[炼丹术]使用Pytorch搭建模型的步骤及教程
使用Pytorch搭建模型的步骤及教程
我们知道,模型有一个特定的生命周期,了解这个为数据集建模和理解 PyTorch API 提供了指导方向。我们可以根据生命周期的每一个步骤进行设计和优化,同时更加方便调整各种细节。
模型的生命周期的五个步骤如下:
- 1.准备数据
- 2.定义模型
- 3.训练模型
- 4.评估模型
- 5.进行预测
注意:使用 PyTorch API 有很多方法可以实现这些步骤中的每一个,下面是一些使用Pytorch API最简单、最常见或最惯用的方法。
一、准备数据
第一步是加载和准备数据。
神经网络模型需要数值输入数据和数值输出数据。
您可以使用标准 Python 库来加载和准备表格数据,例如 CSV 文件。例如,Pandas 可用于加载 CSV 文件,scikit-learn 中的工具可用于编码分类数据,例如类标签。
PyTorch 提供了Dataset 类,您可以对其进行扩展和自定义以加载数据集。
例如,您的数据集对象的构造函数可以加载您的数据文件(例如 CSV 文件)。然后可以覆盖__len __()可以被用于获取数据集(行或样本数)的长度函数和__getitem __() ,其用于获得由索引的特定示例函数。
加载数据集时,您还可以执行任何所需的转换,例如缩放或编码。
下面提供了自定义数据集类的骨架。
# dataset definition
class CSVDataset(Dataset):
# load the dataset
def __init__(self, path):
# store the inputs and outputs
self.X = ...
self.y = ...
# number of rows in the dataset
def __len__(self):
return len(self.X)
# get a row at an index
def __getitem__(self, idx):
return [self.X[idx], self.y[idx]]
加载后,PyTorch 提供DataLoader 类以在模型的训练和评估期间导航Dataset实例。
可以为训练数据集、测试数据集甚至验证数据集创建一个DataLoader实例。
所述random_split()函数可以被用于将数据集分裂成训练集和测试集。拆分后,可以将数据集中的行选择提供给 DataLoader,同时提供批量大小以及是否应在每个 epoch 中对数据进行混洗。
random_split(dataset, lengths)
返回从原始数据集随机拆分的 n 个非重叠数据集。lengths 参数指定每个拆分的长度。
例如,我们可以通过传入数据集中的选定行样本来定义DataLoader。
DataLoader(dataset, batch_size=1, shuffle=False)
返回给定数据集的迭代,每批具有指定数量的样本。该函数还有许多其他参数。
shuffle参数设置为“True”,以便在每个epoch之后对数据进行shuffled。这对于验证和测试数据集是不必要的,因为我们将只对它们进行评估,而顺序并不重要。
...
# create the dataset
dataset = CSVDataset(...)
# select rows from the dataset
train, test = random_split(dataset, [[...], [...]])
# create a data loader for train and test sets
train_dl = DataLoader(train, batch_size=32, shuffle=True)
test_dl = DataLoader(test, batch_size=1024, shuffle=False)
定义后,可以枚举DataLoader,每次迭代产生一批样本。
# train the model
for i, (inputs, targets) in enumerate(train_dl):
...
二、定义模型
下一步是定义模型。
在 PyTorch 中定义模型的习惯用法涉及定义一个扩展Module 类的类。
nn.Module 是为所有神经网络模型扩展的基类。我们定义的模型有四个功能
1.__ init __(self)
该函数调用超类的构造函数。这是强制性的。
此处使用 torch.nn 库定义了该模型的不同层。层的类型和数量特定于手头的问题。它可以是单层线性模型,也可以是基于复杂数学模型的多层。
还声明了每一层的输入和输出大小以及其他必需的参数。每层的大小和其他值可以作为构造函数中的参数进行检索,从而允许模型实例具有可变架构或硬编码。
2.forward(self, x)
此函数定义数据如何通过一次前向传递。可以从 torch.nn.functional 库定义不同层的激活函数。
3.training_step(self,batch)
在这个函数中,我们定义了模型的一个训练步骤,该步骤接收一批数据并返回损失。
对于给定的批次,我们将输入和目标分开,这里是图像及其标签。输入通过使用“ self ”关键字调用的 forward 函数传递,以获得输出。
将适当的损失函数应用于输出和目标以计算损失。
4.validation_step(self,batch)
在这个函数中,我们定义了一个验证步骤,即我们评估当前状态的模型。
给定批次的损失是按照上面的 training_step() 函数中的描述计算的。除此之外,还可以评估其他几个指标,例如准确度、auc、精确度、召回率等等。
这些指标的结果用于评估模型的性能,而不是用于训练过程。因此,我们将.detach()应用于结果以将它们从梯度计算中排除。
对来自 DataLoader 对象的每批数据调用模型的 validation_step() 函数。输出列表可以看作是一个二维数组,每一行对应一个批次,每一行按顺序保存损失和 n 个度量的值。
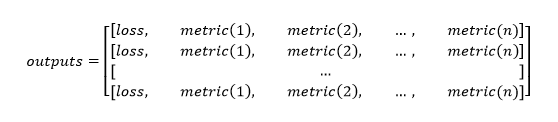
它的转置如下:

这使得使用 torch.mean() 函数更容易计算平均损失和其他指标。.item() 函数用于返回数值而不是单值张量。
fit拟合函数
fit 函数接受许多参数,其中一个是默认优化函数。创建了优化器的一个实例。在每个epoch:
- 每一批训练集都经过模型的training_step()函数得到loss。
- 梯度是使用 .backward() 函数计算的。
- 优化器根据梯度更新权重和偏差。
- 梯度值被重置为 0,这样它们就不会在 epoch 上累积。
- 在训练阶段结束时,将评估验证集并将结果附加到历史记录中。
你的类的构造函数定义了模型的层,而 forward() 函数是定义如何通过模型的定义层向前传播输入的覆盖。
此外,Pytorch Module还有许多网络层级可用,例如Linear用于全连接层,Conv2d用于卷积层,MaxPool2d用于池化层。
激活函数也可以定义为层,例如ReLU、Softmax和Sigmoid。
下面是一个具有一层的简单 MLP 模型的示例。
# model definition
class MLP(Module):
# define model elements
def __init__(self, n_inputs):
super(MLP, self).__init__()
self.layer = Linear(n_inputs, 1)
self.activation = Sigmoid()
# forward propagate input
def forward(self, X):
X = self.layer(X)
X = self.activation(X)
return X
给定层的权重也可以在构造函数中定义层后初始化。
...
xavier_uniform_(self.layer.weight)
三、训练模型
训练过程要求您定义损失函数和优化算法。
常见的损失函数包括:
- BCELoss:二元分类的二元交叉熵损失。
- CrossEntropyLoss:多类分类的分类交叉熵损失。
- MSELoss:回归的均方损失。
有关损失函数的更多信息,请参阅教程:
使用随机梯度下降进行优化,标准算法由SGD 类提供,尽管该算法的其他版本也可用,例如Adam。
# define the optimization
criterion = MSELoss()
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
训练模型涉及枚举训练数据集的DataLoader。
首先,训练时期的数量需要一个循环。然后,随机梯度下降的小批量需要一个内循环。
...
# enumerate epochs
for epoch in range(100):
# enumerate mini batches
for i, (inputs, targets) in enumerate(train_dl):
...
模型的每次更新都涉及相同的一般模式,包括:
- 清除最后一个误差梯度。
- 输入通过模型的前向传递。
- 计算模型输出的损失。
- 通过模型反向传播错误。
- 更新模型以减少损失。
...
# clear the gradients
optimizer.zero_grad()
# compute the model output
yhat = model(inputs)
# calculate loss
loss = criterion(yhat, targets)
# credit assignment
loss.backward()
# update model weights
optimizer.step()
四、评估模型
一旦模型拟合好,就可以在测试数据集上对其进行评估。
这可以通过将DataLoader用于测试数据集并收集测试集的预测,然后将预测与测试集的预期值进行比较并计算性能指标来实现。
...
for i, (inputs, targets) in enumerate(test_dl):
# evaluate the model on the test set
yhat = model(inputs)
...
五、进行预测
拟合模型可用于对新数据进行预测。
例如,您可能有一张图像或一行数据,并且想要进行预测。
这要求您将数据包装在PyTorch Tensor数据结构中。
Tensor只是用于保存数据的 NumPy 数组的 PyTorch 版本。它还允许您在模型图中执行自动微分任务,例如在训练模型时调用Backward()。
预测也将是一个Tensor,尽管您可以通过从自动微分图中分离张量并调用 NumPy 函数来检索 NumPy 数组。
...
# convert row to data
row = Variable(Tensor([row]).float())
# make prediction
yhat = model(row)
# retrieve numpy array
yhat = yhat.detach().numpy()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号