对需求的准确把握,而我们的初始设计阶段往往对需求理解的透彻。
系统在初始阶段,可能只是一个很简单的原型,然后通过不断地迭代完善,才逐步发展起来变好的。
(4)关于模块内部的组成
一个模块,比如.py、.c、.go这样的模块,其内部组成主要是:

在文件头中,需要对模块的功能进行简要说明,需要把文件的修改历史写清楚,包括修改时间、修改人和修改内容。
在模块内,内容的顺序尽量保持一致,以方便未来对内容的搜索查询,
(5)关于函数
函数的切分同样十分重要。
对于一个函数来说,要有明确的单一功能。
函数描述三要素,包括功能、传入参数和返回值
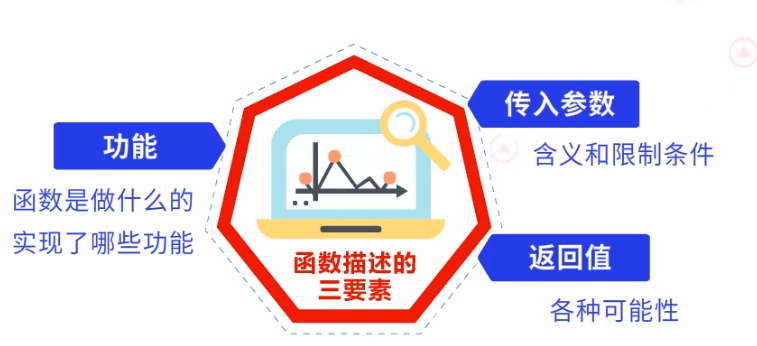
功能描述,是指描述这个函数是做什么的,实现了哪些功能。
传入参数描述,是指描述这个函数中,传入参数的含义和限制条件。
返回值描述,是指描述这个函数中,返回值都有哪些可能性。
函数的规模要足够的短小,这是写好程序的秘诀之一。
bug往往出现在那些非常长的函数里。
在函数头中,需要对函数的语义做出清晰和准确的说明。
我们需要注意函数的返回值,在写函数时,要判断函数的语义,确定返回值的类型。
基于函数的语义,函数的返回值有三种类型:
- 1.“逻辑判断型”函数
“逻辑判断型”函数,返回布尔类型的值,True或False,表示“真”或“假”。 - 2.“操作型”函数
“操作型”函数,作为一个动作,返回成功或者失败的结果——SUCCESS或ERROR。 - 3.“获取数据型”函数
在“获取数据型”函数中,返回一个“数据”或者返回“无数据/获取数据失败”。
在这里,推荐一种函数的书写方式:
以“单入口、单出口”的方式书写,这种方式能够比较清晰地反映出函数的逻辑。
尤其是在实现多线程的数据表中,推荐使用一个内部函数来实现,“单入口 单出口”的方式。
(6)关于代码注释
要重视注释。
书写注释,要做到清晰明确,在编写程序的过程中,先写注释后写代码。
(7)关于代码块
代码块的讨论范围,是在一个函数类的代码实现。
书写代码块内的思路,是先把代码中的段落分清楚,文章有段落,代码同样有段落,
代码的段落背后表达的是我们对于代码的逻辑理解,包括代码的层次、段落划分、逻辑等。
代码中的空行或空格,是帮助我们表达代码逻辑的符号,并非可有可无。
好的代码,可以使人在观看时,一眼明了。
(8)关于命名
命名,包括系统命名、子系统命名、模块命名、函数命名、变量命名、常量命名等。
我们要清楚命名的重要性,命名重要的主要原因为:
1.“望文生义”是人的自然反应。不准确的命名会使人产生误导,
2.概念是建立模型的出发点。(概念、逻辑推理=>模型体系)
好的命名是系统设计的基础。
命名中普遍存在的问题有:
1.名字中不携带任何信息
2.名字中携带的信息是错误的
命名不是一件容易的事情,关系着代码的可读性,需要仔细思考。
命名的基本要求是:准确、易懂。
提高代码命名可读性的方式之一:在名字的格式中加入下划线、驼峰等。
(9)关于系统的运营
在互联网时代,系统非常依赖运营,并不是我们把代码写完调试通了就可以,在系统运营过程中,代码的可监测性非常重要,很多程序都是通过线上的不断运行、不断监测、不断优化而迭代完善的。
所以,我们在编写代码的过程中,要注意尽可能多地暴露出可监控接口。
对于一个系统来说,数据和功能同等重要。
数据收集很重要,数据量够大才能知道这个项目或这个系统的具体收益。
关于系统的运营,我们在设计和编码阶段就需要考虑系统的运营,也就要求:
- 提供足够的状态记录
- 提供方便的对外接口
2.1.5 怎样修炼成为优秀的软件工程师
通常,人们在判断一名软件工程师的水平时,都会用工作时间、代码量、学历、曾就职的公司等等,这类外部因素作为评判标准。
但事实上,修炼成为优秀的软件工程师,重要的因素有三点:
(1)学习-思考-实践
1.多学习
- 软件编写的历史已经超过半个世纪,有太多的经验可以借鉴。
- 技术更新进步迅速,要不断的学习进步。
2.多思考
- 学而不思则罔,思而不学则殆。
- 对于做过的项目要去深入思考,复盘写心得。
3.多实践
- 知行合一谓之善,要做到知行合一,我们大部分的心得和成长,其实是来自于实践中的经历。
- 在学习和思考的基础之上,要多做项目,把学到的理论运用到真正的工作中去。
(2)知识-方法-精神
互联网的发展日新月异,对于软件开发来说,知识永远在增加。
所以在变化快速的知识世界中,最好的方式是找到方法。
方法就是用来分析问题和解决问题的,虽然说起来简单,但是适合每个人的方法都需要自己去寻找和总结。
在大多数人的成长过程中,并不单单只是鲜花和掌声,更多的是和困难荆棘做斗争,而真正能做出成就的人,都有着远大理想和宏伟志向。
所以光有知识和方法往往是不够的,还需要有精神作为支撑。
下面列出几个精神理念:
1 自由精神、独立思想
人一定要有自己的思考,不要人云亦云,不要随波逐流。
2 对完美的不懈追求
不要做到一定程度就满意了,而是要去不断的追求一个更好的结果。
(3)基础知识是根本
唐朝著名宰相魏征曾经对唐太宗说过,“求木之长者,必固其根;欲流之远者,必浚其泉源”,充分表达了基础乃治学之根本。

对于一个软件工程师来说,需要掌握的基础知识是非常繁杂的,包括以下种种:
- 数据结构、算法、操作系统、系统结构、计算机网络
- 软件工程、编程思想
- 逻辑思维能力、归纳总结能力、表达能力
- 研究能力、分析问题、解决问题的能力等
这些基础的建立,至少也要5~8年的时间。
欲速则不达,希望可以沉下心来,尤其是在自己职业生涯开始的几年,将基础打好。这样,才能在未来有更长远的发展。
2.1.6《代码的艺术》课程总结
通过这部分的学习,我们了解了公司与学校写代码有很大的不同,消除了对程序员这个职业的误解,建立了对软件编程的正确认识,明确了作为软件工程师的修炼方向。
在最后,还需要强调一下几个要点:
软件工程师不等于码农,软件工程师是一个很有深度的职业。
代码,我们可以把它携程艺术品。最终成品完全在于我们自身的修养。
不要忘记我们为什么出发。我们的目的是改变世界,而不是学习编程或炫耀技术。
好代码的来源不是写好代码,好代码是系列工作的结果。
代码是写给别人看的,别人看不懂的代码就是失败的。
写好代码是有方法的。系统工程师至少需要学习8~10年的积累。希望能够沉下心来,把基础打好,提升能力。
2.2 Mini-spider实践
本部分将从两个方面来讲解Mini-Spider框架在实际场景下的使用和注意事项等问题:
2.2.1 多线程编程
2.2.1.1 数据互斥访问
多线程中数据互斥访问的情况非常常见,在真实的生产环境中,经常会有开发人员会将对一张表的“添加”和“判断是否存在”分为两个接口,这是一种非常常见的错误。
以下图中的代码为例,左边的代码是正确的写法,将添加和判断写进一个函数中,右边的代码是典型的错误代码,编写了两个函数,分别是添加和判断函数。事实上,这种将添加和判断写进一个函数,并且运行的实现机制,是同8086的底层指令集支持密不可分的。

2.2.1.2 临界区的注意事项
在代码中,用锁来保护的区域被称为临界区。
以下图代码为例,临界区为self.lock.acquire和self.lock.release两句话之间的区域。在使用临界区的时候要注意,不要把耗费时间的操作放在临界区内执行。

很多开发人员在编写多线程的时候,会将耗费时间很多的逻辑放入临界区内,这样会导致无法发挥多线程对于硬件资源最大化利用的优势。
2.2.1.3 I/O操作的处理
在多线程编程中,还要注意对于IO操作的处理。
首先,在编写代码的时候,要注意不能出现无捕捉的exception,
以下图最左边的代码为例,如果不对异常进行捕捉,那么一旦出现问题,就不会执行self.lock.release()语句,进而导致死锁的发生。
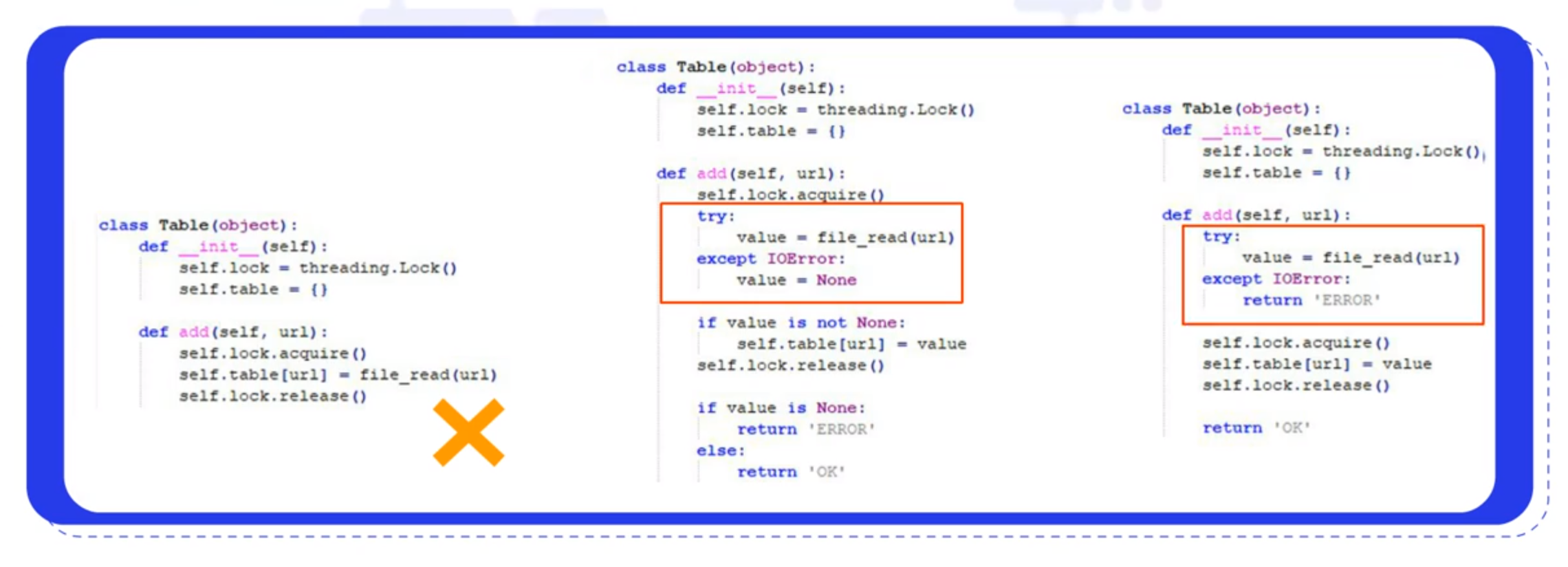
其次,因为异常处理是非常消耗资源的,所以我们也不能像图中中间的代码一样,将异常放在临界区内,要像最右边的代码一样处理。
2.2.2 具体细节处理
下面来讲解一下Mini-Spider过程中的细节处理问题,
2.2.2.1 种子信息的读取
很多开发人员会将种子信息读取的逻辑,和其他逻辑耦合在一起,这样是错误的。
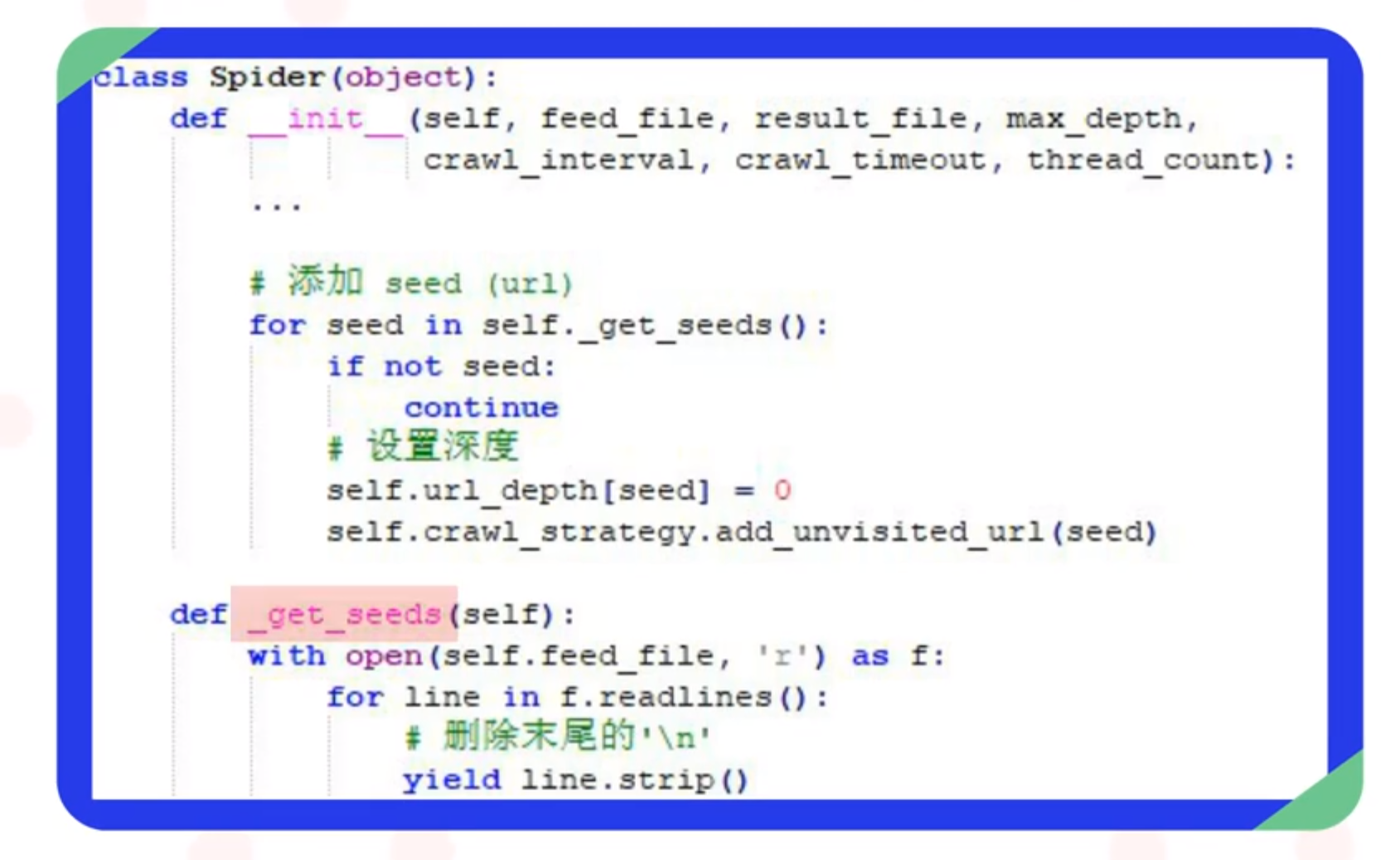
以图中代码为例,虽然通过_get_seeds函数直接读取文件中的信息,并灭有书写错误,但是如果后续的开发中文件的格式发生了变化,那就需要重新回来修改这部分的代码。
通过上述代码可以发现,模块划分和逻辑的复杂程度是没有关系的。
即使是逻辑简单的代码,如果没有做好模块划分,也会变得难以维护。
2.2.2.2 程序优雅退出
在真实的应用中,很多开发人员在实现程序退出功能的时候,使用了非常复杂的机制,导致后期维护难度较高。
在实际应用中,可以使用Python系统库中,关于队列的task_done()和join()的机制,以下图中的代码为例,左边的代码就是使用了task_done(),中间的代码是主程序中的一种常规逻辑使用,右边的是对中间主程序的一种优化,增加了spider.wait(),让整个逻辑可读性更强,更容易被理解。

2.2.2.3 爬虫的主逻辑编码
下面来讲一下爬虫主逻辑代码,编写需要注意的地方:
很多开发人员编写的主逻辑,非常的复杂且难懂,事实上图中的代码就是一个爬虫的主逻辑的所有代码,可以看到,里面包含了六个步骤:
第一步:从队列中拿到任务
第二步:读取内容,如果读取内容失败,则重新读取。如果读取成功,则执行第三步。
第三步:存储数据,
第四步:检查数据深度
第五步:如果数据深度不足,就进一步解析,并且放到队列中
第六步:结束任务

通过对六个步骤的编写和分析,可以看到好的代码是可以很快理解的,可读性是非常好的,这是开发人员在编写代码中需要注意的一个点。
2.3 代码检查规则背景及总体介绍
2.3.1 代码检测的意义
1 提高代码可读性
- 规范统一
- 方便他人维护
- 长远来看,符合公司内部开源战略
2 发现代码缺陷
- 帮助发现代码缺陷,弥补人工代码评审的疏漏
- 节省代码评审的时间与成本
3 提前发现问题
- 有助于提前发现问题,节约时间成本
- 降低缺陷修复成本
4 规范制定与准入检查
- 促进公司编码规范的落地
- 在规范制定后,借助工具进行准入检查
5 提升编码规范可运营
- 提升编码规范的可运营性
- 针对反馈较多的不合理规范进行调整更新
2.3.2 代码检查场景及工具
1 代码检查场景
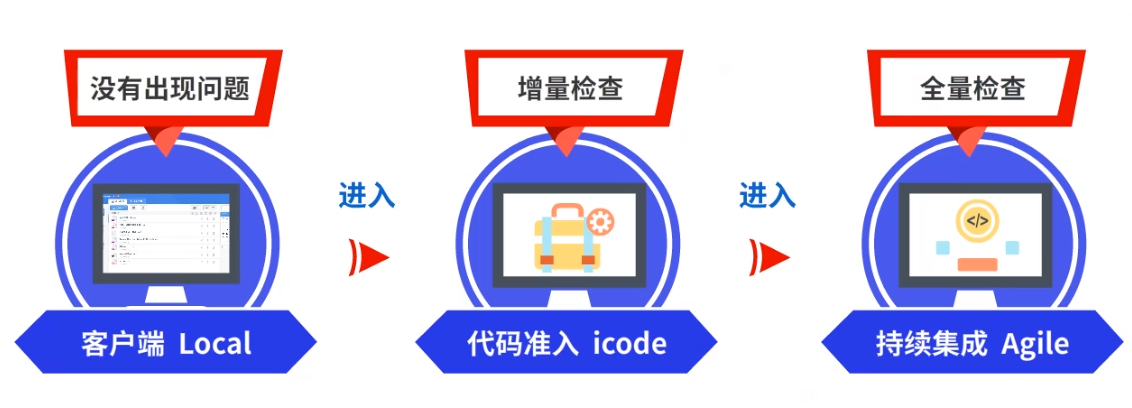
首先是本地研发环节,借助客户端工具,在push发起评审之前进行检查。
若本地代码扫描没有出现问题,就进入第二个环节,代码准入环节,即为Code Review,这一环节进行增量检查,属于公司强制要求。第三个环节,持续集成环节Agile,当代码合入到代码库之后进行全量检查,业务线根据自身需求来配置。
2 代码检查工具与服务
代码检查的产品、客户端、SCM(icode)、CI(Agile)之间具有交互性,共同构成整个代码检查环节。

3 代码检查覆盖范围
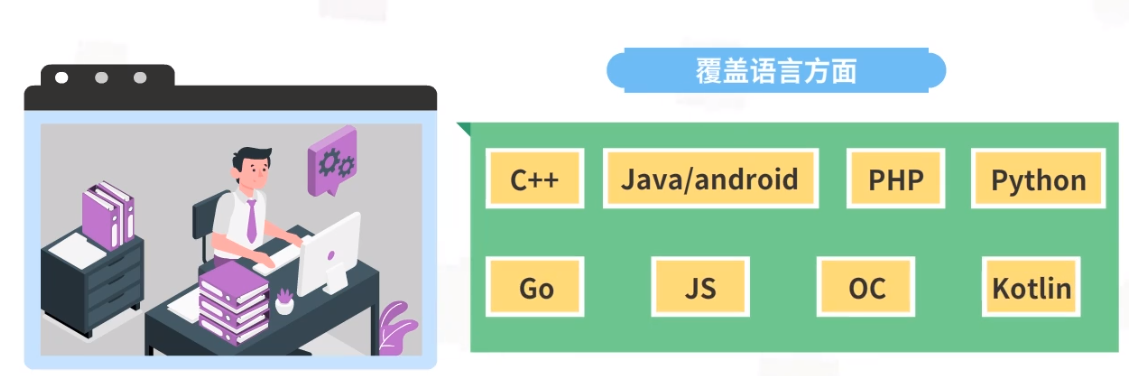
在覆盖语言方面,代码检查目前已经覆盖了包括C++、Java/android、PHP、Python、Go、JS、OC、Kotlin等在内的几乎所有主流语言。
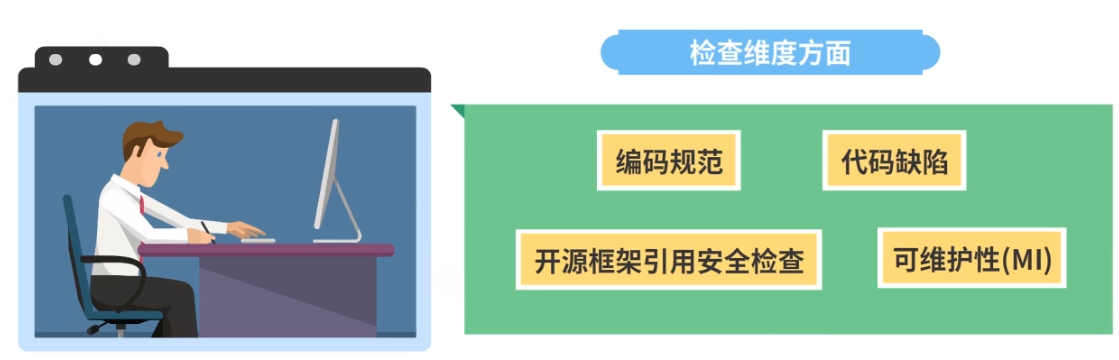
在检查维度方面,代码检查包括编码规范、代码缺陷、开源框架引用安全检查、可维护性(MI)。
4 代码检查速度
编码规范
只扫描变更文件,检查代码变更行是否复合规范,速度较快。
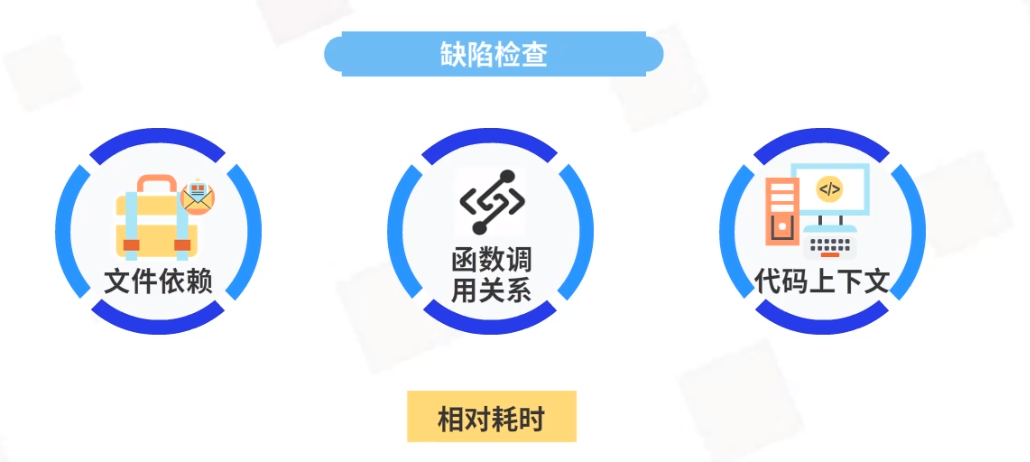
缺陷检查
需考虑文件依赖、函数调用关系、代码上下文等环节,因此相对耗时。
针对bugbye侧耗时的策略,默认超时时间10分钟,达到超时时间后,为了不影响代码合入,可选择“重新触发”或“跳过检查”。
2.3.3 代码检查规则分级
1 规则等级梳理
Code Review阶段,所有维度扫描出的问题,可以分为以下三个等级:
(1)Error
Error,属于需要强制解决的类型,影响代码的合入。
应视具体情况不同,采取修复、临时豁免、标记误报等措施及时处理。
(2)Warning
Warning,属于非强制性解决类型,不影响代码的合入。
但很可能存在风险,应尽量修复。
(3)Advice
非强制解决类型,级别相对较低,不影响代码合入。
可以选择性修复。
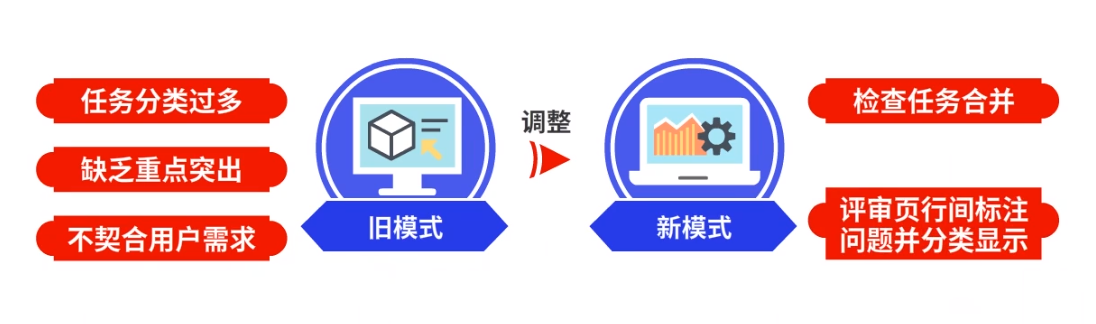
2 机检任务统一
在旧的模式下,旧的机器检查任务分类过多,缺乏重点,不契合用户需求,针对这一问题进行了调整,新模式下机器检查任务合并,评审页行间标注问题并分类显示。
3 评审页间行提示
评审业行间提示,指出具体的编码规范和缺陷检查。

4 针对豁免、误报、咨询的说明
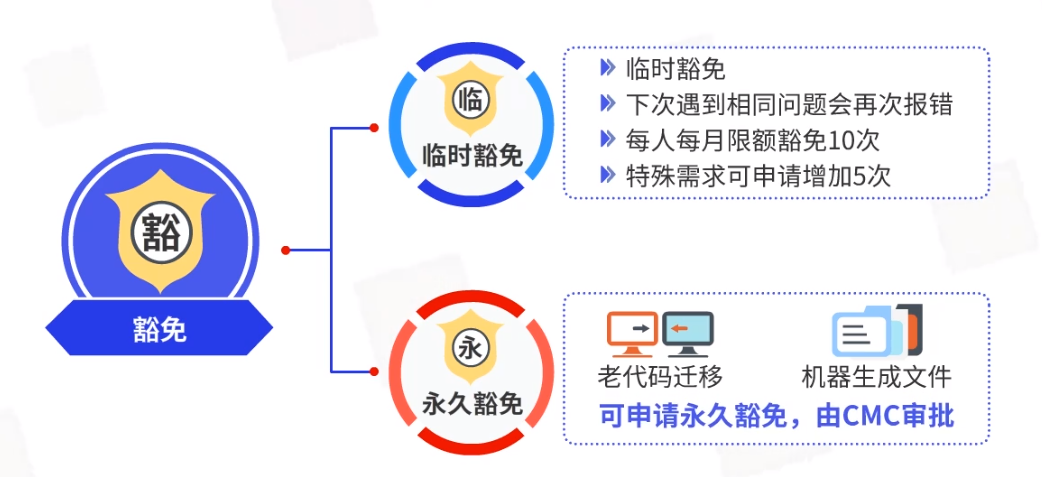
豁免分为临时豁免与永久豁免。
临时豁免,本次检查临时豁免,下次遇到相同问题会再次报错,每人每月限额豁免10次,特殊需求可申请增加5次。
永久豁免,针对老代码迁移,机器生成文件等不适合按代码规范检查的情况,可申请永久豁免,由CMC审批。
标记误报
行间点击误报并填写理由,也可直接反馈服务号。

问题咨询
对扫出的bug有疑问,或者检查失败等,可通过服务号咨询。
2.4 代码检测规则:Python语言案例详解
这部分的主要内容分为两个部分,Python的代码检查规则与Python的编码惯例,内涵涵盖了共计34条代码检查规则与4个Python编码惯例。这些规则与惯例都将在未来的编码规则中被反复应用。
2.4.2 Python的代码检查规则
一套良好的代码检查规则,可以带来代码质量提高,降低缺陷修复和后期维护成本等一系列收益,这里为大家提供了一套完备的代码检查体系。
规定的Python代码检查规则中,主要分为四个大类,分别是:
1.代码风格规范
2.引用规范
3.定义规范
4.异常处理规范

(1)代码风格规范
这一大类的规范规则较为繁琐,具体有可细分为以下七个小类(共计17条规则):
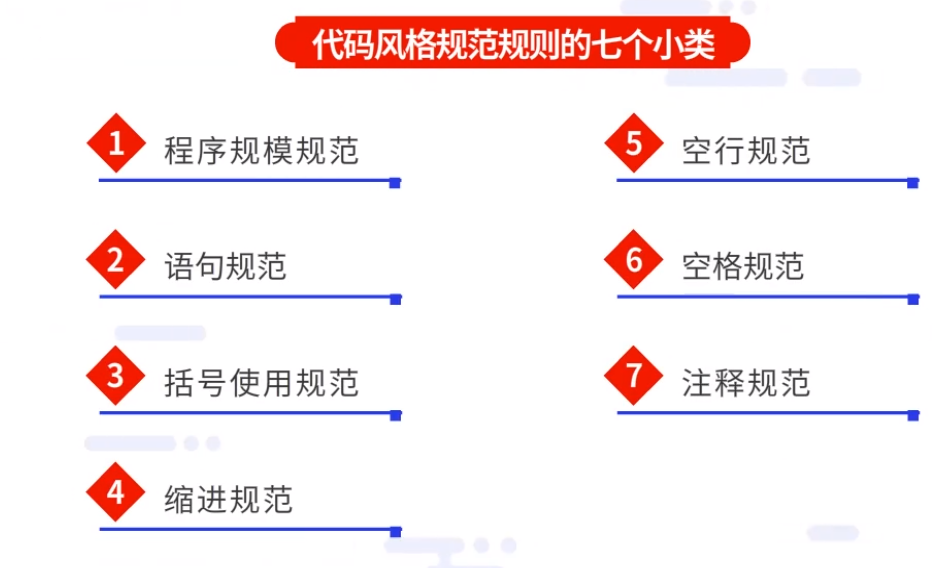
1.程序规范规模
(1)每行≤120个字符
每行不得超过120个字符
(2))函数长度≤120行
定义的函数长度不得超过120行,这意味着,在编写代码时,要时刻注意自己编写的程序规模,要避免冗余,确保简洁而高效。
2.语句规范
因为Python语言与其他语言不同,可以不需要明确的标识符标示语句的结尾,所以有以下规定:
(3)禁止以分号结束语句
(4)在任何情况下,一行只能写一条语句
3.括号使用规范
(5)除非用于明确算术表达式优先级、元组或者隐式行连接,否则尽量避免冗余的括号
4.缩进规范
(6)禁止使用Tab进行缩进,而统一使用4个空格进行缩进
在需要将单行内容拆成多行写时,我们规定
(7)与首行保持对齐,或者首行留空,从第二行起统一缩进四个空格
5.空行规范
(8)文件级定义(类或全局函数)之间,相隔两个空行;
类方法之间,相隔一个空行
6.空格规范
(9)括号之间均不添加空格
(10)参数列表、索引或切片的左括号前不应加空格
(11)逗号、分号、冒号前均不添加空格,而是在它们之后添加一个空格
(12)所有二元运算符前后各加一个空格
(13)关键字参数或参数默认值的等号前后不加空格
7.注释规范
(14)每个文件都必须有文件声明
声明必须包括以下三个方面的信息:
- (a) 版权声明
- (b) 功能和用途介绍
- (c) 修改人及联系方式
用文档字符串(docstring)进行注释时,规定
(15)使用docstring描述模块、函数、类和类方法接口时,docstring必须用三个双引号括起来。
(16)对外接口部分,必须使用docstring描述,内部接口视情况自行决定是否写docstring
(17)接口的docstring描述内容,至少包括以下三个方面的信息:
- 功能简介
- 参数
- 返回值
如果可能抛出异常,则特别注明会发生。
(2)引用规范
一个良好的代码风格,是程序员写出优美代码的基础,而当我们想要写出更为间接的代码,我们很难在不导入各种的模块、库与包的情况下完成它。
(1)禁止使用from ...import...句式直接导入类或函数
而应自导入库后再行调用,
(2)每行只导入一个库
(3)按标准库、第三方库、应用程序自有库的的顺序排列import
三个部分之间分别留一个空行。
(3)定义规范
下面我们将分别介绍各种定义的规范,具体可分为三个小类:
(1) 变量定义规范
(2) 函数定义规范
(3) 类定义规范
1.变量定义规范
在变量定义方面,我们有强制的规范规定:
①局部变量使用全小写字母,单词间使用下划线分割;
②定义的全局变量必须写在文件头部
③常量使用全大写字母,单词间使用下划线分隔
2.函数的定义规范
函数的定义规范,主要体现在函数的返回值,以及默认参数的定义上,为提高代码可读性,对于函数的返回值,规范要求为:
①函数返回值必须小于或者等于三个,若返回值大于三个,则必须通过各种具名的形式进行包装。
为了保障函数运行效率,以及降低后期维护和纠错成本,对于函数默认参数的定义有如下要求:
②仅可使用以下基本类型的常量或字面常量作为默认参数(整数、浮点数、bool、浮点数、字符串、None)
3.类定义的规范
类定义的规范,包括了四个方面的内容:
①类的命名,使用首字母大写的驼峰式命名法
②对于类定义的成员,protected成员使用单下划线前缀,private成员使用双下划线前缀。
③如果一个类没有基类,必须继承自ovject类。
④类构造函数应尽量简单,不能包含可能失败或过于复杂的操作
(4)异常处理规范
在代码编写中应该尽量避免代码异常状态的出现,然而错误有时也在所难免,对于这些异常状态的处理,有着明确的规范要求。
①禁止使用双参数形式或字符串形式的语法抛出异常
②如需自定义异常,应在模块内定义名为Error的异常基类,并且该基类必须继承自Exception,其他异常均由该基类派生而来。
③除非重新抛出异常,禁止使用except语句捕获所有异常,一般情况下,应使用except...语句捕获具体的异常
④捕捉异常时,应当使用as语法,禁止使用逗号语法。
2.4.3 Python的编码惯例
下面介绍几个常见的Python编码惯例,便于大家理解日后所见的代码:
它们分别是:
1.让模块即可被导入又可被执行
2.in运算符的使用
3.不适用临时变量交换两个值
4.用序列构建字符串
(1)让模块即可被导入又可被执行
Python不同于编译型语言,而属于脚本语言,是动态的逐行解释运行,没有统一的程序入口。
所以,为了方便模块之间的相互导入,我们通过自定义一个main函数,并使用一个if语句,if内置变量__name__=='__main__',在这个if条件下,再去执行main函数,这样我们就能够实现,让模块即可被导入又可被执行。
(2) in运算符的使用
in是一种简洁而高效的运算符,很多时候,合理的使用in运算符,可以替代大量的重复判断过程,降低时间复杂度,提高代码的运行效率。
(3) 不适用临时变量交换两个值
Python有简洁而高效的语句,可以实现交换两个值的操作,并无必要引入临时变量来交换两个值。
(4) 用序列构建字符串
对于一个字符串列表、元组等,可以用序列来构建字符串,利用一个空字符串和join函数,可以避免重复,从而高效完成字符串的构建。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号