深度学习-序列模型2
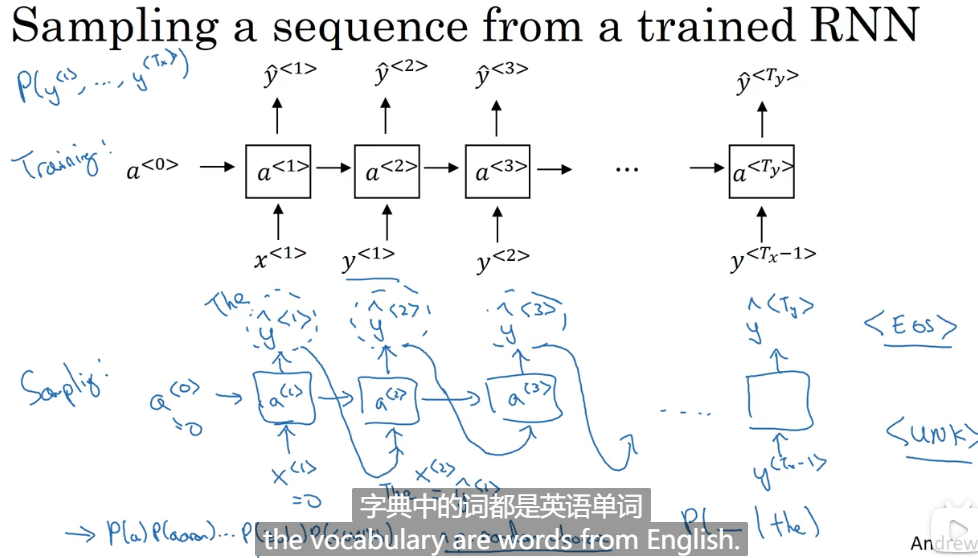
RNN新生成序列采样,这样做的动机:因为要看训练好的模型不知道在那些方面表现的好,具体来分析,便于进一步改进模型。数学角度说,就是检查训练好的数据分布是怎样的。
具体来说:
1、按照生成模型那样,先生成第一个单词,softmax分布进行随机抽选,第二个词在第一个词的基础上进行生成,第三个在前两个词的基础上进行生成。
2、直至EOS结束,或者句子到达一定长度停止。
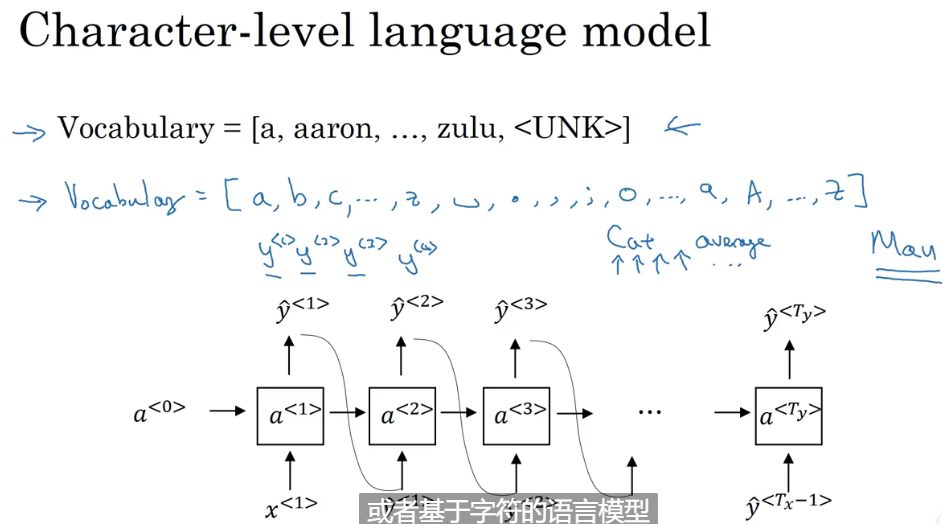
词典:基于字符的,基于词的, 现在一般情况都用的时基于词的词典。
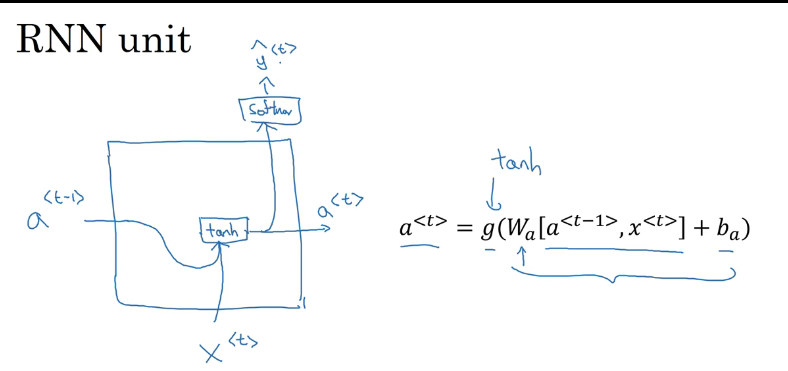
GRU : 如何缓解梯度消失的?
加入gamma u 无限小,那么基本上就是值传递不断传递到最后,这就是一定程度上缓解了梯度消失,
并且gamma u选用sigmoid函数,那么就比较容易产生接近0的数字。

补充了重置门,经过研究者的大量实验,能够使得网络更深,学习的更好。

LSTM:单独的控制遗忘门,能够更独立,不像时GRU那样直接依赖的1-u,所以表现的效果更好。
GRU 计算更快,适合更大规模的网络。
LSTM更加强大,更加灵活,因为门都是独立的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号