深度学习-词嵌入
1、onehot 缺点:词之间没有关联,泛化性差
2、高维特征表示:每词由300维的特征表示,能够获取词之间的相似性关系。更好。
学习词嵌入,可以迁移学习,可以小样本 在训练集中找相似特征的进行归纳。
一般词嵌入,使用双向RNN
词嵌入,找网上模型然后少量训练标记进行迁移学习,可以使用比1-hot更低维的进行表示。
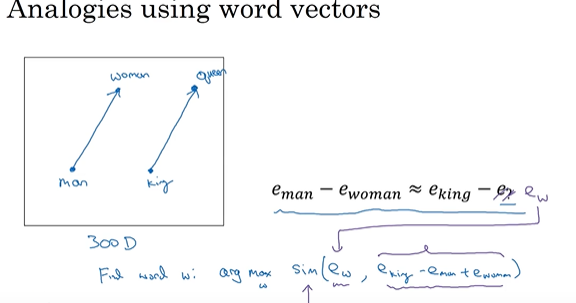
3、词嵌入的特性:依据相似性可以匹配词,cos衡量相似性(余弦距离),
t_SNE 高维映射到二维可视化
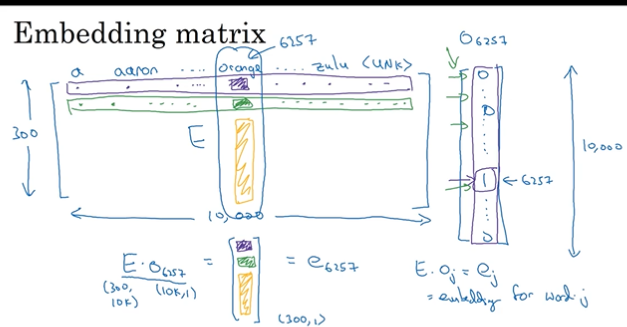
4、嵌入矩阵,实践中不会用1-hot矩阵乘法,因为维度太高,所以用其他矩阵来代替。
5、学习词嵌入
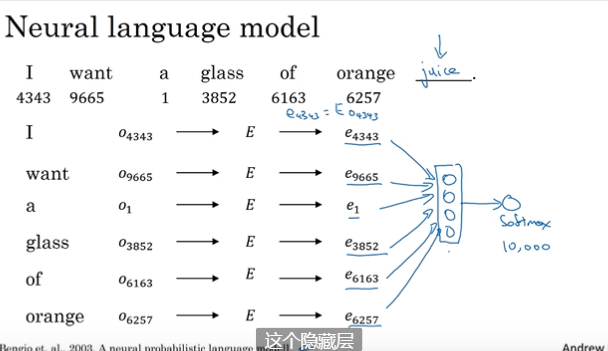
可以任意选择窗口大小进行预测。
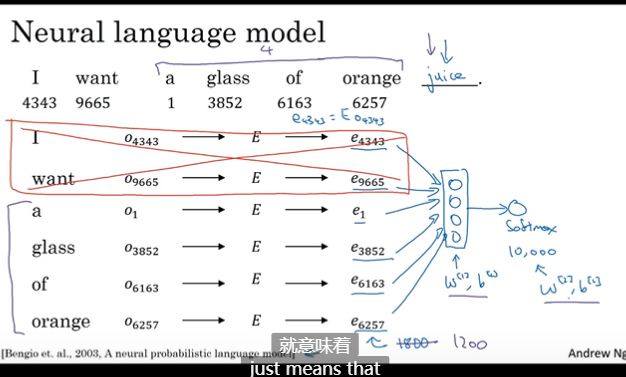
CBOW模型,周围词预测中间词。正负10距有很多单词,导致最终预测效果不是很好。(这块我其实没有好理解)
这里那复杂度说,CBOW,多次预测一个,而skip-gram 一次预测多个,效率更高,但是skip复杂度高。用负采样解决。
cbow 与 skip-gram的比较 - 卡门的文章 - 知乎 https://zhuanlan.zhihu.com/p/37477611

word2vec(词嵌入):计算高效,skip-gram中间词利用softmax 预测周围词(窗口大小为2)。
Fake Task,word2vec模型的最终目的并不是建模,而是通过训练数据来学习隐层的参数,而隐层的参数实际就是word vectors,就是说将中心词和上下文词成组输入,(input word, output word),然后最大化他们的概率,从而学习隐层参数,而隐层的参数就是最终要获取的词向量。
缺点:softmax耗费很大,因为有个求和操作。
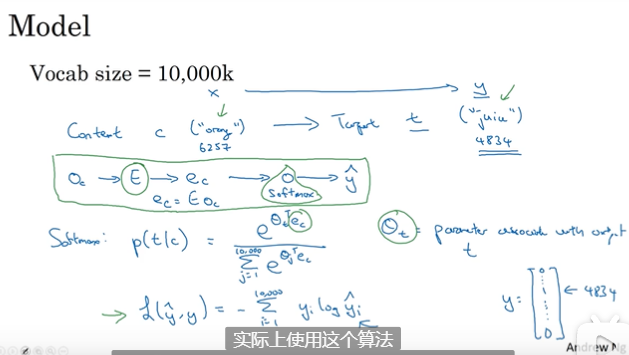
负采样:
作用:减少softmax的复杂度。
步骤:
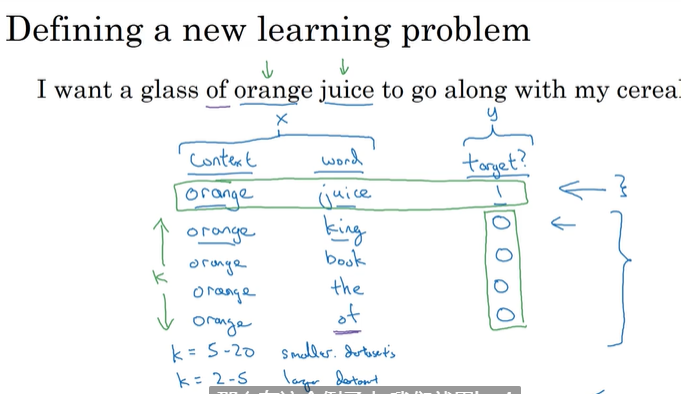
两词匹配,负采样就是在词典中随机一个词(有更好的做法),距离不正负10的距离内, 匹配标记为0;
K的选择,小数据5-20,大数据2-5;
利用logistic回归进行训练,每次训练集之训练k+1个样本,复杂度从大量的词典长度降低到k+1;
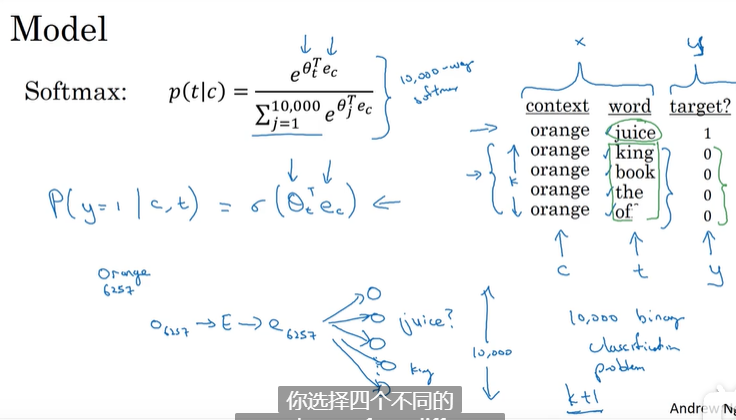
根据经验,英文3/4次方的分布对整体是比较好的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号