Transformer总结
一、提出背景
因为之前的LSTM、GRU等RNN的结构,虽然一定程度上解决了长程依赖的问题,但是还是没有根本解决超过一定范围的长程依赖问题。并且,RNN的顺序计算使得模型训练速度慢的问题。
提出Tranformer:1、并行计算,大大减少训练时间,摒弃了RNN、CNN的使用。 2、仅仅依赖多头自注意力的encoder-decoder模型,使得长程依赖问题有了进一步的解决。
为什么使用多头注意力:因为不同位置不同子空间的信息能够更加全面的表达,然后简单拼接即可。
二、主要结构
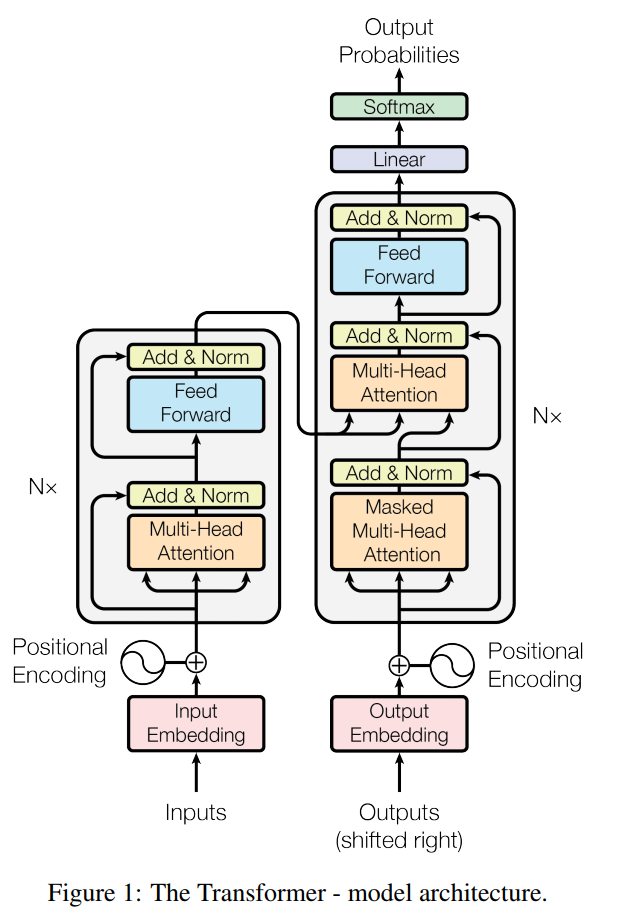
6层encoder+6层decoder的模型,顺便全都使用了残差网络来解决梯度弥散的问题。
encoder 由multi-head attention 和feed forward network 组成
decider由mast-multi-head 、multi-head、feed forward netword组成
encoder和decoder之间由Q、K、V联系
主要结构图如下;
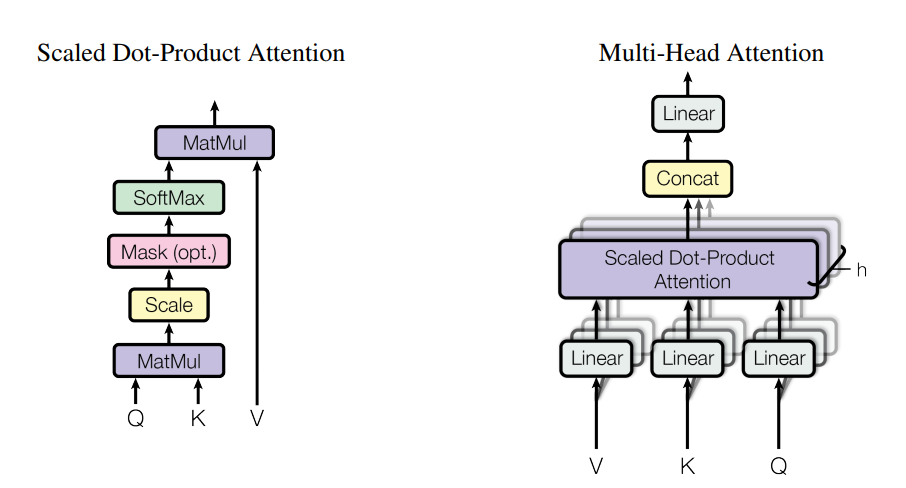
注意力计算公式如下: 其中Q、K、V 由每个单词嵌入向量得到,

补充对公式的理解:(参考链接: https://www.zhihu.com/question/325839123/answer/2127918771)
本身注意力机制公式的类型: softmax(XYT)Z
XYT的意义:就是X在Y上的投影,即表示X与Y的相关程度,然后对Z的加权平均,
衡量每个特征维度上 所有特征之间的相关性,可并行是最大的优势。
针对上图做重要解释:
1、encoder-decoder之间的联系,其中Q来自之前的decoder层,KV来自于最后一层encoder,这使得decoder的每个位置都能查询input中所有位置的KV
2、encoder内部通过6层不断迭代,每一个位置都能匹配之前encoder层
3、decoder同上,并且注意这里的自回归模型(t时刻仅依赖于之前时刻的输入,而与之后的输入无关),这里decoder专门做了相应的处理
全连接应用的公式:
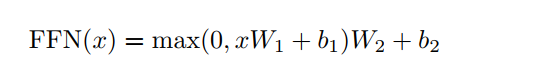
位置编码:(这里的原理还是不太懂)
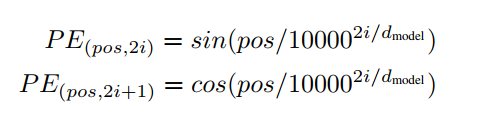
三、缺点
1、摒弃了RNN、CNN,丧失了捕捉局部特征的能力
2、对于位置信息,position embedding只是权宜之计,是有一定的缺陷。
参考资料:
https://zhuanlan.zhihu.com/p/48508221
https://blog.csdn.net/hellozhxy/article/details/107617431
Attention Is All You Need

 浙公网安备 33010602011771号
浙公网安备 33010602011771号