Oracle 行转列pivot 、列转行unpivot 的Sql语句总结
这个比较简单,用||或concat函数可以实现
- select concat(id,username) str from app_user
- select id||username str from app_user
字符串转多列
实际上就是拆分字符串的问题,可以使用 substr、instr、regexp_substr函数方式wm_concat函数
- create table test(id number,name varchar2(20));
- insert into test values(1,'a');
- insert into test values(1,'b');
- insert into test values(1,'c');
- insert into test values(2,'d');
- insert into test values(2,'e');
效果1 : 行转列 ,默认逗号隔开
- select wm_concat(name) name from test;
效果2: 把结果里的逗号替换成"|"
- select replace(wm_concat(name),',','|') from test;
效果3: 按ID分组合并name
- select id,wm_concat(name) name from test group by id;
sql语句等同于下面的sql语句
- -------- 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE )
- select id, max(decode(rn, 1, name, null)) || max(decode(rn, 2, ','||name, null)) || max(decode(rn, 3, ','||name, null)) str
- from (select id, name ,row_number() over(partition by id order by name) as rn from test) t group by id order by 1;
- -------- 适用范围:8i,9i,10g及以后版本 ( ROW_NUMBER + LEAD )
- select id, str from (select id,row_number() over(partition by id order by name) as rn,name || lead(',' || name, 1)
- over(partition by id order by name) || lead(',' || name, 2) over(partition by id order by name) || lead(',' || name, 3)
- over(partition by id order by name) as str from test) where rn = 1 order by 1;
- -------- 适用范围:10g及以后版本 ( MODEL )
- select id, substr(str, 2) str from test model return updated rows partition by(id) dimension by(row_number()
- over(partition by id order by name) as rn) measures (cast(name as varchar2(20)) as str) rules upsert iterate(3)
- until(presentv(str[iteration_number + 2], 1, 0)=0) (str[0] = str[0] || ',' || str[iteration_number + 1]) order by 1;
- -------- 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE )
- select t.id id, max(substr(sys_connect_by_path(t.name, ','), 2)) str from (select id, name, row_number()
- over(partition by id order by name) rn from test) t start with rn = 1 connect by rn = prior rn + 1 and id = prior id
- group by t.id;
懒人扩展用法:
案例: 我要写一个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法? 当然有了,看我如果应用wm_concat来让这个需求变简单,假设我的APP_USER表中有(id,username,password,age)4个字段。查询结果如下
- /** 这里的表名默认区分大小写 */
- select 'create or replace view as select '|| wm_concat(column_name) || ' from APP_USER' sqlStr
- from user_tab_columns where table_name='APP_USER';
利用系统表方式查询
- select * from user_tab_columns
Oracle 11g 行列互换 pivot 和 unpivot 说明
在Oracle 11g中,Oracle 又增加了2个查询:pivot(行转列) 和unpivot(列转行)
参考:http://blog.csdn.NET/tianlesoftware/article/details/7060306、http://www.oracle.com/technetwork/cn/articles/11g-pivot-101924-zhs.html
google 一下,网上有一篇比较详细的文档:http://www.oracle-developer.net/display.php?id=506
pivot 列转行
测试数据 (id,类型名称,销售数量),案例:根据水果的类型查询出一条数据显示出每种类型的销售数量。
- create table demo(id int,name varchar(20),nums int); ---- 创建表
- insert into demo values(1, '苹果', 1000);
- insert into demo values(2, '苹果', 2000);
- insert into demo values(3, '苹果', 4000);
- insert into demo values(4, '橘子', 5000);
- insert into demo values(5, '橘子', 3000);
- insert into demo values(6, '葡萄', 3500);
- insert into demo values(7, '芒果', 4200);
- insert into demo values(8, '芒果', 5500);

分组查询
(当然这是不符合查询一条数据的要求的)
- select name, sum(nums) nums from demo group by name

行转列查询
- select * from (select name, nums from demo) pivot (sum(nums) for name in ('苹果' 苹果, '橘子', '葡萄', '芒果'));

注意: pivot(聚合函数 for 列名 in(类型)) ,其中 in(‘’) 中可以指定别名,in中还可以指定子查询,比如 select distinct code from customers
当然也可以不使用pivot函数,等同于下列语句,只是代码比较长,容易理解
- ------ 多项子查询
- select * from (select sum(nums) 苹果 from demo where name='苹果'),(select sum(nums) 橘子 from demo where name='橘子'),
- (select sum(nums) 葡萄 from demo where name='葡萄'),(select sum(nums) 芒果 from demo where name='芒果');
- ------ decode 函数利用
- select sum(decode(name,'苹果',nums)) 苹果, sum(decode(name,'橘子',nums)) 橘子,
- sum(decode(name,'葡萄',nums)) 葡萄, sum(decode(name,'芒果',nums)) 芒果 from demo


unpivot 行转列
顾名思义就是将多列转换成1列中去
案例:现在有一个水果表,记录了4个季度的销售数量,现在要将每种水果的每个季度的销售情况用多行数据展示。
创建表和数据
- create table Fruit(id int,name varchar(20), Q1 int, Q2 int, Q3 int, Q4 int);
- insert into Fruit values(1,'苹果',1000,2000,3300,5000);
- insert into Fruit values(2,'橘子',3000,3000,3200,1500);
- insert into Fruit values(3,'香蕉',2500,3500,2200,2500);
- insert into Fruit values(4,'葡萄',1500,2500,1200,3500);
- select * from Fruit

列转行查询
- select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) )
注意: unpivot没有聚合函数,xiaoshou、jidu字段也是临时的变量

同样不使用unpivot也可以实现同样的效果,只是sql语句会很长,而且执行速度效率也没有前者高
- select id, name ,'Q1' jidu, (select q1 from fruit where id=f.id) xiaoshou from Fruit f
- union
- select id, name ,'Q2' jidu, (select q2 from fruit where id=f.id) xiaoshou from Fruit f
- union
- select id, name ,'Q3' jidu, (select q3 from fruit where id=f.id) xiaoshou from Fruit f
- union
- select id, name ,'Q4' jidu, (select q4 from fruit where id=f.id) xiaoshou from Fruit f
。。。。
oracle 12c 关于wm_concat 的替换;LISTAGG
https://blog.csdn.net/tb_problem/article/details/80650334
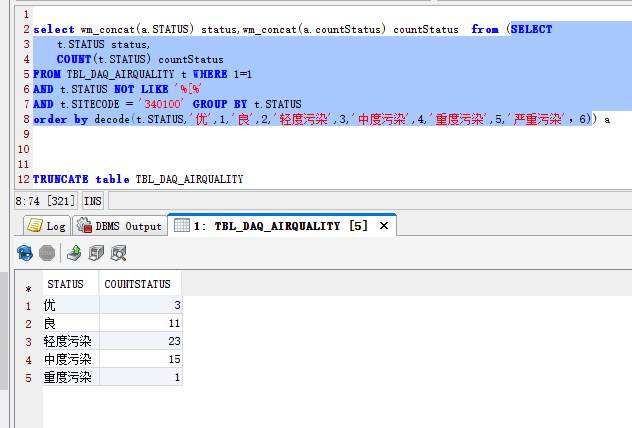
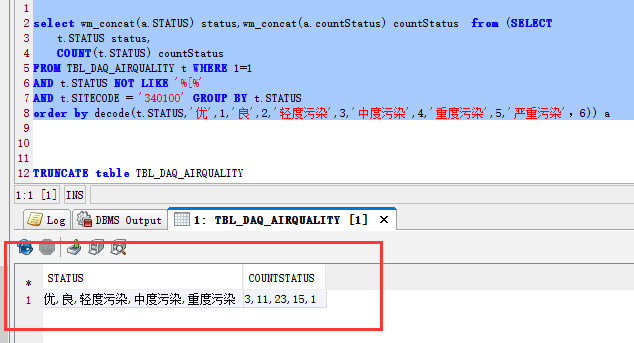
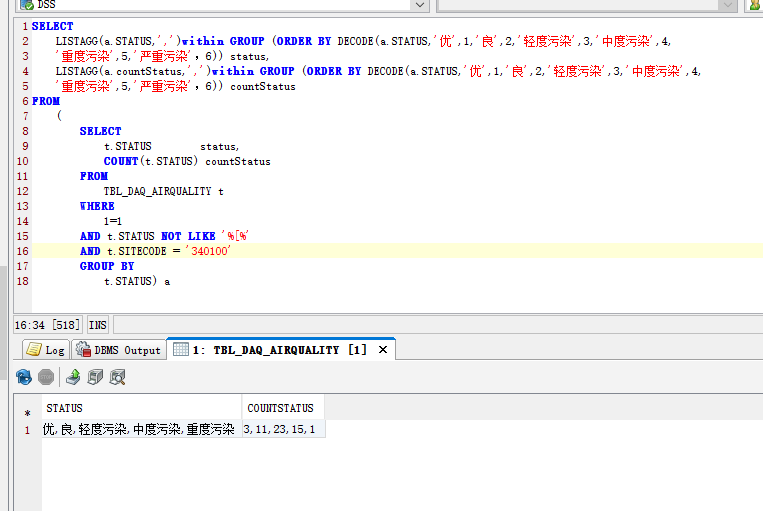
oracle行转列(动态行转不定列)
/*物料 需要数量 需要仓库 现存量仓库 现存量仓库数量 批次
A1
2 C1 C1 20 123
A1
2 C1 C2 30 111
A1
2 C1 C2 20 222
A1
2 C1 C3 10 211
A2
3 C4 C1 40 321
A2
3 C4 C4 50 222
A2
3 C4 C4 60 333
A2
3 C4 C5 70 223
我需要把上面的查询结果转换为下面的。
物料 需要数量 需要仓库 C1 C2 C3 C4 C5
A1
2 C1 20 50 10 0 0
A2 3 C4 40 0 0 110
70
*/
---------------------------------------------------------------建表
----------------判断表是否存在
declare
num number;
begin
select count(1) into num from user_tables where table_name='TEST';
if num>0 then
execute
immediate 'drop table TEST';
end if;
end;
----------------建表
CREATE
TABLE TEST(
WL
VARCHAR2(10),
XYSL
INTEGER,
XYCK
VARCHAR2(10),
XCLCK
VARCHAR2(10),
XCLCKSL
INTEGER,
PC INTEGER
);
----------------第一部分测试数据
INSERT
INTO TEST VALUES('A1', 2, 'C1', 'C1' , 20, 123);
INSERT
INTO TEST VALUES('A1', 2, 'C1', 'C2' , 30, 111);
INSERT
INTO TEST VALUES('A1', 2, 'C1', 'C2' , 20, 222);
INSERT
INTO TEST VALUES('A1', 2, 'C1', 'C3' , 10, 211);
INSERT
INTO TEST VALUES('A2', 3, 'C4', 'C1' , 40, 321);
INSERT
INTO TEST VALUES('A2', 3, 'C4', 'C4' , 50, 222);
INSERT
INTO TEST VALUES('A2', 3, 'C4', 'C4' , 60, 333);
INSERT
INTO TEST VALUES('A2', 3, 'C4', 'C5' , 70, 223);
COMMIT;
--select * from test;
---------------------------------------------------------------行转列的存储过程
CREATE OR REPLACE PROCEDURE P_TEST IS
V_SQL VARCHAR2(2000);
CURSOR CURSOR_1 IS SELECT DISTINCT T.XCLCK FROM TEST T ORDER BY XCLCK;
BEGIN
V_SQL
:= 'SELECT WL,XYSL,XYCK';
FOR V_XCLCK IN
CURSOR_1
LOOP
V_SQL := V_SQL || ',' || 'SUM(DECODE(XCLCK,''' || V_XCLCK.XCLCK ||
''',XCLCKSL,0)) AS ' || V_XCLCK.XCLCK;
END LOOP;
V_SQL := V_SQL
|| ' FROM TEST GROUP BY WL,XYSL,XYCK ORDER BY WL,XYSL,XYCK';
--DBMS_OUTPUT.PUT_LINE(V_SQL);
V_SQL :=
'CREATE OR REPLACE VIEW RESULT AS '|| V_SQL;
--DBMS_OUTPUT.PUT_LINE(V_SQL);
EXECUTE
IMMEDIATE V_SQL;
END;
----------------------------------------------------------------结果
----------------执行存储过程,生成视图
BEGIN
P_TEST;
END;
----------------结果
SELECT
* FROM RESULT T;
WL XYSL
XYCK C1 C2 C3 C4 C5
----------
--------------------------------------- ---------- ---------- ----------
---------- ---------- ----------
A1 2
C1 20 50 10 0 0
A2 3
C4 40 0 0 110 70
----------------第二部分测试数据
INSERT
INTO TEST VALUES('A1', 2, 'C1', 'C6' , 20, 124);
INSERT
INTO TEST VALUES('A2', 2, 'C1', 'C7' , 30, 121);
INSERT
INTO TEST VALUES('A3', 2, 'C1', 'C8' , 20, 322);
COMMIT;
----------------报告存储过程,生成视图
BEGIN
P_TEST;
END;
----------------结果
SELECT
* FROM RESULT T;
WL XYSL
XYCK C1 C2 C3 C4 C5 C6 C7 C8
-----
----- -------- ------- -------- ---------- ---------- ---------- ----------
---------- ----------
A1 2 C1 20 50 10 0 0 20 0 0
A2 2 C1 0 0 0 0 0 0 30 0
A2 3 C4 40 0 0 110 70 0 0 0
A3 2 C1 0 0 0 0 0 0 0 20
---------------
删除实体
DROP VIEW RESULT;
DROP
PROCEDURE P_TEST;
DROP TABLE TEST;
Oracle12C—行列转换
-
基础示例
- 示例:查询每个部门中各个职位的总工资
-
分析:本程序所要查询的并不是一个部门的总工资,而是需要统计出各个职位的信息,最简单的做法是直接按照部门编号及职位进行分组统计,于是有了以下的查询语句
- 步骤1:按照部门编号及职位进行分组。此步骤进行了多表连接而后进行数据分组的方式完成的。但这种数据显示的方式不适合用户浏览,因为数据没有规律,而对于数据最好的浏览方式是像普通数据表那样,按照行的方式列出每一种职位的总工资。



- 步骤2:针对不同的职位,应该使用不同的sal内容进行求和的统计,此时只能利用decode()函数完成判断。同时为了让多条记录在同一行上显示,可以针对每一个职位分别统计,对于该职位信息的部门应该使用0进行处理;
|
SELECT deptno, from emp group BY deptno;
|

- 步骤2中的decode函数是Oracle的专有函数,如果不使用此函数的话,就要通过如下的子查询方式来做了
|
SELECT temp.dno, SUM(president_job) , SUM(manager_job) , SUM(analyst_job) , SUM(clerk_job) , SUM(salesman_job) FROM ( SELECT deptno dno , (SELECT SUM(sal) FROM emp WHERE job='PRESIDENT' AND empno=e.empno) PRESIDENT_JOB , (SELECT SUM(sal) FROM emp WHERE job='MANAGER' AND empno=e.empno) MANAGER_JOB , (SELECT SUM(sal) FROM emp WHERE job='ANALYST' AND empno=e.empno) ANALYST_JOB , (SELECT SUM(sal) FROM emp WHERE job='CLERK' AND empno=e.empno) CLERK_JOB , (SELECT SUM(sal) FROM emp WHERE job='SALESMAN' AND empno=e.empno) SALESMAN_JOB FROM emp e ) temp GROUP BY temp.dno ORDER BY temp.dno DESC ;
|

- 此时所完成的是一个基本的行列转换操作功能,并且显示的记录结果也更加清晰,但代码过于复杂;
-
pivot()函数
- 语法
|
select * | 列 [别名]... 统计函数(列)s for转换列名称 in( 内容 1 [ [as]别名], 内容 2 [ [as]别名], ... ) ) [group by 分组字段1,分组字段2,....] [having 过滤条件(s)] |
核心组成说明如下: |
- 示例1:利用pivot()函数实现转换
|
SELECT * FROM (SELECT deptno , job , sal FROM emp) PIVOT ( SUM(sal) FOR job IN ( 'PRESIDENT' AS president_job , 'MANAGER' AS manager_job , 'ANALYST' AS analyst_job , 'CLERK' AS clerk_job , 'SALESMAN' AS salesman_job ) ) ORDER BY deptno ;
|

-
拓展:使用XML与ANY
- 如果在使用pivot()函数时增加了XML显示,可以利用ANY设置所要操作的所有数据
|
SELECT * FROM (SELECT deptno , job , sal FROM emp) PIVOT XML ( SUM(sal) FOR job IN (ANY) ) ORDER BY deptno ; |
- 这样就会以XML的形式显示数据,不过ANY只能用于PIVOT XML操作里,并不能用于之前的PIVOT()函数中
|
|

- 示例2:使用PIVOT()函数只能够完成一种信息的统计,在了解了不同职位的总工资之外,还希望知道部门的人数及最高和最低工资,就需要利用OVER PARTITION BY语句完成
|
SELECT * FROM ( SELECT job ,deptno , sal, SUM(sal) OVER(PARTITION BY deptno) sum_sal , MAX(sal) OVER(PARTITION BY deptno) max_sal , MIN(sal) OVER(PARTITION BY deptno) min_sal FROM emp) PIVOT ( SUM(sal) FOR job IN ( 'PRESIDENT' AS president_job , 'MANAGER' AS manager_job , 'ANALYST' AS analyst_job , 'CLERK' AS clerk_job , 'SALESMAN' AS salesman_job ) ) ORDER BY deptno ;
|

- 示例3:设置多个统计函数,查询每个部门不同职位的总工资,以及每个部门不同职位ide最高工资
|
SELECT * FROM (SELECT deptno , job , sal FROM emp) PIVOT ( SUM(sal) AS sum_sal , MAX(sal) AS sum_max FOR job IN ( 'PRESIDENT' AS president_job , 'MANAGER' AS manager_job , 'ANALYST' AS analyst_job , 'CLERK' AS clerk_job , 'SALESMAN' AS salesman_job ) ) ORDER BY deptno ;
|

-
unpivot()函数
- 首先,使用下面的sql语句更新基础代码:
|
ALTER TABLE emp ADD (sex VARCHAR2(10) DEFAULT '男') ; UPDATE emp SET sex='女' WHERE TO_CHAR(hiredate,'yyyy')='1981' ; COMMIT ; |
- 示例1:设置多个统计列。上面的代码更新后,会在emp表中增加一个性别列,现在要求使用PIVOT()函数针对不同职位的不同性别进行总工资的统计,可以在for语句中设置多个列
|
SELECT * FROM (SELECT deptno , job , sal , sex FROM emp) PIVOT ( SUM(sal) AS sum_sal , MAX(sal) AS sum_max FOR (job, sex) IN ( ('MANAGER','男') AS manager_male_JOB , ('MANAGER','女') AS manager_female_JOB , ('CLERK','男') AS clerk_male_JOB , ('CLERK','女') AS clerk_female_JOB ) ) ORDER BY deptno ;
|

- 通过PIVOT()函数可以将行转换为列,反过来,也可以使用UNPIVOT()函数将列重新转换为行
- UNPIVOT()函数语法:
|
select * | 列 [别名]... 统计函数(列)s for转换列名称 in( 内容1 [[as]别名], 内容2 [[as]别名], .... 内容n [[as]别名], ) ) [where 条件(s)] [group by 分组字段1,分组字段2,....] [having 过滤条件(s)] [order by 排序字段 asc|desc]; |
此函数与pivot()定义类似,不同的地方在于两个选项; |
- 示例2:
|
WITH temp AS ( SELECT * FROM (SELECT deptno , job , sal FROM emp) PIVOT ( SUM(sal) FOR job IN ( 'PRESIDENT' AS PRESIDENT_JOB , 'MANAGER' AS MANAGER_JOB , 'ANALYST' AS ANALYST_JOB , 'CLERK' AS CLERK_JOB , 'SALESMAN' AS SALESMAN_JOB ) ) ORDER BY deptno ) SELECT * FROM temp UNPIVOT ( sal_sum FOR job IN ( president_job AS 'PRESIDENT' , manager_job AS 'MANAGER' , analyst_job AS 'ANALYST' , clerk_job AS 'CLERK' , salesman_job AS 'SALESMAN' ) ) ORDER BY deptno ;
|
|

- 示例3:示例2的查询不包含Null值,可以使用INCLUDE NULLS选项包含null值
|
WITH temp AS ( SELECT * FROM (SELECT deptno , job , sal FROM emp) PIVOT ( SUM(sal) FOR job IN ( 'PRESIDENT' AS PRESIDENT_JOB , 'MANAGER' AS MANAGER_JOB , 'ANALYST' AS ANALYST_JOB , 'CLERK' AS CLERK_JOB , 'SALESMAN' AS SALESMAN_JOB ) ) ORDER BY deptno ) SELECT * FROM temp UNPIVOT INCLUDE NULLS( sal_sum FOR job IN ( president_job AS 'PRESIDENT' , manager_job AS 'MANAGER' , analyst_job AS 'ANALYST' , clerk_job AS 'CLERK' , salesman_job AS 'SALESMAN' ) ) ORDER BY deptno ;
|
|

学问:纸上得来终觉浅,绝知此事要躬行
为事:工欲善其事,必先利其器。
态度:道阻且长,行则将至;行而不辍,未来可期
.....................................................................
------- 桃之夭夭,灼灼其华。之子于归,宜其室家。 ---------------
------- 桃之夭夭,有蕡其实。之子于归,宜其家室。 ---------------
------- 桃之夭夭,其叶蓁蓁。之子于归,宜其家人。 ---------------
=====================================================================
* 博客文章部分截图及内容来自于学习的书本及相应培训课程以及网络其他博客,仅做学习讨论之用,不做商业用途。
* 如有侵权,马上联系我,我立马删除对应链接。 * @author Alan -liu * @Email no008@foxmail.com
转载请标注出处! ✧*꧁一品堂.技术学习笔记꧂*✧. ---> https://www.cnblogs.com/ios9/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号