
动态博客
1、@Builder
依赖
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
反编译文件Card.class
public class Card { private int id; private String name; private boolean sex; Card(int id, String name, boolean sex) { this.id = id; this.name = name; this.sex = sex; } public static Card.CardBuilder builder() { return new Card.CardBuilder(); } public static class CardBuilder { private int id; private String name; private boolean sex; CardBuilder() { } public Card.CardBuilder id(int id) { this.id = id; return this; } public Card.CardBuilder name(String name) { this.name = name; return this; } public Card.CardBuilder sex(boolean sex) { this.sex = sex; return this; } public Card build() { return new Card(this.id, this.name, this.sex); } public String toString() { return "Card.CardBuilder(id=" + this.id + ", name=" + this.name + ", sex=" + this.sex + ")"; } } }
使用
1、类注解:@Builder(toBuilder = true) 2、Card card = Card.builder().id(10).name("dasd").sex(true).build();
不需要太多的set方法来定义属性内容。对属性的赋值采用Builder的方式,这种方式最优雅,也更符合封装的原则,不对外公开属性的写操作!
编译后使得Card类中多了一个名为Card.CardBuilder的静态内部类。这个静态类拥有和Card类相同的属性,并且他额外实现了一些方法。
缺点:
在生成Card实例之前,实际上是先创建了一个Card.CardBuilder实例,这样很明显额外占用了内存。
2、Objects.equals
JDK1.7提供的Objects.equals方法,非常方便地实现了对象的比较,有效地避免了繁琐的空指针检查
1、a.equals(b), a 是null, 抛出NullPointException异常。
2、a.equals(b), a不是null, b是null, 返回false
3、Objects.equals(a, b)比较时, 若a 和 b 都是null, 则返回 true, 如果a 和 b 其中一个是null, 另一个不是null, 则返回false。
注意:
不会抛出空指针异常。null.equals("abc") → 抛出 NullPointerException 异常。
"abc".equals(null) → 返回 false null.equals(null) → 抛出 NullPointerException 异常 Objects.equals(null, "abc") → 返回 false Objects.equals("abc",null) → 返回 false Objects.equals(null, null) → 返回 true
3、foreach之collection
foreach元素的属性主要有 item,index,collection,open,separator,close。
item表示集合中每一个元素进行迭代时的别名,
index指 定一个名字,用于表示在迭代过程中,每次迭代到的位置,
open表示该语句以什么开始,
separator表示在每次进行迭代之间以什么符号作为分隔 符,
close表示以什么结束。
collection:
1. 如果传入的参数类型是一个List的时候,collection属性值为list
2. 如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array
3. 如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可
#模糊多项查询 <if test="projCode !=null"> and <foreach collection="projCode" index="index" item="pcode" open="(" separator="or" close=")"> p.code like CONCAT('%',#{pcode},'%') </foreach> </if>
4、批量插入
<insert id="insertBatch" parameterType="entity.ProjIncoCosPla"> insert into proj_inc_co_pn (id, proj_id, proj_milep_id, nam, ordr_nu, incom_fla, incom_rati, incom_amoun, cos_rati ) values <foreach collection="list" item="paramValue" index="index" separator=","> ( #{paramValue.id,jdbcType=BIGINT}, #{paramValue.projId,jdbcType=BIGINT}, #{paramValue.projMilepId,jdbcType=BIGINT}, #{paramValue.nam,jdbcType=VARCHAR}, #{paramValue.ordeNu,jdbcType=BIGINT}, #{paramValue.incomFla,jdbcType=BIT}, #{paramValue.incomRati,jdbcType=DECIMAL}, #{paramValue.incomAmoun,jdbcType=DECIMAL}, #{paramValue.cosRati,jdbcType=DECIMAL} ) </foreach> </insert>
5、多项查询(传入逗号隔开的值)
Map<String,Object> header = new HashMap<>(); if(orgFrom != null) { String[] split = orgFrom.split(","); List<String> orgFromList = Stream.of(split).map(String::toString).collect(Collectors.toList()); header.put("orgFromList", orgFromList); } header.put("orgFrom",orgFrom); List<OrgCustDiHea> orgCustDiHea = orgMapper.selectAll(header);
<select id="selectAll" parameterType="java.util.Map" resultType="entity.OrgCustDiHea"> select <include refid="Base_Column_List" /> from ctd.dict_header ocdh where ocdh.deleted_flag = 0 <if test="orgName != null and orgName != ''"> and ocdh.org_name = #{orgName} </if> <if test="orgFromList != null and orgFromList.size > 0"> and ocdh.org_from in <foreach collection="orgFromList" item="org" index="index" open="(" separator="," close=")"> #{org} </foreach> </if> order by ocdh.org_name asc </select>
6、SprintBoot之spring.factories
spring.factories文件
Spring Factories实现原理
spring-core包里定义了SpringFactoriesLoader类,这个类实现了检索META-INF/spring.factories文件,并获取指定接口的配置的功能。在这个类中定义了两个对外的方法:
1、loadFactories。根据接口类获取其实现类的实例,这个方法返回的是对象列表。
2、loadFactoryNames。根据接口获取其接口类的名称,这个方法返回的是类名的列表。
上面的两个方法的关键都是从指定的ClassLoader中获取spring.factories文件,并解析得到类名列表。
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
config.GatewayWebConfiguration,\
config.RestTemplateConfig,\
config.StatWebConfig
加载factories文件
从代码中我们可以知道,在这个方法中会遍历整个ClassLoader中所有jar包下的spring.factories文件。也就是说我们可以在自己的jar中配置spring.factories文件,不会影响到其它地方的配置,也不会被别人的配置覆盖。
源码 public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories"; private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) { MultiValueMap<String, String> result = cache.get(classLoader); if (result != null) { return result; } try { Enumeration<URL> urls = (classLoader != null ? classLoader.getResources(FACTORIES_RESOURCE_LOCATION) : ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION)); result = new LinkedMultiValueMap<>(); while (urls.hasMoreElements()) { URL url = urls.nextElement(); UrlResource resource = new UrlResource(url); Properties properties = PropertiesLoaderUtils.loadProperties(resource); for (Map.Entry<?, ?> entry : properties.entrySet()) { List<String> factoryClassNames = Arrays.asList( StringUtils.commaDelimitedListToStringArray((String) entry.getValue())); result.addAll((String) entry.getKey(), factoryClassNames); } } cache.put(classLoader, result); return result; } catch (IOException ex) { throw new IllegalArgumentException("Unable to load factories from location [" + FACTORIES_RESOURCE_LOCATION + "]", ex); } }
也可以使用:在@SpringBootApplication启动类加上@Import(需要注入的类) 实现。
7、雪花id、自增id、uuid
最常见的两种主键类型是自增Id和UUID,两者之间最大的不同点就在于有序性,主键有序比无序查询效率要快。自增id会担心主键重复,UUID不能保证有序性。
不用自增id的情况
1、容易导致主键重复。比如导入旧数据时,线上又有新的数据新增,这时就有可能在导入时发生主键重复的异常。为了避免导入数据时出现主键重复的情况,要选择在应用停业后导入旧数据,导入完成后再启动应用。显然这样会造成不必要的麻烦。而UUID作为主键就不用担心这种情况。
2、不利于数据库的扩展。当采用自增id时,分库分表也会有主键重复的问题。UUID则不用担心这种问题。
SnowFlakeID的最大的特性就是天然去中心化,通过时间戳、工作机器编号两个变量进行配置后,通过SnowFlake算法会生成唯一的递增ID。在任何机器上,只要保证工作机器编号不同,就可以确保生成的ID唯一,且整体趋势是递增的
0 - 0000000000 0000000000 0000000000 0000000000 0 - 0000000000 – 000000000000
第一段1位为未使用,永远固定为0
第二段41位为毫秒级时间(41位的长度可以使用69年)
第三段10位为workerId(10位的长度最多支持部署1024个节点)
第四段12位为毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号),12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
缺点也是有的,就是强依赖机器时钟,如果机器上时钟回拨,有可能会导致主键重复的问题。
美团开源的Leaf
百度开源的UidGenerator
优化方案:用变量记录上一个id的时间戳,如果当前的时间戳小于上一个的,那么就阻塞1s或者直接抛出异常,重新获取id。
8、PL/SQL
Procedural Language/SQL,Oracle数据库对SQL语句的扩展,在普通SQL语句的使用上增加了编程语言的特点。在SQL命令语言中增加了过程处理语句(如分支、循环等),使sql语言具有过程处理能力。
扩展:结构化查询语言(Structured Query Language,简称SQL)是用来访问关系型数据库一种通用语言,属于第四代语言(4GL),其执行特点是非过程化,即不用指明执行的具体方法和途径,而是简单地调用相应语句来直接取得结果即可。
PL/SQL程序都是以块(block)为基本单位,整个PL/SQL块分三部分:声明部分(用declare开头)、执行部分(以 begin开头)和异常处理部分(以exception开头)。
格式: declare /* 声明区(可选):定义类型和变量、声明变量、声明函数、游标 */ begin /* 执行区(必须的):执行pl/sql语句或者sql语句 */ exception /* 异常处理区(可选):处理错误的 */ end;
比如建立一个包头如下:
比如建立一个包头如下: create or replace PACKAGE LSG_OBC_ORDERS_HK01_EC_PKG AS PROCEDURE LSG_OBC_HK01_main( errbuf OUT VARCHAR2, --plsql 必须的参数格式,照着写就行 retcode OUT NUMBER, --plsql 必须的参数格式,照着写就行 p_ou IN VARCHAR2, --你自己定义的参数 1 p_from_date IN VARCHAR2, -- 你自己定义的桉树 2 p_to_date IN VARCHAR2 ); --你自己订单的参数 3 END LSG_OBC_ORDERS_HK01_EC_PKG;
LSG_OBC_HK01_main 这个主函数, 这个函数里面放你需要的sql代码
----执行--- DECLARE aaaa VARCHAR2(100); retcode number; testvalue VARCHAR2(20); p_ou VARCHAR2(100); p_from_date VARCHAR2(100); p_to_date varchar2(100); BEGIN p_ou := '1234'; --公司代码 p_from_date := '20190201'; p_to_date := '20190201'; testvalue := 'First Test!'; dbms_output.put_line( testvalue ); LSG_OBC_ORDERS_HK01_EC_PKG.LSG_OBC_HK01_main(aaaa , retcode, p_ou ,p_from_date,p_to_date ); --参数对应好,依次放入 END;
存储过程:存储过程是一组为了完成特定功能的SQL语句,经编译后存储在数据库中。create or replace procedure p is 相当于PLSQL中的declare。
9、KILL/RM
kill -Signal pid (signal是发送给进程的信号)
kill -l 查看所有信号名称
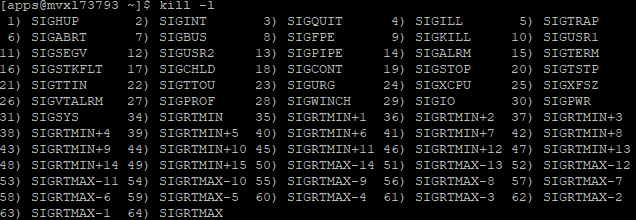
如果是前台进程可以使用Ctrl+C键进行终止;如果是后台进程,那么需要使用kill命令来终止。
kill命令默认的信号就是15,当使用 kill -15 时,系统会发送一个SIGTERM的信号给对应的程序。当程序接收到该信号后,具体要如何处理是自己可以决定的。
这时候,应用程序可以选择:
1、立即停止程序
2、释放响应资源后停止程序
3、忽略该信号,继续执行程序
和 kill -15 相比, kill -9 就相对强硬一点,系统会发出SIGKILL信号,他要求接收到该信号的程序应该立即结束运行,不能被阻塞或者忽略。
所以,相比于kill -15命令,kill -9在执行时,应用程序是没有时间进行"准备工作"的,所以这通常会带来一些副作用,数据丢失或者终端无法恢复到正常状态等。
rm -rf
命令的名字是rm,单词remove(删除)的缩写。r是给rm加入递归(recursion)特性,也就是目标为文件夹时删除文件夹下所有数据。f给rm加入强制(force)特性,也就是遇到删除时不需要询问即可直接删除。
10、性能测试
TPS
TPS(Transactions Per Second) 也就是事务数/秒。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
Tps即每秒处理事务数,包括了
○ 用户请求服务器
○ 服务器自己的内部处理
○ 服务器返回给用户
这三个过程,每秒能够完成N个这三个过程,Tps也就是N
QPS
QPS(Queries Per Second)是每秒查询率 ,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
即每秒的响应请求数,也即是最大吞吐能力。
并发数
并发数(并发度):指系统同时能处理的请求数量,同样反应了系统的负载能力。这个数值可以分析机器1s内的访问日志数量来得到。
QPS(TPS)=并发数/平均响应时间
一个系统吞吐量通常有QPS(TPS),并发数两个因素决定,每套系统这个两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换,内存等等其他消耗导致系统性能下降。
吞吐量
吞吐量是指系统在单位时间内处理请求的数量,TPS、QPS都是吞吐量的常用量化指标。
PV
PV(Page View):页面访问量,即页面浏览量或点击量,用户每次刷新即被计算一次。可以统计服务一天的访问日志得到。
事务
在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。例如:在关系数据库中,一个事务可以是一条SQL语句,一组SQL语句或整个程序。
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
1、原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。
2、一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
3、隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
4、持久性(durability)。持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
1、在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
2、事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
3、事务用来管理 insert,update,delete 语句
11、SQL执行对象
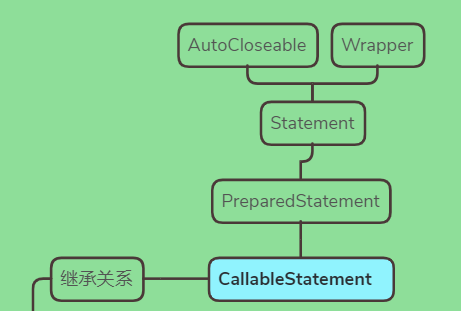
CallableStatement
添加了调用存储过程核函数以及处理输出参数的方法。
实现了存储过程函数调用的方法以及对于输出的处理,用于执行 SQL 存储过程的接口,实现了对输入和输出的支持,在prepareStatement大量setXXX方法基础上扩展了getXXX
PreparedStatement
添加了处理输入参数的方法
支持可变参数的SQL
预编译,被缓冲,会被再次解析,但不会被再次编译,能够有效提高系统性能。
能够预防SQL注入攻击,通过预编译,原有的SQL语句中的参数转换为占位符? 的形式,输入的内容作为参数,而不可能作为SQL的一部分。
假如登录SQL为select * from user where name='姓名' and password='密码' ,如果在登录框密码处输入 “密码 or 1=1”,那么SQL就成为了
select * from user where name='姓名' and password='密码' or 1=1 ,这就是SQL注入。你把密码输入为‘密码 or 1=1’然后提交,他会转换为 and password='密码' or 1=1 输入内容都转换为纯粹参数。
SQL注入
将SQL语句片段插入到被执行的语句中,把SQL命令插入到Web表单提交或者输入域名或者页面请求的查询字符串,最终达到欺骗服务器,达到执行恶意SQL命令的目的。
Statement
提供了执行语句和获取结果的基本方法
普通的不带参的查询SQL
每次的执行都需要编译SQL


12、JDBC
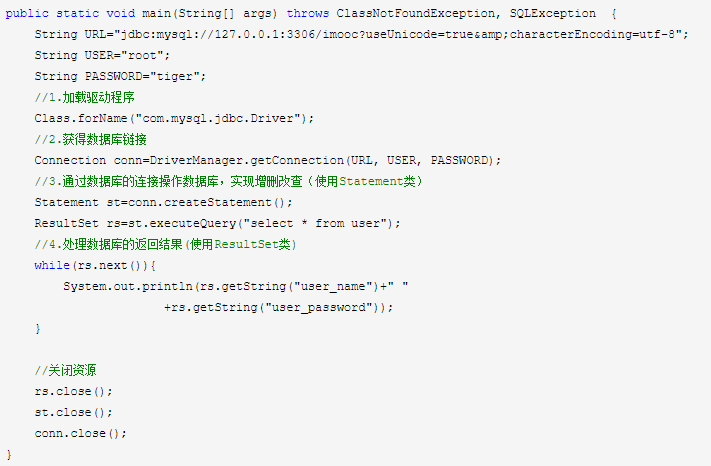
Java Data Base Connectivity (java数据库连接),可以为多种数据库提供填统一的访问。
(1)建立与数据库或者其他数据源的链接
(2)向数据库发送SQL命令
(3)处理数据库的返回结果
常用类或接口
驱动程序管理类(DriverManager):DriverManager类是JDBC的管理类,作用于用户和驱动程序之间。直接使用唯一的方法时DriverManager.getConnection()。该方法将建立与数据库的链接。
声明类(Statement):Statement对象用于将SQL语句发送到数据库中。
数据库连接类 (Connection):Connection对象代表与数据库的链接。连接过程包括所执行的SQL语句和在该连接上所返回的结果。
结果集合类 (ResultSet):ResultSet包含符合SQL语句中条件的所有行记录,并且它通过一套get方法(提供了对这些行中数据的访问。ResultSet.next()方法用于移动到ResultSet中的下一行,使下一行成为当前行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号