RabbitMQ
消息队列
消息队列简介
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可以包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
消息队列应用场景
消息队列是一种应用间的异步协作机制,那什么时候需要使用 MQ 呢?
以常见的订单系统为例,用户点击【下单】按钮之后的业务逻辑可能包括:扣减库存、生成相应单据、发红包、发短信通知。在业务发展初期这些逻辑可能放在一起同步执行,随着业务的发展订单量增长,需要提升系统服务的性能,这时可以将一些不需要立即生效的操作拆分出来异步执行,比如发放红包、发短信通知等。这种场景下就可以用 MQ ,在下单的主流程(比如扣减库存、生成相应单据)完成之后发送一条消息到 MQ 让主流程快速完结,而由另外的单独线程拉取MQ的消息(或者由 MQ 推送消息),当发现 MQ 中有发红包或发短信之类的消息时,执行相应的业务逻辑。
RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
RabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。
RabbitMQ安装
rabbitMQ工作模型
简单模式
####################生产者#################### import pika # 1 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 2 创建队列 channel.queue_declare(queue='hello') # 3 塞值 channel.basic_publish(exchange='', # exchange=''表示简单模式 routing_key='hello', body='Hello World!') print("[x] Sent "Hello World!") # 4 关闭连接 connection.close()
####################消费者#################### import pika # 1 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 2 创建队列 channel.queue_declare(queue='hello') # 3 定义一个回调函数 def callback(ch, method, properties, body): print(" [x] Received %r" % body) # 确定监听事件 channel.basic_consume(callback, queue='hello', no_ack=True) # 开始监听 channel.start_consuming()
应答参数
如果消费者遇到情况,在消费者恢复正常后,由于异常情况下已向RabbitMQ拿到数据,所以上次数据已丢失。
为了防止消费者应用程序异常而导致数据丢失,可设置:
- basic_comsume中的no_ack=False
- 回调函数中新增ch.basic_ack(delivery_tag = method.delivery_tag)
####################消费者#################### import pika # 1 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 2 创建队列 channel.queue_declare(queue='hello') # 3 定义一个回调函数 def callback(ch, method, properties, body): print(" [x] Received %r" % body) # 应答 ch.basic_ack(delivery_tag = method.delivery_tag) # 确定监听事件 channel.basic_consume(callback, queue='hello', no_ack=False) # 开始监听 channel.start_consuming()
持久化参数
如果生产者已传入数据,而生产者还未取到数据,此时RabbitMQ服务器宕机。由于RabbitMQ数据放置于内存中,则此时也会导致数据丢失。
为防止RabbitMQ服务器异常而导致数据丢失,可在生产者处设置持久化:
- queue_declare设置durable=True
- basic_publish设置properties=pika.BasicProperties(delivery_mode=2,)
此时RabbitMQ将队列里的数据保存于磁盘中。虽然此方式提高了数据安全性,但牺牲了效率。
####################生产者#################### import pika # 1 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 2 创建队列 channel.queue_declare(queue='hello', durable=True) # 3 塞值 channel.basic_publish(exchange='', # exchange=''表示简单模式 routing_key='hello', body='Hello World!', properties=pika.BasicProperties( delivery_mode=2, )) print("[x] Sent "Hello World!") # 4 关闭连接 connection.close()
####################消费者#################### import pika # 1 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 2 创建队列 channel.queue_declare(queue='hello',durable=True) # 3 定义一个回调函数 def callback(ch, method, properties, body): print(" [x] Received %r" % body) # 确定监听事件 channel.basic_consume(callback, queue='hello', no_ack=True) # 开始监听 channel.start_consuming()
分配模式
默认平均分配,即如果有两个消费者,生产者生产了三个任务,则第一个任务分配给第一个消费者,第二个任务分配给第二个消费者,第三个任务分配给第一个消费者,即使第二个消费者任务提前结束,也不会分配给它。
因此,平均分配导致资源不能充分利用而效率低下,可设置为谁先处理完分给谁:
- channel.basic_qos(prefetch_count=1)
####################消费者#################### import pika # 1 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 2 创建队列 channel.queue_declare(queue='hello') # 3 定义一个回调函数 def callback(ch, method, properties, body): print(" [x] Received %r" % body)
# 确定监听事件 channel.basic_consume(callback, queue='hello', no_ack=True) # 分配方式 channel.basic_qos(prefetch_count=1) # 开始监听 channel.start_consuming()
exchange模式
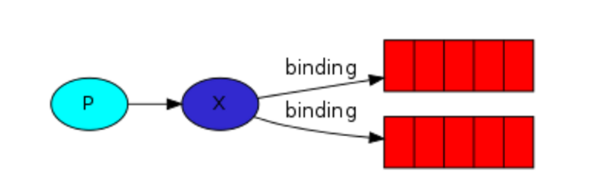
发布订阅模式
exchange_type = "fanout"
此时队列只由消费者创建,交换机由生产者和消费者创建。
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而简单的消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
####################生产者#################### import pika # 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明一个交换机 channel.exchange_declare(exchange='logs',exchange_type="fanout") # 塞值 message ="info: Hello World!" channel.basic_publish(exchange='logs', routing_key='', body=message) print(" [x] Sent %r" % message) # 关闭连接 connection.close()
####################消费者####################
import pika # 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明交换机 channel.exchange_declare(exchange='logs',exchange_type='fanout') # 声明队列 result = channel.queue_declare(exclusive=True) # 创建随机队列对象 queue_name = result.method.queue # 为队列绑定交换机 channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') # 回调函数 def callback(ch, method, properties, body): print(" [x] %r" % body) # 确定监听事件 channel.basic_consume(callback, queue=queue_name, no_ack=True) # 开始监听 channel.start_consuming()
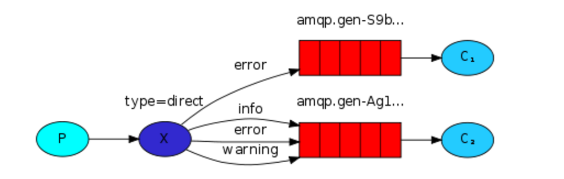
关键字模式
exchange_type = "direct"
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据关键字判定应该将数据发送至指定队列。关键字通过routing_key设置。


#####################生产者##################### import pika # 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明一个交换机 channel.exchange_declare(exchange='direct_logs',exchange_type="direct") # 塞值 message ="warning: Hello World!" channel.basic_publish(exchange='direct_logs', routing_key='warning', # 关键字'warning' body=message) print(" [x] Sent %r" % message) # 关闭连接 connection.close()
#####################消费者##################### import pika # 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明交换机 channel.exchange_declare(exchange='direct_logs', exchange_type='direct') # 声明队列 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 为队列绑定交换机 channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key="error") print(' [*] Waiting for logs. To exit press CTRL+C') # 回调函数 def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) # 确定监听事件 channel.basic_consume(callback, queue=queue_name, no_ack=True) # 开始监听 channel.start_consuming()
#####################消费者##################### import pika # 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明交换机 channel.exchange_declare(exchange='direct_logs', exchange_type='direct') # 声明队列 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 为队列绑定交换机 channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key="warning") print(' [*] Waiting for logs. To exit press CTRL+C') # 回调函数 def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) # 确定监听事件 channel.basic_consume(callback, queue=queue_name, no_ack=True) # 开始监听 channel.start_consuming()
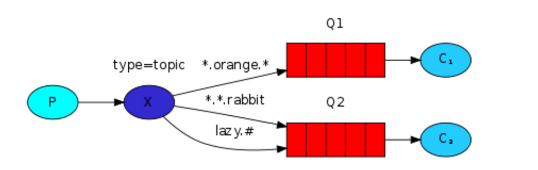
模糊匹配模式
exchange_type = 'topic'
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配0个或多个单词
- * 表示只能匹配一个单词(单词个数以'.'为分隔符)
发送路由值 队列 结果 baidu.python.class baidu.* 不匹配 baidu.python.class baidu.# 匹配
####################生产者#################### import pika # 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明一个交换机 channel.exchange_declare(exchange='topic_logs',exchange_type="topic") # 塞值 message ="Hello World!" channel.basic_publish(exchange='topic_logs', routing_key='banana.apple.xigua.juzi', body=message) print(" [x] Sent %r" % message) # 关闭连接 connection.close()
####################消费者#################### import pika # 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明交换机 channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 声明队列 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 为队列绑定交换机 channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key="*.apple.#") print(' [*] Waiting for logs. To exit press CTRL+C') # 回调函数 def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) # 确定监听事件 channel.basic_consume(callback, queue=queue_name, no_ack=True) # 开始监听 channel.start_consuming()
####################消费者#################### import pika # 连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明交换机 channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 声明队列 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 为队列绑定交换机 channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key="*.apple.*") print(' [*] Waiting for logs. To exit press CTRL+C') # 回调函数 def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) # 确定监听事件 channel.basic_consume(callback, queue=queue_name, no_ack=True) # 开始监听 channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号