
sklearn包源码分析(一)--neighbors
在anaconda的安装目录下,有一块会放着我们安装的所有包,在里面可以找到所有的包
找到scikit learn包,进入

这里面又有了多个子包,每个子包就是一个主要的算法或功能块。我们经常使用的一些算法或功能,比如线性模型、集成算法、神经网络、邻近neighbors算法,都是在这里面实现的。我们可以进入这些代码,看看底层到底是如何实现的。
来理一下sklearn中neighbors算法的实现。
neighbors中,又分为按照不同的问题(分类、回归),不同的算法(knn、最近形心点、kernel密度)等放在不同的模块

这部分内容参考:sklearn中knn相关包
KNN和限定半径最近邻法使用的算法algorithm:算法一共有三种,第一种是蛮力实现,第二种是KD树实现,第三种是球树实现。这三种方法在K近邻法(KNN)原理小结中都有讲述。
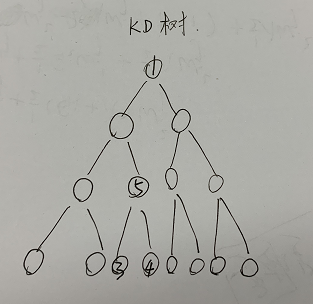
如果用蛮力计算,当样本量较大时,计算量太大,所以就要考虑节省计算量的方法,KD树或者球树都是这样的方法,主要目的就是节省找到预测样本的k个最近邻节点的时间。主要操作就是,1.先建一个kd树(根据训练样本建树),2.然后把待预测样本放到kd树的相应叶子结点,通过比较结点中最短距离与与父节点中最短距离、直到根结点,来找到最近结点,第二轮把刚才找到的结点抛掉后再进行第二轮找到余下样本中最近的结点,这样进行k轮,找到k个最近邻,3.根据k个最近邻训练样本y值给出待预测样本y值。
以上就是neighbors包中所有的内容,具体的代码里面的内容参考下面的文章。
下面先粘一个集成算法的文章
posted on 2019-11-08 15:42 静静的白桦林_andy 阅读(3528) 评论(0) 编辑 收藏 举报

