
中文分词&词向量化
NLP: 1.分词(代表:jieba)----2.向量化(包括字符向量化、词向量化、拼音向量化、词性向量化等,代表:word2vec,glove)----3.进一步分析

一、jieba
“结巴”中文分词:做最好的 Python 中文分词组件,参考资料
特点
- 支持四种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- paddle模式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。paddle模式使用需安装paddlepaddle-tiny,
pip install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba v0.40以下版本,请升级jieba,pip install jieba --upgrade。PaddlePaddle官网
- 支持繁体分词
- 支持自定义词典
- MIT 授权协议
主要功能
- 分词。jieba.cut(), jieba.cut_for_search()
- 添加自定义词典。jieba.load_userdict(file_name)
- 关键词提取。a.基于tdfif:jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=()) b.基于textrank:jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
- 词性标注。jieba.posseg.POSTokenizer(tokenizer=None),标注句子分词后每个词的词性
- 并行分词。jieba.enable_parallel(4),将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词。
- Tokenize:返回词语在原文的起止位置
- ChineseAnalyzer for Whoosh 搜索引擎。from jieba.analyse import ChineseAnalyzer
- 命令行分词。使用示例:
python -m jieba news.txt > cut_result.txt
二、向量化
代表算法:word2vec,包括了CBOW和skip-gram两种模式。
其实词组向量化不止word2vec,还有比如Doc2Vec,FastTest等。
以CBOW算法为例说明计算流程:
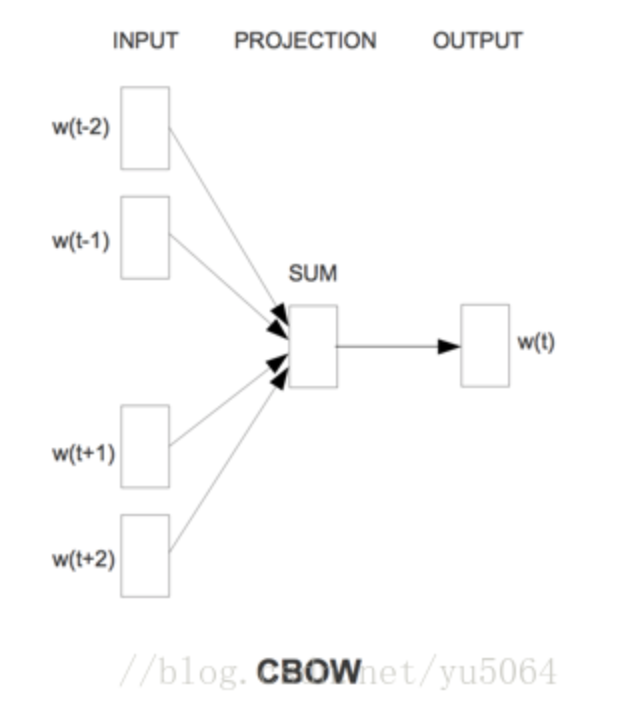
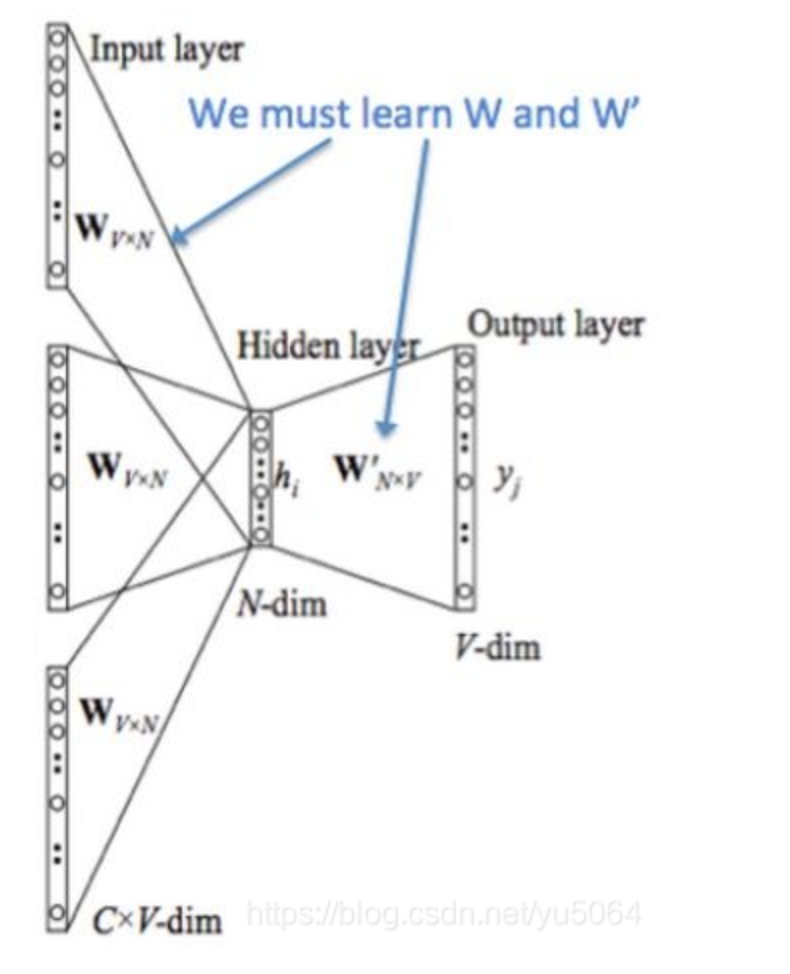
用中心词前后的词,来计算中心词的词向量。
a.首先将前后词进行one-hot编码,1*V维度,V是字典长度。
b.1*V 乘以V*N的权重矩阵,1*N,并相加,得到隐藏层,Hidden layer,1*N。(N是我们设定的要求的词向量长度)
c.乘以N*V的权重系数,得到1*N的向量,就是我们要求的长度为N的该词的向量。
词向量化1
【NLP学习笔记1】分词和词向量
posted on 2020-03-23 15:06 静静的白桦林_andy 阅读(1041) 评论(0) 编辑 收藏 举报

