[决策树]西瓜数据graphviz可视化实现
[决策树]西瓜数据graphviz可视化实现
一、问题描述:
使用西瓜数据集构建决策树,并将构建的决策树进行可视化操作。
二、问题简析:
首先我们简单的介绍一下什么是决策树。决策树是广泛用于分类和回归任务的模型。本质上,它从一层层的if/else问题中进行学习,并得出结论。
三、代码实现:
说明:本实例运行在linux环境下,通过jupyter notebook运行。
依赖项:graphviz
下载GraphViz’s executables的网址:http://www.graphviz.org/
用pip安装的Graphviz,但是Graphviz不是一个python tool,仍然需要安装GraphViz’s executables。
sudo apt-get install graphviz
代码如下:
from random import choice
from collections import Counter
import math
# 定义数据集
D = [
{'色泽': '青绿', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '蜷缩', '敲声': '沉闷', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '青绿', '根蒂': '蜷缩', '敲声': '沉闷', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '浅白', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '青绿', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '清晰', '脐部': '稍凹', '触感': '软粘', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '稍糊', '脐部': '稍凹', '触感': '软粘', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '清晰', '脐部': '稍凹', '触感': '硬滑', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '沉闷', '纹理': '稍糊', '脐部': '稍凹', '触感': '硬滑', '好瓜': '否'},
{'色泽': '青绿', '根蒂': '硬挺', '敲声': '清脆', '纹理': '清晰', '脐部': '平坦', '触感': '软粘', '好瓜': '否'},
{'色泽': '浅白', '根蒂': '硬挺', '敲声': '清脆', '纹理': '模糊', '脐部': '平坦', '触感': '硬滑', '好瓜': '否'},
{'色泽': '浅白', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '模糊', '脐部': '平坦', '触感': '软粘', '好瓜': '否'},
{'色泽': '青绿', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '稍糊', '脐部': '凹陷', '触感': '硬滑', '好瓜': '否'},
{'色泽': '浅白', '根蒂': '稍蜷', '敲声': '沉闷', '纹理': '稍糊', '脐部': '凹陷', '触感': '硬滑', '好瓜': '否'},
{'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '清晰', '脐部': '稍凹', '触感': '软粘', '好瓜': '否'},
{'色泽': '浅白', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '模糊', '脐部': '平坦', '触感': '硬滑', '好瓜': '否'},
{'色泽': '青绿', '根蒂': '蜷缩', '敲声': '沉闷', '纹理': '稍糊', '脐部': '稍凹', '触感': '硬滑', '好瓜': '否'},
]
# ==========
# 决策树生成类
# ==========
class DecisionTree:
def __init__(self, D, label, chooseA):
self.D = D # 数据集
self.label = label # 哪个属性作为标签
self.chooseA = chooseA # 划分方法
self.A = list(filter(lambda key: key != label, D[0].keys())) # 属性集合A
# 获得A的每个属性的可选项
self.A_item = {}
for a in self.A:
self.A_item.update({a: set(self.getClassValues(D, a))})
self.root = self.generate(self.D, self.A) # 生成树并保存根节点
# 获得D中所有className属性的值
def getClassValues(self, D, className):
return list(map(lambda sample: sample[className], D))
# D中样本是否在A的每个属性上相同
def isSameInA(self, D, A):
for a in A:
types = set(self.getClassValues(D, a))
if len(types) > 1:
return False
return True
# 构建决策树,递归生成节点
def generate(self, D, A):
node = {} # 生成节点
remainLabelValues = self.getClassValues(D, self.label) # D中的所有标签
remainLabelTypes = set(remainLabelValues) # D中含有哪几种标签
if len(remainLabelTypes) == 1:
# 当前节点包含的样本全属于同个类别,无需划分
return remainLabelTypes.pop() # 标记Node为叶子结点,值为仅存的标签
most = max(remainLabelTypes, key=remainLabelValues.count) # D占比最多的标签
if len(A) == 0 or self.isSameInA(D, A):
# 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
return most # 标记Node为叶子结点,值为占比最多的标签
a = self.chooseA(D,A,self) # 划分选择
for type in self.A_item[a]:
condition = (lambda sample: sample[a] == type) # 决策条件
remainD = list(filter(condition, D)) # 剩下的样本
if len(remainD) == 0:
# 当前节点包含的样本集为空,不能划分
node.update({type: most}) # 标记Node为叶子结点,值为占比最多的标签
else:
# 继续对剩下的样本按其余属性划分
remainA = list(filter(lambda x: x != a, A)) # 未使用的属性
_node = self.generate(remainD, remainA) # 递归生成子代节点
node.update({type: _node}) # 把生成的子代节点更新到当前节点
return {a: node}
# 定义划分方法
# 随机选择
def random_choice(D, A, tree: DecisionTree):
return choice(A)
# 信息熵
def Ent(D,label,a,a_v):
D_v = filter(lambda sample:sample[a]==a_v,D)
D_v = map(lambda sample:sample[label],D_v)
D_v = list(D_v)
D_v_length = len(D_v)
counter = Counter(D_v)
info_entropy = 0
for k, v in counter.items():
p_k = v / D_v_length
info_entropy += p_k * math.log(p_k, 2)
return -info_entropy
# 信息增益
def information_gain(D, A, tree: DecisionTree):
gain = {}
for a in A:
gain[a] = 0
values = tree.getClassValues(D, a)
counter = Counter(values)
for a_v,nums in counter.items():
gain[a] -= (nums / len(D)) * Ent(D,tree.label,a,a_v)
return max(gain.keys(),key=lambda key:gain[key])
# 创建决策树
desicionTreeRoot = DecisionTree(D, label='好瓜',chooseA=information_gain).root
print('决策树:', desicionTreeRoot)
# 决策树可视化类
class TreeViewer:
def __init__(self):
from graphviz import Digraph
self.id_iter = map(str, range(0xffff))
self.g = Digraph('G', filename='decisionTree.gv')
def create_node(self, label, shape=None):
id = next(self.id_iter)
self.g.node(name=id, label=label, shape=shape, fontname="Microsoft YaHei")
return id
def build(self, key, node, from_id):
for k in node.keys():
v = node[k]
if type(v) is dict:
first_attr = list(v.keys())[0]
id = self.create_node(first_attr+"?", shape='box')
self.g.edge(from_id, id, k, fontsize = '12', fontname="Microsoft YaHei")
self.build(first_attr, v[first_attr], id)
else:
id = self.create_node(v)
self.g.edge(from_id, id, k, fontsize = '12', fontname="Microsoft YaHei")
def show(self, root):
first_attr = list(root.keys())[0]
id = self.create_node(first_attr+"?", shape='box')
self.build(first_attr, root[first_attr], id)
self.g.view()
# 显示创建的决策树
viewer = TreeViewer()
viewer.show(desicionTreeRoot)
输出结果:
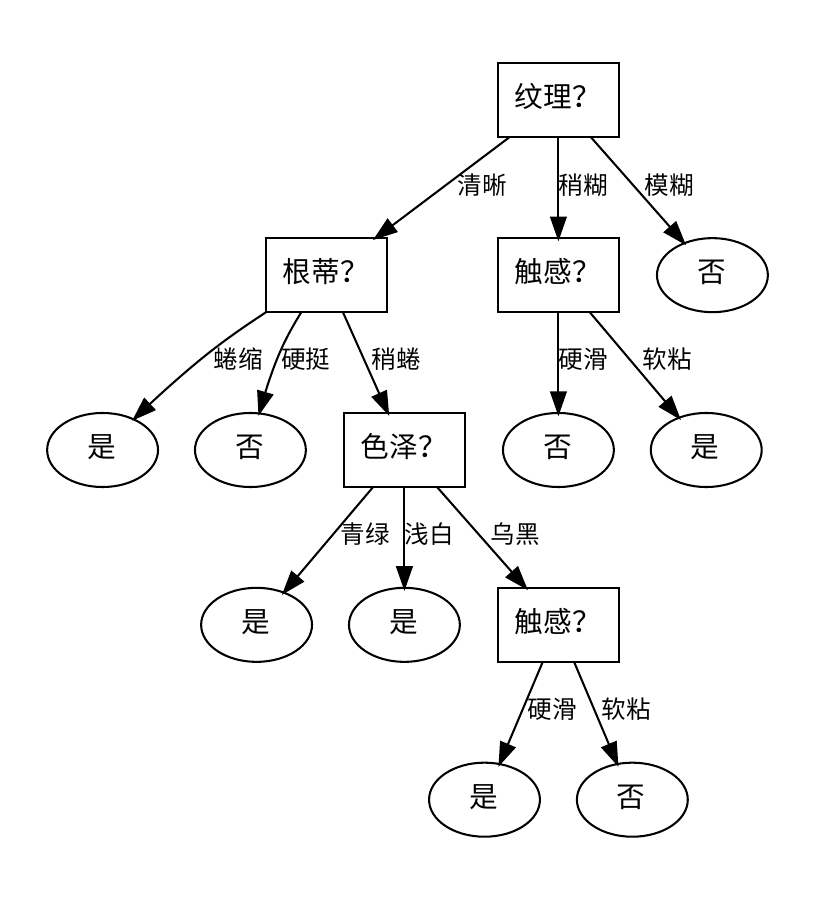
决策树: {'纹理': {'清晰': {'根蒂': {'蜷缩': '是', '硬挺': '否', '稍蜷': {'色泽': {'青绿': '是', '浅白': '是', '乌黑': {'触感': {'硬滑': '是', '软粘': '否'}}}}}}, '稍糊': {'触感': {'硬滑': '否', '软粘': '是'}}, '模糊': '否'}}
在jupyter notebook的运行效果如图:
Talk is cheap. Show me the code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号