


我注册了某音帐号之后。。。(内含推荐算法)
写在前面
某音作为风靡中外的一款音乐创意短视频社交软件,其成功性不言而喻,一直听说其强大的“威力”,但却从没深入研究过,作为人民的先锋队,这怎么行,毅然决然的我,在上周五注册了一个账号,但没想到的是等待我的确是一条不归路~(以下内容纯属个人经历与个人看法,没有任何代表性,图一乐呵儿)
一个视频在发出后要面临什么?
初入抖音的我很快就被它背后神奇的推荐算法,引流手段,DOU+上热门计划深深的吸引住了。
抱着试试看的态度,我尝试发了我第一个视频。在发之前我也是四处取经,怎么写文案,怎么配背景音乐,怎么找和文案有呼应的视频和照片。
最后在我高超的视频剪辑技术之下(也就废了刷五六道算法题的时间),终于把它发出去了。
了解到,抖音平台对每一个视频是有系统推荐的基础流量的(这里考虑到新用户首个视频的特殊性,这里从第二个视频开始分析)。

短视频发布后抖音一般会进行的一系列推荐流程。
如果从技术层面去分析的话,那是相当复杂的,涉及很多数学层面的知识,但我始终相信,一切知识都是简洁的。
所以我们何不以问题为导向,如果说你是某一鸣,可能的未来首富,你会如何去留住某音平台的创作者与用户们?
打分算法
在我把我的这个视频发出去之后,就开始了焦急的等待,人嘛,嘴上说着我不在乎,其实心里都希望获得一种认同感的。
看到有人观看点赞自己的作品,心里不开心是假的,真正做到宠辱不惊,不以物喜不以己悲,那也是看得多了,习惯了而已。
很快,距离我发布这个作品马上到一个小时了,但观看数据仍然是没有什么变化的,大约在1~2个小时之后,数据出现断崖式的增长,这说明平台开始给你引流了。

而这一套引流的机制,要看四个标准:点赞量、评论量、转发量、完播率。
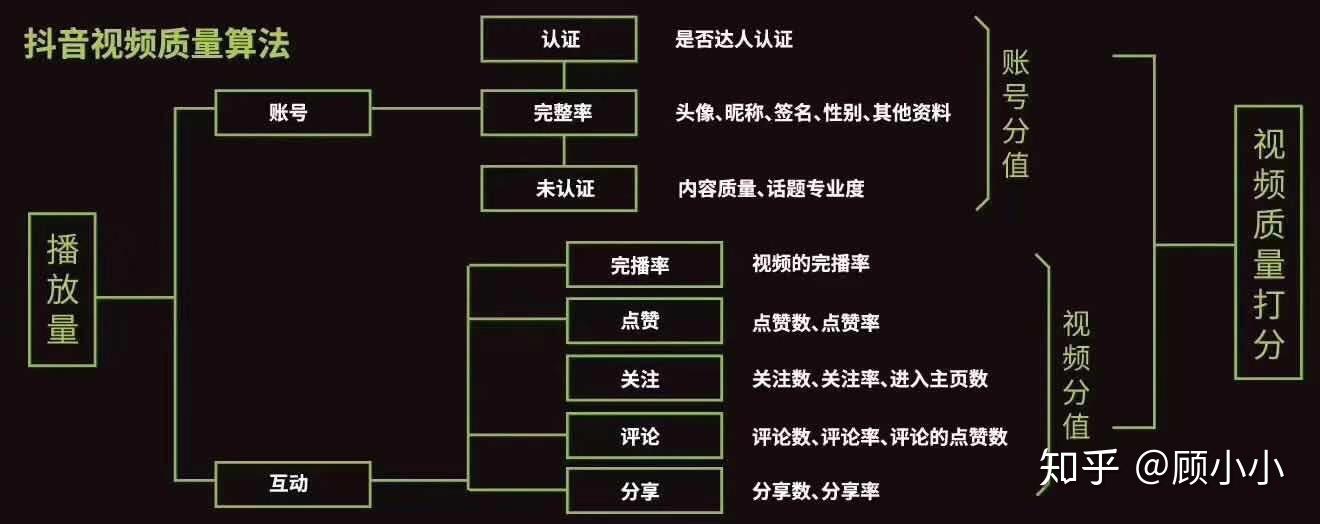
也就是在这个阶段你作品的质量就会打上一个又一个的标签,最后得到一个综合得分,来决定该作品的曝光率,而且这种曝光是层层递进的,上个阶段的总分决定你下个阶段的曝光率,当然如果你在第一个阶段的效果就不行,那也就不需要第二阶段了。
即播放量=A×完播率+B×点赞率+C×评论率+D×转发率
看了我视频的播放量,原来我连第一阶段都算不上,这可太惨了。
这一两百的播放,还是我冒着被围观社死的风险,分享到了我那些相亲相爱的一家人的群里,结果,果然被围观了。(不过,也让我明白一个道理,这世界上能永远无私对你好的只有你的父母,他们会在你的每一个作品下点赞,赞美天下父母)。

DOU+上播放量
如果说,要我说谁是这个世界上最大的大怨种,那这个人就是我(我自以为)。
来到这世上二十几载岁月,从没有让任何一个平台从我身上割下一把韭菜的我,被割了一把。

看到这个作品鹤立鸡群的播放量没,这是我花了30大洋送上去的。

结果投放质量不好,还被嘲讽了一波,也是属实扎心了。
推荐系统
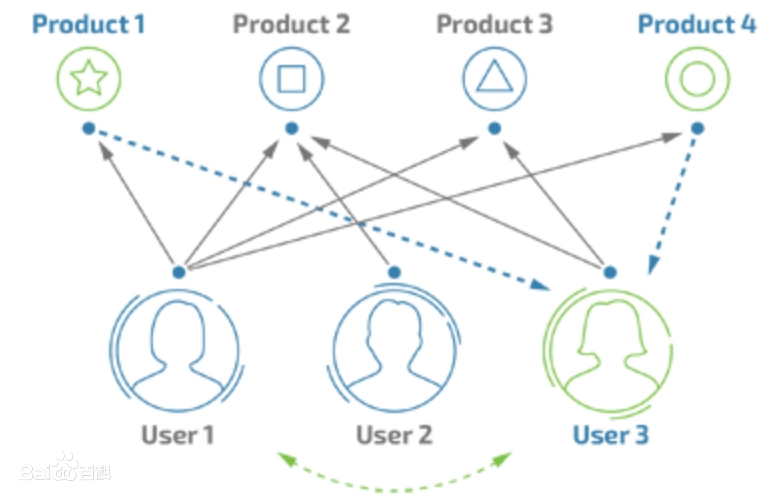
系统先识别出你想看的内容,读懂我们的需求,然后在内容池里匹配你想看的内容,最后展示出来,也就是千人千面,目前很多软件都能做到千人千面。接下来进入正题,了解抖音的推荐系统,主要包括三部分:用户画像、内容画像、用户和内容之间的匹配。
1)用户画像,系统根据用户基本属性(比如:性别、年龄、学历等)、兴趣爱好(比如:科技、娱乐、体育、金融等)等数据集,然后给肪定义相关的标签。
2)内容画像,系统根据内容的层级分类、关键词、实体词等分析出特点,给各类内容打上相关的标签。
3)用户与内容匹配,有了用户标签和内容标签之后,系统根据用户画像、内容画像,在内容池里面匹配出用户喜欢的内容然后展示出来。
4)排序,系统要面对数亿级的用户和内容,同时还要考虑用户的喜欢会不断的发生改变,为了让挑选的内容更加的贴近用户想要的、更加符合用户喜欢,系统需要对内容进行排序。
推荐算法
我们的日常生活现在已经被各种推荐算法包围了,不只是某音,还有某条,某团,某了么,甚至我们学校的一些APP都可以根据你常用的功能,推荐相应的信息。
但是对于我们这些非专业人士,能从这些推荐算法中得到什么呢?
百度百科:推荐算法是计算机专业中的一种算法,通过一些数学算法,推测出用户可能喜欢的东西,应用推荐算法比较好的地方主要是网络。所谓推荐算法就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西
起源
如果说非要给推荐算法找一个老祖宗,那就不得不提上世纪九十年代,一群美国明尼苏达大学的大学生,他们本意是想制作一个名为Movielens的电影推荐系统,从而实现对用户进行电影的个性化推荐。
但令他们没想到的是,这一举动,让这个网站的销售额提高了35%。
有利益的地方就会有资本的进入,在资本的驱动下,这项还很年轻的技术开始了快速的发展,个性化推荐的应用也越来越广泛。
五种常见推荐算法
基于内容的推荐、协同过滤推荐、基于关联规则的推荐、基于知识的推荐、混合推荐。
1.基于内容的推荐
基于内容的推荐(Content-based Recommendation)是信息过滤技术的延续与发展,它是建立在项目的内容信息上做出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。
也就是说这种算法是从供给侧上分析,只管视频内容,不管你用户怎么看怎么评价。
2.协同过滤算法
基于协同过滤的推荐算法(Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,从而根据这一喜好程度来对目标用户进行推荐。

该算法是诞生最早,并且较为著名的推荐算法,主要的功能是预测和推荐。
说白了,就是把人分成不同的兴趣小组,把作品贴上相应的兴趣标签,在推给对应的小组。
3.基于关联规则的推荐
基于关联规则的推荐(Association Rule-based Recommendation)是以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。关联规则挖掘可以发现不同商品在销售过程中的相关性,在零售业中已经得到了成功的应用。
关联规则就是在一个交易数据库中统计购买了商品集X的交易中有多大比例的交易同时购买了商品集y。
其直观的意义就是用户在购买某些商品的时候有多大倾向去购买另外一些商品。比如购买牛奶的同时很多人会购买面包。
4.基于知识的推荐
基于知识的推荐(Knowledge-based Recommendation)在某种程度是可以看成是一种推理(Inference)技术,它不是建立在用户需要和偏好基础上推荐的。
比如说,你在平台上的用户资料就可以是任何能支持推理的知识结构,它可以是用户已经规范化的查询,也可以是一个更详细的用户需要的表示
5.混合推荐
混合推荐即将上面的4种算法组合应用,充分利用各个算法的优点解决现实的问题。
一个简单的推荐算法实例
网上这种例子很多,这里给大家找了一个。
python实现协同过滤推荐算法完整代码示例: https://www.jb51.net/article/130674.htm
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from numpy import *
import time
from texttable import Texttable
class CF:
def __init__(self, movies, ratings, k=5, n=10):
self.movies = movies
self.ratings = ratings
# 邻居个数
self.k = k
# 推荐个数
self.n = n
# 用户对电影的评分
# 数据格式{'UserID:用户ID':[(MovieID:电影ID,Rating:用户对电影的评星)]}
self.userDict = {}
# 对某电影评分的用户
# 数据格式:{'MovieID:电影ID',[UserID:用户ID]}
# {'1',[1,2,3..],...}
self.ItemUser = {}
# 邻居的信息
self.neighbors = []
# 推荐列表
self.recommandList = []
self.cost = 0.0
# 基于用户的推荐
# 根据对电影的评分计算用户之间的相似度
def recommendByUser(self, userId):
self.formatRate()
# 推荐个数 等于 本身评分电影个数,用户计算准确率
self.n = len(self.userDict[userId])
self.getNearestNeighbor(userId)
self.getrecommandList(userId)
self.getPrecision(userId)
# 获取推荐列表
def getrecommandList(self, userId):
self.recommandList = []
# 建立推荐字典
recommandDict = {}
for neighbor in self.neighbors:
movies = self.userDict[neighbor[1]]
for movie in movies:
if(movie[0] in recommandDict):
recommandDict[movie[0]] += neighbor[0]
else:
recommandDict[movie[0]] = neighbor[0]
# 建立推荐列表
for key in recommandDict:
self.recommandList.append([recommandDict[key], key])
self.recommandList.sort(reverse=True)
self.recommandList = self.recommandList[:self.n]
# 将ratings转换为userDict和ItemUser
def formatRate(self):
self.userDict = {}
self.ItemUser = {}
for i in self.ratings:
# 评分最高为5 除以5 进行数据归一化
temp = (i[1], float(i[2]) / 5)
# 计算userDict {'1':[(1,5),(2,5)...],'2':[...]...}
if(i[0] in self.userDict):
self.userDict[i[0]].append(temp)
else:
self.userDict[i[0]] = [temp]
# 计算ItemUser {'1',[1,2,3..],...}
if(i[1] in self.ItemUser):
self.ItemUser[i[1]].append(i[0])
else:
self.ItemUser[i[1]] = [i[0]]
# 找到某用户的相邻用户
def getNearestNeighbor(self, userId):
neighbors = []
self.neighbors = []
# 获取userId评分的电影都有那些用户也评过分
for i in self.userDict[userId]:
for j in self.ItemUser[i[0]]:
if(j != userId and j not in neighbors):
neighbors.append(j)
# 计算这些用户与userId的相似度并排序
for i in neighbors:
dist = self.getCost(userId, i)
self.neighbors.append([dist, i])
# 排序默认是升序,reverse=True表示降序
self.neighbors.sort(reverse=True)
self.neighbors = self.neighbors[:self.k]
# 格式化userDict数据
def formatuserDict(self, userId, l):
user = {}
for i in self.userDict[userId]:
user[i[0]] = [i[1], 0]
for j in self.userDict[l]:
if(j[0] not in user):
user[j[0]] = [0, j[1]]
else:
user[j[0]][1] = j[1]
return user
# 计算余弦距离
def getCost(self, userId, l):
# 获取用户userId和l评分电影的并集
# {'电影ID':[userId的评分,l的评分]} 没有评分为0
user = self.formatuserDict(userId, l)
x = 0.0
y = 0.0
z = 0.0
for k, v in user.items():
x += float(v[0]) * float(v[0])
y += float(v[1]) * float(v[1])
z += float(v[0]) * float(v[1])
if(z == 0.0):
return 0
return z / sqrt(x * y)
# 推荐的准确率
def getPrecision(self, userId):
user = [i[0] for i in self.userDict[userId]]
recommand = [i[1] for i in self.recommandList]
count = 0.0
if(len(user) >= len(recommand)):
for i in recommand:
if(i in user):
count += 1.0
self.cost = count / len(recommand)
else:
for i in user:
if(i in recommand):
count += 1.0
self.cost = count / len(user)
# 显示推荐列表
def showTable(self):
neighbors_id = [i[1] for i in self.neighbors]
table = Texttable()
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(["t", "t", "t", "t"])
table.set_cols_align(["l", "l", "l", "l"])
rows = []
rows.append([u"movie ID", u"Name", u"release", u"from userID"])
for item in self.recommandList:
fromID = []
for i in self.movies:
if i[0] == item[1]:
movie = i
break
for i in self.ItemUser[item[1]]:
if i in neighbors_id:
fromID.append(i)
movie.append(fromID)
rows.append(movie)
table.add_rows(rows)
print(table.draw())
# 获取数据
def readFile(filename):
files = open(filename, "r", encoding="utf-8")
# 如果读取不成功试一下
# files = open(filename, "r", encoding="iso-8859-15")
data = []
for line in files.readlines():
item = line.strip().split("::")
data.append(item)
return data
# -------------------------开始-------------------------------
start = time.clock()
movies = readFile("/home/hadoop/Python/CF/movies.dat")
ratings = readFile("/home/hadoop/Python/CF/ratings.dat")
demo = CF(movies, ratings, k=20)
demo.recommendByUser("100")
print("推荐列表为:")
demo.showTable()
print("处理的数据为%d条" % (len(demo.ratings)))
print("准确率: %.2f %%" % (demo.cost * 100))
end = time.clock()
print("耗费时间: %f s" % (end - start))
主要任务
1、初始化数据
获取movies和ratings,转换成数据userDict表示某个用户的所有电影的评分集合,并对评分除以5进行归一化,转换成数据ItemUser表示某部电影参与评分的所有用户集合
2、计算所有用户与userId的相似度
找出所有观看电影与userId有交集的用户,对这些用户循环计算与userId的相似度,获取A用户与userId的并集。格式为:{'电影ID',[A用户的评分,userId的评分]},没有评分记为0,计算A用户与userId的余弦距离,越大越相似
3、根据相似度生成推荐电影列表
4、输出推荐列表和准确率
写在最后
记得前段时间社会上曾出现过关于推荐系统究竟是服务了我们生活,还是限制了我们的生活的大讨论。
2021年8月27日,国家互联网信息办公室发布了关于《互联网信息服务算法推荐管理规定(征求意见稿)》公开征求意见的通知。其中第十五条规定:
算法推荐服务提供者应当向用户提供不针对其个人特征的选项,或者向用户提供便捷的关闭算法推荐服务的选项。用户选择关闭算法推荐服务的,算法推荐服务提供者应当立即停止提供相关服务。 算法推荐服务提供者应当向用户提供选择、修改或者删除用于算法推荐服务的用户标签的功能。
更是引发了人们对推荐算法这一技术的关注。
就像哈佛大学教授桑斯坦(Cass R. Sunstein)在2006年出版的《信息乌托邦》(Infotopia)一书中提出的信息茧房(Information Cocoon)这一概念:
当个体只关注自我选择的或能够愉悦自身的内容,而减少对其他信息的接触,久而久之,便会像蚕一样逐渐禁锢于自我编织的“茧房”之中。

我们知道这是陷阱,这是牢笼,但仍会跨入其中。很难去讲这些对对错错,我们确实在享受它带来的便利,又被它深深套牢。
但有一点是无可厚非的:技术本身是没有对错而言的,关键在用这项技术的人或团体,有力量的武器应该在更严格的监督制度中。
好了,以上便是这次的所有内容了。
迟来的端午祝福送给大家:

(不说了,剪视频去了,趁着周六周日,把下周的要发的内容全剪完)
参考文献:
漫画来源 小林漫画
http://t.csdn.cn/xxe7C
http://t.csdn.cn/XEG1j
http://t.csdn.cn/J4VR7
https://juejin.cn/post/7020246064955392013
https://www.zhihu.com/question/270224768/answer/1542280267
https://zhan-bin.github.io/2018/10/14/5种常用的推荐系统算法/
https://baike.baidu.com/item/推荐算法/6560536

