
Hive与Mysql之间的藕断丝连
背景:最近做的一个项目需求需要把生产环境服务器上指定目录下数据推送到hdfs上,然后通过hive去查询,但在安装hive之前需要先安装mysql,原因是啥呢?先了解下他们之间的关系。
一、什么是Hive
Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL(数据仓库技术,将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程)的工作。
hive定义了一个类似于SQL的查询语言:HQL,能够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive 可以看成是从SQL到MapReduce的映射器
以下是hive的架构:
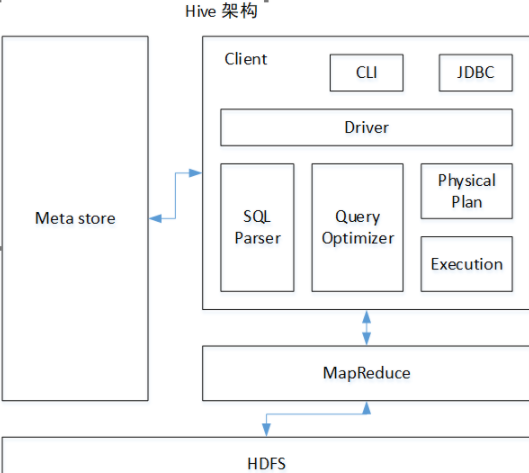
二、Hive与Mysql之间的联系
默认情况下,Hive元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。为了支持多用户多会话,则需要一个独立的元数据库,我们使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
hive的安装有三种模式:
内嵌模式:元数据保持在内嵌的Derby模式,只允许一个会话连接
本地独立模式:在本地安装Mysql,把元数据放到Mysql内
远程模式:元数据放置在远程的Mysql数据库。
目的是使用Mysql作为Hive metaStore的存储数据库
| 表名 | 说明 | 关联键 |
| TBLS | 所有hive表的基本信息(表名,创建时间,所属者等) | TBL_ID,SD_ID |
| TABLE_PARAM | 表级属性,(如是否外部表,表注释,最后修改时间等) | TBL_ID |
| COLUMNS | Hive表字段信息(字段注释,字段名,字段类型,字段序号) | SD_ID |
| SDS | 所有hive表、表分区所对应的hdfs数据目录和数据格式 | SD_ID,SERDE_ID |
| SERDE_PARAM | 序列化反序列化信息,如行分隔符、列分隔符、NULL的表示字符等 | SERDE_ID |
| PARTITIONS | Hive表分区信息(所属表,分区值) | PART_ID,SD_ID,TBL_ID |
| PARTITION_KEYS | Hive分区表分区键(即分区字段) | TBL_ID |
| PARTITION_KEY_VALS | Hive表分区名(键值) | PART_ID |
(1)hive数据的存放地
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的元数据保存在mysql中(或Derby)。
(2)hive表的类型
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
三、Hive与Mysql之间的区别
-
Hive采用了类SQL的查询语言HQL(hive query language)。除了HQL之外,其余无任何相似的地方。Hive是为了数据仓库设计的。
-
存储位置:Hive在Hadoop上;Mysql将数据存储在设备或本地系统中;
-
数据更新:Hive不支持数据的改写和添加,是在加载的时候就已经确定好了;数据库可以CRUD;
-
索引:Hive无索引,每次扫描所有数据,底层是MR,并行计算,适用于大数据量;MySQL有索引,适合在线查询数据;
-
执行:Hive底层是MarReduce;MySQL底层是执行引擎;
-
可扩展性:Hive:大数据量,慢慢扩去吧;MySQL相对就很少

 浙公网安备 33010602011771号
浙公网安备 33010602011771号