[数据结构]查找相关算法

目录
1.6 查找
1.6.1 顺序表的查找
#include<limits.h> /* INT_MAX等 */
#include<stdio.h> /* EOF(=^Z或F6),NULL */
#include <cstdlib>
#define OK 1
#define ERROR 0
#define N 5 /* 数据元素个数 */
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
typedef int Boolean; /* Boolean是布尔类型,其值是TRUE或FALSE */
typedef int KeyType; /* 设关键字域为整型 */
typedef struct /* 数据元素类型(以教科书图9.1高考成绩为例) */
{
long number; /* 准考证号 */
char name[10]; /* 姓名(4个汉字加1个串结束标志) */
int politics; /* 政治 */
int Chinese; /* 语文 */
int English; /* 英语 */
int math; /* 数学 */
int physics; /* 物理 */
int chemistry; /* 化学 */
int biology; /* 生物 */
KeyType key; /* 关键字类型应为KeyType,域名应为key,与bo9-1.c中一致 */
} ElemType;
ElemType r[N] = {{179324, "何芳芳", 85, 89, 98, 100, 93, 80, 47},
{179325, "陈红", 85, 86, 88, 100, 92, 90, 45},
{179326, "陆华", 78, 75, 90, 80, 95, 88, 37},
{179327, "张平", 82, 80, 78, 98, 84, 96, 40},
{179328, "赵小怡", 76, 85, 94, 57, 77, 69, 44}}; /* 全局变量 */
#define total key /* 定义总分(total)为关键字 */
#define EQ(a, b) ((a)==(b))
#define LT(a, b) ((a)<(b))
#define LQ(a, b) ((a)<=(b))
typedef struct {
ElemType *elem; /* 数据元素存储空间基址,建表时按实际长度分配,0号单元留空 */
int length; /* 表长度 */
} SSTable;
Status Creat_Seq(SSTable *ST, int n) { /* 操作结果: 构造一个含n个数据元素的静态顺序查找表ST(数据来自全局数组r) */
int i;
(*ST).elem = (ElemType *) calloc(n + 1, sizeof(ElemType)); /* 动态生成n个数据元素空间(0号单元不用) */
if (!(*ST).elem)
return ERROR;
for (i = 1; i <= n; i++)
*((*ST).elem + i) = r[i - 1]; /* 将全局数组r的值依次赋给ST */
(*ST).length = n;
return OK;
}
void Ascend(SSTable *ST) { /* 重建静态查找表为按关键字非降序排序 */
int i, j, k;
for (i = 1; i < (*ST).length; i++) {
k = i;
(*ST).elem[0] = (*ST).elem[i]; /* 待比较值存[0]单元 */
for (j = i + 1; j <= (*ST).length; j++)
if LT((*ST).elem[j].key, (*ST).elem[0].key) {
k = j;
(*ST).elem[0] = (*ST).elem[j];
}
if (k != i) /* 有更小的值则交换 */
{
(*ST).elem[k] = (*ST).elem[i];
(*ST).elem[i] = (*ST).elem[0];
}
}
}
Status Creat_Ord(SSTable *ST, int n) { /* 操作结果: 构造一个含n个数据元素的静态按关键字非降序查找表ST */
/* 数据来自全局数组r */
Status f;
f = Creat_Seq(ST, n);
if (f)
Ascend(ST);
return f;
}
Status Destroy(SSTable *ST) { /* 初始条件: 静态查找表ST存在。操作结果: 销毁表ST */
free((*ST).elem);
(*ST).elem = NULL;
(*ST).length = 0;
return OK;
}
int Search_Seq(SSTable ST, KeyType key) { /* 在顺序表ST中顺序查找其关键字等于key的数据元素。若找到,则函数值为 */
/* 该元素在表中的位置,否则为0。*/
int i;
ST.elem[0].key = key; /* 哨兵 */
for (i = ST.length; !EQ(ST.elem[i].key, key); --i); /* 从后往前找 */
return i; /* 找不到时,i为0 */
}
int Search_Bin(SSTable ST, KeyType key) { /* 在有序表ST中折半查找其关键字等于key的数据元素。若找到,则函数值为 */
/* 该元素在表中的位置,否则为0。*/
int low, high, mid;
low = 1; /* 置区间初值 */
high = ST.length;
while (low <= high) {
mid = (low + high) / 2;
if EQ(key, ST.elem[mid].key) /* 找到待查元素 */
return mid;
else if LT(key, ST.elem[mid].key)
high = mid - 1; /* 继续在前半区间进行查找 */
else
low = mid + 1; /* 继续在后半区间进行查找 */
}
return 0; /* 顺序表中不存在待查元素 */
}
Status Traverse(SSTable ST, void(*Visit)(ElemType)) { /* 初始条件: 静态查找表ST存在,Visit()是对元素操作的应用函数 */
/* 操作结果: 按顺序对ST的每个元素调用函数Visit()一次且仅一次。 */
/* 一旦Visit()失败,则操作失败 */
ElemType *p;
int i;
p = ++ST.elem; /* p指向第一个元素 */
for (i = 1; i <= ST.length; i++)
Visit(*p++);
return OK;
}
void print(ElemType c) /* Traverse()调用的函数 */
{
printf("%-8ld%-8s%4d%5d%5d%5d%5d%5d%5d%5d\n", c.number, c.name, c.politics, c.Chinese, c.English, c.math, c.physics,
c.chemistry, c.biology, c.total);
}
int main() {
SSTable st;
int i, s;
for (i = 0; i < N; i++) /* 计算总分 */
r[i].total =
r[i].politics + r[i].Chinese + r[i].English + r[i].math + r[i].physics + r[i].chemistry + r[i].biology;
Creat_Seq(&st, N); /* 由全局数组产生静态查找表st */
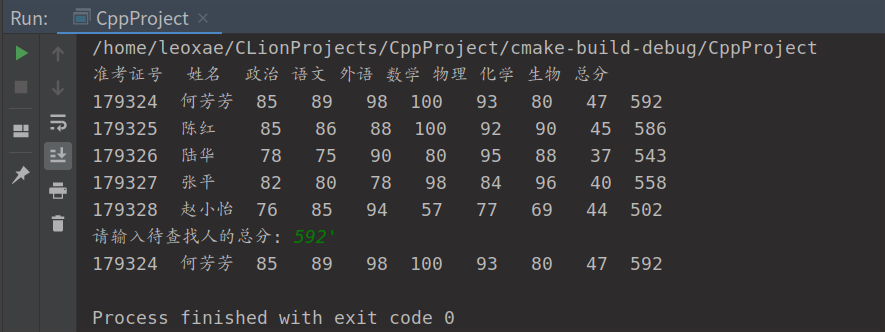
printf("准考证号 姓名 政治 语文 外语 数学 物理 化学 生物 总分\n");
Traverse(st, print); /* 按顺序输出静态查找表st */
printf("请输入待查找人的总分: ");
scanf("%d", &s);
i = Search_Seq(st, s); /* 顺序查找 */
if (i)
print(*(st.elem + i));
else
printf("没找到\n");
Destroy(&st);
return 0;
}
运行结果
1.6.2 静态树表的查找
#include<stdio.h> /* EOF(=^Z或F6),NULL */
#include <cstdlib>
#include <math.h>
#define FALSE 0
#define OK 1
#define ERROR 0
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
#define N 9 /* 数据元素个数 */
typedef char KeyType; /* 设关键字域为字符型 */
typedef struct /* 数据元素类型 */
{
KeyType key;
int weight;
} ElemType;
ElemType r[N] = {{'A', 1},
{'B', 1},
{'C', 2},
{'D', 5},
{'E', 3},
{'F', 4},
{'G', 4},
{'H', 3},
{'I', 5}}; /* 数据元素(以教科书例9-1为例),全局变量 */
int sw[N + 1]; /* 累计权值,全局变量 */
#define EQ(a, b) ((a)==(b))
#define LT(a, b) ((a)<(b))
typedef struct {
ElemType *elem; /* 数据元素存储空间基址,建表时按实际长度分配,0号单元留空 */
int length; /* 表长度 */
} SSTable;
Status Creat_Seq(SSTable *ST, int n) { /* 操作结果: 构造一个含n个数据元素的静态顺序查找表ST(数据来自全局数组r) */
int i;
(*ST).elem = (ElemType *) calloc(n + 1, sizeof(ElemType)); /* 动态生成n个数据元素空间(0号单元不用) */
if (!(*ST).elem)
return ERROR;
for (i = 1; i <= n; i++)
*((*ST).elem + i) = r[i - 1]; /* 将全局数组r的值依次赋给ST */
(*ST).length = n;
return OK;
}
void Ascend(SSTable *ST) { /* 重建静态查找表为按关键字非降序排序 */
int i, j, k;
for (i = 1; i < (*ST).length; i++) {
k = i;
(*ST).elem[0] = (*ST).elem[i]; /* 待比较值存[0]单元 */
for (j = i + 1; j <= (*ST).length; j++)
if LT((*ST).elem[j].key, (*ST).elem[0].key) {
k = j;
(*ST).elem[0] = (*ST).elem[j];
}
if (k != i) /* 有更小的值则交换 */
{
(*ST).elem[k] = (*ST).elem[i];
(*ST).elem[i] = (*ST).elem[0];
}
}
}
Status Creat_Ord(SSTable *ST, int n) { /* 操作结果: 构造一个含n个数据元素的静态按关键字非降序查找表ST */
/* 数据来自全局数组r */
Status f;
f = Creat_Seq(ST, n);
if (f)
Ascend(ST);
return f;
}
Status Traverse(SSTable ST, void(*Visit)(ElemType)) { /* 初始条件: 静态查找表ST存在,Visit()是对元素操作的应用函数 */
/* 操作结果: 按顺序对ST的每个元素调用函数Visit()一次且仅一次。 */
/* 一旦Visit()失败,则操作失败 */
ElemType *p;
int i;
p = ++ST.elem; /* p指向第一个元素 */
for (i = 1; i <= ST.length; i++)
Visit(*p++);
return OK;
}
typedef ElemType TElemType;
typedef struct BiTNode {
TElemType data;
struct BiTNode *lchild, *rchild; /* 左右孩子指针 */
} BiTNode, *BiTree;
Status
SecondOptimal(BiTree *T, ElemType R[], int sw[], int low, int high) { /* 由有序表R[low..high]及其累计权值表sw(其中sw[0]==0)递归构造 */
/* 次优查找树T。*/
int i, j;
double min, dw;
i = low;
min = fabs(sw[high] - sw[low]);
dw = sw[high] + sw[low - 1];
for (j = low + 1; j <= high; ++j) /* 选择最小的△Pi值 */
if (fabs(dw - sw[j] - sw[j - 1]) < min) {
i = j;
min = fabs(dw - sw[j] - sw[j - 1]);
}
*T = (BiTree) malloc(sizeof(BiTNode));
if (!*T)
return ERROR;
(*T)->data = R[i]; /* 生成结点 */
if (i == low)
(*T)->lchild = NULL; /* 左子树空 */
else
SecondOptimal(&(*T)->lchild, R, sw, low, i - 1); /* 构造左子树 */
if (i == high)
(*T)->rchild = NULL; /* 右子树空 */
else
SecondOptimal(&(*T)->rchild, R, sw, i + 1, high); /* 构造右子树 */
return OK;
}
void FindSW(int sw[], SSTable ST) { /* 按照有序表ST中各数据元素的Weight域求累计权值表sw */
int i;
sw[0] = 0;
for (i = 1; i <= ST.length; i++)
sw[i] = sw[i - 1] + ST.elem[i].weight;
}
typedef BiTree SOSTree; /* 次优查找树采用二叉链表的存储结构 */
Status CreateSOSTree(SOSTree *T, SSTable ST) { /* 由有序表ST构造一棵次优查找树T。ST的数据元素含有权域weight。*/
if (ST.length == 0)
*T = NULL;
else {
FindSW(sw, ST); /* 按照有序表ST中各数据元素的Weight域求累计权值表sw */
SecondOptimal(T, ST.elem, sw, 1, ST.length);
}
return OK;
}
Status Search_SOSTree(SOSTree *T, KeyType key) { /* 在次优查找树T中查找关键字等于key的元素。找到则返回OK,否则返回FALSE */
while (*T) /* T非空 */
if ((*T)->data.key == key)
return OK;
else if ((*T)->data.key > key)
*T = (*T)->lchild;
else
*T = (*T)->rchild;
return FALSE; /* 顺序表中不存在待查元素 */
}
void print(ElemType c) /* Traverse()调用的函数 */
{
printf("(%c %d) ", c.key, c.weight);
}
int main() {
SSTable st;
SOSTree t;
Status i;
KeyType s;
Creat_Ord(&st, N); /* 由全局数组产生非降序静态查找表st */
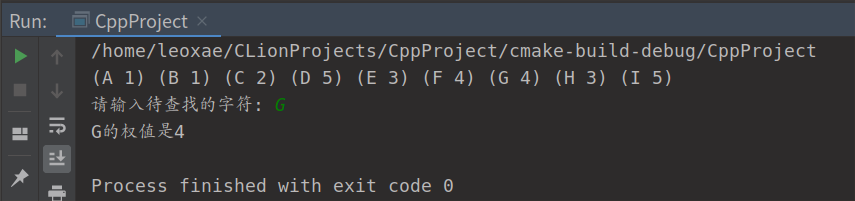
Traverse(st, print);
CreateSOSTree(&t, st); /* 由有序表构造一棵次优查找树 */
printf("\n请输入待查找的字符: ");
scanf("%c", &s);
i = Search_SOSTree(&t, s);
if (i)
printf("%c的权值是%d\n", s, t->data.weight);
else
printf("表中不存在此字符\n");
return 0;
}
运行结果
1.6.3 二叉排序树的基本操作
#include<stdio.h> /* EOF(=^Z或F6),NULL */
#include <cstdlib>
#define TRUE 1
#define FALSE 0
#define OK 1
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
typedef int Boolean; /* Boolean是布尔类型,其值是TRUE或FALSE */
#define N 10 /* 数据元素个数 */
typedef int KeyType; /* 设关键字域为整型 */
typedef struct {
KeyType key;
int others;
} ElemType; /* 数据元素类型 */
typedef ElemType TElemType;
typedef struct BiTNode {
TElemType data;
struct BiTNode *lchild, *rchild; /* 左右孩子指针 */
} BiTNode, *BiTree;
#define EQ(a, b) ((a)==(b))
#define LT(a, b) ((a)<(b))
Status InitDSTable(BiTree *DT) /* 同bo6-2.c */
{ /* 操作结果: 构造一个空的动态查找表DT */
*DT = NULL;
return OK;
}
void DestroyDSTable(BiTree *DT) /* 同bo6-2.c */
{ /* 初始条件: 动态查找表DT存在。操作结果: 销毁动态查找表DT */
if (*DT) /* 非空树 */
{
if ((*DT)->lchild) /* 有左孩子 */
DestroyDSTable(&(*DT)->lchild); /* 销毁左孩子子树 */
if ((*DT)->rchild) /* 有右孩子 */
DestroyDSTable(&(*DT)->rchild); /* 销毁右孩子子树 */
free(*DT); /* 释放根结点 */
*DT = NULL; /* 空指针赋0 */
}
}
BiTree SearchBST(BiTree T, KeyType key) { /* 在根指针T所指二叉排序树中递归地查找某关键字等于key的数据元素, */
/* 若查找成功,则返回指向该数据元素结点的指针,否则返回空指针。*/
if ((!T) || EQ(key, T->data.key))
return T; /* 查找结束 */
else if LT(key, T->data.key) /* 在左子树中继续查找 */
return SearchBST(T->lchild, key);
else
return SearchBST(T->rchild, key); /* 在右子树中继续查找 */
}
void SearchBST1(BiTree *T, KeyType key, BiTree f, BiTree *p, Status *flag) { /* 在根指针T所指二叉排序树中递归地查找其关键字等于key的数据元素,若查找 */
/* 成功,则指针p指向该数据元素结点,并返回TRUE,否则指针p指向查找路径上 */
/* 访问的最后一个结点并返回FALSE,指针f指向T的双亲,其初始调用值为NULL */
if (!*T) /* 查找不成功 */
{
*p = f;
*flag = FALSE;
} else if EQ(key, (*T)->data.key) /* 查找成功 */
{
*p = *T;
*flag = TRUE;
} else if LT(key, (*T)->data.key)
SearchBST1(&(*T)->lchild, key, *T, p, flag); /* 在左子树中继续查找 */
else
SearchBST1(&(*T)->rchild, key, *T, p, flag); /* 在右子树中继续查找 */
}
Status InsertBST(BiTree *T, ElemType e) { /* 当二叉排序树T中不存在关键字等于e.key的数据元素时,插入e并返回TRUE, */
/* 否则返回FALSE。*/
BiTree p, s;
Status flag;
SearchBST1(T, e.key, NULL, &p, &flag);
if (!flag) /* 查找不成功 */
{
s = (BiTree) malloc(sizeof(BiTNode));
s->data = e;
s->lchild = s->rchild = NULL;
if (!p)
*T = s; /* 被插结点*s为新的根结点 */
else if LT(e.key, p->data.key)
p->lchild = s; /* 被插结点*s为左孩子 */
else
p->rchild = s; /* 被插结点*s为右孩子 */
return TRUE;
} else
return FALSE; /* 树中已有关键字相同的结点,不再插入 */
}
void Delete(BiTree *p) { /* 从二叉排序树中删除结点p,并重接它的左或右子树。*/
BiTree q, s;
if (!(*p)->rchild) /* 右子树空则只需重接它的左子树(待删结点是叶子也走此分支) */
{
q = *p;
*p = (*p)->lchild;
free(q);
} else if (!(*p)->lchild) /* 只需重接它的右子树 */
{
q = *p;
*p = (*p)->rchild;
free(q);
} else /* 左右子树均不空 */
{
q = *p;
s = (*p)->lchild;
while (s->rchild) /* 转左,然后向右到尽头(找待删结点的前驱) */
{
q = s;
s = s->rchild;
}
(*p)->data = s->data; /* s指向被删结点的"前驱"(将被删结点前驱的值取代被删结点的值) */
if (q != *p)
q->rchild = s->lchild; /* 重接*q的右子树 */
else
q->lchild = s->lchild; /* 重接*q的左子树 */
free(s);
}
}
Status DeleteBST(BiTree *T, KeyType key) { /* 若二叉排序树T中存在关键字等于key的数据元素时,则删除该数据元素结点, */
/* 并返回TRUE;否则返回FALSE。*/
if (!*T) /* 不存在关键字等于key的数据元素 */
return FALSE;
else {
if EQ(key, (*T)->data.key) /* 找到关键字等于key的数据元素 */
Delete(T);
else if LT(key, (*T)->data.key)
DeleteBST(&(*T)->lchild, key);
else
DeleteBST(&(*T)->rchild, key);
return TRUE;
}
}
void TraverseDSTable(BiTree DT, void(*Visit)(ElemType)) { /* 初始条件: 动态查找表DT存在,Visit是对结点操作的应用函数 */
/* 操作结果: 按关键字的顺序对DT的每个结点调用函数Visit()一次且至多一次 */
if (DT) {
TraverseDSTable(DT->lchild, Visit); /* 先中序遍历左子树 */
Visit(DT->data); /* 再访问根结点 */
TraverseDSTable(DT->rchild, Visit); /* 最后中序遍历右子树 */
}
}
void print(ElemType c) {
printf("(%d,%d) ", c.key, c.others);
}
int main() {
BiTree dt, p;
int i;
KeyType j;
ElemType r[N] = {{45, 1},
{12, 2},
{53, 3},
{3, 4},
{37, 5},
{24, 6},
{100, 7},
{61, 8},
{90, 9},
{78, 10}};
InitDSTable(&dt); /* 构造空表 */
for (i = 0; i < N; i++)
InsertBST(&dt, r[i]); /* 依次插入数据元素 */
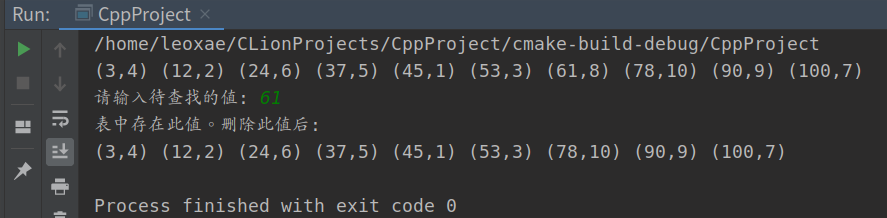
TraverseDSTable(dt, print);
printf("\n请输入待查找的值: ");
scanf("%d", &j);
p = SearchBST(dt, j);
if (p) {
printf("表中存在此值。");
DeleteBST(&dt, j);
printf("删除此值后:\n");
TraverseDSTable(dt, print);
printf("\n");
} else
printf("表中不存在此值\n");
DestroyDSTable(&dt);
return 0;
}
运行结果
1.6.4 平衡二叉树的基本操作
#include<stdio.h> /* EOF(=^Z或F6),NULL */
#include <cstdlib>
#define TRUE 1
#define FALSE 0
#define OK 1
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
#define N 5 /* 数据元素个数 */
typedef char KeyType; /* 设关键字域为字符型 */
typedef struct {
KeyType key;
int order;
} ElemType; /* 数据元素类型 */
#define EQ(a, b) ((a)==(b))
#define LT(a, b) ((a)<(b))
typedef struct BSTNode {
ElemType data;
int bf; /* 结点的平衡因子 */
struct BSTNode *lchild, *rchild; /* 左、右孩子指针 */
} BSTNode, *BSTree;
Status InitDSTable(BSTree *DT) /* 同bo6-2.c */
{ /* 操作结果: 构造一个空的动态查找表DT */
*DT = NULL;
return OK;
}
void DestroyDSTable(BSTree *DT) /* 同bo6-2.c */
{ /* 初始条件: 动态查找表DT存在。操作结果: 销毁动态查找表DT */
if (*DT) /* 非空树 */
{
if ((*DT)->lchild) /* 有左孩子 */
DestroyDSTable(&(*DT)->lchild); /* 销毁左孩子子树 */
if ((*DT)->rchild) /* 有右孩子 */
DestroyDSTable(&(*DT)->rchild); /* 销毁右孩子子树 */
free(*DT); /* 释放根结点 */
*DT = NULL; /* 空指针赋0 */
}
}
BSTree SearchBST(BSTree T, KeyType key) { /* 在根指针T所指二叉排序树中递归地查找某关键字等于key的数据元素, */
/* 若查找成功,则返回指向该数据元素结点的指针,否则返回空指针。*/
if ((!T) || EQ(key, T->data.key))
return T; /* 查找结束 */
else if LT(key, T->data.key) /* 在左子树中继续查找 */
return SearchBST(T->lchild, key);
else
return SearchBST(T->rchild, key); /* 在右子树中继续查找 */
}
void R_Rotate(BSTree *p) { /* 对以*p为根的二叉排序树作右旋处理,处理之后p指向新的树根结点,即旋转 */
/* 处理之前的左子树的根结点。*/
BSTree lc;
lc = (*p)->lchild; /* lc指向p的左子树根结点 */
(*p)->lchild = lc->rchild; /* lc的右子树挂接为p的左子树 */
lc->rchild = *p;
*p = lc; /* p指向新的根结点 */
}
void L_Rotate(BSTree *p) { /* 对以*p为根的二叉排序树作左旋处理,处理之后p指向新的树根结点,即旋转 */
/* 处理之前的右子树的根结点。*/
BSTree rc;
rc = (*p)->rchild; /* rc指向p的右子树根结点 */
(*p)->rchild = rc->lchild; /* rc的左子树挂接为p的右子树 */
rc->lchild = *p;
*p = rc; /* p指向新的根结点 */
}
#define LH +1 /* 左高 */
#define EH 0 /* 等高 */
#define RH -1 /* 右高 */
void LeftBalance(BSTree *T) { /* 对以指针T所指结点为根的二叉树作左平衡旋转处理,本算法结束时, */
/* 指针T指向新的根结点。*/
BSTree lc, rd;
lc = (*T)->lchild; /* lc指向*T的左子树根结点 */
switch (lc->bf) { /* 检查*T的左子树的平衡度,并作相应平衡处理 */
case LH: /* 新结点插入在*T的左孩子的左子树上,要作单右旋处理 */
(*T)->bf = lc->bf = EH;
R_Rotate(T);
break;
case RH: /* 新结点插入在*T的左孩子的右子树上,要作双旋处理 */
rd = lc->rchild; /* rd指向*T的左孩子的右子树根 */
switch (rd->bf) { /* 修改*T及其左孩子的平衡因子 */
case LH:
(*T)->bf = RH;
lc->bf = EH;
break;
case EH:
(*T)->bf = lc->bf = EH;
break;
case RH:
(*T)->bf = EH;
lc->bf = LH;
}
rd->bf = EH;
L_Rotate(&(*T)->lchild); /* 对*T的左子树作左旋平衡处理 */
R_Rotate(T); /* 对*T作右旋平衡处理 */
}
}
void RightBalance(BSTree *T) { /* 对以指针T所指结点为根的二叉树作右平衡旋转处理,本算法结束时, */
/* 指针T指向新的根结点 */
BSTree rc, rd;
rc = (*T)->rchild; /* rc指向*T的右子树根结点 */
switch (rc->bf) { /* 检查*T的右子树的平衡度,并作相应平衡处理 */
case RH: /* 新结点插入在*T的右孩子的右子树上,要作单左旋处理 */
(*T)->bf = rc->bf = EH;
L_Rotate(T);
break;
case LH: /* 新结点插入在*T的右孩子的左子树上,要作双旋处理 */
rd = rc->lchild; /* rd指向*T的右孩子的左子树根 */
switch (rd->bf) { /* 修改*T及其右孩子的平衡因子 */
case RH:
(*T)->bf = LH;
rc->bf = EH;
break;
case EH:
(*T)->bf = rc->bf = EH;
break;
case LH:
(*T)->bf = EH;
rc->bf = RH;
}
rd->bf = EH;
R_Rotate(&(*T)->rchild); /* 对*T的右子树作右旋平衡处理 */
L_Rotate(T); /* 对*T作左旋平衡处理 */
}
}
Status InsertAVL(BSTree *T, ElemType e, Status *taller) { /* 若在平衡的二叉排序树T中不存在和e有相同关键字的结点,则插入一个 */
/* 数据元素为e的新结点,并返回1,否则返回0。若因插入而使二叉排序树 */
/* 失去平衡,则作平衡旋转处理,布尔变量taller反映T长高与否。*/
if (!*T) { /* 插入新结点,树"长高",置taller为TRUE */
*T = (BSTree) malloc(sizeof(BSTNode));
(*T)->data = e;
(*T)->lchild = (*T)->rchild = NULL;
(*T)->bf = EH;
*taller = TRUE;
} else {
if EQ(e.key, (*T)->data.key) { /* 树中已存在和e有相同关键字的结点则不再插入 */
*taller = FALSE;
return FALSE;
}
if LT(e.key, (*T)->data.key) { /* 应继续在*T的左子树中进行搜索 */
if (!InsertAVL(&(*T)->lchild, e, taller)) /* 未插入 */
return FALSE;
if (*taller) /* 已插入到*T的左子树中且左子树"长高" */
switch ((*T)->bf) /* 检查*T的平衡度 */
{
case LH: /* 原本左子树比右子树高,需要作左平衡处理 */
LeftBalance(T);
*taller = FALSE;
break;
case EH: /* 原本左、右子树等高,现因左子树增高而使树增高 */
(*T)->bf = LH;
*taller = TRUE;
break;
case RH:
(*T)->bf = EH; /* 原本右子树比左子树高,现左、右子树等高 */
*taller = FALSE;
}
} else { /* 应继续在*T的右子树中进行搜索 */
if (!InsertAVL(&(*T)->rchild, e, taller)) /* 未插入 */
return FALSE;
if (*taller) /* 已插入到T的右子树且右子树"长高" */
switch ((*T)->bf) /* 检查T的平衡度 */
{
case LH:
(*T)->bf = EH; /* 原本左子树比右子树高,现左、右子树等高 */
*taller = FALSE;
break;
case EH: /* 原本左、右子树等高,现因右子树增高而使树增高 */
(*T)->bf = RH;
*taller = TRUE;
break;
case RH: /* 原本右子树比左子树高,需要作右平衡处理 */
RightBalance(T);
*taller = FALSE;
}
}
}
return TRUE;
}
void TraverseDSTable(BSTree DT, void(*Visit)(ElemType)) { /* 初始条件: 动态查找表DT存在,Visit是对结点操作的应用函数 */
/* 操作结果: 按关键字的顺序对DT的每个结点调用函数Visit()一次且至多一次 */
if (DT) {
TraverseDSTable(DT->lchild, Visit); /* 先中序遍历左子树 */
Visit(DT->data); /* 再访问根结点 */
TraverseDSTable(DT->rchild, Visit); /* 最后中序遍历右子树 */
}
}
void print(ElemType c) {
printf("(%d,%d)", c.key, c.order);
}
int main() {
BSTree dt, p;
Status k;
int i;
KeyType j;
ElemType r[N] = {{13, 1},
{24, 2},
{37, 3},
{90, 4},
{53, 5}}; /* (以教科书图9.12为例) */
InitDSTable(&dt); /* 初始化空树 */
for (i = 0; i < N; i++)
InsertAVL(&dt, r[i], &k); /* 建平衡二叉树 */
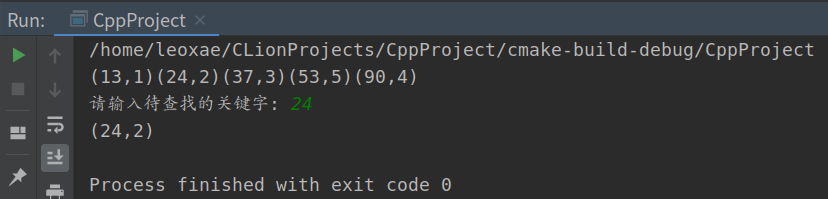
TraverseDSTable(dt, print); /* 按关键字顺序遍历二叉树 */
printf("\n请输入待查找的关键字: ");
scanf("%d", &j);
p = SearchBST(dt, j); /* 查找给定关键字的记录 */
if (p)
print(p->data);
else
printf("表中不存在此值");
printf("\n");
DestroyDSTable(&dt);
return 0;
}
运行结果
1.6.5 B树的基本操作
#include<stdio.h> /* EOF(=^Z或F6),NULL */
#include <cstdlib>
/* 函数结果状态代码 */
#define TRUE 1
#define FALSE 0
#define OK 1
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
#define m 3 /* B树的阶,暂设为3 */
#define N 16 /* 数据元素个数 */
#define MAX 5 /* 字符串最大长度+1 */
typedef int KeyType; /* 设关键字域为整型 */
typedef struct {
char info[MAX];
} Others;/* 记录的其它部分 */
typedef struct {
KeyType key; /* 关键字 */
Others others; /* 其它部分(由主程定义) */
} Record; /* 记录类型 */
typedef struct BTNode {
int keynum; /* 结点中关键字个数,即结点的大小 */
struct BTNode *parent; /* 指向双亲结点 */
struct Node /* 结点向量类型 */
{
KeyType key; /* 关键字向量 */
struct BTNode *ptr; /* 子树指针向量 */
Record *recptr; /* 记录指针向量 */
} node[m + 1]; /* key,recptr的0号单元未用 */
} BTNode, *BTree; /* B树结点和B树的类型 */
typedef struct {
BTNode *pt; /* 指向找到的结点 */
int i; /* 1..m,在结点中的关键字序号 */
int tag; /* 1:查找成功,O:查找失败 */
} Result; /* B树的查找结果类型 */
Status InitDSTable(BTree *DT) { /* 操作结果: 构造一个空的动态查找表DT */
*DT = NULL;
return OK;
}
void DestroyDSTable(BTree *DT) { /* 初始条件: 动态查找表DT存在。操作结果: 销毁动态查找表DT */
int i;
if (*DT) /* 非空树 */
{
for (i = 0; i <= (*DT)->keynum; i++)
DestroyDSTable(&(*DT)->node[i].ptr); /* 依次销毁第i棵子树 */
free(*DT); /* 释放根结点 */
*DT = NULL; /* 空指针赋0 */
}
}
int Search(BTree p, KeyType K) { /* 在p->node[1..keynum].key中查找i,使得p->node[i].key≤K<p->node[i+1].key */
int i = 0, j;
for (j = 1; j <= p->keynum; j++)
if (p->node[j].key <= K)
i = j;
return i;
}
Result SearchBTree(BTree T, KeyType K) { /* 在m阶B树T上查找关键字K,返回结果(pt,i,tag)。若查找成功,则特征值 */
/* tag=1,指针pt所指结点中第i个关键字等于K;否则特征值tag=0,等于K的 */
/* 关键字应插入在指针Pt所指结点中第i和第i+1个关键字之间。*/
BTree p = T, q = NULL; /* 初始化,p指向待查结点,q指向p的双亲 */
Status found = FALSE;
int i = 0;
Result r;
while (p && !found) {
i = Search(p, K); /* p->node[i].key≤K<p->node[i+1].key */
if (i > 0 && p->node[i].key == K) /* 找到待查关键字 */
found = TRUE;
else {
q = p;
p = p->node[i].ptr;
}
}
r.i = i;
if (found) /* 查找成功 */
{
r.pt = p;
r.tag = 1;
} else /* 查找不成功,返回K的插入位置信息 */
{
r.pt = q;
r.tag = 0;
}
return r;
}
void Insert(BTree *q, int i, Record *r, BTree ap) { /* 将r->key、r和ap分别插入到q->key[i+1]、q->recptr[i+1]和q->ptr[i+1]中 */
int j;
for (j = (*q)->keynum; j > i; j--) /* 空出q->node[i+1] */
(*q)->node[j + 1] = (*q)->node[j];
(*q)->node[i + 1].key = r->key;
(*q)->node[i + 1].ptr = ap;
(*q)->node[i + 1].recptr = r;
(*q)->keynum++;
}
void split(BTree *q, BTree *ap) { /* 将结点q分裂成两个结点,前一半保留,后一半移入新生结点ap */
int i, s = (m + 1) / 2;
*ap = (BTree) malloc(sizeof(BTNode)); /* 生成新结点ap */
(*ap)->node[0].ptr = (*q)->node[s].ptr; /* 后一半移入ap */
for (i = s + 1; i <= m; i++) {
(*ap)->node[i - s] = (*q)->node[i];
if ((*ap)->node[i - s].ptr)
(*ap)->node[i - s].ptr->parent = *ap;
}
(*ap)->keynum = m - s;
(*ap)->parent = (*q)->parent;
(*q)->keynum = s - 1; /* q的前一半保留,修改keynum */
}
void NewRoot(BTree *T, Record *r, BTree ap) { /* 生成含信息(T,r,ap)的新的根结点*T,原T和ap为子树指针 */
BTree p;
p = (BTree) malloc(sizeof(BTNode));
p->node[0].ptr = *T;
*T = p;
if ((*T)->node[0].ptr)
(*T)->node[0].ptr->parent = *T;
(*T)->parent = NULL;
(*T)->keynum = 1;
(*T)->node[1].key = r->key;
(*T)->node[1].recptr = r;
(*T)->node[1].ptr = ap;
if ((*T)->node[1].ptr)
(*T)->node[1].ptr->parent = *T;
}
void InsertBTree(BTree *T, Record *r, BTree q, int i) { /* 在m阶B树T上结点*q的key[i]与key[i+1]之间插入关键字K的指针r。若引起 */
/* 结点过大,则沿双亲链进行必要的结点分裂调整,使T仍是m阶B树。*/
BTree ap = NULL;
Status finished = FALSE;
int s;
Record *rx;
rx = r;
while (q && !finished) {
Insert(&q, i, rx, ap); /* 将r->key、r和ap分别插入到q->key[i+1]、q->recptr[i+1]和q->ptr[i+1]中 */
if (q->keynum < m)
finished = TRUE; /* 插入完成 */
else { /* 分裂结点*q */
s = (m + 1) / 2;
rx = q->node[s].recptr;
split(&q, &ap); /* 将q->key[s+1..m],q->ptr[s..m]和q->recptr[s+1..m]移入新结点*ap */
q = q->parent;
if (q)
i = Search(q, rx->key); /* 在双亲结点*q中查找rx->key的插入位置 */
}
}
if (!finished) /* T是空树(参数q初值为NULL)或根结点已分裂为结点*q和*ap */
NewRoot(T, rx, ap); /* 生成含信息(T,rx,ap)的新的根结点*T,原T和ap为子树指针 */
}
void TraverseDSTable(BTree DT, void(*Visit)(BTNode, int)) { /* 初始条件: 动态查找表DT存在,Visit是对结点操作的应用函数 */
/* 操作结果: 按关键字的顺序对DT的每个结点调用函数Visit()一次且至多一次 */
int i;
if (DT) /* 非空树 */
{
if (DT->node[0].ptr) /* 有第0棵子树 */
TraverseDSTable(DT->node[0].ptr, Visit);
for (i = 1; i <= DT->keynum; i++) {
Visit(*DT, i);
if (DT->node[i].ptr) /* 有第i棵子树 */
TraverseDSTable(DT->node[i].ptr, Visit);
}
}
}
void print(BTNode c, int i) /* TraverseDSTable()调用的函数 */
{
printf("(%d,%s)", c.node[i].key, c.node[i].recptr->others.info);
}
int main() {
Record r[N] = {{24, "1"},
{45, "2"},
{53, "3"},
{12, "4"},
{37, "5"},
{50, "6"},
{61, "7"},
{90, "8"},
{100, "9"},
{70, "10"},
{3, "11"},
{30, "12"},
{26, "13"},
{85, "14"},
{3, "15"},
{7, "16"}}; /* (以教科书中图9.16为例) */
BTree t;
Result s;
int i;
InitDSTable(&t);
for (i = 0; i < N; i++) {
s = SearchBTree(t, r[i].key);
if (!s.tag)
InsertBTree(&t, &r[i], s.pt, s.i);
}
printf("按关键字的顺序遍历B_树:\n");
TraverseDSTable(t, print);
printf("\n请输入待查找记录的关键字: ");
scanf("%d", &i);
s = SearchBTree(t, i);
if (s.tag)
print(*(s.pt), s.i);
else
printf("没找到");
printf("\n");
DestroyDSTable(&t);
return 0;
}

1.6.6 按关键字符串的遍历双链键树
#include<stdio.h> /* EOF(=^Z或F6),NULL */
#include<math.h> /* floor(),ceil(),abs() */
#include <cstring>
/* 函数结果状态代码 */
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
#define N 16 /* 数据元素个数 */
#define OVERFLOW 3
typedef struct {
int ord;
} Others; /* 记录的其它部分 */
#define Nil ' ' /* 定义结束符为空格(与教科书不同) */
#define MAXKEYLEN 16 /* 关键字的最大长度 */
typedef struct {
char ch[MAXKEYLEN]; /* 关键字 */
int num; /* 关键字长度 */
} KeysType; /* 关键字类型 */
typedef struct {
KeysType key; /* 关键字 */
Others others; /* 其它部分(由主程定义) */
} Record; /* 记录类型 */
typedef enum {
LEAF, BRANCH
} NodeKind; /* 结点种类:{叶子,分支} */
typedef struct DLTNode /* 双链树类型 */
{
char symbol;
struct DLTNode *next; /* 指向兄弟结点的指针 */
NodeKind kind;
union {
Record *infoptr; /* 叶子结点的记录指针 */
struct DLTNode *first; /* 分支结点的孩子链指针 */
} a;
} DLTNode, *DLTree;
Status InitDSTable(DLTree *DT) { /* 操作结果: 构造一个空的双链键树DT */
*DT = NULL;
return OK;
}
void DestroyDSTable(DLTree *DT) { /* 初始条件: 双链键树DT存在。操作结果: 销毁双链键树DT */
if (*DT) /* 非空树 */
{
if ((*DT)->kind == BRANCH && (*DT)->a.first) /* *DT是分支结点且有孩子 */
DestroyDSTable(&(*DT)->a.first); /* 销毁孩子子树 */
if ((*DT)->next) /* 有兄弟 */
DestroyDSTable(&(*DT)->next); /* 销毁兄弟子树 */
free(*DT); /* 释放根结点 */
*DT = NULL; /* 空指针赋0 */
}
}
Record *SearchDLTree(DLTree T, KeysType K) { /* 在非空双链键树T中查找关键字等于K的记录,若存在, */
/* 则返回指向该记录的指针,否则返回空指针。*/
DLTree p;
int i;
if (T) {
p = T; /* 初始化 */
i = 0;
while (p && i < K.num) {
while (p && p->symbol != K.ch[i]) /* 查找关键字的第i位 */
p = p->next;
if (p && i < K.num) /* 准备查找下一位 */
p = p->a.first;
++i;
} /* 查找结束 */
if (!p) /* 查找不成功 */
return NULL;
else /* 查找成功 */
return p->a.infoptr;
} else
return NULL; /* 树空 */
}
void InsertDSTable(DLTree *DT, Record *r) { /* 初始条件: 双链键树DT存在,r为待插入的数据元素的指针 */
/* 操作结果: 若DT中不存在其关键字等于(*r).key.ch的数据元素, */
/* 则按关键字顺序插r到DT中 */
DLTree p = NULL, q, ap;
int i = 0;
KeysType K = r->key;
if (!*DT && K.num) /* 空树且关键字符串非空 */
{
*DT = ap = (DLTree) malloc(sizeof(DLTNode));
for (; i < K.num; i++) /* 插入分支结点 */
{
if (p)
p->a.first = ap;
ap->next = NULL;
ap->symbol = K.ch[i];
ap->kind = BRANCH;
p = ap;
ap = (DLTree) malloc(sizeof(DLTNode));
}
p->a.first = ap; /* 插入叶子结点 */
ap->next = NULL;
ap->symbol = Nil;
ap->kind = LEAF;
ap->a.infoptr = r;
} else /* 非空树 */
{
p = *DT; /* 指向根结点 */
while (p && i < K.num) {
while (p && p->symbol < K.ch[i]) /* 沿兄弟结点查找 */
{
q = p;
p = p->next;
}
if (p && p->symbol == K.ch[i]) /* 找到与K.ch[i]相符的结点 */
{
q = p;
p = p->a.first; /* p指向将与K.ch[i+1]比较的结点 */
++i;
} else /* 没找到,插入关键字 */
{
ap = (DLTree) malloc(sizeof(DLTNode));
if (q->a.first == p)
q->a.first = ap; /* 在长子的位置插入 */
else /* q->next==p */
q->next = ap; /* 在兄弟的位置插入 */
ap->next = p;
ap->symbol = K.ch[i];
ap->kind = BRANCH;
p = ap;
ap = (DLTree) malloc(sizeof(DLTNode));
i++;
for (; i < K.num; i++) /* 插入分支结点 */
{
p->a.first = ap;
ap->next = NULL;
ap->symbol = K.ch[i];
ap->kind = BRANCH;
p = ap;
ap = (DLTree) malloc(sizeof(DLTNode));
}
p->a.first = ap; /* 插入叶子结点 */
ap->next = NULL;
ap->symbol = Nil;
ap->kind = LEAF;
ap->a.infoptr = r;
}
}
}
}
typedef struct {
char ch;
DLTree p;
} SElemType; /* 定义栈元素类型 */
#define STACK_INIT_SIZE 10 /* 存储空间初始分配量 */
#define STACKINCREMENT 2 /* 存储空间分配增量 */
typedef struct SqStack {
SElemType *base; /* 在栈构造之前和销毁之后,base的值为NULL */
SElemType *top; /* 栈顶指针 */
int stacksize; /* 当前已分配的存储空间,以元素为单位 */
} SqStack; /* 顺序栈 */
Status InitStack(SqStack *S) { /* 构造一个空栈S */
(*S).base = (SElemType *) malloc(STACK_INIT_SIZE * sizeof(SElemType));
if (!(*S).base)
exit(OVERFLOW); /* 存储分配失败 */
(*S).top = (*S).base;
(*S).stacksize = STACK_INIT_SIZE;
return OK;
}
Status StackEmpty(SqStack S) { /* 若栈S为空栈,则返回TRUE,否则返回FALSE */
if (S.top == S.base)
return TRUE;
else
return FALSE;
}
Status Push(SqStack *S, SElemType e) { /* 插入元素e为新的栈顶元素 */
if ((*S).top - (*S).base >= (*S).stacksize) /* 栈满,追加存储空间 */
{
(*S).base = (SElemType *) realloc((*S).base, ((*S).stacksize + STACKINCREMENT) * sizeof(SElemType));
if (!(*S).base)
exit(OVERFLOW); /* 存储分配失败 */
(*S).top = (*S).base + (*S).stacksize;
(*S).stacksize += STACKINCREMENT;
}
*((*S).top)++ = e;
return OK;
}
Status Pop(SqStack *S, SElemType *e) { /* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */
if ((*S).top == (*S).base)
return ERROR;
*e = *--(*S).top;
return OK;
}
void TraverseDSTable(DLTree DT, void(*Vi)(Record)) { /* 初始条件: 双链键树DT存在,Vi是对结点操作的应用函数, */
/* ViR是对记录操作的应用函数 */
/* 操作结果: 按关键字的顺序输出关键字及其对应的记录 */
SqStack s;
SElemType e;
DLTree p;
int i = 0, n = 8;
if (DT) {
InitStack(&s);
e.p = DT;
e.ch = DT->symbol;
Push(&s, e);
p = DT->a.first;
while (p->kind == BRANCH) /* 分支结点 */
{
e.p = p;
e.ch = p->symbol;
Push(&s, e);
p = p->a.first;
}
e.p = p;
e.ch = p->symbol;
Push(&s, e);
Vi(*(p->a.infoptr));
i++;
while (!StackEmpty(s)) {
Pop(&s, &e);
p = e.p;
if (p->next) /* 有兄弟结点 */
{
p = p->next;
while (p->kind == BRANCH) /* 分支结点 */
{
e.p = p;
e.ch = p->symbol;
Push(&s, e);
p = p->a.first;
}
e.p = p;
e.ch = p->symbol;
Push(&s, e);
Vi(*(p->a.infoptr));
i++;
if (i % n == 0)
printf("\n"); /* 输出n个元素后换行 */
}
}
}
}
void print(Record e) {
int i;
printf("(");
for (i = 0; i < e.key.num; i++)
printf("%c", e.key.ch[i]);
printf(",%d)", e.others.ord);
}
int main() {
DLTree t;
int i;
char s[MAXKEYLEN + 1];
KeysType k;
Record *p;
Record r[N] = {{{"CAI"}, 1},
{{"CAO"}, 2},
{{"LI"}, 3},
{{"LAN"}, 4},
{{"CHA"}, 5},
{{"CHANG"}, 6},
{{"WEN"}, 7},
{{"CHAO"}, 8},
{{"YUN"}, 9},
{{"YANG"}, 10},
{{"LONG"}, 11},
{{"WANG"}, 12},
{{"ZHAO"}, 13},
{{"LIU"}, 14},
{{"WU"}, 15},
{{"CHEN"}, 16}};
/* 数据元素(以教科书式9-24为例) */
InitDSTable(&t);
for (i = 0; i < N; i++) {
r[i].key.num = strlen(r[i].key.ch);
p = SearchDLTree(t, r[i].key);
if (!p) /* t中不存在关键字为r[i].key的项 */
InsertDSTable(&t, &r[i]);
}
printf("按关键字符串的顺序遍历双链键树:\n");
TraverseDSTable(t, print);
printf("\n请输入待查找记录的关键字符串: ");
scanf("%s", s);
k.num = strlen(s);
strcpy(k.ch, s);
p = SearchDLTree(t, k);
if (p)
print(*p);
else
printf("没找到");
printf("\n");
DestroyDSTable(&t);
return 0;
}
运行结果
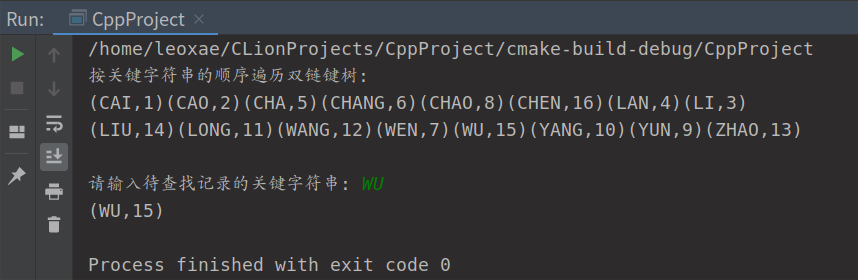
1.6.7 按关键字符串的遍历Trie树
#include<stdio.h> /* EOF(=^Z或F6),NULL */
#include <cstring>
#include <cctype>
#include <cstdlib>
#define OK 1
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
#define N 16 /* 数据元素个数 */
#define LENGTH 27 /* 结点的最大度+1(大写英文字母) */
typedef struct {
int ord;
} Others; /* 记录的其它部分 */
#define Nil ' ' /* 定义结束符为空格(与教科书不同) */
#define MAXKEYLEN 16 /* 关键字的最大长度,同c9-4.h */
typedef struct {
char ch[MAXKEYLEN]; /* 关键字 */
int num; /* 关键字长度 */
} KeysType;
typedef struct {
KeysType key; /* 关键字 */
Others others; /* 其它部分(由主程定义) */
} Record;
typedef enum {
LEAF, BRANCH
} NodeKind;
typedef struct TrieNode /* Trie键树类型 */
{
NodeKind kind;
union {
struct /* 叶子结点 */
{
KeysType K;
Record *infoptr;
} lf;
struct /* 分支结点 */
{
struct TrieNode *ptr[LENGTH]; /* LENGTH为结点的最大度+1,在主程定义 */
/* int num; 改 */
} bh;
} a;
} TrieNode, *TrieTree;
#define EQ(a, b) (!strcmp((a),(b)))
Status InitDSTable(TrieTree *T) { /* 操作结果: 构造一个空的Trie键树T */
*T = NULL;
return OK;
}
void DestroyDSTable(TrieTree *T) { /* 初始条件: Trie树T存在。操作结果: 销毁Trie树T */
int i;
if (*T) /* 非空树 */
{
for (i = 0; i < LENGTH; i++)
if ((*T)->kind == BRANCH && (*T)->a.bh.ptr[i]) /* 第i个结点不空 */
if ((*T)->a.bh.ptr[i]->kind == BRANCH) /* 是子树 */
DestroyDSTable(&(*T)->a.bh.ptr[i]);
else /* 是叶子 */
{
free((*T)->a.bh.ptr[i]);
(*T)->a.bh.ptr[i] = NULL;
}
free(*T); /* 释放根结点 */
*T = NULL; /* 空指针赋0 */
}
}
int ord(char c) {
c = toupper(c);
if (c >= 'A' && c <= 'Z')
return c - 'A' + 1; /* 英文字母返回其在字母表中的序号 */
else
return 0; /* 其余字符返回0 */
}
Record *SearchTrie(TrieTree T, KeysType K) { /* 在键树T中查找关键字等于K的记录。*/
TrieTree p;
int i;
for (p = T, i = 0; p && p->kind == BRANCH && i < K.num; p = p->a.bh.ptr[ord(K.ch[i])], ++i);
/* 对K的每个字符逐个查找,*p为分支结点,ord()求字符在字母表中序号 */
if (p && p->kind == LEAF && p->a.lf.K.num == K.num && EQ(p->a.lf.K.ch, K.ch)) /* 查找成功 */
return p->a.lf.infoptr;
else /* 查找不成功 */
return NULL;
}
void InsertTrie(TrieTree *T, Record *r) { /* 初始条件: Trie键树T存在,r为待插入的数据元素的指针 */
/* 操作结果: 若T中不存在其关键字等于(*r).key.ch的数据元素, */
/* 则按关键字顺序插r到T中 */
TrieTree p, q, ap;
int i = 0, j;
KeysType K1, K = r->key;
if (!*T) /* 空树 */
{
*T = (TrieTree) malloc(sizeof(TrieNode));
(*T)->kind = BRANCH;
for (i = 0; i < LENGTH; i++) /* 指针量赋初值NULL */
(*T)->a.bh.ptr[i] = NULL;
p = (*T)->a.bh.ptr[ord(K.ch[0])] = (TrieTree) malloc(sizeof(TrieNode));
p->kind = LEAF;
p->a.lf.K = K;
p->a.lf.infoptr = r;
} else /* 非空树 */
{
for (p = *T, i = 0; p && p->kind == BRANCH && i < K.num; ++i) {
q = p;
p = p->a.bh.ptr[ord(K.ch[i])];
}
i--;
if (p && p->kind == LEAF && p->a.lf.K.num == K.num && EQ(p->a.lf.K.ch, K.ch)) /* T中存在该关键字 */
return;
else /* T中不存在该关键字,插入之 */
{
if (!p) /* 分支空 */
{
p = q->a.bh.ptr[ord(K.ch[i])] = (TrieTree) malloc(sizeof(TrieNode));
p->kind = LEAF;
p->a.lf.K = K;
p->a.lf.infoptr = r;
} else if (p->kind == LEAF) /* 有不完全相同的叶子 */
{
K1 = p->a.lf.K;
do {
ap = q->a.bh.ptr[ord(K.ch[i])] = (TrieTree) malloc(sizeof(TrieNode));
ap->kind = BRANCH;
for (j = 0; j < LENGTH; j++) /* 指针量赋初值NULL */
ap->a.bh.ptr[j] = NULL;
q = ap;
i++;
} while (ord(K.ch[i]) == ord(K1.ch[i]));
q->a.bh.ptr[ord(K1.ch[i])] = p;
p = q->a.bh.ptr[ord(K.ch[i])] = (TrieTree) malloc(sizeof(TrieNode));
p->kind = LEAF;
p->a.lf.K = K;
p->a.lf.infoptr = r;
}
}
}
}
void TraverseDSTable(TrieTree T, Status(*Vi)(Record *)) { /* 初始条件: Trie键树T存在,Vi是对记录指针操作的应用函数 */
/* 操作结果: 按关键字的顺序输出关键字及其对应的记录 */
TrieTree p;
int i;
if (T) {
for (i = 0; i < LENGTH; i++) {
p = T->a.bh.ptr[i];
if (p && p->kind == LEAF)
Vi(p->a.lf.infoptr);
else if (p && p->kind == BRANCH)
TraverseDSTable(p, Vi);
}
}
}
Status pr(Record *r) {
printf("(%s,%d)", r->key.ch, r->others.ord);
return OK;
}
int main() {
TrieTree t;
int i;
char s[MAXKEYLEN + 1];
KeysType k;
Record *p;
Record r[N] = {{{"CAI"}, 1},
{{"CAO"}, 2},
{{"LI"}, 3},
{{"LAN"}, 4},
{{"CHA"}, 5},
{{"CHANG"}, 6},
{{"WEN"}, 7},
{{"CHAO"}, 8},
{{"YUN"}, 9},
{{"YANG"}, 10},
{{"LONG"}, 11},
{{"WANG"}, 12},
{{"ZHAO"}, 13},
{{"LIU"}, 14},
{{"WU"}, 15},
{{"CHEN"}, 16}};
/* 数据元素(以教科书式9-24为例) */
InitDSTable(&t);
for (i = 0; i < N; i++) {
r[i].key.num = strlen(r[i].key.ch) + 1;
r[i].key.ch[r[i].key.num] = Nil; /* 在关键字符串最后加结束符 */
p = SearchTrie(t, r[i].key);
if (!p)
InsertTrie(&t, &r[i]);
}
printf("按关键字符串的顺序遍历Trie树(键树):\n");
TraverseDSTable(t, pr);
printf("\n请输入待查找记录的关键字符串: ");
scanf("%s", s);
k.num = strlen(s) + 1;
strcpy(k.ch, s);
k.ch[k.num] = Nil; /* 在关键字符串最后加结束符 */
p = SearchTrie(t, k);
if (p)
pr(p);
else
printf("没找到");
printf("\n");
DestroyDSTable(&t);
return 0;
}
运行结果
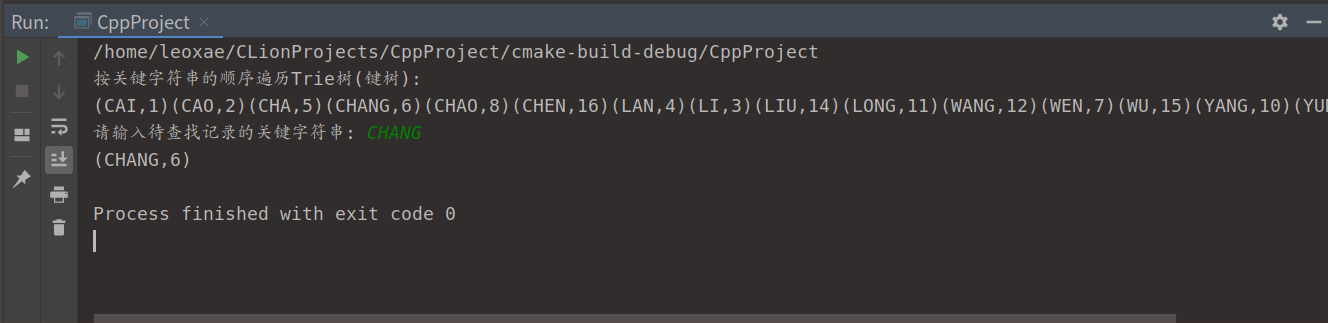
1.6.8 哈希表的基本操作
#include<stdio.h> /* EOF(=^Z或F6),NULL */
#include<math.h> /* floor(),ceil(),abs() */
#define OK 1
#define ERROR 0
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
#define NULLKEY 0 /* 0为无记录标志 */
#define N 10 /* 数据元素个数 */
#define OVERFLOW 3
typedef int KeyType; /* 设关键字域为整型 */
typedef struct {
KeyType key;
int ord;
} ElemType; /* 数据元素类型 */
#define EQ(a, b) ((a)==(b))
int hashsize[] = {11, 19, 29, 37}; /* 哈希表容量递增表,一个合适的素数序列 */
int m = 0; /* 哈希表表长,全局变量 */
typedef struct {
ElemType *elem; /* 数据元素存储基址,动态分配数组 */
int count; /* 当前数据元素个数 */
int sizeindex; /* hashsize[sizeindex]为当前容量 */
} HashTable;
#define SUCCESS 1
#define UNSUCCESS 0
#define DUPLICATE -1
Status InitHashTable(HashTable *H) { /* 操作结果: 构造一个空的哈希表 */
int i;
(*H).count = 0; /* 当前元素个数为0 */
(*H).sizeindex = 0; /* 初始存储容量为hashsize[0] */
m = hashsize[0];
(*H).elem = (ElemType *) malloc(m * sizeof(ElemType));
if (!(*H).elem)
exit(OVERFLOW); /* 存储分配失败 */
for (i = 0; i < m; i++)
(*H).elem[i].key = NULLKEY; /* 未填记录的标志 */
return OK;
}
void DestroyHashTable(HashTable *H) { /* 初始条件: 哈希表H存在。操作结果: 销毁哈希表H */
free((*H).elem);
(*H).elem = NULL;
(*H).count = 0;
(*H).sizeindex = 0;
}
unsigned Hash(KeyType K) { /* 一个简单的哈希函数(m为表长,全局变量) */
return K % m;
}
void collision(int *p, int d) /* 线性探测再散列 */
{ /* 开放定址法处理冲突 */
*p = (*p + d) % m;
}
Status SearchHash(HashTable H, KeyType K, int *p, int *c) { /* 在开放定址哈希表H中查找关键码为K的元素,若查找成功,以p指示待查数据 */
/* 元素在表中位置,并返回SUCCESS;否则,以p指示插入位置,并返回UNSUCCESS */
/* c用以计冲突次数,其初值置零,供建表插入时参考。*/
*p = Hash(K); /* 求得哈希地址 */
while (H.elem[*p].key != NULLKEY && !EQ(K, H.elem[*p].key)) { /* 该位置中填有记录.并且关键字不相等 */
(*c)++;
if (*c < m)
collision(p, *c); /* 求得下一探查地址p */
else
break;
}
if EQ(K, H.elem[*p].key)
return SUCCESS; /* 查找成功,p返回待查数据元素位置 */
else
return UNSUCCESS; /* 查找不成功(H.elem[p].key==NULLKEY),p返回的是插入位置 */
}
Status InsertHash(HashTable *, ElemType); /* 对函数的声明 */
void RecreateHashTable(HashTable *H) /* 重建哈希表 */
{ /* 重建哈希表 */
int i, count = (*H).count;
ElemType *p, *elem = (ElemType *) malloc(count * sizeof(ElemType));
p = elem;
printf("重建哈希表\n");
for (i = 0; i < m; i++) /* 保存原有的数据到elem中 */
if (((*H).elem + i)->key != NULLKEY) /* 该单元有数据 */
*p++ = *((*H).elem + i);
(*H).count = 0;
(*H).sizeindex++; /* 增大存储容量 */
m = hashsize[(*H).sizeindex];
p = (ElemType *) realloc((*H).elem, m * sizeof(ElemType));
if (!p)
exit(OVERFLOW); /* 存储分配失败 */
(*H).elem = p;
for (i = 0; i < m; i++)
(*H).elem[i].key = NULLKEY; /* 未填记录的标志(初始化) */
for (p = elem; p < elem + count; p++) /* 将原有的数据按照新的表长插入到重建的哈希表中 */
InsertHash(H, *p);
}
Status InsertHash(HashTable *H, ElemType e) { /* 查找不成功时插入数据元素e到开放定址哈希表H中,并返回OK; */
/* 若冲突次数过大,则重建哈希表。*/
int c, p;
c = 0;
if (SearchHash(*H, e.key, &p, &c)) /* 表中已有与e有相同关键字的元素 */
return DUPLICATE;
else if (c < hashsize[(*H).sizeindex] / 2) /* 冲突次数c未达到上限,(c的阀值可调) */
{ /* 插入e */
(*H).elem[p] = e;
++(*H).count;
return OK;
} else
RecreateHashTable(H); /* 重建哈希表 */
return ERROR;
}
void TraverseHash(HashTable H, void(*Vi)(int, ElemType)) { /* 按哈希地址的顺序遍历哈希表 */
int i;
printf("哈希地址0~%d\n", m - 1);
for (i = 0; i < m; i++)
if (H.elem[i].key != NULLKEY) /* 有数据 */
Vi(i, H.elem[i]);
}
Status Find(HashTable H, KeyType K, int *p) { /* 在开放定址哈希表H中查找关键码为K的元素,若查找成功,以p指示待查数据 */
/* 元素在表中位置,并返回SUCCESS;否则,返回UNSUCCESS */
int c = 0;
*p = Hash(K); /* 求得哈希地址 */
while (H.elem[*p].key != NULLKEY && !EQ(K, H.elem[*p].key)) { /* 该位置中填有记录.并且关键字不相等 */
c++;
if (c < m)
collision(p, c); /* 求得下一探查地址p */
else
return UNSUCCESS; /* 查找不成功(H.elem[p].key==NULLKEY) */
}
if EQ(K, H.elem[*p].key)
return SUCCESS; /* 查找成功,p返回待查数据元素位置 */
else
return UNSUCCESS; /* 查找不成功(H.elem[p].key==NULLKEY) */
}
void print(int p, ElemType r) {
printf("address=%d (%d,%d)\n", p, r.key, r.ord);
}
int main() {
ElemType r[N] = {{17, 1},
{60, 2},
{29, 3},
{38, 4},
{1, 5},
{2, 6},
{3, 7},
{4, 8},
{60, 9},
{13, 10}};
HashTable h;
int i, p;
Status j;
KeyType k;
InitHashTable(&h);
for (i = 0; i < N - 1; i++) { /* 插入前N-1个记录 */
j = InsertHash(&h, r[i]);
if (j == DUPLICATE)
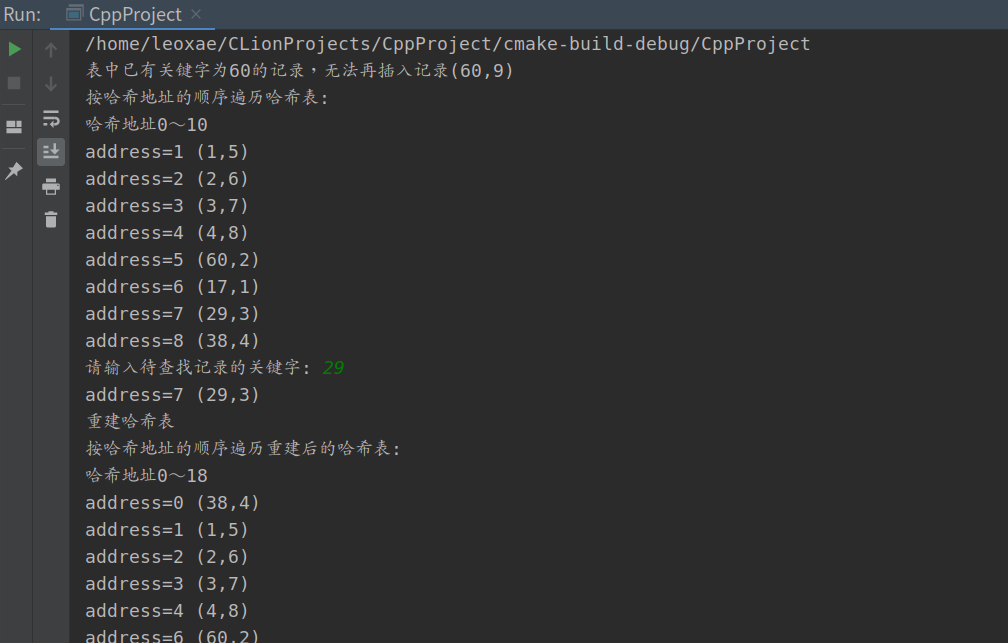
printf("表中已有关键字为%d的记录,无法再插入记录(%d,%d)\n", r[i].key, r[i].key, r[i].ord);
}
printf("按哈希地址的顺序遍历哈希表:\n");
TraverseHash(h, print);
printf("请输入待查找记录的关键字: ");
scanf("%d", &k);
j = Find(h, k, &p);
if (j == SUCCESS)
print(p, h.elem[p]);
else
printf("没找到\n");
j = InsertHash(&h, r[i]); /* 插入第N个记录 */
if (j == ERROR) /* 重建哈希表 */
j = InsertHash(&h, r[i]); /* 重建哈希表后重新插入第N个记录 */
printf("按哈希地址的顺序遍历重建后的哈希表:\n");
TraverseHash(h, print);
printf("请输入待查找记录的关键字: ");
scanf("%d", &k);
j = Find(h, k, &p);
if (j == SUCCESS)
print(p, h.elem[p]);
else
printf("没找到\n");
DestroyHashTable(&h);
return 0;
}
Talk is cheap. Show me the code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号