
树模型
一、简介
树模型是一种非线性模型。决策树是一种监督学习算法,输入和输出变量可以是离散值或连续值。
二、涉及到的术语
根节点、决策节点、叶子/终端节点、剪枝、分支/子树、父节点和孩子节点
特征选择、树的生成、剪枝
三、建模流程
1.缺失值填充(cart模型自动填充,id3和c4.5需要手动填充)
2.连续自变量离散化
2.1 无监督方法:等宽、等频、聚类算法
2.2 有监督方法:基于卡方的方法、基于信息熵的方法、LR方法
3.如果类别变量分类过多,要进行合并。
4.选择分裂节点
5.检查分裂节点是否满足停止分裂条件,如果满足,置该节点为叶子节点,返回节点中最多类别标记(分类问题)、或者返回节点的均值(回归问题)。否则按照3中选出节点分裂。
6.重复3/4直到满足分裂停止条件。
四、方法及区别
| 树的分裂准则 | 处理缺失值 |
能否自动处理连续自 变量 |
说明 | 能否处理回归问题 | 是否有剪枝操作 | 树的结构 | |
| id3 | 信息增益最大 | 没有自动处理 |
不能,要事先手动把 连续自变量离散化。 |
1986,Ross Quinlan | 只能处理分类问题 | 有 | 多枝树 |
| c4.5 | 信息增益比最大 | 没有自动处理 |
可以,自动把连续自变量 离散化。 |
只能处理分类问题 | 有 | 多枝树 | |
| cart |
当cart是分类树时,采用 gini最小作为分裂节点的 依据; 当cart对于回归问题,采 用样本量的最小方差mse 作为分裂节点依据,也可 以采用MAE、 Friedman_mse(改进mse)。 |
至少在sklearn 中是没有 自动处理的, 如果有缺 失就会报 错。 |
可以。 对于选定的分类自变量, 划分为是、或不是。这 样每个都是二叉树。 对于连续自变量,对于 每个可能的切分点,分 别计算相应的均方差或 gini,选择最优变量最 优切分点。 |
1984年,四人帮 Leo Breiman、 等提出 |
既能是分类树, 又能是回归树。 |
二叉树 |
注意:(1)cart与id3和c4.5不同的是他能处理回归问题。
(2)cart不计算规则集,我理解就是变量可以重复选择使用。
(3)sklearn中的cart暂时不支持类别型自变量。could not convert string to float: 'M' 20190910
这样的安排是更合理的。因为cart是二叉树,如果按照cart原思路实现类别自变量的处理,则只能
实现 1类vs其它 的效果,而不能把某两类分到一起,余下的分到一起。按照sklearn中cart的实现,
需要我们手动把类别变量one hot处理一下,这样可以实现刚才说的交叉效果,效果更好。
参考资料:https://scikit-learn.org/stable/modules/tree.html#tree-algorithms-id3-c4-5-c5-0-and-cart
(4)sklearn中对树模型只实现了cart树,没有实现id3和c4.5
参考资料:https://blog.csdn.net/appleyuchi/article/details/82953806
(5)sklearn中的cart树不允许有缺失值,否则会返回
ValueError: Input contains NaN, infinity or a value too large for dtype('float32').

上面是每种决策树算法针对不同问题时,对变量及分界点的选择方式。
五、节点复杂度(熵、gini值)、信息增益、信息增益比、gini值、回归方差
1.熵:描述了随机变量X不确定性(在具体的数据挖掘分类树中,我们想看的是y变量是否一致了,所以这里的变量是y变量)的度量。熵越大,随机变量不确定性越大,也就是纯度越低。
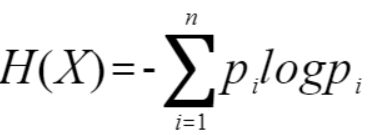
对于离散变量,n即为y变量的类别数。熵的符号沿用自热力学中熵的概念,取自Heat function,所以简写为H。
对于y变量为连续值时,就是回归问题了,节点分裂标准就用回归方差了,不用熵了,所以不存在连续y变量计算熵的问题。上面式子中的n就是取值种类。
对于自变量为连续值时,要先把自变量离散化,比如年龄,会按照[0,20]/[20,40]/[40,60]...划分为几个区间段,成为离散变量。
pi表示y变量类i的概率,即该值在总体数量中的占比。
信息熵中的log默认是以2为底或者以e为底。
熵的概念这块,在网上查的有各种资料,讨论的路径不一样,所以在看的时候要把握住一种绝对正确的就可以,
本文完全以李航的统计学习方法为依据,参考资料:《统计学习方法》p60
附加一个小的理解思路:从信息量--------到信息熵
多少信息用信息量来衡量,我们接受到的信息量跟具体发生的事件有关。信息量计算公式满足概率越大、提供的信息值越小。变量单个取值的信息量是-logP。当概率为1时,提供的信息量为0。
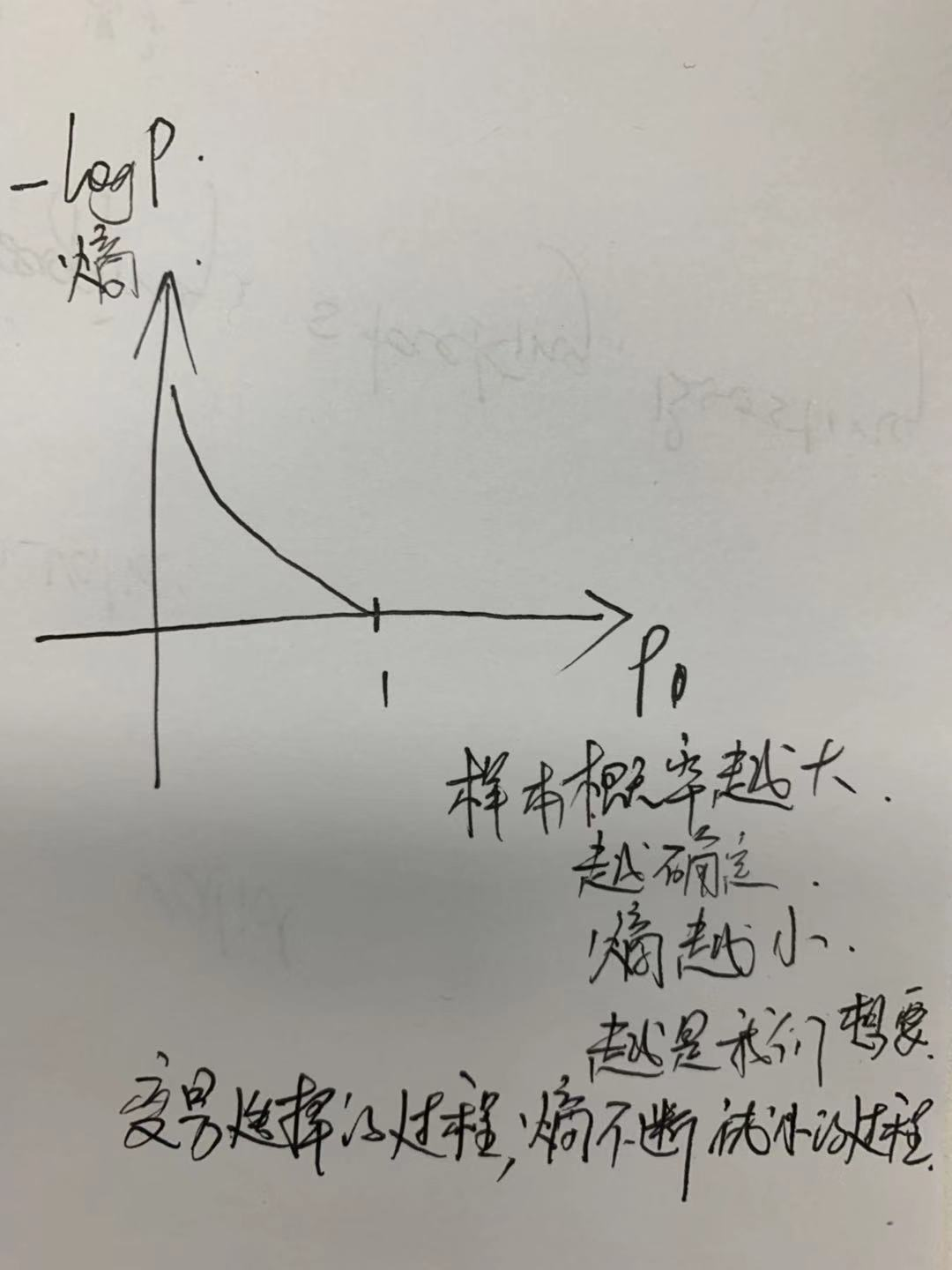
信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。
参考资料:
2.条件熵
条件熵表示在已知随机变量X的条件下随机变量Y的不确定性。
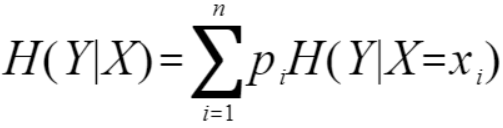
3.基尼值
单节点的基尼值计算式:
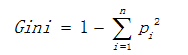
pi表示y变量类i在总体数量中的占比。
属性a的基尼指数定义为:
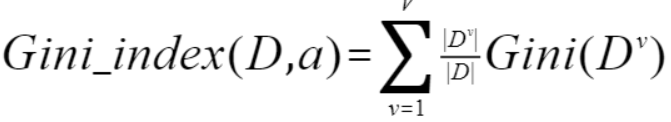
我们在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性。
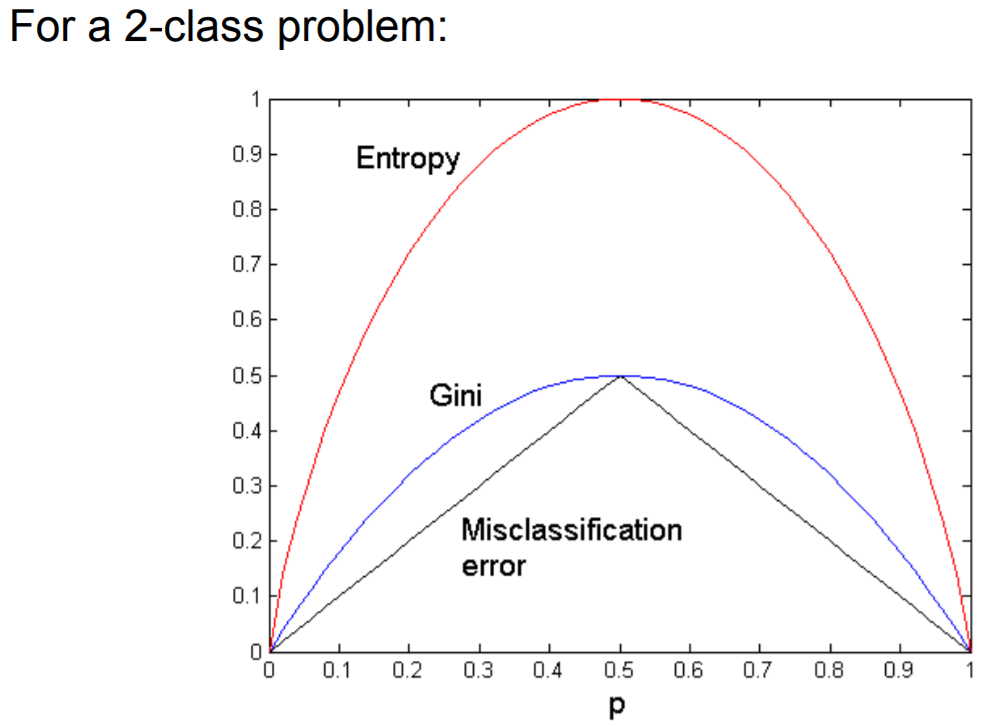
熵和基尼值是两种衡量数据集复杂度的指标,总体上比较类似,如下
4.信息增益:信息增益表示分裂前总体的数据复杂度和分裂后节点数据复杂度的变化值
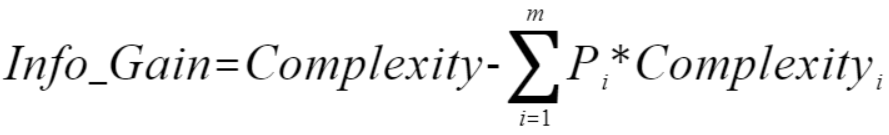
其中Complexity表示根节点的复杂度,Complexity(i)表示每个子节点的复杂度,m表示根据该自变量x(i)分类后的子节点数。
用统计学习方法中的讲述,就是:特征A对训练数据集D的信息增益g(D,A)为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即
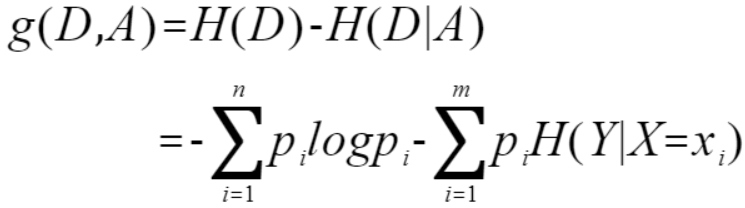
其中,n表示y变量的取值种类。m表示自变量X的取值种类。
可以看出,它们的计算在本质上是一样的。
记住一点,熵都是针对目标变量来计算的,也就是说都是看该节点中y变量各种类的占比。有时为了计算期望,会涉及到各子节点数据量占父节点比例,这个要弄清楚。
复杂度的计算方法是上面介绍的信息熵或者gini值,一般用信息熵比较多。
5.信息增益比:使用信息增益作为选择分裂的条件有一个不可避免的缺点:倾向选择分支比较多的属性进行分裂(极端情况下,每个样本都被分为一组,比如如果有个日期变量,
将每个样本分为了一组,这时每个样本计算熵时都是0,他们相加也还是0,因为每一组(只有一个样本)都是完全纯净的,那么熵增就会是最大的)。为了解决这个问题,引入
了信息增益率这个概念。http://www.ke.tu-darmstadt.de/lehre/archiv/ws0809/mldm/dt.pdf p22
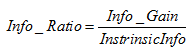
其中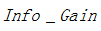 表示信息增益,
表示信息增益,  表示分裂子节点数据量的信息增益,其计算公式为:
表示分裂子节点数据量的信息增益,其计算公式为:
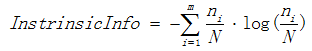
其中m表示子节点的数量,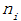 表示第i个子节点的数据量,N表示父节点数据量,说白了, 其实
表示第i个子节点的数据量,N表示父节点数据量,说白了, 其实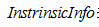 是分裂节点对于父亲节点的熵。
是分裂节点对于父亲节点的熵。
如果这样的话,那信息增益比和信息增益不都一样吗?这块我也没搞太清。
6.GINI值:
7.回归方差:
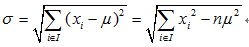
六、停止分裂条件
1.最小节点数
2.熵、gini值小于阈值
3.树的深度
4.所有特征用完(课本上写的特征只能用一次,但我发现很多实际算法中,特征是可以重复筛选的)
posted on 2019-08-28 17:50 静静的白桦林_andy 阅读(753) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号