[机器学习]实用数据挖掘与人工智能一月特训班-熟悉Jupyter notebook
熟悉Jupyter notebook
- python环境与版本
- 几个重要的工具:numpy, scipy, sklearn, pandas, keras, tensorflow
- 安装tensorflow与keras
- jupyter notebook基本使用
- markdown的用法
1.Python环境与版本
python语言是一种简单易学的脚本语言。脚本语言就是不用编译的语言。C语言需要经历“编写、编译、链接、运行”(edit->compile->link->run)整个过程,而脚本语言只用“解释、运行”即可,而不用“编译、链接”
众多的版本(解释器的版本)以及其配套的工具包与安装包地址,可能造成了使用起来的混乱。比如说在命令行里面给python3.6安装了numpy,但在python2.7里面想调用python3.6的numpy就不行,需要对应起来。Anaconda就提供了一个比较好的环境是,将不同版本的python分开使用。
在选择最新版本的Anaconda时,请选择python3.6版本。现在众多工具包已经宣布停止对python2.7版本的维护和升级,转向python3.6。我们也需要与时俱进。
1.1 python虚拟环境管理
可以通过anaconda安装不同的环境,进行管理。
分清python环境为什么重要?
- 避免语法版本不一致引起的错误
- 避免工具包安装与调用的混乱
1.1.1 新建python环境
方法:在终端命令行中执行以下代码
conda create -n py27 python=2.7
conda create -n py36 python=3.6
1.1.2 激活python环境
(Mac user)source active py27
(Linux user)conda activate py27
(Windows user)activate py27
1.1.3 安装环境kernel
pip install ipykernel
python -m ipykernel install --user
kernel.json
{
"display_name":"Python 2",
"language":"python",
"argv":[
"/home/linxu/.local/share/jupyter/kernels/py27",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
]
}
1.1.4 退出当前环境
mac user > source deactivate env_name
windows user > deactivate env_name
linux user > conda deactivate env_name
1.1.5 查看已安装的环境
以下三种命令均可查看已有环境:
conda info -e
conda info --env
conda env list
查看结果显示如下:
# conda environments:
#
base * /home/linxu/Apps/Anaconda3
py27 /home/linxu/Apps/Anaconda3/envs/py27
py36 /home/linxu/Apps/Anaconda3/envs/py36
其中,带“*”的符号,表现当前使用的环境,默认是在base环境下。
1.1.6 删除已安装的python环境
conda remove -n py27 --all
1.1.7 如何加到可选的Kernel中?(针对jupyter notebook的使用)
conda create -n env_name python=x.x # 创建环境
conda activate env_name # 激活环境 linux user
# mac user > source activate env_name
# windows user > activate env_name
# linux user > conda activate env_name
pip install ipykernel # 安装内核
python -m ipykernel install --name env_name # windows
python -m ipykernel install --user --name env_name # linux
My kernel space address is: /home/linxu/.local/share/jupyter/kernels/py27
/home/linxu/.local/share/jupyter/kernels/py36
查看已有kernel
jupyter kernelspec list
1.2 Package 包管理
若未进入到指定的某个虚拟环境,则可使用-n env_name 的方式去指定对某个虚拟环境安装软件。
命令如下:
-
1.2.1指定环境下的Package包管理
1.2.1.1 查看指定环境下已安装的Package包
conda list -n env_name1.2.1.2 安装指定环境下某个Package
conda install -n env_name [package] #例 conda install -n py36 numpy1.2.1.3 删除指定环境下某个Package
conda remove -n env_name [package] #例 conda remove -n py36 numpy1.2.1.4 更新指定环境下某个Package
conda update -n env_name [package]
-
1.2.2 当前环境下的Package包管理
1.2.2.1 查看已经安装的Package
conda list1.2.2.2 安装某个Package
conda install [package]1.2.2.3 删除某个Package
conda remove [package]1.2.2.4 更新某个package
conda update [package]1.2.2.5 更新conda,保持conda最新
conda update conda
- 补充
安装完anaconda后,发现每次打开终端后都会自动进入到base的虚拟环境中去,可以使用conda deactivate退出。也可以关闭自动打开的虚拟环境,命令如下
conda config --set auto_activate_base false
参考:
Conda 创建和删除虚拟环境-Author:行路南
1.3 安装决策树可视化工具Graphviz
1.3.1 Graphviz 安装与依赖
下载
下载GraphViz’s executables的网址:http://www.graphviz.org/
用pip安装的Graphviz,但是Graphviz不是一个python tool,仍然需要安装GraphViz’s executables。
sudo apt install graphviz
依赖项
conda install pydotplus # pydotplus
conda install scikit-learn # sklearn
conda install pandas # pandas
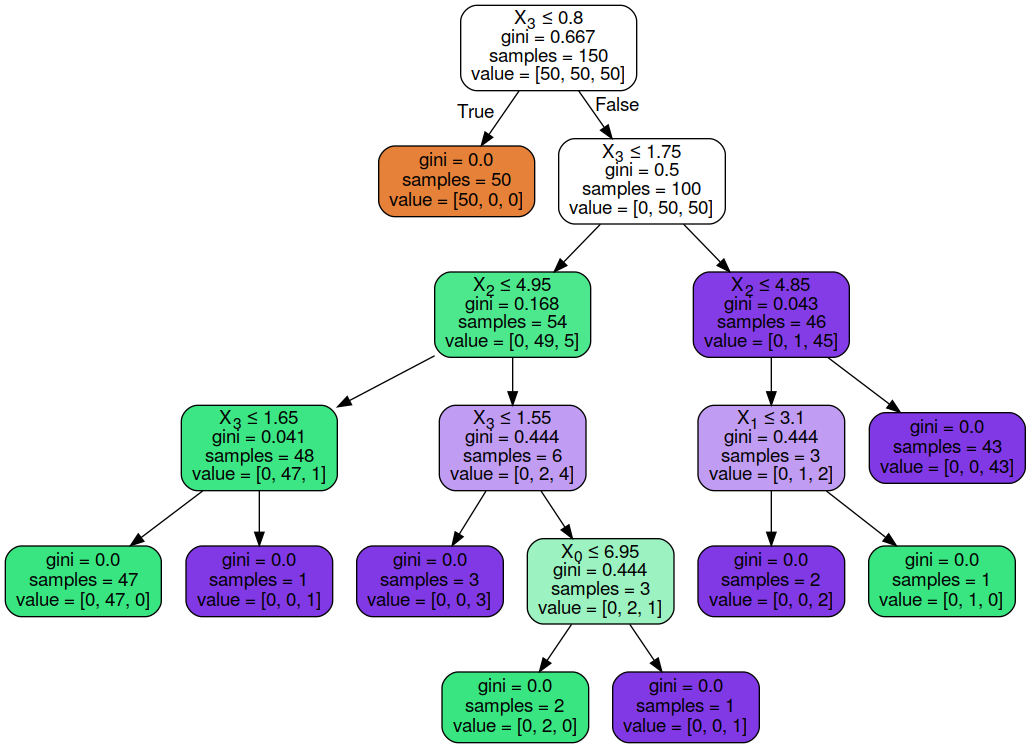
实例1 决策树graphviz可视化
import graphviz
import sklearn.datasets as datasets
import pandas as pd
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier()
dtree.fit(df, y)
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(dtree, out_file=dot_data, filled = True, rounded = True,special_characters = True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
输出
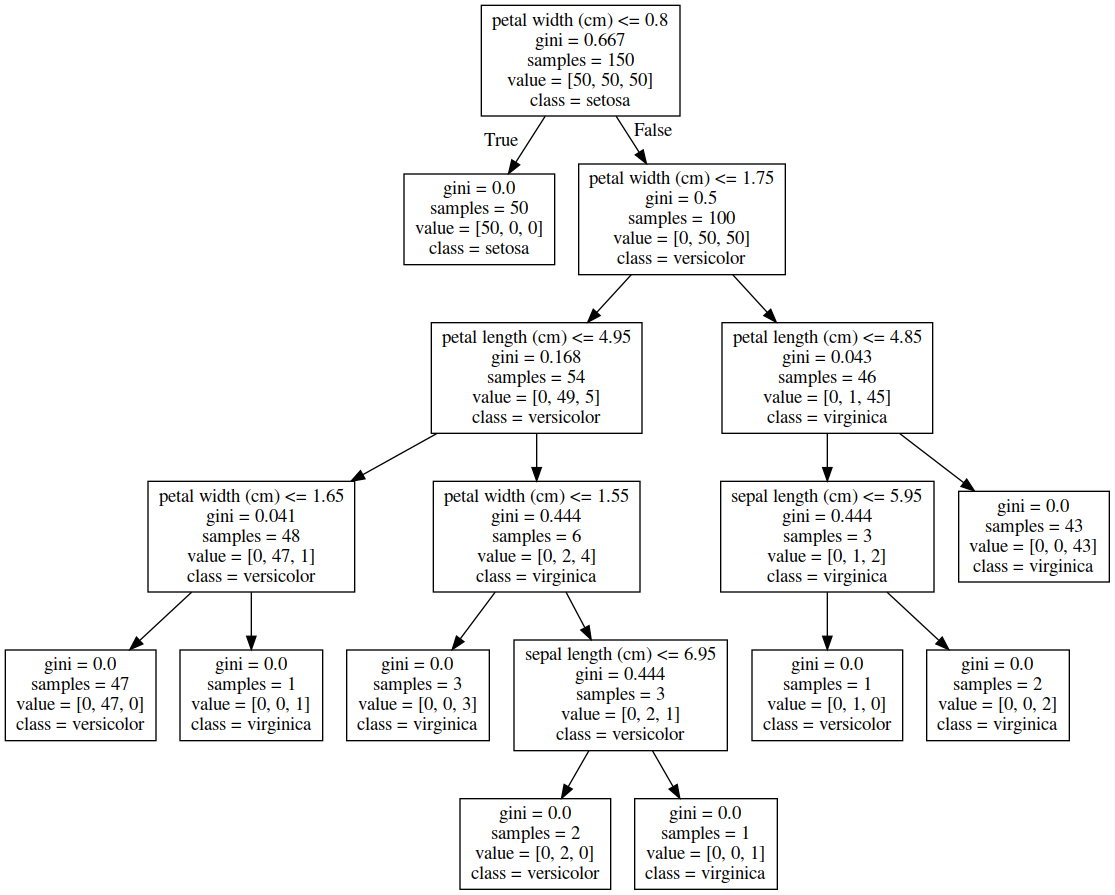
实例2 鸢尾花数据集-决策树graphviz可视化
from sklearn.datasets import load_iris # 导入类库
from IPython.display import Image
from sklearn import tree
import graphviz
iris = load_iris() # 载入sciki-learn的自带数据
features = iris.data
target = iris.target
clf = tree.DecisionTreeClassifier() # 载入决策树分类模型
clf = clf.fit(features, target) # 决策树拟合,得到模型
dot_data = tree.export_graphviz(clf,
out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png('iris.png')
Image(graph.create_png())
输出
sklearn 玩具数据集
除鸢尾花数据集之外, sklearn 还有一些举例用的玩具数据集, 可以直接用如下函数加载
鸢尾花数据集, 可以用来做分类练习
load_iris([return_X_y])
波士顿房价数据集, 可以用来做回归分析
load_boston([return_X_y])
糖尿病数据集, 可用来做回归分析
load_diabetes([return_X_y])
数字数据集, 可以用来做分类练习
load_digits([n_class, return_X_y])
兰纳胡德体能训练的数据, 可用来做多变量回归分析
load_linnerud([return_X_y])
酒类数据集, 可用做分类练习
load_wine([return_X_y])
乳腺癌数据集, 可用做分类练习
load_breast_cancer([return_X_y])
如果你需要原始数据文件, 可以从 https://archive.ics.uci.edu/ml/datasets.html 下载这些数据集,其中鸢尾花数据集就在 https://archive.ics.uci.edu/ml/machine-learning-databases/iris/
Markdown的基本技巧
1.标题
# h1
## h2
### h3
#### h4
h1
h2
h3
h4
2.划重点
黑体 —> **黑体**
斜体 —> *斜体*
下划线 —> <u>下划线</u>
引用一段话 >show me the code
注释 <!--注释-->
黑体 —> 黑体
斜体 —> 斜体
下划线 —> 下划线
引用一段话
show me the code
注释
3.段落列表
3.1 无序列表
- 观点1
- 观点2
- 观点3
- 观点1
- 观点2
- 观点3
3.2 有序列表
1. 第一章
* 第一节
* 第二节
* 第三节
2. 第二章
3. 第三章
- 第一章
- 第一节
- 第二节
- 第三节
- 第二章
- 第三章
3.3 任务列表
- [ ] 任务1
- [ ] 任务2
- [ ] 任务2
4.段落内容
4.1 插入数学公式块
\sum_{\forall i}{x_i^(2)}
e^{i\pi}+1=o
\begin{align}
\dot{x} & = \sigma(y-x) \\
\dot{y} & = \rho x -y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
4.2 插入代码块
using namespace std;
int main() {
std::cout << "hello world" << endl;
}
#include<iostream>
using namespace std;
int main() {
std::cout << "hello world" << endl;
}
4.2 插入图像
第一种写法


第二种写法
<img src='/home/linxu/Pictures/pic/宇航员头像.jpg',width=200>
4.4 插入超链接

4.5 插入表格
| 1 | 2 | 3 |
| :----: |:----:| :----:|
| 4 | 5 | 6 |
| 7 | 8 | 9 |
冒号:表示对齐
例如 :xx 为左对齐
xx: 为右对齐
:xx: 为居中对齐
| 1 | 2 | 3 |
|---|---|---|
| 4 | 5 | 6 |
| 7 | 8 | 9 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号