oracle_基本SQL语言
一:DDL数据定义语言
1:create(创建)
创建表
1 CREATE TABLE <table_name>( 2 column1 DATATYPE [NOT NULL] [PRIMARY KEY], 3 column2 DATATYPE [NOT NULL], 4 ... 5 [constraint <约束名> 约束类型 (要约束的字段) 6 ... ] ) 7 /*说明: 8 DATATYPE --是Oracle的数据类型,可以查看附录。 9 NUT NULL --可不可以允许资料有空的(尚未有资料填入)。 10 PRIMARY KEY --是本表的主键。 11 constraint --是对表里的字段添加约束.(约束类型有 12 Check,Unique,Primary key,not null,Foreign key)。 13 */ 14 ---示例: 15 create table stu( 16 s_id number(8) PRIMARY KEY, 17 s_name varchar2(20) not null, 18 s_sex varchar2(8), 19 clsid number(8), 20 constraint u_1 unique(s_name), 21 constraint c_1 check (s_sex in ('MALE','FEMALE')) 22 ); 23
复制表
1 CREATE TABLE <table_name> as <SELECT 语句> 2 3 ---(需注意的是复制表不能复制表的约束); 4 5 --示例: 6 create table test as select * from emp; 7 8 ---如果只复制表的结构不复制表的数据则: 9 create table test as select * from emp where 1=2;
创建索引
1 --创建索引 2 3 -------------------------------------------------------------------------------- 4 CREATE [UNIQUE] INDEX <index_name> ON <table_name>(字段 [ASC|DESC]); 5 /* 6 UNIQUE --确保所有的索引列中的值都是可以区分的。 7 [ASC|DESC] --在列上按指定排序创建索引。 8 9 (创建索引的准则: 10 1.如果表里有几百行记录则可以对其创建索引(表里的记录行数越多索引的效果就越明显)。 11 2.不要试图对表创建两个或三个以上的索引。 12 3.为频繁使用的行创建索引。 13 ) 14 */ 15 16 --示例 17 create index i_1 on emp(empno asc);
创建同义词
1 --创建同义词 2 3 -------------------------------------------------------------------------------- 4 5 CREATE SYNONYM <synonym_name> for <tablename/viewname> 6 7 --同义词即是给表或视图取一个别名。 8 9 --示例: 10 create synonym mm for emp; 11
2:alter(修改)
1 --修改表 2 3 -------------------------------------------------------------------------------- 4 5 --1.向表中添加新字段 6 ALTER TABLE <table_name> ADD (字段1 类型 [NOT NULL],字段2 类型 [NOT NULL].... ); 8 9 --2.修改表中字段 10 ALTER TABLE <table_name> modify(字段1 类型,字段2 类型.... ); 11 12 --3 .删除表中字段 13 ALTER TABLE <table_name> drop(字段1,字段2 .... ); 14 15 --4 .修改表的名称 16 RENAME <table_name> to <new table_name>; 17 18 --5 .对已经存在的表添加约束 19 ALTER TABLE <table_name> ADD CONSTRAINT <constraint_name> 约束类型 (针对的字段名); 20 ---示例: 21 Alter table emp add constraint S_F Foreign key (deptno) references dept(deptno); 22 23 --6 .对表里的约束禁用; 24 ALTER TABLE <table_name> DISABLE CONSTRAINT <constraint_name>; 25 26 ---7 .对表里的约束重新启用; 27 ALTER TABLE <table_name> ENABLE CONSTRAINT <constraint_name>; 28 29 ---8 .删除表中约束 30 ALTER TABLE <table_name> DROP CONSTRAINT <constraint_name>; 31 ---示例: 32 ALTER TABLE emp drop CONSTRAINT <Primary key>; 33 34 35
2:drop(删除)
删除表
1 --删除表 2 3 -------------------------------------------------------------------------------- 4 DROP TABLE <table_name>; 5 6 ---示例 7 drop table emp; 8
删除索引
1 --删除索引 2 3 -------------------------------------------------------------------------------- 4 DROP INDEX <index_name>; 5 6 --示例 7 drop index i_1; 8
删除同义词
1 --删除同义词 2 3 -------------------------------------------------------------------------------- 4 DROP SYNONYM <synonym_name>; 5 6 --示例 7 drop synonym mm; 8
二:DML数据操纵语言
插入记录 insert into
1 --插入记录 2 3 -------------------------------------------------------------------------------- 4 INSERT INTO table_name (column1,column2,...) 5 values ( value1,value2, ...); 6 7 --示例 8 insert into emp (empno,ename) values(9500,'AA'); 9 10 11 --把 一个表中的数据插入另一个表中 12 13 INSERT INTO <table_name> <SELECT 语句> 14 --示例 15 create table a as select * from emp where 1=2; 16 insert into a select * from emp where sal>2000; 17 18 19
查询记录 select
1 --查询记录 2 3 -------------------------------------------------------------------------------- 4 5 --一般查询 6 SELECT [DISTINCT] <column1 [as new name] ,columns2,...> 7 FROM <table1> 8 [WHERE <条件>] 9 [GROUP BY <column_list>] 10 [HAVING <条件>] 11 [ORDER BY <column_list> [ASC|DESC]] 12 13 /* 14 DISTINCT --表示隐藏重复的行 15 WHERE --按照一定的条件查找记录 16 GROUP BY --分组查找(需要汇总时使用) 17 HAVING --分组的条件 18 ORDER BY --对查询结果排序 19 20 21 要显示全部的列可以用*表示 */ 22 --示例: 23 select * from emp; 24 25 WHERE 语句的运算符 26 where <条件1>AND<条件2> --两个条件都满足 27 --示例: 28 select * from emp where deptno=10 and sal>1000; 29 30 where <条件1>OR<条件2> --两个条件中有一个满足即可 31 --示例: 32 select * from emp where deptno=10 OR sal>2000; 33 34 where NOT <条件> --不满足条件的 35 --示例: 36 select * from emp where not deptno=10; 37 38 where IN(条件列表) --所有满足在条件列表中的记录 39 --示例: 40 select * from emp where empno in(7788,7369,7499); 41 42 where BETWEEN .. AND .. --按范围查找 43 --示例: 44 select * from emp where sal between 1000 and 3000; 45 46 where 字段 LIKE --主要用与字符类型的字段 47 --示例1: 48 select * from emp where ename like '_C%'; --查询姓名中第二个字母是'C'的人 49 --'-' 表示任意字符; 50 --'%' 表示多字符的序列; 51 52 where 字段 IS [NOT] NULL --查找该字段是[不是]空的记录 53 54 --汇总数据是用的函数 55 --SUM --求和 56 --示例: 57 select deptno,sum(sal) as sumsal from emp GROUP BY deptno; 58 59 /* 60 AVG --求平均值 61 MAX --求最大值 62 MIN --求最小值 63 COUNT --求个数 64 */ 65 66 --子查询 67 SELECT <字段列表> from <table_name> where 字段 运算符(<SELECT 语句>); 68 69 --示例: 70 select * from emp where sal=(select max(sal) from emp); 71 72 --运算符 73 Any 74 --示例: 75 select * from emp where sal>ANY(select sal from emp where deptno=30) and deptno<>30; 76 --找出比deptno=30的员工最低工资高的其他部门的员工 77 78 --ALL 79 select * from emp where sal>ALL(select sal from emp where deptno=30) and deptno<>30; 80 --找出比deptno=30的员工最高工资高的其他部门的员工 81 82 83 --连接查询 84 SELECT <字段列表> from <table1,table2> WHERE table1.字段[(+)]=table2.字段[(+)] 85 86 --示例 87 select empno,ename,dname from emp,dept where emp.deptno=dept.deptno; 88 89 90 --查询指定行数的数据 91 SELECT <字段列表> from <table_name> WHERE ROWNUM<行数; 92 --示例: 93 select * from emp where rownum<=10;--查询前10行记录 94 --注意ROWNUM只能为1 因此不能写 select * from emp where rownum between 20 and 30; 95 96 --要查第几行的数据可以使用以下方法: 97 select * from emp where rownum<=3 and empno not in (select empno from emp where rownum<=3); 98 --结果可以返回整个数据的3-6行; 99 --不过这种方法的性能不高;如果有别的好方法请告诉我。 100 101 102 103 104 105
更新数据 update
1 --更新数据 2 3 -------------------------------------------------------------------------------- 4 UPDATE table_name set column1=new value,column2=new value,... 5 WHERE <条件> 6 7 --示例 8 update emp set sal=1000,empno=8888 where ename='SCOTT' 9
删除数据 delete
1 --更新数据 2 3 -------------------------------------------------------------------------------- 4 DELETE FROM <table_name> 5 WHERE <条件> 6 7 --示例 8 delete from emp where empno='7788' 9
三:DCL数据控制语言
数据控制语言
1 --数据控制语言 2 3 -------------------------------------------------------------------------------- 4 --1.授权 5 GRANT <权限列表> to <user_name>; 6 7 --2.收回权限 8 REVOKE <权限列表> from <user_name> 9 10 /* 11 Oracle 的权限列表 12 connect 连接 13 resource 资源 14 unlimited tablespace 无限表空间 15 dba 管理员 16 session 会话 17 */
四:TCL事务控制语言
1 --数据控制语言 2 3 -------------------------------------------------------------------------------- 4 --1.提交; 5 COMMIT; 6 7 --2.回滚; 8 ROLLBACK [TO savepoint] 9 10 --3.保存位置。 11 SAVEPOINT <savepoint> 12 13
五:Oracle 其他对象
视图:
1 --创建视图 2 -------------------------------------------------------------------------------- 3 CREATE [OR REPLACE] VIEW <view_name> 4 AS 5 <SELECT 语句>; 6 7 OR REPLACE --表示替换以有的视图 8 9 --删除视图 10 -------------------------------------------------------------------------------- 11 12 DROP VIEW <view_name> 13 14
序列:
1 --创建序列 2 -------------------------------------------------------------------------------- 3 4 CREATE SEQUENCE <sequencen_name> 5 INCREMENT BY n 6 START WITH n 7 [MAXVALUE n][MINVALUE n] 8 [CYCLE|NOCYCLE] 9 [CACHE n|NOCACHE]; 10 11 /* 12 INCREMENT BY n --表示序列每次增长的幅度;默认值为1. 13 START WITH n --表示序列开始时的序列号。默认值为1. 14 MAXVALUE n --表示序列可以生成的最大值(升序). 15 MINVALUE n --表示序列可以生成的最小值(降序). 16 CYCLE --表示序列到达最大值后,在重新开始生成序列.默认值为 NOCYCLE。 17 CACHE --允许更快的生成序列. 18 */ 19 20 --示例: 21 create sequence se_1 22 increment by 1 23 start with 100 24 maxvalue 999999 25 cycle; 26 27 28 --修改序列 29 30 31 -------------------------------------------------------------------------------- 32 33 ALTER SEQUENCE <sequencen_name> 34 INCREMENT BY n 35 START WITH n 36 [MAXVALUE n][MINVALUE n] 37 [CYCLE|NOCYCLE] 38 [CACHE n|NOCACHE]; 39 40 41 42 --删除序列 43 44 45 -------------------------------------------------------------------------------- 46 47 DROP SEQUENCE <sequence_name> 48 49 50 51 52 --使用序列 53 54 55 -------------------------------------------------------------------------------- 56 57 1.CURRVAL 58 返回序列的当前值. 59 注意在刚建立序列后,序列的CURRVAL值为NULL,所以不能直接使用。 60 可以先初始化序列: 61 方法:select <sequence_name>.nextval from dual; 62 示例:select se_1.nextval from dual; 63 之后就可以使用CURRVAL属性了 64 65 2.NEXTVAL 66 返回序列下一个值; 67 示例: 68 begin 69 for i in 1..5 70 loop 71 insert into emp(empno) values(se_1.nextval); 72 end loop; 73 end; 74 75 76 --查看序列的当前值 77 select <sequence_name>.currval from dual; 78 79 --示例:select se_1.currval from dual; 80 81 82
用户
1 --创建用户 2 -------------------------------------------------------------------------------- 3 4 CREATE USER <user_name> [profile "DEFAULT"] 5 identified by "<password>" [default tablespace "USERS"] 6 7 8 --删除用户 9 10 11 -------------------------------------------------------------------------------- 12 13 DROP USER <user_name> CASCADE 14 15
角色
1 --创建角色 2 -------------------------------------------------------------------------------- 3 4 CREATE ROLE <role_name> 5 identified by "<password>" 6 7 8 --删除角色 9 -------------------------------------------------------------------------------- 10 11 DROP ROLE <role_name> 12 13
六:PL/SQL
PL/SQL 结构
1 ---PL/SQL 结构 2 3 -------------------------------------------------------------------------------- 4 DECLARE --声明部分 5 声明语句 6 BEGIN --执行部分 7 执行语句 8 9 EXCEPTION --异常处理部分 10 执行语句 11 12 END; 13 14 变量声明 15 <变量名> 类型[:=初始值]; 16 特殊类型 字段%type 17 示例: name emp.ename%type --表示name的类型和emp.ename的类型相同 18 表 %rowtype 19 示例: test emp%rowtype --表示test的类型为emp表的行类型;也有 .empno; .ename; .sal ;等属性 20 21 常量声明 22 <变量名> CONSTANT 类型:=初始值; 23 示例: pi constant number(5,3):=3.14; 24 25 全局变量声明 26 VARIABLE <变量名> 类型; 27 示例: VARIABLE num number; 28 29 使用全局变量 30 :<变量名> 31 示例: 32 :num:=100; 33 i=:num; 34 35 查看全局变量的值 36 print <变量名> 37 示例: print num; 38 39 赋值运算符: := 40 示例: num := 100; 41 42 使用SELECT <列名> INTO <变量名> FROM <表名> WHERE <条件> 43 注意select into 语句的返回结果只能为一行; 44 示例:test emp%rowtype; 45 select * into test from emp where empno=7788; 46 47 用户交互输入 48 <变量>:='&变量' 49 示例: 50 num:=# 51 52 注意oracle的用户交互输入是先接受用户输入的所有值后在执行语句; 53 所以不能使用循环进行用户交互输入; 54 55 56 条件控制语句 57 IF <条件1> THEN 58 语句 59 [ELSIF <条件2> THEN 60 语句 61 . 62 . 63 . 64 ELSIF <条件n> THEN 65 语句] 66 [ELSE 67 语句] 68 END IF; 69 70 71 72 循环控制语句 73 1.LOOP 74 LOOP 75 语句; 76 EXIT WHEN <条件> 77 END LOOP; 78 79 2.WHILE LOOP 80 WHILE <条件> 81 LOOP 82 语句; 83 END LOOP; 84 85 3.FOR 86 FOR <循环变量> IN 下限..上限 87 LOOP 88 语句; 89 END LOOP; 90 91 92 NULL 语句 93 null; 94 表示没有操作; 95 96 97 注释使用 98 单行注释: -- 99 多行注释:/* ....... 100 ...............*/ 101 102 103 异常处理 104 105 EXCEPTION 106 WHEN <异常类型> THEN 107 语句; 108 WHEN OTHERS THEN 109 语句; 110 END; 111 关于异常类型请查看附录. 112 113 114 115 116
游标
1 显示游标 2 -------------------------------------------------------------------------------- 3 4 定义:CURSOR <游标名> IS <SELECT 语句> [FOR UPDATE | FOR UPDATE OF 字段]; 5 6 [FOR UPDATE | FOR UPDATE OF 字段] --给游标加锁,既是在程序中有"UPDATE","INSERT","DELETE"语句对数据库操作时。 7 游标自动给指定的表或者字段加锁,防止同时有别的程序对指定的表或字段进行"UPDATE","INSERT","DELETE"操作. 8 在使用"DELETE","UPDATE"后还可以在程序中使用CURRENT OF <游标名> 子句引用当前行. 9 10 操作:OPEN <游标名> --打开游标 11 FETCH <游标名> INTO 变量1,变量2,变量3,....变量n,; 12 或者 13 FETCH <游标名> INTO 行对象; --取出游标当前位置的值 14 CLOSE <游标名> --关闭游标 15 属性: %NOTFOUND --如果FETCH语句失败,则该属性为"TRUE",否则为"FALSE"; 16 %FOUND --如果FETCH语句成果,则该属性为"TRUE",否则为"FALSE"; 17 %ROWCOUNT --返回游标当前行的行数; 18 %ISOPEN --如果游标是开的则返回"TRUE",否则为"FALSE"; 19 20 使用: 21 LOOP循环 22 示例: 23 DECLARE 24 cursor c_1 is select * from emp; --定义游标 25 r c_1%rowtype; --定义一个行对象,用于获得游标的值 26 BEGIN 27 if c_1%isopen then 28 CLOSE c_1; 29 end if; 30 OPEN c_1; --判断游标是否打开.如果开了将其关闭,然后在打开 31 dbms_output.put_line('行号 姓名 薪水'); 32 LOOP 33 FETCH c_1 INTO r; --取值 34 EXIT WHEN c_1%NOTFOUND; --如果游标没有取到值,退出循环. 35 dbms_output.put_line(c_1%rowcount||''||r.ename||''||r.sal); --输出结果,需要 set serverout on 才能显示. 36 END LOOP; 37 END; 38 39 40 FOR循环 41 示例: 42 DECLARE 43 cursor c_1 is select ename,sal from emp; --定义游标 44 BEGIN 45 dbms_output.put_line('行号 姓名 薪水'); 46 FOR i IN c_1 --for循环中的循环变量i为c_1%rowtype类型; 47 LOOP 48 dbms_output.put_line(c_1%rowcount||''||i.ename||''||i.sal); --输出结果,需要 set serverout on 才能显示. 49 END LOOP; 50 END; 51 52 for循环使用游标是在循环开始前自动打开游标,并且自动取值到循环结束后,自动关闭游标. 53 54 游标加锁示例: 55 DECLARE 56 cursor c_1 is select ename,sal from emp for update of sal; --定义游标对emp表的sal字段加锁. 57 BEGIN 58 dbms_output.put_line('行号 姓名 薪水'); 59 FOR i IN c_1 --for循环中的循环变量i为c_1%rowtype类型; 60 LOOP 61 UPDATE EMP set sal=sal+100 WHERE CURRENT OF c_1; --表示对当前行的sal进行跟新. 62 END LOOP; 63 FOR i IN c_1 64 LOOP 65 dbms_output.put_line(c_1%rowcount||''||i.ename||''||i.sal); --输出结果,需要 set serverout on 才能显示. 66 END LOOP; 67 END; 68 69 70 71 代参数的游标 72 定义:CURSOR <游标名>(参数列表) IS <SELECT 语句> [FOR UPDATE | FOR UPDATE OF 字段]; 73 示例: 74 DECLARE 75 cursor c_1(name emp.ename%type) is select ename,sal from emp where ename=name; --定义游标 76 BEGIN 77 dbms_output.put_line('行号 姓名 薪水'); 78 FOR i IN c_1('&name') --for循环中的循环变量i为c_1%rowtype类型; 79 LOOP 80 dbms_output.put_line(c_1%rowcount||''||i.ename||''||i.sal); --输出结果,需要 set serverout on 才能显示. 81 END LOOP; 82 END; 83 84 85 隐试游标 86 -------------------------------------------------------------------------------- 87 隐试游标游标是系统自动生成的。每执行一个DML语句就会产生一个隐试游标,起名字为SQL; 88 89 隐试游标不能进行"OPEN" ,"CLOSE","FETCH"这些操作; 90 91 属性: 92 %NOTFOUND --如果DML语句没有影响到任何一行时,则该属性为"TRUE",否则为"FALSE"; 93 %FOUND --如果DML语句影响到一行或一行以上时,则该属性为"TRUE",否则为"FALSE"; 94 %ROWCOUNT --返回游标当最后一行的行数; 95 96 个人认为隐试游标的作用是判断一个DML语句; 97 示例: 98 BEGIN 99 DELETE FROM EMP WHERE empno=&a; 100 IF SQL%NOTFOUND THEN 101 dbms_output.put_line('empno不存在'); 102 END IF; 103 IF SQL%ROWCOUNT>0 THEN 104 dbms_output.put_line('删除成功'); 105 END IF; 106 END;
PL/SQL表
1 PL/SQL表 2 -------------------------------------------------------------------------------- 3 pl/sql表只有两列,其中第一列为序号列为INTEGER类型,第二列为用户自定义列. 4 5 定义:TYPE <类型名> IS TABLE OF <列的类型> [NOT NULL] INDEX BY BINARY_INTEGER; 6 <列的类型>可以为Oracle的数据类行以及用户自定义类型; 7 8 属性方法: 9 .count --返回pl/sql表的总行数 10 .delect --删除pl/sql表的所有内容 11 .delect(行数) --删除pl/sql表的指定的行 12 .delct(开始行,结束行) --删除pl/sql表的多行 13 .first --返回表的第一个INDEX; 14 .next(行数) --这个行数的下一条的INDEX; 15 .last --返回表的最后一个INDEX; 16 17 使用 18 示例: 19 DECLARE 20 TYPE mytable IS TABLE OF VARCHAR2(20) index by binary_integer; --定义一个名为mytable的PL/sql表类型; 21 cursor c_1 is select ename from emp; 22 n number:=1; 23 tab_1 mytable; --为mytable类型实例化一个tab_1对象; 24 BEGIN 25 for i in c_1 26 loop 27 tab_1(n):=i.ename; --将得到的值输入pl/sql表 28 n:=n+1; 29 end loop; 30 n:=1; 31 tab_1.delete(&要删除的行数); --删除pl/sql表的指定行 32 for i in tab_1.first..tab_1.count 33 loop 34 dbms_output.put_line(n||''||tab_1(n)); --打印pl/sql表的内容 35 n:=tab_1.next(n); 36 end loop; 37 EXCEPTION 38 WHEN NO_DATA_FOUND THEN --由于删除了一行,会发生异常,下面语句可以接着删除的行后显示 39 for i in n..tab_1.count+1 40 loop 41 dbms_output.put_line(n||''||tab_1(n)); 42 n:=tab_1.next(n); 43 end loop; 44 END;
PL/SQL记录
1 PL/SQL记录 2 -------------------------------------------------------------------------------- 3 pl/sql表只有一行,但是有多列。 4 5 定义:TYPE <类型名> IS RECORD <列名1 类型1,列名2 类型2,...列名n 类型n,> [NOT NULL] 6 <列的类型>可以为Oracle的数据类行以及用户自定义类型;可以是记录类型的嵌套 7 8 使用 9 示例: 10 DECLARE 11 TYPE myrecord IS RECORD(id emp.empno%type, 12 name emp.ename%type,sal emp.sal%type); --定义一个名为myrecoed的PL/sql记录类型; 13 rec_1 myrecord; --为myrecord类型实例化一个rec_1对象; 14 BEGIN 15 select empno,ename,sal into rec_1.id,rec_1.name,rec_1.sal 16 from emp where empno=7788; --将得到的值输入pl/sql记录 17 dbms_output.put_line(rec_1.id||''||rec_1.name||''||rec_1.sal); --打印pl/sql记录的内容 18 END; 19 20 21 22 结合使用PL/SQL表和PL/SQL记录 23 示例: 24 DECLARE 25 CURSOR c_1 is select empno,ename,job,sal from emp; 26 TYPE myrecord IS RECORD(empno emp.empno%type,ename emp.ename%type, 27 job emp.job%type,sal emp.sal%type); --定义一个名为myrecoed的PL/sql记录类型; 28 TYPE mytable IS TABLE OF myrecord index by binary_integer; 29 --定义一个名为mytable的PL/sql表类型;字段类型为PL/sql记录类型; 30 31 n number:=1; 32 tab_1 mytable; --为mytable类型实例化一个tab_1对象; 33 BEGIN 34 --赋值 35 for i in c_1 36 loop 37 tab_1(n).empno:=i.empno; 38 tab_1(n).ename:=i.ename; 39 tab_1(n).job:=i.job; 40 tab_1(n).sal:=i.sal; 41 n:=n+1; 42 end loop; 43 n:=1; 44 --输出 45 for i in n..tab_1.count 46 loop 47 dbms_output.put_line(i||''||tab_1(i).empno 48 ||''||tab_1(i).ename||''||tab_1(i).job||''||tab_1(i).sal); 49 end loop; 50 END; 51
REF游标
1 强型REF游标 2 -------------------------------------------------------------------------------- 3 4 定义:TYPE <游标名> IS REF CURSOR RETURN<返回类型>; 5 6 7 操作:OPEN <游标名> For <select 语句> --打开游标 8 FETCH <游标名> INTO 变量1,变量2,变量3,....变量n,; 9 或者 10 FETCH <游标名> INTO 行对象; --取出游标当前位置的值 11 CLOSE <游标名> --关闭游标 12 属性: %NOTFOUND --如果FETCH语句失败,则该属性为"TRUE",否则为"FALSE"; 13 %FOUND --如果FETCH语句成果,则该属性为"TRUE",否则为"FALSE"; 14 %ROWCOUNT --返回游标当前行的行数; 15 %ISOPEN --如果游标是开的则返回"TRUE",否则为"FALSE"; 16 17 使用: 18 示例: 19 DECLARE 20 type c_type is ref cursor return emp%rowtype; --定义游标 21 c_1 c_type; --实例化这个游标类型 22 r emp%rowtype; 23 BEGIN 24 dbms_output.put_line('行号 姓名 薪水'); 25 open c_1 for select * from emp; 26 loop 27 fetch c_1 into r; 28 exit when c_1%notfound; 29 dbms_output.put_line(c_1%rowcount||''||r.ename||''||r.sal); --输出结果,需要 set serverout on 才能显示. 30 END LOOP; 31 close c_1; 32 END; 33 34 35 弱型REF游标 36 -------------------------------------------------------------------------------- 37 定义:TYPE <游标名> IS REF CURSOR; 38 39 40 操作:OPEN <游标名> For <select 语句> --打开游标 41 FETCH <游标名> INTO 变量1,变量2,变量3,....变量n,; 42 或者 43 FETCH <游标名> INTO 行对象; --取出游标当前位置的值 44 CLOSE <游标名> --关闭游标 45 属性: %NOTFOUND --如果FETCH语句失败,则该属性为"TRUE",否则为"FALSE"; 46 %FOUND --如果FETCH语句成果,则该属性为"TRUE",否则为"FALSE"; 47 %ROWCOUNT --返回游标当前行的行数; 48 %ISOPEN --如果游标是开的则返回"TRUE",否则为"FALSE"; 49 示例: 50 set autoprint on; 51 var c_1 refcursor; 52 DECLARE 53 n number; 54 BEGIN 55 n:=&请输入; 56 if n=1 then 57 open :c_1 for select * from emp; 58 else 59 open :c_1 for select * from dept; 60 end if; 61 END;
1 过程 2 -------------------------------------------------------------------------------- 3 4 定义:CREATE [OR REPLACE] PROCEDURE <过程名>[(参数列表)] IS 5 [局部变量声明] 6 BEGIN 7 可执行语句 8 EXCEPTION 9 异常处理语句 10 END [<过程名>]; 11 12 变量的类型:in 为默认类型,表示输入; out 表示只输出;in out 表示即输入又输出; 13 14 15 操作以有的过程:在PL/SQL块中直接使用过程名;在程序外使用execute <过程名>[(参数列表)] 16 17 使用: 18 示例: 19 创建过程: 20 create or replace procedure p_1(n in out number) is 21 r emp%rowtype; 22 BEGIN 23 dbms_output.put_line('姓名 薪水'); 24 select * into r from emp where empno=n; 25 dbms_output.put_line(r.ename||''||r.sal); --输出结果,需要 set serverout on 才能显示. 26 n:=r.sal; 27 END; 28 使用过程: 29 declare 30 n number; 31 begin 32 n:=&请输入员工号; 33 p_1(n); 34 dbms_output.put_line('n的值为 '||n); 35 end; 36 37 38 删除过程: 39 DROP PROCEDURE <过程名>;
函数
1 函数 2 -------------------------------------------------------------------------------- 3 4 定义:CREATE [OR REPLACE] FUNCTION <过程名>[(参数列表)] RETURN 数据类型 IS 5 [局部变量声明] 6 BEGIN 7 可执行语句 8 EXCEPTION 9 异常处理语句 10 END [<过程名>]; 11 12 变量的类型:in 为默认类型,表示输入; out 表示只输出;in out 表示即输入又输出; 13 14 15 使用: 16 示例: 17 创建函数: 18 create or replace function f_1(n number) return number is 19 r emp%rowtype; 20 BEGIN 21 dbms_output.put_line('姓名 薪水'); 22 select * into r from emp where empno=n; 23 dbms_output.put_line(r.ename||''||r.sal); --输出结果,需要 set serverout on 才能显示. 24 return r.sal; 25 END; 26 使用函数: 27 declare 28 n number; 29 m number; 30 begin 31 n:=&请输入员工号; 32 m:=f_1(n); 33 dbms_output.put_line('m的值为 '||m); 34 end; 35 36 37 删除函数: 38 DROP FUNCTION <函数名>;
数据包
1 数据包 2 -------------------------------------------------------------------------------- 3 4 定义: 5 定义包的规范 6 CREATE [OR REPLACE] PACKAGE <数据包名> AS 7 --公共类型和对象声明 8 --子程序说明 9 END; 10 定义包的主体 11 CREATE [OR REPLACE] PACKAGE BODY <数据包名> AS 12 --公共类型和对象声明 13 --子程序主体 14 BEGIN 15 -初始化语句 16 END; 17 18 19 使用: 20 示例: 21 创建数据包规范: 22 create or replace package pack_1 as 23 n number; 24 procedure p_1; 25 FUNCTION f_1 RETURN number; 26 end; 27 28 创建数据包主体: 29 create or replace package body pack_1 as 30 procedure p_1 is 31 r emp%rowtype; 32 begin 33 select * into r from emp where empno=7788; 34 dbms_output.put_line(r.empno||''||r.ename||''||r.sal); 35 end; 36 37 FUNCTION f_1 RETURN number is 38 r emp%rowtype; 39 begin 40 select * into r from emp where empno=7788; 41 return r.sal; 42 end; 43 end; 44 45 使用包: 46 declare 47 n number; 48 begin 49 n:=&请输入员工号; 50 pack_1.n:=n; 51 pack_1.p_1; 52 n:=pack_1.f_1; 53 dbms_output.put_line('薪水为 '||n); 54 end; 55 56 在包中使用REF游标 57 示例: 58 创建数据包规范: 59 create or replace package pack_2 as 60 TYPE c_type is REF CURSOR; --建立一个ref游标类型 61 PROCEDURE p_1(c1 in out c_type); --过程的参数为ref游标类型; 62 end; 63 64 创建数据包主体: 65 create or replace package body pack_2 as 66 PROCEDURE p_1(c1 in out c_type) is 67 begin 68 open c1 for select * from emp; 69 end; 70 end; 71 72 使用包: 73 var c_1 refcursor; 74 set autoprint on; 75 execute pack_2.p_1(:c_1); 76 77 78 79 删除包: 80 DROP PACKAGE <包名>;
触发器
1 触发器 2 3 -------------------------------------------------------------------------------- 4 创建触发器: 5 CREATE [OR REPLACE] TRIGGER <触发器名> 6 BEFORE|AFTER 7 INSERT|DELETE|UPDATE [OF <列名>] ON <表名> 8 [FOR EACH ROW] 9 WHEN (<条件>) 10 <pl/sql块> 11 12 关键字"BEFORE"在操作完成前触发;"AFTER"则是在操作完成后触发; 13 关键字"FOR EACH ROW"指定触发器每行触发一次. 14 关键字"OF <列名>" 不写表示对整个表的所有列. 15 WHEN (<条件>)表达式的值必须为"TRUE". 16 17 特殊变量: 18 :new --为一个引用最新的列值; 19 :old --为一个引用以前的列值; 20 这些变量只有在使用了关键字 "FOR EACH ROW"时才存在.且update语句两个都有,而insert只有:new ,delect 只有:old; 21 22 使用RAISE_APPLICATION_ERROR 23 语法:RAISE_APPLICATION_ERROR(错误号(-20000到-20999),消息[,{true|false}]); 24 抛出用户自定义错误. 25 如果参数为'TRUE',则错误放在先前的堆栈上. 26 27 INSTEAD OF 触发器 28 INSTEAD OF 触发器主要针对视图(VIEW)将触发的dml语句替换成为触发器中的执行语句,而不执行dml语句. 29 30 31 禁用某个触发器 32 ALTER TRIGGER <触发器名> DISABLE 33 重新启用触发器 34 ALTER TRIGGER <触发器名> ENABLE 35 禁用所有触发器 36 ALTER TRIGGER <触发器名> DISABLE ALL TRIGGERS 37 启用所有触发器 38 ALTER TRIGGER <触发器名> ENABLE ALL TRIGGERS 39 删除触发器 40 DROP TRIGGER <触发器名> 41 42
自定义对象
1 自定义对象 2 3 -------------------------------------------------------------------------------- 4 创建对象: 5 CREATE [OR REPLACE] TYPE <对象名> AS OBJECT( 6 属性1 类型 7 属性2 类型 8 . 9 . 10 方法1的规范(MEMBER PROCEDURE <过程名> 11 方法2的规范 (MEMBER FUNCTION <函数名> RETURN 类型) 12 . 13 . 14 PRAGMA RESTRIC_REFERENCES(<方法名>,WNDS/RNDS/WNPS/RNPS); 15 关键字"PRAGMA RESTRIC_REFERENCES"通知ORACLE函数按以下模式之一操作; 16 WNDS-不能写入数据库状态; 17 RNDS-不能读出数据库状态; 18 WNPS-不能写入包状态; 19 RNDS-不能读出包状态; 20 21 22 创建对象主体: 23 CREATE [OR REPLACE] TYPE body <对象名> AS 24 方法1的规范(MEMBER PROCEDURE <过程名> is <PL/SQL块> 25 方法2的规范 (MEMBER FUNCTION <函数名> RETURN 类型 is <PL/SQL块> 26 END; 27 28 使用MAP方法和ORDER方法 29 用于对自定义类型排序。每个类型只有一个MAP或ORDER方法。 30 格式:MAP MEMBER FUNCTION <函数名> RETURN 类型 31 ORDER MEMBER FUNCTION <函数名> RETURN NUMBER 32 33 创建对象表 34 CREATE TABLE <表名> OF <对象类型> 35 36 示例: 37 1. 创建name 类型 38 create or replace type name_type as object( 39 f_name varchar2(20), 40 l_name varchar2(20), 41 map member function name_map return varchar2); 42 43 create or replace type body name_type as 44 map member function name_map return varchar2 is --对f_name和l_name排序 45 begin 46 return f_name||l_name; 47 end; 48 end; 49 2 创建address 类型 50 create or replace type address_type as object 51 ( city varchar2(20), 52 street varchar2(20), 53 zip number, 54 order member function address_order(other address_type) return number); 55 56 create or replace type body address_type as 57 order member function address_order(other address_type) return number is --对zip排序 58 begin 59 return self.zip-other.zip; 60 end; 61 end; 62 63 3 创建stu对象 64 create or replace type stu_type as object ( 65 stu_id number(5), 66 stu_name name_type, 67 stu_addr address_type, 68 age number(3), 69 birth date, 70 map member function stu_map return number, 71 member procedure update_age); 72 73 create or replace type body stu_type as 74 map member function stu_map return number is --对stu_id排序 75 begin 76 return stu_id; 77 end; 78 member procedure update_age is --求年龄用现在时间-birth 79 begin 80 update student set age=to_char(sysdate,'yyyy')-to_char(birth,'yyyy') where stu_id=self.stu_id; 81 end; 82 end; 83 4. 创建对象表 84 create table student of stu_type(primary key(stu_id)); 85 5.向对象表插值 86 insert into student values(1,name_type('关','羽'),address_type('武汉','成都路',43000), null,sysdate-365*20); 87 6.使用对象的方法 88 delcare 89 aa stu_type; 90 begin 91 select value(s) into aa from student s where stu_id=1; --value()将对象表的每一行转成行对象括号中必须为表的别名 92 aa.update_age(); 93 end; 94 7.select stu_id,s.stu_name.f_name,s.stu_name.l_name from student s; --查看类型的值 95 8.select ref(s) from student s ; --ref()求出行对象的OID,括号中必须为表的别名;deref()将oid变成行队像; 96
其他
1 其他 2 3 -------------------------------------------------------------------------------- 4 1.在PL/SQL中使用DDL 5 将sql语句赋给一个varchar2变量,在用execute immediate 这个varchar2变量即可; 6 示例: 7 declare 8 str varchar2(200); 9 begin 10 str:='create table test(id number,name varchar2(20))'; --创建表 11 execute immediate str; 12 str:='insert into test values(3,''c'')'; --向表里插数据 13 execute immediate str; 14 end; 15 但是要队这个表插入数据也必须使用execute immediate 字符变量 16 17 2.判断表是否存在; 18 示例: 19 declare 20 n tab.tname%type; 21 begin 22 select tname into n from tab where tname='&请输入表名'; 23 dbms_output.put_line('此表以存在'); 24 exception 25 when no_data_found then 26 dbms_output.put_line('还没有此表'); 27 end; 28 29 30 2.查看以有的过程; 31 示例: 32 select object_name,object_type,status from user_objects where object_type='PROCEDURE'; 33
七: 附录
Oracle 数据库类型
|
|
||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||
函数
字符函数
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
名称
|
描述 |
|
ABS(数字)
|
一个数的绝对值 |
|
CEIL(数字)
|
向上取整;不论小数后的书为多少都要向前进位; CEIL(123.01)=124; CEIL(-123.99)=-123; |
|
FLOOR(数字)
|
向下取整;不论小数后的书为多少都删除;| floor(123.99)=123; floor(-123.01)=-124; |
|
MOD(被除数,除数)
|
取余数; MOD(20,3)=2 |
|
ROUND(数字,从第几为开始取)
|
四舍五入; ROUND(123.5,0)=124; ROUND(-123.5,0)=-124; ROUND(123.5,-2)=100; ROUND(-123.5,-2)=-100; |
|
SIGN(数字)
|
判断是正数还是负数;正数返回1,负数返回-1,0返回0; |
|
SQRT(数字)
|
对数字开方; |
|
POWER(m,n)
|
求m的n次方; |
|
TRUNC(数字,从第几位开始)
|
切数字; TRUNC(123.99,1)=123.9 TRUNC(-123.99,1)=-123.9 TRUNC(123.99,-1)=120 TRUNC(-123.99,-1)=-120 TRUNC(123.99)=123 |
|
GREATEST(数字列表)
|
找出数字列表中最大的数; 示例: select greatest(100,200,-100) from dual; --结果为200 |
|
LEAST(数字列表)
|
找出数字列表中最小的数; |
|
SIN(n)
|
求n的正旋 |
|
COS(n)
|
求n的余旋 |
|
TAN(n)
|
求n的正切 |
|
ACos(n)
|
求n的反正切 |
|
ATAN(n)
|
求n的反正切 |
|
exp(n)
|
求n的指数 |
|
LN(n)
|
求n的自然对数,n必须大于0 |
|
LOG(m,n)
|
求n以m为底的对数,m和n为正数,且m不能为0 |
日期函数
|
名称
|
描述 |
sysdate |
sysdate 【功能】:返回当前日期。 【参数】:没有参数,没有括号 【返回】:日期 【示例】select sysdate hz from dual; 返回:2008-11-5 |
|
ADD_MONTHS(日期,数字)
|
在以有的日期上加一定的月份;
add_months(d1,n1) 【功能】:返回在日期d1基础上再加n1个月后新的日期。 【参数】:d1,日期型,n1数字型 【返回】:日期 【示例】select sysdate,add_months(sysdate,3) hz from dual; 返回:2008-11-5,2009-2-5
|
|
LAST_DAY(日期)
|
last_day(d1) 【功能】:返回日期d1所在月份最后一天的日期。 【参数】:d1,日期型 【返回】:日期 【示例】select sysdate,last_day(sysdate) hz from dual; 返回:2008-11-5,2008-11-30 |
|
MONTHS_BETWEEN(日期1,日期2)
|
months_between(d1,d2)
【功能】:返回日期d1到日期d2之间的月数。
【参数】:d1,d2 日期型
【返回】:数字
如果d1>d2,则返回正数
如果d1<d2,则返回负数
【示例】
select sysdate,
months_between(sysdate,to_date('2006-01-01','YYYY-MM-DD')),
months_between(sysdate,to_date('2016-01-01','YYYY-MM-DD')) from dual;
返回:2008-11-5,34.16,-85.84
示例: select months_between(sysdate,hiredate) from emp; |
|
NEW_TIME(时间,时区,'gmt')
|
NEW_TIME(dt1,c1,c2) 【功能】:给出时间dt1在c1时区对应c2时区的日期和时间 【参数】:dt1,d2 日期型 【返回】:日期时间 【参数】:c1,c2对应的 时区及其简写 大西洋标准时间:AST或ADT 阿拉斯加_夏威夷时间:HST或HDT 英国夏令时:BST或BDT 美国山区时间:MST或MDT 美国中央时区:CST或CDT 新大陆标准时间:NST 美国东部时间:EST或EDT 太平洋标准时间:PST或PDT 格林威治标准时间:GMT Yukou标准时间:YST或YDT 【示例】 select to_char(sysdate,'yyyy.mm.dd hh24:mi:ss') bj_time, to_char(new_time(sysdate,'PDT','GMT'),'yyyy.mm.dd hh24:mi:ss') los_angles from dual; 返回: BJ_TIME LOS_ANGLES ------------------- ------------------- 2008.11.05 20:11:58 2008.11.06 03:11:58 【示例】 select sysdate bj_time, new_time(sysdate,'PDT','GMT') los_angles from dual; 返回: BJ_TIME LOS_ANGLES ------------------- ------------------- 2008-11-05 20:11:58 2008-11-06 03:11:58 |
round(d1[,c1]) |
round(d1[,c1]) 【功能】:给出日期d1按期间(参数c1)四舍五入后的期间的第一天日期(与数值四舍五入意思相近) 【参数】:d1日期型,c1为字符型(参数),c1默认为j(即最近0点日期) 【参数表】:c1对应的参数表: 最近0点日期: 取消参数c1或j 最近的星期日:day或dy或d 最近月初日期:month或mon或mm或rm 最近季日期:q 最近年初日期:syear或year或yyyy或yyy或yy或y(多个y表示精度) 最近世纪初日期:cc或scc 【返回】:日期 【示例】 select sysdate 当时日期, round(sysdate) 最近0点日期, round(sysdate,'day') 最近星期日, round(sysdate,'month') 最近月初, round(sysdate,'q') 最近季初日期, round(sysdate,'year') 最近年初日期 from dual; |
trunc(d1[,c1]) |
trunc(d1[,c1]) 【功能】:返回日期d1所在期间(参数c1)的第一天日期 【参数】:d1日期型,c1为字符型(参数),c1默认为j(即当前日期) 【参数表】:c1对应的参数表: 最近0点日期: 取消参数c1或j 最近的星期日:day或dy或d (每周顺序:日,一,二,三,四,五,六) 最近月初日期:month或mon或mm或rm 最近季日期:q 最近年初日期:syear或year或yyyy或yyy或yy或y(多个y表示精度) 最近世纪初日期:cc或scc 【返回】:日期 【示例】 select sysdate 当时日期, trunc(sysdate) 今天日期, trunc(sysdate,'day') 本周星期日, trunc(sysdate,'month') 本月初, trunc(sysdate,'q') 本季初日期, trunc(sysdate,'year') 本年初日期 from dual; |
|
NEXT_DAY(d,char)
|
next_day(d1[,c1]) 【功能】:返回日期d1在下周,星期几(参数c1)的日期 【参数】:d1日期型,c1为字符型(参数),c1默认为j(即当前日期) 【参数表】:c1对应:星期一,星期二,星期三……星期日 【返回】:日期 【示例】 select sysdate 当时日期, next_day(sysdate,'星期一') 下周星期一, next_day(sysdate,'星期二') 下周星期二, next_day(sysdate,'星期三') 下周星期三, next_day(sysdate,'星期四') 下周星期四, next_day(sysdate,'星期五') 下周星期五, next_day(sysdate,'星期六') 下周星期六, next_day(sysdate,'星期日') 下周星期日 from dual; |
extract(c1 from d1) |
extract(c1 from d1) 【功能】:日期/时间d1中,参数(c1)的值 【参数】:d1日期型(date)/日期时间型(timestamp),c1为字符型(参数) 【参数表】:c1对应的参数表详见示例 【返回】:字符 【示例】 select extract(hour from timestamp '2001-2-16 2:38:40 ' ) 小时, extract(minute from timestamp '2001-2-16 2:38:40 ' ) 分钟, extract(second from timestamp '2001-2-16 2:38:40 ' ) 秒, extract(DAY from timestamp '2001-2-16 2:38:40 ' ) 日, extract(MONTH from timestamp '2001-2-16 2:38:40 ' ) 月, extract(YEAR from timestamp '2001-2-16 2:38:40 ' ) 年 from dual; select extract (YEAR from date '2001-2-16' ) from dual; select sysdate 当前日期, extract(hour from timestamp timestamp sysdate) 小时, extract(DAY from sysdate ) 日, extract(MONTH from sysdate ) 月, extract(YEAR from sysdate ) 年 from dual; |
localtimestamp |
localtimestamp 【功能】:返回会话中的日期和时间 【参数】:没有参数,没有括号 【返回】:日期 【示例】select localtimestamp from dual; 返回:14-11月-08 12.35.37.453000 上午 |
current_timestamp |
current_timestamp 【功能】:以timestamp with time zone数据类型返回当前会话时区中的当前日期 【参数】:没有参数,没有括号 【返回】:日期 【示例】select current_timestamp from dual; 返回:14-11月-08 12.37.34.609000 上午 +08:00 |
current_date |
current_date 【功能】:返回当前会话时区中的当前日期 【参数】:没有参数,没有括号 【返回】:日期 【示例】select current_date from dual; 返回:2008-11-14 |
dbtimezone |
dbtimezone 【功能】:返回时区 【参数】:没有参数,没有括号 【返回】:字符型 【示例】select dbtimezone from dual; |
SESSIONTIMEZONE |
SESSIONTIMEZONE 【功能】:返回会话时区 【参数】:没有参数,没有括号 【返回】:字符型 【示例】select dbtimezone,SESSIONTIMEZONE from dual; 返回:+00:00 +08:00 |
INTERVAL c1 set1 |
INTERVAL c1 set1 【功能】:变动日期时间数值 【参数】:c1为数字字符串或日期时间字符串,set1为日期参数 【参数表】:set1具体参照示例 【返回】:日期时间格式的数值,前面多个+号 以天或天更小单位时可用数值表达式借用,如1表示1天,1/24表示1小时,1/24/60表示1分钟 【示例】 select trunc(sysdate)+(interval '1' second), --加1秒(1/24/60/60) trunc(sysdate)+(interval '1' minute), --加1分钟(1/24/60) trunc(sysdate)+(interval '1' hour), --加1小时(1/24) trunc(sysdate)+(INTERVAL '1' DAY), --加1天(1) trunc(sysdate)+(INTERVAL '1' MONTH), --加1月 trunc(sysdate)+(INTERVAL '1' YEAR), --加1年 trunc(sysdate)+(interval '01:02:03' hour to second), --加指定小时到秒 trunc(sysdate)+(interval '01:02' minute to second), --加指定分钟到秒 trunc(sysdate)+(interval '01:02' hour to minute), --加指定小时到分钟 trunc(sysdate)+(interval '2 01:02' day to minute) --加指定天数到分钟 from dual; |
转换函数
|
名称
|
描述 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

chartorowid(c1) 。。 |
chartorowid(c1) 。。
【功能】转换varchar2类型为rowid值
【参数】c1,字符串,长度为18的字符串,字符串必须符合rowid格式
【返回】返回rowid值
【示例】
SELECT chartorowid('AAAADeAABAAAAZSAAA') FROM DUAL;
【说明】
在Oracle中,每一条记录都有一个rowid,rowid在整个数据库中是唯一的,rowid确定了每条记录是在Oracle中的哪一个数据文件、块、行上。
在重复的记录中,可能所有列的内容都相同,但rowid不会相同.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

ROWIDTOCHAR(rowid) 。。 |
ROWIDTOCHAR(rowid) 。。 【功能】转换rowid值为varchar2类型 【参数】rowid,固定参数 【返回】返回长度为18的字符串 【示例】 SELECT ROWIDTOCHAR(rowid) FROM DUAL; 【说明】 在Oracle中,每一条记录都有一个rowid,rowid在整个数据库中是唯一的,rowid确定了每条记录是在Oracle中的哪一个数据文件、块、行上。 在重复的记录中,可能所有列的内容都相同,但rowid不会相同. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
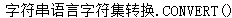
CONVERT(c1,set1,set2) |
CONVERT(c1,set1,set2)
【功能】将源字符串c1 从一个语言字符集set2转换到另一个目的set1字符集
【参数】c1,字符串,set1,set2为字符型参数
【返回】字符串
【示例】
select convert('strutz','we8hp','f7dec') "conversion" from dual;
conver
------
strutz
select convert(name,'us7ascii','zhs16cgb231280') "conversion" from dual;
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

HEXTORAW(c1) |
HEXTORAW(c1)
【功能】将一个十六进制构成的字符串转换为二进制
【参数】c1,十六进制的字符串
【返回】字符串
【示例】
select HEXTORAW('A123') from dual;
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
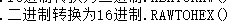
RAWTOHEX(c1) |
RAWTOHEX(c1)
【功能】将一个二进制构成的字符串转换为十六进制
【参数】c1,二进制的字符串
【返回】字符串
【示例】
select RAWTOHEX('A123') from dual;
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
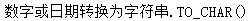
TO_CHAR(x[[,c2],C3]) |
TO_CHAR(x[[,c2],C3]) c1格式表参考:
【示例】
【示例】
【示例】带C3示例 select
to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American')
from dual;
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

TO_DATE(X[,c2[,c3]]) |
TO_DATE(X[,c2[,c3]])
【功能】将字符串X转化为日期型
【参数】c2,c3,字符型,参照to_char()
【返回】字符串
如果x格式为日期型(date)格式时,则相同表达:date x
如果x格式为日期时间型(timestamp)格式时,则相同表达:timestamp x
【相反】 to_char(date[,c2[,c3]])
【示例】
select to_date('199912','yyyymm'),
to_date('2000.05.20','yyyy.mm.dd'),
(date '2008-12-31') XXdate,
to_date('2008-12-31 12:31:30','yyyy-mm-dd hh24:mi:ss'),
(timestamp '2008-12-31 12:31:30') XXtimestamp
from dual;
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

TO_NUMBER(X[[,c2],c3]) |
TO_NUMBER(X[[,c2],c3])
【功能】将字符串X转化为数字型
【参数】c2,c3,字符型,参照to_char()
【返回】数字串
【相反】 to_char(date[[,c2],c3])
【示例】
select TO_NUMBER('199912'),TO_NUMBER('450.05') from dual;
转换为16进制。
TO_CHAR(100,'XX')= 64
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
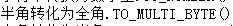
TO_MULTI_BYTE(c1) |
TO_MULTI_BYTE(c1)
【功能】将字符串中的半角转化为全角
【参数】c1,字符型
【返回】字符串
【示例】
SQL> select to_multi_byte('高A') text from dual;
test
--
高A
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
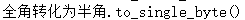
to_single_byte(c1) |
to_single_byte(c1)
【功能】将字符串中的全角转化为半角
【参数】c1,字符型
【返回】字符串
【示例】
SQL> select to_multi_byte('高A') text from dual;
test
----
高A
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

nls_charset_id(c1) |
nls_charset_id(c1)
【功能】返回字符集名称参应id值
【参数】c1,字符型
【返回】数值型
sql> select nls_charset_id('zhs16gbk') from dual;
nls_charset_id('zhs16gbk')
--------------------------
852
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

nls_charset_name(n1) |
nls_charset_name(n1) 【功能】返回字符集名称参应id值 【参数】n1,数值型 【返回】字符型 sql> select nls_charset_name(852) from dual; nls_char -------- zhs16gbk |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
聚合函数 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

AVG([distinct|all]x) |
AVG([distinct|all]x)
【功能】统计数据表选中行x列的平均值。
【参数】all表示对所有的值求平均值,distinct只对不同的值求平均值,默认为all
如果有参数distinct或all,需有空格与x(列)隔开。
【参数】x,只能为数值型字段
【返回】数字值
【示例】
环境:
create table table3(xm varchar(8),sal number(7,2));
insert into table3 values('gao',1111.11);
insert into table3 values('gao',1111.11);
insert into table3 values('zhu',5555.55);
commit;
执行统计:
select avg(distinct sal),avg(all sal),avg(sal) from table3;
结果: 3333.33 2592.59 2592.59
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

SUM([distinct|all]x) |
SUM([distinct|all]x)
【功能】统计数据表选中行x列的合计值。
【参数】all表示对所有的值求合计值,distinct只对不同的值求合计值,默认为all
如果有参数distinct或all,需有空格与x(列)隔开。
【参数】x,只能为数值型字段
【返回】数字值
【示例】
环境:
create table table3(xm varchar(8),sal number(7,2));
insert into table3 values('gao',1111.11);
insert into table3 values('gao',1111.11);
insert into table3 values('zhu',5555.55);
commit;
执行统计:
select SUM(distinct sal),SUM(all sal),SUM(sal) from table3;
结果: 6666.66 7777.77 7777.77
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

STDDEV([distinct|all]x) |
STDDEV([distinct|all]x)
【功能】统计数据表选中行x列的标准误差。
【参数】all表示对所有的值求标准误差,distinct只对不同的值求标准误差,默认为all
如果有参数distinct或all,需有空格与x(列)隔开。
【参数】x,只能为数值型字段
【返回】数字值
【示例】
环境:
create table table3(xm varchar(8),sal number(7,2));
insert into table3 values('gao',1111.11);
insert into table3 values('gao',1111.11);
insert into table3 values('zhu',5555.55);
commit;
执行统计:
select STDDEV(distinct sal),STDDEV(all sal),STDDEV(sal) from table3;
结果: 3142.69366257674 2565.99863039714 2565.99863039714
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
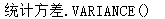
VARIANCE([distinct|all]x) |
VARIANCE([distinct|all]x)
【功能】统计数据表选中行x列的方差。
【参数】all表示对所有的值求方差,distinct只对不同的值求方差,默认为all
如果有参数distinct或all,需有空格与x(列)隔开。
【参数】x,只能为数值型字段
【返回】数字值
【示例】
环境:
create table table3(xm varchar(8),sal number(7,2));
insert into table3 values('gao',1111.11);
insert into table3 values('gao',1111.11);
insert into table3 values('zhu',5555.55);
commit;
执行统计:
select VARIANCE(distinct sal),VARIANCE(all sal),VARIANCE(sal) from table3;
结果: 9876523.4568 6584348.9712 6584348.9712
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
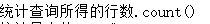
count(*|[distinct|all]x) |
count(*|[distinct|all]x)
【功能】统计数据表选中行x列的合计值。
【参数】
*表示对满足条件的所有行统计,不管其是否重复或有空值(NULL)
all表示对所有的值统计,默认为all
distinct只对不同的值统计,
如果有参数distinct或all,需有空格与x(列)隔开,均忽略空值(NULL)。
【参数】x,可为数字、字符、日期型及其它类型的字段
【返回】数字值
count(*)=sum(1)
【示例】
环境:
create table table3(xm varchar(8),sal number(7,2));
insert into table3 values('gao',1111.11);
insert into table3 values('gao',1111.11);
insert into table3 values('zhu',5555.55);
insert into table3 values('',1111.11);
insert into table3 values('zhu',0);
commit;
执行统计:
select count(*),count(xm),count(all xm),count(distinct sal),count(all sal),count(sal),sum(1) from table3;
结果: 5 4 4 3 5 5 5
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

MAX([distinct|all]x) |
MAX([distinct|all]x)
【功能】统计数据表选中行x列的最大值。
【参数】all表示对所有的值求最大值,distinct只对不同的值求最大值,默认为all
如果有参数distinct或all,需有空格与x(列)隔开。
【参数】x,可为数字、字符或日期型字段
【返回】对应x字段类型
【示例】
环境:
create table table3(xm varchar(8),sal number(7,2));
insert into table3 values('gao',1111.11);
insert into table3 values('gao',1111.11);
insert into table3 values('zhu',5555.55);
insert into table3 values('',1111.11);
insert into table3 values('zhu',0);
commit;
执行统计:
select MAX(distinct sal),MAX(xm) from table3;
结果:5555.55 zhu
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

MIN([distinct|all]x) |
MIN([distinct|all]x)
【功能】统计数据表选中行x列的最大值。
【参数】all表示对所有的值求最大值,distinct只对不同的值求最大值,默认为all
如果有参数distinct或all,需有空格与x(列)隔开。
【参数】x,可为数字、字符或日期型字段
【返回】对应x字段类型
注:字符型字段,将忽略空值(NULL)
【示例】
环境:
create table table3(xm varchar(8),sal number(7,2));
insert into table3 values('gao',1111.11);
insert into table3 values('gao',1111.11);
insert into table3 values('zhu',5555.55);
insert into table3 values('',1111.11);
insert into table3 values('zhu',0);
commit;
执行统计:
select MIN(distinct sal),MIN(xm),MIN(distinct xm),MIN(all xm) from table3;
结果:0 gao gao gao
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Oracle 分析函数 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
其他函数
|
名称
|
描述 |
|
VSIZE(类型)
|
求出数据类型的大小; |
|
NVL(字符串,替换字符)
|
如果字符串为空则替换,否则不替换 |
|
命令
|
描述 |
|
DESC 表名
|
查看表的信息. |
|
SET SERVEROUT [ON|OFF]
|
设置系统输出的状态. |
|
SET PAGESIZE <大小>
|
设置浏览中没页的大小 |
|
SET LINESIZE <大小>
|
设置浏览中每行的长度 |
|
SET AUTOPRINT [ON|OFF]
|
设置是否自动打印全局变量的值 |
|
SELECT SYSDATE FROM DUAL
|
查看当前系统时间 |
|
ALTER SESSION SET nls_date_format='格式'
|
设置当前会话的日期格式 示例:ALTER SESSION SET nls_date_format='dd-mon-yy hh24:mi:ss' |
|
SELECT * FROM TAB
|
查看当前用户下的所有表 |
|
SHOW USER
|
显示当前用户 |
|
HELP TOPIC
|
显示有那些命令 |
|
SAVE <file_name>
|
将buf中的内容保存成一个文件 |
|
RUN <file_name>
|
执行已经保存的文件;也可以写成@<file_name> |
|
GET <file_name>
|
显示文件中的内容 |
|
LIST
|
显示buf中的内容 |
|
ED
|
用记事本打开buf,可以进行修改 |
|
DEL 行数
|
删除buf中的单行 |
|
DEL 开始行 结束行
|
删除buf中的多行 |
|
INPUT 字符串
|
向buf中插入一行 |
|
APPEND 字符串
|
将字符串追加到当前行 |
|
C/以前的字符串/替换的字符串
|
修改buf中当前行的内容 |
|
CONNECT
|
连接 |
|
DISCONNECT
|
断开连接 |
|
QUIT
|
退出sql*plus |
|
EXP
|
导出数据库(可以在DOS键入exp help=y 可以看到详细说明) 示例: exp scott/tiger full=y file=e:\a.dmp; --导出scott下的所有东西 exp scott/tiger tables=(emp,dept) file=e:\emp.dmp --导出scott下的 emp,dept表 |
|
IMP
|
导入数据库(可以在DOS键入imp help=y 可以看到详细说明) imp scott/tiger tables=(emp,dept) file=e:\emp.dmp |
可以通过help <命令>获得命令的帮助
常用命令
|
异常
|
描述
|
|
CURSOR_ALREADY_OPEN
|
试图"OPEN"一个已经打开的游标
|
|
DUP_VAL_ON_INDEX
|
试图向有"UNIQUE"中插入重复的值
|
|
INVALID_CURSOR
|
试图对以关闭的游标进行操作
|
|
INVALID_NUMBER
|
在SQL语句中将字符转换成数字失败
|
|
LOGIN_DENIED
|
使用无效用户登陆
|
|
NO_DATA_FOUND
|
没有找到数据时
|
|
NOT_LOGIN_ON
|
没有登陆Oracle就发出命令时
|
|
PROGRAM_ERROR
|
PL/SQL存在诸如某个函数没有"RETURN"语句等内部问题
|
|
STORAGE_ERROR
|
PL/SQL耗尽内存或内存严重不足
|
|
TIMEOUT_ON_RESOURCE
|
Oracle等待资源期间发生超时
|
|
TOO_MANY_ROWS
|
"SELECT INTO"返回多行时
|
|
VALUE_ERROR
|
当出现赋值错误
|
|
ZERO_DIVIDE
|
除数为零
|
学问:纸上得来终觉浅,绝知此事要躬行
为事:工欲善其事,必先利其器。
态度:道阻且长,行则将至;行而不辍,未来可期
.....................................................................
------- 桃之夭夭,灼灼其华。之子于归,宜其室家。 ---------------
------- 桃之夭夭,有蕡其实。之子于归,宜其家室。 ---------------
------- 桃之夭夭,其叶蓁蓁。之子于归,宜其家人。 ---------------
=====================================================================
* 博客文章部分截图及内容来自于学习的书本及相应培训课程以及网络其他博客,仅做学习讨论之用,不做商业用途。
* 如有侵权,马上联系我,我立马删除对应链接。 * @author Alan -liu * @Email no008@foxmail.com
转载请标注出处! ✧*꧁一品堂.技术学习笔记꧂*✧. ---> https://www.cnblogs.com/ios9/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号