[机器学习笔记]幂次学院西瓜书集训营-第一章机器学习简介
第一章 机器学习简介
1.1 机器学习概述
机器学习:研究如何构造理论、算法和计算机系统,让机器通过从数据中学习后可以进行如下工作:分类和识别事物、推理决策、预测未来等。
Wiki:“The design and development of algorithms that take as input empirical data and yield patterns or predictions that generated the data”。
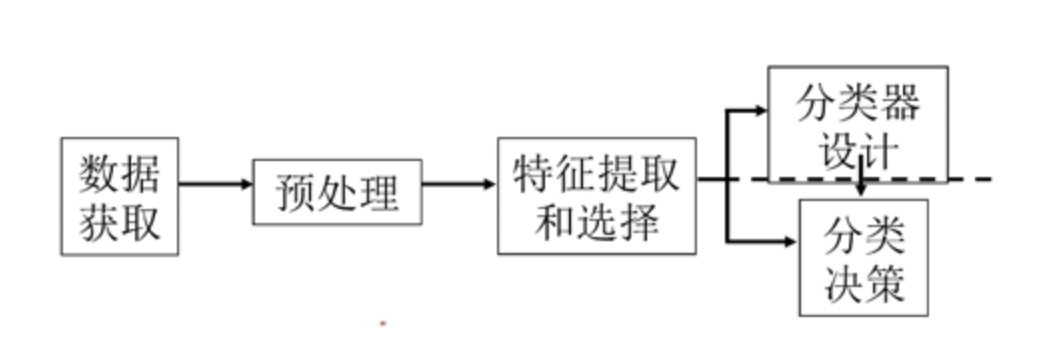
1.2 机器学习与人脑学习的对比
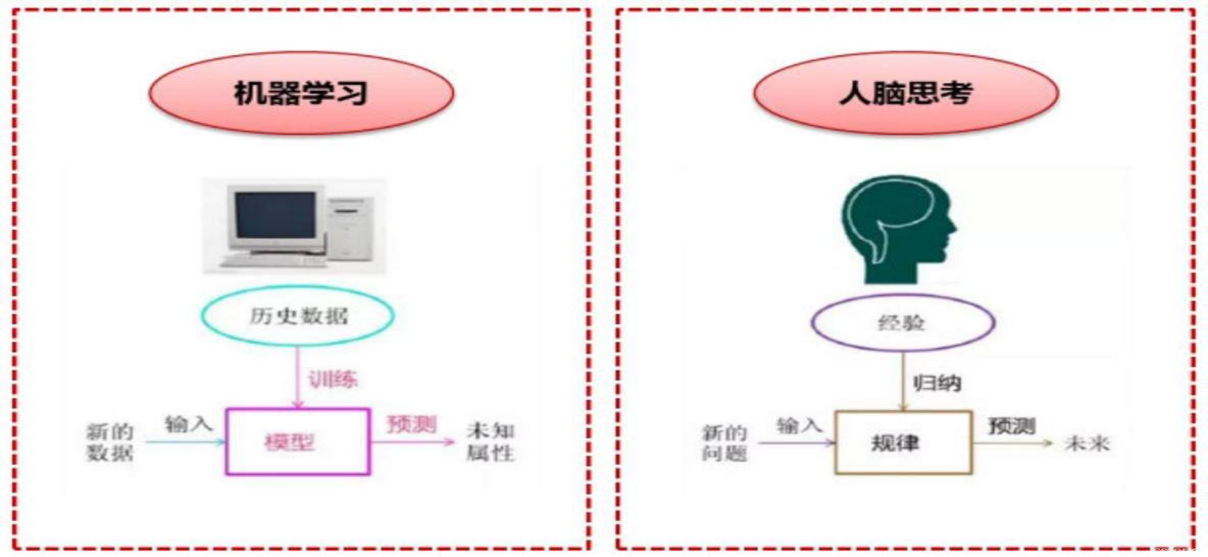
1.3 主要分类和学习方法

1.3.1 数据聚类
- 目标:用某种相似性度量的方法将原始数据组织成有意义的和有用的各种数据集。
- 是一种非监督学习的方法,解决方案是数据驱动的。
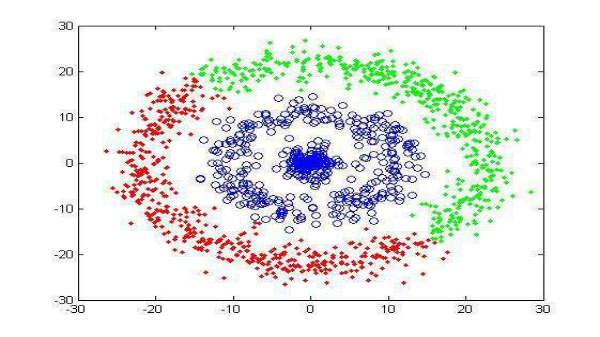
1.3.2 统计分类
-
基于概率统计模型得到各类别的特征向量的分布,以取得分类的方法。
-
特征向量分布的获得是基于一个类别已知的训练样本集。是一种监督分类的方法,分类器是概念驱动的。
-
相似度模型(Rocchio、K-近邻)、概率模型(贝叶斯)、线性模型(LLSF、SVM) 、非线性模型(决策树、神经网络)、组合模型。
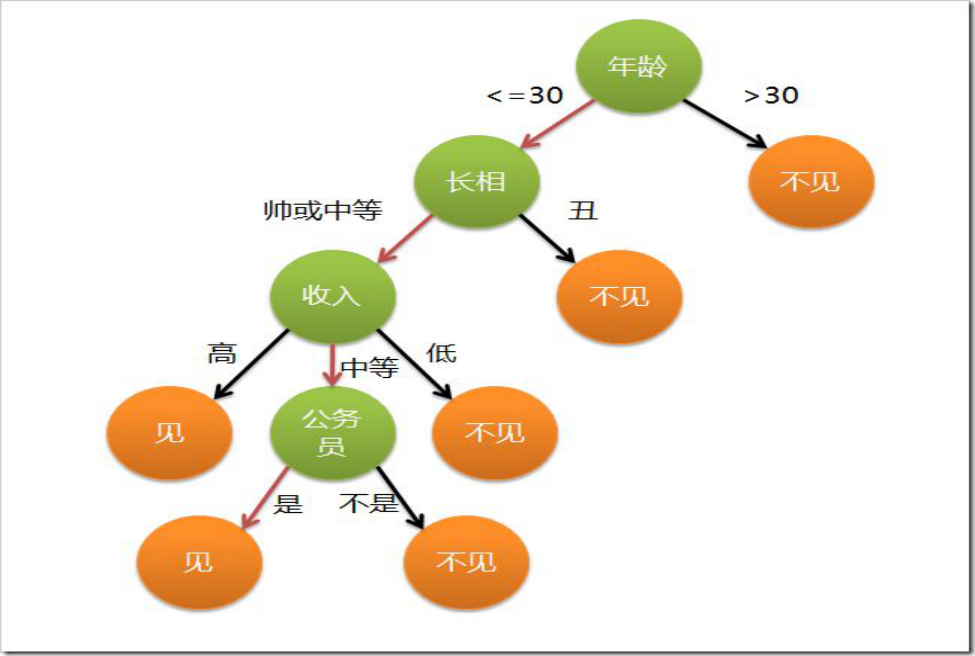
e.g:在深度学习兴起之前,随机森林与SDM在两个不同领域上的表现良好,且应用较多。
1.3.3 神经网络
- 神经网络是受人脑组织的生理学启发而创立的
- 由一系列互相联系的、相同的单元(神经元)组成。相互间的联系可以在不同的神经元之间传递增强或抑制信号。
- 增强或抑制是通过神经元相互间联系的权重系数(weight)来实现的。
- 神经网络可以实现监督和非监督学习条件下的分类。

1.3.4 监督学习
- 监督学习是从有标记的训练数据来推断或建立一个模型,并依此模型推测新的实例。
- 训练数据包括一套训练实例。在监督学习中,每个实例都是一个输入对象(通常是矢量)和一个期望的输出值(也称为监督信号)组成。
- 一个最佳的模型将能够正确地决定那些看不见的实例的标签。常用于分类和回归。
e.g: 如何区分分类和回归?
分类: 若识别的结果是离散的,有限的,可数的,则该任务是分类任务。
回归: 若识别的结果是连续的,无限的,不可数的,则该任务为回归任务。
1.3.5 无监督学习
- 无监督学习是我们不告诉计算机怎么做,而是让它自己去学习怎样做一些事情。
- 无监督学习与监督学习的不同之处在于,事先没有任何训练样本,需要直接对数据进行建模,寻找数据的内在结构及规律,如类别和聚类。
- 常用于聚类、概率密度估计。
1.3.6 半监督学习
- 半监督学习(Semi-supervised Learnin)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。
- 它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。
- 半监督学习的主要算法有五类:基于概率的算法;在现有监督算法基础上改进的方法;直接依赖于聚类假设的方法;基于多视图的方法;基于图的方法。
1.3.7 增强学习
- 增强学习要解决的问题:一个能够感知环境的自治机器人,怎样通过学习选择能达到其目标的最优动作。
- 机器人选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈回来。
- 机器人根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。
1.3.8 AI知识图谱

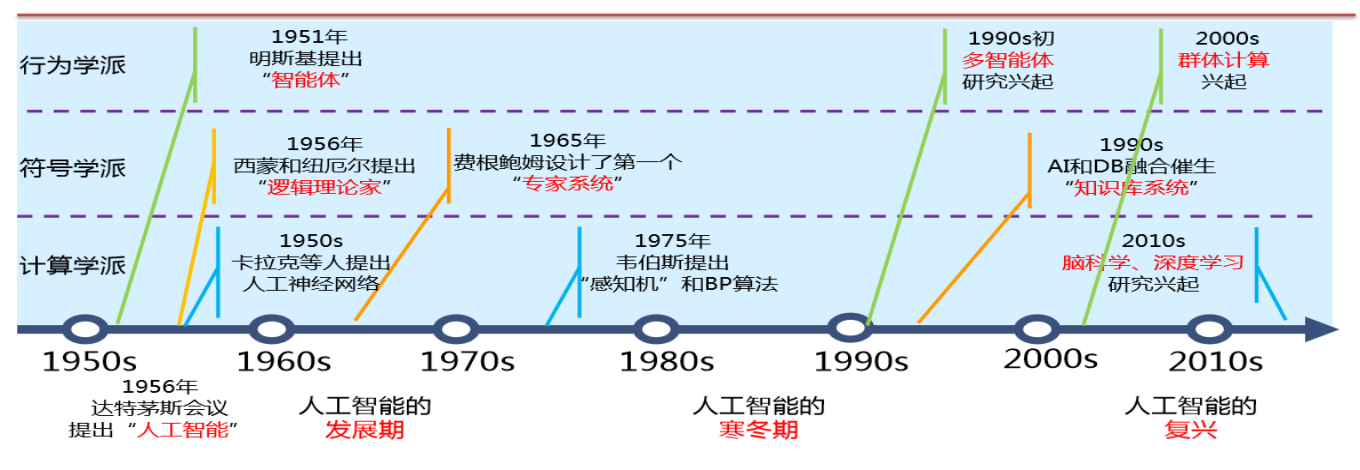
1.4 人工智能的发展历程
1.4.1 人工智能的起源

1.4.2 人工智能的发展


1.4.3 人工智能的复兴

1.4.4 人工智能的今天

1.5 人工智能的路线图
Talk is cheap. Show me the code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号