【论文阅读】M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
QijieZhao1, TaoSheng1, YongtaoWang1∗, ZhiTang1, YingChen2, LingCai2 and HaibinLing3
1 Institute of Computer Science and Technology, Peking University, Beijing, P.R. China
2 AI Labs, DAMO Academy, Alibaba Group
3 Computer and Information Sciences Department, Temple University {zhaoqijie, shengtao, wyt, tangzhi}@pku.edu.cn, {cailing.cl, chenying.ailab}@alibaba-inc.com, {hbling}@temple.edu
Abstract
Feature pyramids are widely exploited by both the state-of the-art one-stage object detectors (e.g., DSSD, RetinaNet, RefineDet) and the two-stage object detectors (e.g., Mask RCNN, DetNet) to alleviate the problem arising from scale variation across object instances. Although these object detectors with feature pyramids achieve encouraging results, they have some limitations due to that they only simply construct the feature pyramid according to the inherent multiscale, pyramidal architecture of the backbones which are originally designed for object classification task. Newly, in this work, we present Multi-Level Feature Pyramid Network (MLFPN) to construct more effective feature pyramids for detecting objects of different scales. First, we fuse multi-level features (i.e. multiple layers) extracted by backbone as the base feature. Second, we feed the base feature into a block of alternating joint Thinned U-shape Modules and Feature Fusion Modules and exploit the decoder layers of each U shape module as the features for detecting objects. Finally, we gather up the decoder layers with equivalent scales(sizes) to develop a feature pyramid for object detection, in which every feature map consists of the layers (features) from multiple levels. To evaluate the effectiveness of the proposed MLFPN, we design and train a powerful end-to-end one stage object detector we call M2Det by integrating it into the architecture of SSD, and achieve better detection performance than state-of-the-art one-stage detectors. Specifically, on MS-COCO benchmark, M2Det achieves AP of 41.0 at speed of 11.8 FPS with single-scale inference strategy and AP of 44.2 with multi-scale inference strategy, which are the new state-of-the-art results among one-stage detectors. The code will be made available on https://github.com/qijiezhao/M2Det.
摘要:现在性能较好的一阶段物体探测器(如DSSD,RetinaNet,RefineDet)和两阶段物体探测器(如Mask RCNN,DetNet)都广泛使用了特征金字塔,从而缓解对象实例的比例大小变化带来的差异问题。尽管这些具有特征金字塔的物体探测器获得了不错的结果,但它们也有一定的局限性:它们只是简单地根据内在的多尺度构造特征金字塔,这种骨干网络的金字塔架构本是为了分类任务而设计。最近,在这项工作中,我们提出了多层次特征金字塔网络(MLFPN)来构建更有效的特征金字塔,用于检测不同尺度的对象。首先,我们融合由骨干网络提取的多级特征(即多层)作为基本特征。然后,我们将上述基本特征送入一组交替连接的简化U形模块和特征融合模块,并利用每个U形模块的解码器层作为检测对象的特征。最后,我们将具有等效尺度(大小)的解码器层集合(组合)起来,形成一个用于目标检测的特征金字塔,其中每个特征图由多个层次的层(特征)组成。为了评估所提出的MLFPN的有效性,我们设计并训练了一个功能强大的端到端一阶段物体探测器,将其集成到SSD架构中,我们称为M2Det,获得了比现有技术更好的检测性能。具体而言,在MS-COCO基准测试中,M2Det采用单尺度推理策略时,以11.8 FPS的速度实现了41.0的AP,当使用多尺度推理策略时,AP为44.2。这是一种新的最先进一阶段探测器。该代码将在https://github.com/qijiezhao/M2Det上提供。
Introduction
Scale variation across object instances is one of the major challenges for the object detection task (Lin et al. 2017a; He etal.2015; Singh and Davis2018), and usually there are two strategies to solve the problem arising from this challenge. The first one is to detect objects in an image pyramid (i.e. a series of resized copies of the input image)( Singh and Davis2018), which can only be exploited at the testing time. Obviously, this solution will greatly increase memory and computational complexity, thus the efficiency of such object detectors drop dramatically. The second one is to detect objects in a feature pyramid extracted from the input image (Liu et al. 2016; Lin et al. 2017a), which can be exploited at both training and testing phases. Compared with the first solution that uses an image pyramid, it has less memory and computational cost. Moreover, the feature pyramid constructing module can be easily integrated into the state-of the-art Deep Neural Networks based detectors, yielding an end-to-end solution.
实例之间的尺度差异是对象检测任务的主要挑战之一(Lin等人2017a; He etal.2015; Singh和Davis2018),通常有两种策略来解决由此挑战引起的问题。第一种是检测图像金字塔中的对象(即一系列已调整输入图像大小的副本)(Singh和Davis2018),这种方法只能在测试时使用。显然,这种解决方案将大大增加内存和计算复杂性,因此这种对象检测器的效率急剧下降。第二种是检测从输入图像中提取的特征金字塔中的对象(Liu et al.2016; Lin et al.2017a),可以在训练和测试阶段进行利用。与使用图像金字塔的第一种解决方案相比,第二种方案需要更少的内存和计算成本。此外,特征金字塔构建模块可以很容易地嵌入到基于深度神经网络的最先进检测器中,从而产生端到端的解决方案。
Although the object detectors with feature pyramids (Liu et al. 2016; Lin et al. 2017a; Lin et al. 2017b; He et al. 2017) achieve encouraging results, they still have some limitations due to that they simply construct the feature pyramid according to the inherent multi-scale, pyramidal architecture of the backbones which are actually designed for object classification task. For example, as illustrated in Fig. 1, SSD (Liu et al. 2016) directly and independently uses two layers of the backbone (i.e. VGG16) and four extra layers obtained by stride 2 convolution to construct the feature pyramid; STDN (Zhou et al. 2018) only uses the last dense block of DenseNet (Huang et al. 2017) to construct feature pyramid by pooling and scale-transfer operations; FPN (Lin et al. 2017a) constructs the feature pyramid by fusing the deep and shallow layers in a top-down manner. Generally speaking, the above-mentioned methods have the two following limitations. First, feature maps in the pyramid are not representative enough for the object detection task, instead they are simply constructed from the layers (features) of the backbone designed for object classification task. Second, each feature map in the pyramid(used for detecting objects in a specific range of size) is mainly or even solely constructed from single-level layers of the backbone, that is, it mainly or only contains single-level information. In general, high-level features in the deeper layers are more discriminative for classification subtask while low-level features in the shallower layers can be helpful for object location regression sub-task. Moreover, low-level features are more suitable to characterize objects with simple appearances while high-level features are appropriate for objects with complex appearances. In practice, the appearances of the object instances with similar size can be quite different. For example, a traffic light and a faraway person may have comparable size, and the appearance of the person is much more complex. Hence, each feature map (used for detecting objects in a specific range of size) in the pyramid mainly or only consists of single-level features will result in suboptimal detection performance.
尽管具有特征金字塔的物体检测器(Liu等人2016; Lin等人2017a; Lin等人2017b; He等人2017)取得了不错的结果,但由于他们只是根据内在多尺度金字塔结构的骨架网络构建了特征金字塔,这种骨架网络实际上是为物体分类任务设计的,因此这些方法仍然存在一些局限性。例如,如图1所示,SSD(Liu等人,2016)直接单独使用两层骨架网络的特征(即VGG16)和通过步幅为2的卷积获得的四个额外层来构建特征金字塔; STDN(Zhou et al.2018)仅使用DenseNet的最后一个Dense块(Huang et al.2017),通过池化和尺度变换操作构建特征金字塔; FPN(Lin et al.2017a)通过以自上而下的方式融合深层和浅层的特征来构造特征金字塔。一般而言,上述方法具有以下两个限制。首先,金字塔中的特征图对于对象检测任务而言不够典型(表达能力不够),它们只是简单地从为对象分类任务设计的骨干网络的层(特征)中构造。其次,金字塔中的每个特征图(用于检测特定大小范围内的对象)主要或甚至仅从骨干网络的单层构建,即,它主要或仅包含单层信息。通常,较深层中的高级特征对分类子任务更具区别性,而较浅层中的低级特征可有助于对象位置回归子任务。此外****,低级特征更适合于表征具有简单外观的对象,而高级特征适合于具有复杂外观的对象。实际上,具有相似大小的对象实例的外观可能完全不同。例如,交通灯和遥远的人可能具有相当的尺寸,但是人的外观要复杂得多。因此,金字塔中的每个特征图(用于检测特定尺寸范围内的对象)主要或仅由单级特征组成将致使检测性能欠佳。
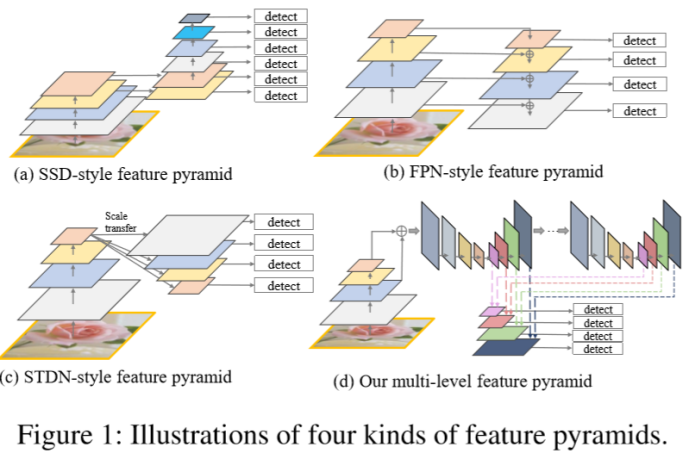
The goal of this paper is to construct a more effective feature pyramid for detecting objects of different scales, while avoid the limitations of the existing methods as above mentioned. As shown in Fig.2, to achieve this goal, we first fuse multi-level features (i.e. multiple layers) extracted by backbone as base feature, and then feed it into a block of alternating joint Thinned U-shape Modules (TUM) and Feature Fusion Modules (FFM)to extract more representative, multilevel multi-scale features. It is worth noting that, decoder layers in each U-shape Module share a similar depth. Finally, we gather up the feature maps with equivalent scales to construct the final feature pyramid for object detection. Obviously, decoder layers that form the final feature pyramid are much deeper than the layers in the backbone, namely, they are more representative. Moreover, each feature map in the final feature pyramid consists of the decoder layers from multiple levels. Hence, we call our feature pyramid block Multi-Level Feature Pyramid Network (MLFPN).
本文的目的是构建一个更有效的特征金字塔,用于检测不同尺度的物体,同时避免上述现有方法的局限性。如图2所示,为了实现这个目标,我们首先融合由骨干网络提取的多级特征(即多个层)作为基本特征,然后将其馈送到交替连接的简化U形模块(TUM)和特征融合模块(FFM),从而提取更具代表性的多级多尺度特征。值得注意的是,每个U形模块中的解码器层共享相似的深度。最后,我们收集(组合,融合)具有等效尺度的特征图,以构建用于对象检测的最终特征金字塔。显然,形成最终特征金字塔的解码器层比骨干中的层深得多,即它们更具代表性。此外,最终特征金字塔中的每个特征图都包含来自多个级别的解码器层。因此,我们将我们的特征金字塔块称为多级特征金字塔网络(MLFPN)。
To evaluate the effectiveness of the proposed MLFPN, we design and train a powerful end-to-end one-stage object detector we call M2Det (according to that it is built up on multilevel and multi-scale features) by integrating MLFPN into the architecture of SSD (Liu et al. 2016). M2Det achieves the new state-of-the-art result (i.e. AP of 41.0 at speed of 11.8 FPS with single-scale inference strategy and AP of 44.2 with multi-scale inference strategy), outperforming the one stage detectors on MS-COCO (Lin et al. 2014) benchmark.
为了评估所提出的MLFPN的有效性,我们将MLFPN嵌入到SSD(Liu et al.2016)架构中来设计和训练一个功能强大的端到端一阶段对象检测器,我们称之为M2Det(根据它建立在多级和多尺度特征上)。 M2Det实现了最新的最佳结果(即AP为41.0,速度为11.8 FPS,采用单尺度推理策略,AP为44.2,具有多尺度推理策略),优于MS-COCO上的一级探测器( 林等人,2014)的基准。
Related Work
Researchers have put plenty of efforts into improving the detection accuracy of objects with various scales – no matter what kind of detector it is, either an one-stage detector or a two-stage one. To the best of our knowledge, there are mainly two strategies to tackle this scale-variation problem.
研究人员已经投入了大量精力来提高不同尺度物体的探测精度(无论是哪种探测器,无论是一阶段检测器还是两阶段检测器)。 据我们所知,主要有两种策略来解决这种尺度差异问题。
The first one is featurizing image pyramids (i.e. a series of resized copies of the input image) to produce semantically representative multi-scale features. Features from images of different scales yield predictions separately and these predictions work together to give the final prediction. In terms of recognition accuracy and localization precision, features from various-sized images do surpass features that are based merely on single-scale images. Methods such as (Shrivastava et al. 2016) and SNIP (Singh and Davis 2018) employed this tactic. Despite the performance gain, such a strategy could be costly time-wise and memory-wise, which forbid its application in real-time tasks. Considering this major drawback, methods such as SNIP (Singh and Davis 2018) can choose to only employ featurize image pyramids during the test phase as a fallback, whereas other methods including Fast R-CNN (Girshick 2015) and Faster R-CNN (Ren et al. 2015) chose not to use this strategy by default.
第一个是利用图像金字塔(即一系列调整输入图像大小的副本)以产生具有语义代表性的多尺度特征。 来自不同尺度的图像的特征分别产生预测,并且这些预测一起工作(最后融合)以给出最终预测。 在识别精度和定位精度方面,来自各种尺寸图像的特征确实超越仅基于单尺度图像的特征。 诸如(Shrivastava等人2016)和SNIP(Singh和Davis 2018)之类的方法采用了这种策略。 尽管性能提升,但这样的策略在时间和内存方面耗费较大,这限制了其在实时任务中的应用。 考虑到这个主要缺点,像SNIP(Singh和Davis 2018)这样的方法可以选择在测试阶段仅使用图像特征金字塔作为后备手段,而其他方法包括Fast R-CNN(Girshick 2015)和Faster R-CNN(Ren) 等人,2015)默认选择不使用此策略。
The second one is detecting objects in the feature pyramid extracted from inherent layers within the network while merely taking a single-scale image. This strategy demands significantly less additional memory and computational cost than the first one, enabling deployment during both the training and test phases in real-time networks. Moreover, the feature pyramid constructing module can be easily revised and fit into state-of-the-art Deep Neural Networks based detectors. MS-CNN(Caietal.2016), SSD(Liuetal.2016), DSSD(Fu et al. 2017), FPN (Lin et al. 2017a), YOLOv3 (Redmon and Farhadi 2018), RetinaNet (Lin et al. 2017b), and RefineDet (Zhang et al. 2018) adopted this tactic in different ways.
第二种是从网络内的固有层提取的金字塔特征中检测对象,同时仅采用单一尺度的图像。 与第一种策略相比,该策略需要的内存和计算成本显着降低,从而可以在实时网络的训练和测试阶段进行部署。 此外,特征金字塔构建模块可以很容易地修改并嵌入最先进的基于深度神经网络的检测器。 MS-CNN(Caietal.2016),SSD(Liuetal.2016),DSSD(Fu等人2017),FPN(Lin等人2017a),YOLOv3(Redmon和Farhadi 2018),RetinaNet(Lin等人2017b) 和RefineDet(Zhang et al.2018)以不同的方式采用了这种策略。
To the best of our knowledge, MS-CNN (Cai et al. 2016) proposed two sub-networks and first incorporated multiscale features into deep convolutional neural networks for object detection. The proposal sub-net exploited feature maps of several resolutions to detect multi-scale objects in an image. SSD(Liuetal.2016) exploited feature maps from the later layers of VGG16 base-net and extra feature layers for predictions at multiple scales. FPN (Lin et al. 2017a) utilized lateral connections and a top-down pathway to produce a feature pyramid and achieved more powerful representations. DSSD (Fu et al. 2017) implemented deconvolution layers for aggregating context and enhancing the high level semantics for shallow features. RefineDet (Zhang et al. 2018) adopted two-step cascade regression, which achieves a remarkable progress on accuracy while keeping the efficiency of SSD.
据我们所知,MS-CNN(Cai等人,2016)提出了两个子网络,首先将多尺度特征结合到用于物体检测的深度卷积神经网络中。 提议子网利用几种分辨率的特征图来检测图像中的多尺度对象。SSD(Liuetal.2016)利用来自VGG16基础网络的后面层和额外特征层的特征图进行多尺度预测。FPN(Lin et al.2017a)利用横向连接和自上而下的路径来产生特征金字塔并实现更强大的表示。DSSD(Fu et al.2017)实现了反卷积层,用于聚合上下文并增强浅层特征的高级语义。RefineDet(Zhang etal.2018)采用了两步级联回归,在保持SSD效率的同时,在准确性方面取得了显着进步。
Proposed Method
The overall architecture of M2Det is shown in Fig.2. M2Det uses the backbone and the Multi-Level Feature Pyramid Network (MLFPN) to extract features from the input image, and then similar to SSD, produces dense bounding boxes and category scores based on the learned features, followed by the non-maximum suppression (NMS) operation to produce the final results. MLFPN consists of three modules, i.e. Feature Fusion Module (FFM), Thinned U-shape Module (TUM) and Scale-wise Feature Aggregation Module (SFAM). FFMv1 enriches semantic information into base features by fusing feature maps of the backbone. Each TUM generates a group of multi-scale features, and then the alternating joint TUMs and FFMv2s extract multi-level multiscale features. In addition, SFAM aggregates the features into the multi-level feature pyramid through a scale-wise feature concatenation operation and an adaptive attention mechanism. More details about the three core modules and network configurations in M2Det are introduced in the following.
M2Det的整体架构如图2所示。 M2Det使用骨干网和多级特征金字塔网络(MLFPN)从输入图像中提取特征,然后类似于SSD,根据学习的特征生成密集的边界框和类别分数,最后是非最大抑制( NMS)操作以产生最终结果。 MLFPN由三个模块组成,即特征融合模块(FFM),简化的U形模块(TUM)和按基于尺度的特征聚合模块(SFAM)。 FFMv1通过融合骨干网络的特征图,将语义信息丰富为基本特征。每个TUM生成一组多尺度特征,然后交替连接的TUM和FFMv2提取多级多尺度特征。此外,SFAM通过按比例缩放的特征连接操作和自适应注意机制将特征聚合到多级特征金字塔中。下面介绍有关M2Det中三个核心模块和网络配置的更多详细信息。

Figure 2: An overview of the proposed M2Det(320×320). M2Det utilizes the backbone and the Multi-level Feature Pyramid Network (MLFPN) to extract features from the input image, and then produces dense bounding boxes and category scores. In MLFPN, FFMv1 fuses feature maps of the backbone to generate the base feature. Each TUM generates a group of multi-scale features, and then the alternating joint TUMs and FFMv2s extract multi-level multi-scale features. Finally, SFAM aggregates the features into a multi-level feature pyramid. In practice, we use 6 scales and 8 levels mostly.
图2:M2Det(320×320)的概述。 M2Det利用骨干网和多级特征金字塔网络(MLFPN)从输入图像中提取特征,然后生成密集的边界框和类别分数。 在MLFPN中,FFMv1融合骨干的特征图以生成基本特征。 每个TUM生成一组多尺度特征,然后交替连接的TUM和FFMv2s提取多级多尺度特征。 最后,SFAM将特征聚合为多级特征金字塔。 在实践中,我们主要使用6个等级和8个等级。
Multi-level Feature Pyramid Network As shown in Fig. 2, MLFPN contains three parts. Firstly, FFMv1 fuses shallow and deep features to produce the base feature, e.g., conv4 3 and conv5 3 of VGG (Simonyan and Zisserman 2015), which provide multi-level semantic information for MLFPN. Secondly, several TUMs and FFMv2 are stacked alternately. Specially, each TUM generates several feature maps with different scales. The FFMv2 fuses the base feature and the largest output feature map of the previous TUM. And the fused feature maps are fed to the next TUM. Note that the first TUM has no prior knowledge of any other TUMs, so it only learns from Xbase. The output multi-level multi-scale features are calculated as:
如图2所示的多级特征金字塔网络,MLFPN包含三个部分。 首先,FFMv1融合浅和深的特征以产生基本特征,例如VGG的conv4 3和conv5 3(Simonyan和Zisserman 2015),其为MLFPN提供多级语义信息。 其次,交替堆叠多个TUM和FFMv2。 特别地,每个TUM生成具有不同尺度的若干特征图。 FFMv2融合了基本特征和前一个TUM的最大输出特征图。最后,融合的特征图被馈送到下一个TUM。 请注意,第一个TUM没有任何其他TUM的先验知识,因此它只从Xbase学习。 输出多级多尺度特征计算如下:
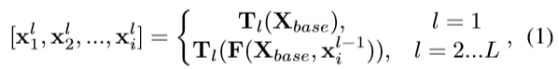
where Xbase denotes the base feature, xli denotes the feature with the i-th scale in the l-th TUM, L denotes the number of TUMs, Tl denotes the l-th TUM processing, and F denotes FFMv1 processing. Thirdly, SFAM aggregates the multi-level multi-scale features by a scale-wise feature concatenation operation and a channel-wise attention mechanism.
其中Xbase表示基本特征,xli表示在第l个TUM中具有第i个尺度的特征,L表示TUM的数量,T1表示第l个TUM处理,并且F表示FFMv1处理。 第三,SFAM通过按比例缩放的特征连接操作和通道注意力机制来聚合多级多尺度特征。
FFMs
FFMs fuse features from different levels in M2Det, which are crucial to constructing the final multi-level feature pyramid. They use 1x1 convolution layers to compress the channels of the input features and use concatenation operation to aggregate these feature maps. Especially, since FFMv1takes two feature maps with different scales in backbone as input, it adopts one upsample operation to rescale the deep features to the same scale before the concatenation operation. Meanwhile, FFMv2 takes the base feature and the largest output feature map of the previous TUM –these two are of the same scale – as input, and produces the fused feature for the next TUM. Structural details of FFMv1 and FFMv2 are shown in Fig. 4 (a) and (b), respectively.
FFM融合了M2Det中不同层次的特征,这对于构建最终的多级特征金字塔至关重要。 它们使用1x1卷积层来压缩输入特征的通道,并使用连接操作来聚合这些特征图。 特别是,由于FFMv1以骨干网络中不同比例的两个特征图作为输入,因此它采用一个上采样操作,在连接操作之前将深度特征重新缩放到相同的尺度。 同时,FFMv2采用基本特征和前一个TUM的最大输出特征图 - 这两个具有相同的比例 - 作为输入,并产生下一个TUM的融合特征。 FFMv1和FFMv2的结构细节分别如图4(a)和(b)所示。
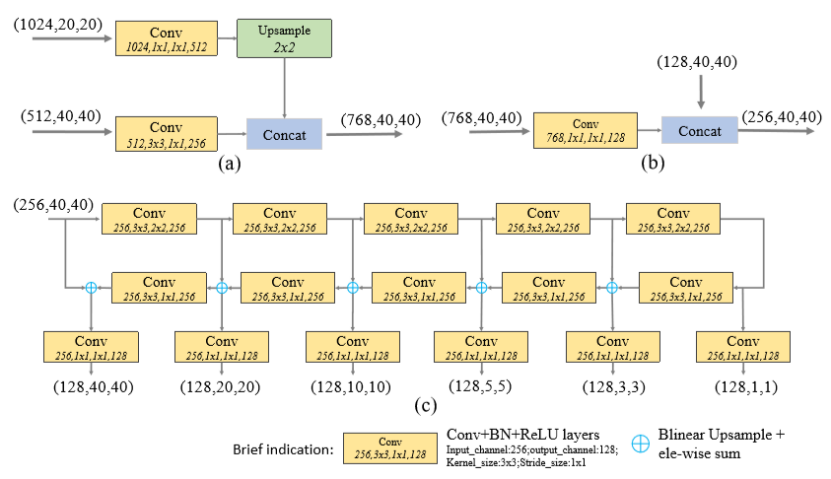
Figure 4: Structural details of some modules. (a) FFMv1, (b)FFMv2,(c)TUM. The inside numbers of each block denote: input channels, Conv kernel size, stride size, output channels.
图4:一些模块的结构细节。 (a)FFMv1,(b)FFMv2,(c)TUM。 每个块的内部数字表示:输入通道,Conv内核大小,步幅大小,输出通道。
TUMs
Different from FPN (Lin et al. 2017a) and RetinaNet (Lin et al. 2017b), TUM adopts a thinner U-shape structure as illustrated in Fig. 4 (c). The encoder is a series of 3x3 convolution layers with stride 2. And the decoder takes the outputs of these layers as its reference set of feature maps, while the original FPN chooses the output of the last layer of each stage in ResNet backbone. In addition, we add 1x1 convolution layers after upsample and elementwise sum operation at the decoder branch to enhance learning ability and keep smoothness for the features (Lin, Chen, and Yan 2014). All of the outputs in the decoder of each TUM form the multi-scale features of the current level. As a whole, the outputs of stacked TUMs form the multi-level multi-scale features, while the front TUM mainly provides shallow-level features, the middle TUM provides medium level features, and the back TUM provides deep-level features.
TUM不同于FPN(Lin等人2017a)和RetinaNet(Lin等人2017b),TUM采用简化的U形结构,如图4(c)所示。 编码器是一系列3x3,步长为2的卷积层.并且解码器将这些层的输出作为其参考特征集,而原始FPN选择ResNet主干网络中每个阶段的最后一层的输出。 此外,我们在解码器分支的上采样层后添加1x1卷积层和按元素求和的操作,以增强学习能力并保持特征的平滑性(Lin,Chen和Yan 2014)。 每个TUM的解码器中的所有输出形成当前级别的多尺度特征。 整体而言,堆叠TUM的输出形成多层次多尺度特征,而前TUM主要提供浅层特征,中间TUM提供中等特征,后TUM提供深层特征。
SFAM
SFAM aims to aggregate the multi-level multiscale features generated by TUMs into a multi-level feature pyramid as shown in Fig. 3. The first stage of SFAM is to concatenate features of the equivalent scale together along the channel dimension. The aggregated feature pyramid can be presented as X = [X1,X2,...,Xi], where Xi = Concat(x1i,x2i,...,xLi ) ∈ RWi×Hi×C refers to the features of the i-th largest scale. Here, each scale in the aggregated pyramid contains features from multi-level depths. However, simple concatenation operations are not adaptive enough. In the second stage, we introduce a channel-wise attention module to encourage features to focus on channels that they benefit most. Following SE block (Hu, Shen, and Sun 2017), we use global average pooling to generate channel-wise statistics z ∈ RC at the squeeze step. And to fully capture channel-wise dependencies, the following excitation step learns the attention mechanism via two fully connected layers:
SFAM旨在将由TUM生成的多级多尺度特征聚合成多级特征金字塔,如图3所示.SFAM的第一阶段是沿着信道维度将等效尺度的特征连接在一起。 聚合特征金字塔可以表示为X = [X1,X2,...,Xi],其中Xi = Concat(x1i,x2i,...,xLi ) ∈ RWi×Hi×C指的是尺度第i个最大的特征。 这里,聚合金字塔中的每个比例都包含来自多级深度的特征。 但是,简单的连接操作不太适合。 在第二阶段,我们引入了通道注意模块,以促使特征集中在最有益的通道。 在SE区块(Hu,Shen和Sun 2017)之后,我们使用全局平均池化来在挤压步骤中生成通道统计z∈RC。 为了完全捕获通道依赖性,以下激励步骤通过两个完全连接的层学习注意机制:
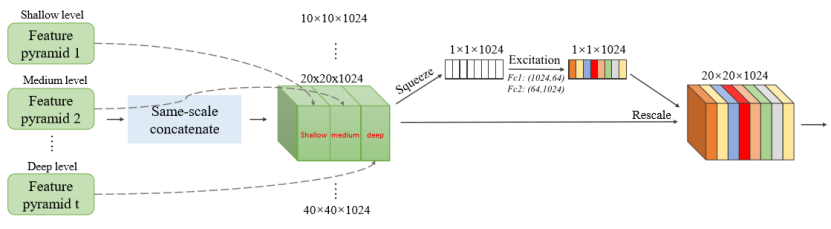
Figure 3: Illustration of Scale-wise Feature Aggregation Module. The first stage of SFAM is to concatenate features with equivalent scales along channel dimension. Then the second stage uses SE attention to aggregate features in an adaptive way.
图3:按缩放比例的特征聚合模块的图示。 SFAM的第一阶段是沿着信道维度连接具有等效比例的特征。 然后第二阶段使用SE注意机制以自适应方式聚合特征。
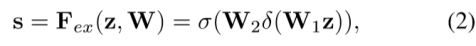
where σ refers to the ReLU function, δ refers to the sigmoid function, W1 ∈ RC/r ×C , W2∈RC×C /r , r is the reduction ratio (r = 16 in our experiments). The final output is obtained by reweighting the input X with activation s:

where ˜ Xi = [˜ X1i, ˜ X2i,..., ˜ XCi ], each of the features is enhanced or weakened by the rescaling operation.
其中σ表示RELU激活函数,δ为sigmoid函数,W1 ∈ RC/r ×C , W2∈RC×C /r ,r是减少的比例(实验中为16). 最后通过激活s对输入X重新加权得到输出:
Network Configurations
We assemble M2Det with two kinds of backbones (Simonyan and Zisserman 2015; He et al. 2016). Before training the whole network, the backbones need to be pre-trained on the ImageNet 2012 dataset(Russakovskyetal.2015).All of the default configurations of MLFPN contain 8 TUMs, each TUM has 5 striding-Convs and 5 Upsample operations, so it will output features with 6 scales. To reduce the number of parameters, we only allocate 256 channels to each scale of their TUM features, so that the network could be easy to train on GPUs. As for input size, we follow the original SSD, RefineDet and RetinaNet, i.e., 320, 512 and 800.
我们用两种主干网络组装M2Det(Simonyan和Zisserman 2015; He等人2016)。 在训练整个网络之前,骨干网络需要在ImageNet 2012数据集上进行预训练(Russakovsky et al.2015).MLFPN的所有默认配置包含8个TUM,每个TUM有5个跨步卷积(编码器)和5个Upsample操作,因此它将输出6种尺度的特征。 为了减少参数的数量,我们只为其TUM功能的每个比例分配256个通道,以便网络可以很容易地在GPU上训练。 至于输入尺寸,我们遵循原始SSD,RefineDet和RetinaNet,即320,512和800。
At the detection stage, we add two convolution layers to each of the 6 pyramidal features to achieve location regression and classification respectively. The detection scale ranges of the default boxes of the six feature maps follow the setting of the original SSD. And when input size is 800×800, the scale ranges increase proportionally except keeping the minimum size of the largest feature map. At each pixel of the pyramidal features, we set six anchors with three ratios entirely. Afterward, we use a probability score of 0.05 as threshold to filter out most anchors with low scores. Then we use soft-NMS (Bodlaetal.2017) with a linear kernel for post-processing, leaving more accurate boxes. Decreasing the threshold to 0.01 can generate better detection results, but it will slow down the inference time a lot, we do not consider it for pursuing better practical values.
在检测阶段,我们为6个金字塔特征中的每一个添加两个卷积层,以分别实现位置回归和分类。 六个特征图的默认框的检测比例范围遵循原始SSD的设置。 当输入尺寸为800×800时,除了保持最大特征图的最小尺寸外,比例范围按比例增加。 在金字塔特征的每个像素处,我们设置六个锚点,完全具有三个比率。 之后,我们使用0.05的概率分数作为阈值来筛选出分数较低的大多数锚点。 然后我们使用带有线性内核的soft-NMS(Bodlaetal.2017)进行后处理,留下更精确的盒子。 将阈值降低到0.01可以产生更好的检测结果,但它会大大减慢推理时间,我们不认为这样会有更好的实用价值。
Experiments
In this section, we present experimental results on the bounding box detection task of the challenging MS-COCO benchmark. Following the protocol in MS-COCO, we use the trainval35k set for training, which is a union of 80k images from train split and a random 35 subset of images from the 40k image val split. To compare with state-of the-art methods, we report COCO AP on the test-dev split, which has no public labels and requires the use of the evaluation server. And then, we report the results of ablation studies evaluated on the mini val split for convenience.
在本节中,我们将介绍具有挑战性的MS-COCO边界框检测任务基准测试的实验结果。 遵循MS-COCO中的协议,我们使用trainval35k集进行训练,这是来自训练集分割的80k图像和来自40k验证集图像分割的随机35个图像子集的并集。 为了与最先进的方法进行比较,我们在test-dev split上报告COCO AP,它没有公开标签,需要使用评估服务器。 然后,为方便起见,我们报告了在小的验证集中评估消融的研究结果。
Our experiment section includes 4 parts: (1) introducing implement details about the experiments; (2) demonstrating the comparisons with state-of-the-art approaches; (3) ablation studies about M2Det; (4) comparing different settings about the internal structure of MLFPN and introducing several version of M2Det.
我们的实验部分包括4个部分:(1)介绍实验的工具细节; (2)展示与最先进方法的比较; (3)关于M2Det的消融研究; (4)比较MLFPN内部结构的不同设置,并介绍几种版本的M2Det。
Implementation details
For all experiments based on M2Det, we start training with warm-up strategy for 5 epochs, initialize the learning rate as 2×10−3, and then decrease it to 2×10−4 and 2×10−5 at 90 epochs and 120 epochs, and stop at 150 epochs. M2Det is developed with PyTorch v0.4.01. When input size is 320and 512, we conduct experiments on a machine with 4 NVIDIA Titan X GPUs, CUDA 9.2 and cuDNN 7.1.4, while for input size of 800, we train the network on NVIDIA Tesla V100 to get results faster. The batch size is set to 32 (16 each for 2 GPUs, or 8 each for 4 GPUs). On NVIDIA Titan Xp that has 12 GB memory, the training performance is limited if batch size on a single GPU is less than 5. Notably, for Resnet101, M2Det with the input size of 512 is not only limited in the batch size (only 4 is available), but also takes a long time to train, so we train it on V100.
对于基于M2Det的所有实验,我们用5个epoch的预热策略开始进行训练,将学习率初始化为2×10-3,然后在90和120个epoch时将其降低到2×10-4和2×10-5。在150个epoch时停止训练。 M2Det是使用PyTorch v0.4.01开发的。 当输入大小为320和512时,我们在具有4个NVIDIA Titan X GPU,CUDA 9.2和cuDNN 7.1.4的机器上进行实验,而对于800的输入大小,我们在NVIDIA Tesla V100上训练网络以更快地获得结果。 批量大小设置为32(2个GPU各16个,4个GPU各8个)。 在具有12 GB内存的NVIDIA Titan Xp上,如果单个GPU上的批量大小小于5,则训练性能有限。值得注意的是,对于Resnet101,输入大小为512的M2Det不仅限于批量大小(仅限4个) 可用),但也需要很长时间训练,所以我们在V100上进行训练。
For training M2Det with the VGG-16 backbone when input size is 320×320 and 512×512 on 4 Titan X devices, the total training time costs 3 and 6 days respectively, and with the ResNet-101 backbone when 320×320 costs 5 days. While for training M2Det with ResNet-101 when input size is 512×512 on 2 V100 devices, it costs 11 days. The most accurate model is M2Det with the VGG backbone and 800×800 input size, it costs 14 days.
当在4个Titan X设备上输入尺寸为320×320和512×512时,使用VGG-16主干训练M2Det,总训练时间分别为3天和6天,而当使用ResNet-101为主干网络,320×320为输入尺寸时需要5天。在2台V100设备上输入尺寸为512×512时使用ResNet-101训练M2Det,需要11天。 最准确的模型是使用VGG骨干网络和800×800输入尺寸的M2Det,它需要14天。
Comparison with State-of-the-art
We compare the experimental results of the proposed M2Det with state-of-the-art detectors in Table 1. For these experiments, we use 8 TUMs and set 256 channels for each TUM. The main information involved in the comparison includes the input size of the model, the test method (whether it uses multi-scale strategy), the speed of the model, and the test results. Test results of M2Det with 10 different setting versions are reported in Table 1, which are produced by testing it on MS-COCO test-dev split, with a single NVIDIA Titan X PASCAL and the batch size 1. Other statistical results stem from references. It is noteworthy that, M2Det-320 with VGG backbone achieves AP of 38.9, which has surpassed most object detectors with more powerful backbones and larger input size, e.g., AP of Deformable R-FCN(Daiet al.2017) is 37.5, AP of Faster R-CNN with FPN is 36.2. As sembled with ResNet-101 can further improve M2Det, the single-scale version obtains AP of 38.8, which is competitive with state-of-the-art two-stage detectors Mask R-CNN (He et al. 2017). In addition, based on the optimization of PyTorch, it can run at 15.8 FPS. RefineDet (Zhang et al. 2018) inherits the merits of one-stage detectors and two stage detectors, gets AP of 41.8, CornerNet (Law and Deng 2018) proposes key point regression for detection and borrows the advantages of Hourglass (Newell, Yang, and Deng 2016) and focal loss(Linetal.2017b),thus gets AP of 42.1. In contrast, our proposed M2Det is based on the regression method of original SSD, with the assistance of Multi-scale Multi-level features, obtains 44.2 AP, which exceeds all one stage detectors. Most approaches do not compare the speed of multi-scale inference strategy due to different methods or tools used, so we also only focus on the speed of single-scale inference methods.
我们将所提出的M2Det与现有技术检测器的实验结果在表1中进行比较。对于这些实验,我们使用8个TUM并为每个TUM设置256个通道。比较中涉及的主要信息包括模型的输入大小,测试方法(是否使用多尺度策略),模型的速度和测试结果。表1中报告了具有10种不同设置版本的M2Det的测试结果,其通过在MS-COCO test-dev split上进行测试而产生,具有单个NVIDIA Titan X PASCAL和批量1。其他统计结果源自参考文献。值得注意的是,具有VGG骨干的M2Det-320达到了38.9的AP,超过了大多数具有更强大骨干和更大输入尺寸的物体探测器,例如,可变形R-FCN(Daiet al.2017)的AP为37.5,AP为FPN更快的R-CNN为36.2。与ResNet-101相结合可以进一步改善M2Det,单级版本获得38.8的AP,这与最先进的两级探测器Mask R-CNN(He et al.2017)相比具有竞争力。此外,基于PyTorch的优化,它可以以15.8 FPS运行。 Re fi neDet(Zhang et al.2018)继承了一级探测器和两级探测器的优点,获得了41.8的AP,CornerNet(Law和Deng 2018)提出了用于探测的关键点回归,并借用了Hourglass(Newell,Yang,和邓2016)和焦点损失(Linetal.2017b),因此获得42.1的AP。相比之下,我们提出的M2Det基于原始SSD的回归方法,在多尺度多级特征的帮助下,获得44.2 AP,超过了所有一级探测器。由于使用的方法或工具不同,大多数方法都没有比较多尺度推理策略的速度,因此我们也只关注单尺度推理方法的速度。
In addition, in order to emphasize that the improvement of M2Det is not entirely caused by the deepened depth of the model or the gained parameters, we compare with state of-the-art one-stage detectors and two-stage detectors. CornerNet with Hourglass has 201M parameters, Mask R-CNN (He et al. 2017) with ResNeXt-101-32x8d-FPN (Xie et al. 2017) has 205M parameters. By contrast, M2Det 800-VGG has only 147M parameters. Besides, consider the comparison of depth, it is also not dominant.
此外,为了强调M2Det的改进并非完全由模型的深度或获得的参数引起,我们将与现有最好的一级检测器和两级检测器进行比较。 带有沙漏的CornerNet具有201M参数,Mask R-CNN(He等人2017)与ResNeXt-101-32x8d-FPN(Xie等人2017)具有205M参数。 相比之下,M2Det 800-VGG只有147M参数。 此外,考虑深度的比较,它也不占优势。
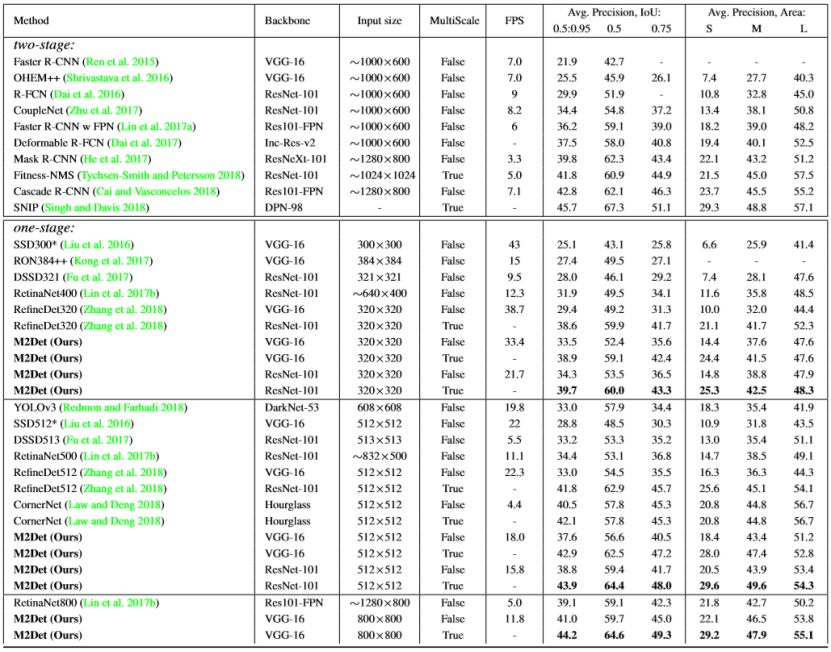
Table 1: Detection accuracy comparisons in terms of mAP percentage on MS COCO test-dev set.
Ablation study
Since M2Det is composed of multiple subcomponents, we need to verify each of its effectiveness to the final performance. The baseline is a simple detector based on the original SSD, with 320×320 input size and VGG-16 reduced backbone.
由于M2Det由多个子组件组成,因此我们需要验证其对最终性能的有效性。 基线是基于原始SSD的简单检测器,具有320×320输入大小和VGG-16修剪的主干网络。
TUM
To demonstrate the effectiveness of TUM, we conduct three experiments. First, following DSSD, we extend the baseline detector with a series of Deconv layers, and the AP has improved from 25.8 to 27.5 as illustrated in the third column in Table2.Then we replace with MLFPN into it .As for the U-shape module, we firstly stack 8 s-TUMs, which is modified to decrease the 1×1 Convolution layers shown in Fig. 4, then the performance has improved 3.1 compared with the last operation, shown in the forth column in Table 2.Finally,replacingTUM by s-TUM in the fifth column has reached the best performance, it comes to AP of 30.8.
为了证明TUM的有效性,我们进行了三次实验。 首先,在DSSD之后,我们使用一系列反卷积层扩展基线检测器,并且AP已经从25.8改进到27.5,如表2中的第三列所示。然后我们将MLFPN替换为它。对于U形模块,我们 首先堆叠8个s-TUM,其被修改以减少图4中所示的1×1卷积层,然后与上一个操作相比,性能提高了3.1,如表2的第四列所示。最后用s-TUM替换TUM达到了最佳性能,如第五列所示,它达到了30.8的AP。
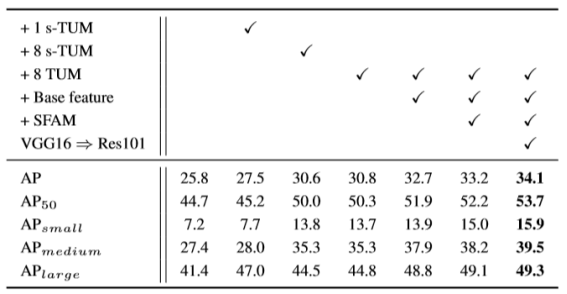
Table 2: Ablation study of M2Det. The detection results are evaluated on minival set
Base feature
Although stacking TUMs can improve detection, but it is limited by input channels of the first TUM. That is, decreasing the channels will drop the abstraction of MLFPN, while increasing them will highly increase the parameters number. Instead of using base feature only once, We afferent base feature at the input of each TUM to alleviate the problem. For each TUM, the embedded base feature provides necessary localization information since it contains shallow features. The AP percentage increases to 32.7, as shown in the sixth column in Table 2.
尽管堆叠TUM可以改善检测,但是它受到第一个TUM的输入通道的限制。 也就是说,减少通道将减少MLFPN的抽象能力,而增加它们将大大增加参数数量。不是仅使用基本特征一次,我们在每个TUM的输入处传达基本特征以缓解该问题。 对于每个TUM,嵌入基本特征提供必要的定位信息,因为它包含浅特征。 AP百分比增加到32.7,如表2中的第六列所示。
SFAM
As shown in the seventh column in Table 2, compared with the architecture that without SFAM, all evaluation metrics have been upgraded. Specifically, all boxes including small, medium and large become more accurate.
如表2第7列所示,与没有SFAM的架构相比,所有评估指标都已升级。 具体而言,所有包括小型,中型和大型的盒子都变得更加准确。
Backbone feature
As in many visual tasks, we observe a noticeable AP gain from 33.2 to 34.1 when we use well Tested ResNet-101(Heetal.2016) instead of VGG-16 as the backbone network. As shown in Table 2, such observation remains true and consistent with other AP metrics.
与许多视觉任务一样,当我们使用ResNet-101(Heetal.2016)而不是VGG-16作为骨干网络时,我们观察到AP从33.2到34.1的明显增益。 如表2所示,这种观察仍然是正确的并且与其他AP指标一致。
Variants of MLFPN
The Multi-scale Multi-level Features have been proved to be effective. But what is the boundary of the improvement brought by MLFPN? Step forward, how to design TUM and how many TUMs should be OK? We implement a group of variants to find the regular patterns. To be more specific, we fix the backbone as VGG-16 and the input image size as 320x320, and then tune the number of TUMs and the number of internal channels of each TUM.
多尺度多级特征已被证明是有效的。 但是,MLFPN带来的改善的边界是什么? 更进一步讲,如何设计TUM以及多少TUM应该可以? 我们实施一组差异对比实验来找到常规模式。 更具体地说,我们将主干网络设为VGG-16,输入图像尺寸为320x320,然后调整每个TUM的TUM数和内部通道数。
As shown in Table3, M2Det with different configurations of TUMs is evaluated on COCO minival set. Comparing the number of TUMs when fixing the channels, e.g.,256, it can be concluded that stacking more TUMs brings more promotion in terms of detection accuracy. Then fixing the number of TUMs, no matter how many TUMs are assembled, more channels consistently benefit the results. Furthermore, assuming that we take a version with 2 TUMS and 128 channels as the baseline, using more TUMs could bring larger improvement compared with increasing the internal channels, while the increase in parameters remains similar.
如表3所示,在COCO小的验证集上评估具有不同TUM配置的M2Det。 比较固定通道时的TUM数量,例如256,可以得出结论,堆叠更多TUM在检测精度方面带来更多提升。 然后确定TUM的数量,无论组装多少TUM,更多的通道始终有利于结果。 此外,假设我们采用具有2个TUMS和128个通道的版本作为基线,与增加内部通道相比,使用更多TUM可以带来更大的改进,而参数的增加保持相似。
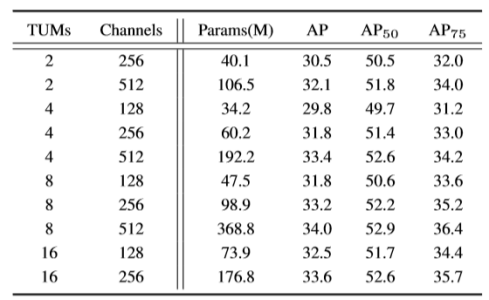
Table 3: Different configurations of MLFPN in M2Det. The backbone is VGG and input image is 320×320.
Speed
We compare the inference speed of M2Det with state-of the-art approaches. Since VGG-16 (Simonyan and Zisserman 2015) reduced backbone has removed FC layers, it is very fast to use it for extracting base feature. We set the batch size to 1, take the sum of the CNN time and NMS time of 1000 images, and divide by 1000 to get the inference time of a single image. We assembleVGG-16 to M2Det and propose the fast version M2Det with the input size 320×320, the standard version M2Det with 512×512 input size and the most accurate version M2Det with 800×800 input size. Based on the optimization of PyTorch, M2Det can achieve accurate results with high speed. As shown in Fig. 5, M2Det benefits the advantage of one-stage detection and our proposed MLFPN structure, draws a significantly better speed-accuracy curve compared with other methods. For fair comparison, we reproduce and test the speed of SSD321-ResNet101, SSD513-ResNet101(Fuetal. 2017), RefineDet512-ResNet101, RefineDet320-ResNet101 (Zhangetal.2018) and CornerNet (Law and Deng 2018)on our device. It is clear that M2Det performs more accurately and efficiently. In addition, replacing Soft-NMS with Hard NMS, the M2Det-VGG-800 can even achieve a speed of 20 fps, only sacrifice little accuracy.
我们将M2Det的推理速度与最先进的方法进行比较。由于VGG-16(Simonyan和Zisserman 2015)减少了主干网(已经删除了FC层),因此使用它来提取基本特征非常快。我们将批量大小设置为1,取1000个图像的CNN时间和NMS时间之和,除以1000得到单个图像的推理时间。我们将VGAG-16组装到M2Det,并提出输入尺寸为320×320的快速版M2Det,具有512×512输入尺寸的标准版M2Det和具有800×800输入尺寸的最准确版M2Det。基于PyTorch的优化,M2Det可以高速实现精确的结果。如图5所示,M2Det得益于一阶段检测和我们提出的MLFPN结构优势,与其他方法相比,能得到明显更好的速度 - 准确度曲线。为了公平比较,我们在我们的设备上重现并测试SSD321-ResNet101,SSD513-ResNet101(Fuetal。2017),Re fi neDet512-ResNet101,Re fi neDet320-ResNet101(Zhangetal.2018)和CornerNet(Law和Deng 2018)的速度。很明显,M2Det可以更准确,更有效地执行。此外,用Hard NMS取代Soft-NMS,M2Det-VGG-800甚至可以达到20 fps的速度,但只有很少的精度损失。
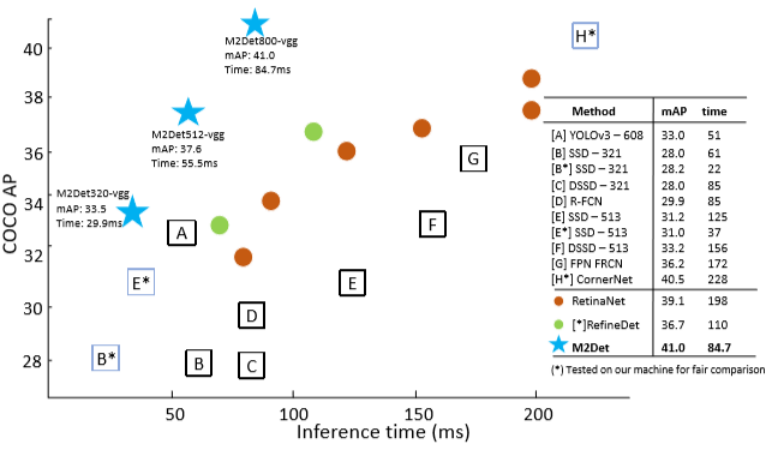
Figure5:Speed(ms) vs. accuracy(mAP) on COCO test-dev.
Discussion
We think the detection accuracy improvement of M2Det is mainly brought by the proposed MLFPN. On one hand, we fuse multi-level features extracted by backbone as the base feature, and then feed it into a block of alternating joint Thinned U-shape Modules and Feature Fusion Modules to extract more representative, multi-level multi-scale features, i.e. the decoder layers of each TUM. Obviously, these decoder layers are much deeper than the layers in the backbone, and thus more representative for object detection. Contrasted with our method, the existing detectors (Zhang et al. 2018; Lin et al. 2017a; Fu et al. 2017) just use the layers of the backbone or extra layers with few depth increase. Hence, our method can achieve superior detection performance. On the other hand, each feature map of the multilevel feature pyramid generated by the SFAM consists of the decoder layers from multiple levels. In particular, at each scale, we use multi-level features to detect objects, which would be better for handling complex appearance variation across object instances.
我们认为M2Det的检测精度提高主要是由提出的MLFPN带来的。一方面,我们将骨干提取的多层特征融合为基本特征,然后将其馈入交替连接的简化U形模块和特征融合模块,以提取更具代表性的多层次多尺度特征,即每个TUM的解码器层。显然,这些解码器层比主干中的层深得多,因此用于物体检测时更有代表性。与我们的方法相比,现有的探测器(Zhang等人,2018; Lin等人,2017a; Fu等人,2017)只使用骨架层或额外层,几乎没有深度增加。因此,我们的方法可以实现卓越的检测性能。另一方面,由SFAM生成的多级特征金字塔的每个特征图包括来自多个级别的解码器层。特别是,在每个比例下,我们使用多级功能来检测对象,这样可以更好地处理跨对象实例的复杂外观变化。
To verify that the proposed MLFPN can learn effective feature for detecting objects with different scales and complex appearances, we visualize the activation values of classification Conv layers along scale and level dimensions, such an example shown in Fig. 6. The input image contains two persons, two cars and a traffic light. Moreover, the sizes of the two persons are different, as well as the two cars. And the traffic light, the smaller person and the smaller car have similar sizes. We can find that: 1) compared with the smaller person, the larger person has strongest activation value at the feature map of large scale, so as to the smaller car and larger car; 2) the traffic light, the smaller person and the smaller car have strongest activation value at the feature maps of the same scale; 3) the persons, the cars and the traffic light have strongest activation value at the highest-level, middle-level, lowest-level feature maps respectively. This example presents that: 1) our method learns very effective features to handle scale variation and complex appearance variation across the object instances; 2) it is necessary to use multilevel features to detect objects with similar size.
为了验证所提出的MLFPN能够学习用于检测具有不同尺度和复杂外观的物体的有效特征,我们可以根据比例和水平尺寸来显示分类Conv层的激活值,如图6所示。输入图像包含两个人,两辆车和一个交通灯。此外,两个人以及两辆车的大小不同。交通灯,较小的人和较小的汽车有相似的尺寸。我们可以发现:1)与较小的人相比,较大的人在大尺度的特征图上具有最强的激活值,对于较小的汽车和较大的汽车也一样; 2)交通灯,较小的人和较小的汽车在相同比例的特征图上具有最强的激活值; 3)人员,汽车和交通灯分别在最高级别,中级别,最低级别的特征地图中具有最强的激活值。这个例子表明:1)我们的方法学习非常有效的特征来处理对象实例中的尺度变化和复杂的外观变化; 2)有必要使用多级特征来检测具有相似大小的对象。
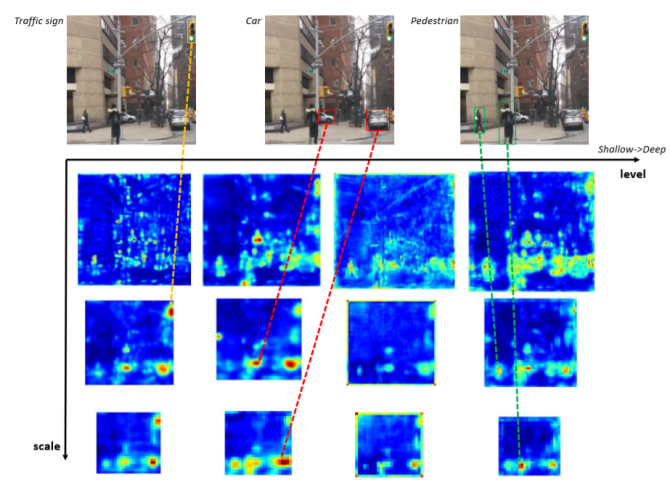
Figure 6: Example activation values of multi-scale multilevel features. Best view in color.
Conclusion
In this work, a novel method called Multi-Level Feature Pyramid Network (MLFPN) is proposed to construct effective feature pyramids for detecting objects of different scales. MLFPN consists of several novel modules. First, multi-level features (i.e. multiple layers) extracted by backbone are fused by a Feature Fusion Module (FFMv1) as the base feature. Second, the base feature is fed into a block of alternating joint Thinned U-shape Modules(TUMs) and Fature Fusion Modules (FFMv2s) and multi-level multi-scale features (i.e. the decoder layers of each TUM) are extracted. Finally, the extracted multi-level multi-scale features with the same scale (size) are aggregated to construct a feature pyramid for object detection by a Scale-wise Feature Aggregation Module (SFAM). A powerful end-to-end one-stage object detector called M2Det is designed based on the proposed MLFPN, which achieves a new state-of-the-art result (i.e. AP of 41.0 at speed of 11.8 FPS with single-scale inference strategy and AP of 44.2 with multi-scale inference strategy) among the one-stage detectors on MS-COCO benchmark. Additional ablation studies further demonstrate the effectiveness of the proposed architecture and the novel modules。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号