Oracle迁移Pgsql对应数据
PostgreSQL 12.2 手册
http://postgres.cn/docs/12/index.html
JDBC连接方式
Oracle
连接方式:
1 jdbc连接:db.url=jdbc:oracle:thin:@127.0.0.1:1521:ORCL 2 驱动 : driver-class-name: org.postgresql.Driver
Springboot配置:
1 spring: 2 datasource: 3 url: jdbc:oracle:thin:@127.0.0.1:1521:orcl 4 driver-class-name: oracle.jdbc.driver.OracleDriver 5 username: nms 6 password: nms
Pgsql
连接方式:
1 jdbc连接:jdbc:postgresql://127.0.0.1:5432/dbtest 2 驱动 : driver-class-name: oracle.jdbc.driver.OracleDriver
Springboot配置:
1 spring: 2 datasource: 3 url: jdbc:postgresql://127.0.0.1:5432/dbtest 4 driver-class-name: org.postgresql.Driver 5 username: pgtest 6 password: pg123456
java连接方式:
1 Class.forName("org.postgresql.Driver"); 2 Connection c = DriverManager.getConnection("jdbc:postgresql://10.9.31.33:5432/dbtest", "pgtest", "pg123456"); 3 stmt = c.createStatement(); 4 String sql = "select * from table"; 5 int s= stmt.executeUpdate(sql); 6 stmt.close();
创建数据库用户

创建模式schame
1 create schema authorization username1; 2 SET search_path TO username1;
字符集
PostgreSQL服务端是不支持GBK的,建议用UTF8。PostgreSQL还有个编码EUC CN,这个我们之前测过很多次,有很多生僻字是无法编码的。 比如“瑄”在EUC_CN下就无法编码。因此,不推荐使用EUC_CN。
多行注释
1 /* some comments 2 /* other comments 3 /*******************/ 4 • 上述注释在Oracle中是合法的 5 • 在POSTGRESQL中是非法的 6 • -- 合法的PostgreSQL注释格式: 7 • -- This is a standard SQL comment 8 • /* multiline comment 9 • * with nesting: /* nested comment */ 10 • */ 11 • 可以使用PLY(Python-Lex-Yacc)将注释自动改写掉
数据类型
数据类型修改点
timestamp/date/time null| Oracle | Postgresql |
| Varchar2 | varchar |
| number | numeric |
| date | |
| 不支持boolean,可通过0/1代替 | 支持boolean |
| null |
数据类型
|
|
Oracle |
PGSQL |
|
整数类型 |
integer |
smallint |
|
integer | ||
|
bigint | ||
|
数字类型 |
decimal(P,S) |
decimal |
|
number(P,S) |
numeric | |
|
number(18,2) |
money | |
|
可变长度的字符串 |
varchar2 |
character varying(n), varchar(n) |
|
varchar2(1) |
boolean | |
|
固定长度的字符串 |
char |
character(n), char(n) |
|
日期类型 |
date |
timestamp [ (p) ] [ without time zone ] |
|
timestamp |
timestamp [ (p) ] with time zone | |
|
|
date | |
|
|
time [ (p) ] [ without time zone ] | |
|
|
time [ (p) ] with time zone | |
|
|
interval [ fields ] [ (p) ] | |
|
字符数据 |
clob |
text |
语法区别
| Oracle | Postgresql |
| unique | distinct (查询用select distinct ) |
迁移语法总结
Oracle迁移PostgreSQL数据库经验总结(SQL部分,未完待续),本文只包括了我工作中接触到或者用到的技术点,其实两个数据库设计上的差异是很大的,但是Oracle数据库有的功能,PostgreSQL大体上也都能实现
| 序号 | 项目 | Oracle | PostgreSQL |
| 1 | 当前时间 | SYSDATE | 可全部使用current_timestamp替换 |
| 2 | 序列 | SEQNAME.NEXTVAL | NEXTVAL('SEQNAME') |
| 3 | 固定值列 | SELECT '1' AS COL1 | SELECT CAST('1' AS TEXT) AS COL1 |
| 4 | NVL | NVL函数 | NVL可以用COALESCE函数替换 |
| 5 | 类型自动转换 | Oracle某些情况下支持类型自动转换 | 会出现类型不匹配等错误,需要在Java或者sql中进行类型转换,使类型匹配 |
| 6 | INSTR函数 | instr('str1','str2') | strpos('str1','str2') |
| 7 | 外连接 | Oracle可简写为(+) | 用LEFT JOIN等语句替换 |
| 8 | 层次查询 | START WITH语句 | 用WITH RECURSIVE语句 |
| CONNECT BY语句 | |||
| 9 | 数据库对象大小写 | 不区分大小写 | 创建数据库对象时要小写,这样才不区分SQL的大小写 |
| 10 | 同义词 | Oracle支持同义词 | 用视图代替 |
| 11 | DUAL | SELECT 1+1 FROM DUAL | SELECT 1+1 或者 CREATE VIEW dual AS SELECT current_timestamp |
| 12 | ROWNUM | ROWNUM关键字 | 两种情况: |
| 1.限制结果集数量,用于翻页等: | |||
| SELECT * FROM T LIMIT 5 OFFSET 0 | |||
| 2.生成行号: | |||
| ROW_NUMBER() OVER() | |||
| 13 | DECODE等判断函数 | DECODE() | 用标准的CASE WHEN THEN ELSE END语句替换 |
| 14 | TO_CHAR | TO_CHAR(COL,FMT),格式化字符串可以为空 | TO_CHAR(COL1,'FM999999'),9的个数为字段长度,详细定义见: |
| http://www.postgresql.org/docs/9.4/static/functions-formatting.html | |||
| 15 | TO_NUMBER | TO_NUMBER(COL,FMT),格式化字符串可以为空 | TO_NUMBER(COL1,'999999'),9的个数为字段长度,详细定义见: |
| http://www.postgresql.org/docs/9.4/static/functions-formatting.html | |||
| 16 | NULL和'' | ORACLE认为''等同于NULL | NULL和''不同 |
| 17 | NULL和'' | LENGTH('')为NULL | LENGTH('')为0 |
| 18 | NULL和'' | TO_DATE('','YYYYMMDD')为空 | TO_DATE('','YYYYMMDD')为0001-01-01 BC |
| 19 | NULL和'' | TO_NUMBER('',1)为NULL | TO_NUMBER('',1),报错 |
| 20 | NULL和'' | INSERT INTO TEST(VALUE4)VALUES('') | INSERT INTO TEST(VALUE4)VALUES('') |
| [Result]VALUE4=NULL (注:VALUE3字段为数值类型) | VALUE4=NULL | ||
| 21 | NULL和'' | INSERT INTO TEST(VALUE4)VALUES('') | INSERT INTO TEST(VALUE4)VALUES('') |
| [Result]VALUE4=NULL (注:VALUE3字段为字符类型) | VALUE4='' | ||
| 22 | NULL和'' | INSERT INTO TEST(VALUE4)VALUES(TO_DATE('','YYYYMMDD')) | INSERT INTO TEST(VALUE6)VALUES(TO_DATE('','YYYYMMDD')) |
| [Result]VALUE4=NULL (注:VALUE3字段为时间类型) | [Result]VALUE6=0001-01-01 BC | ||
| 23 | ADD_MONTHS | ADD_MONTHS(DATE,INT) | CREATE FUNCTION add_months(date, int) |
| RETURNS date AS | |||
| 'SELECT ($1 +($2::text||'' month'')::interval)::date' | |||
| LANGUAGE 'sql' | |||
| 或SQL: | |||
| SELECT ($1 +($2::text||' month')::interval) | |||
| 24 | LAST_DAY | LAST_DAY(DATE) | 创建函数来解决 |
| CREATE OR REPLACE FUNCTION last_day(date) | |||
| RETURNS date AS | |||
| SELECT(datetrunc(′MONTH′,$1)+INTERVAL′1MONTH−1day′)::date;SELECT(datetrunc(′MONTH′,$1)+INTERVAL′1MONTH−1day′)::date; | |||
| LANGUAGE 'sql'; | |||
| 或SQL: | |||
| SELECT (date_trunc('MONTH', $1) + interval '1 month - 1 day')::date; | |||
| 25 | MONTHS_BETWEEN | MONTHS_BETWEEN(DATE,DATE) | 创建函数来解决 |
| CREATE FUNCTION MONTH_BETWEEN(d1 timestamp,d2 timestamp) | |||
| RETURNS NUMERIC AS | |||
| 'SELECT (extract(year from age(d1,d2))*12 + extract(month from age(d1,d2)))::integer' | |||
| LANGUAGE 'sql'; | |||
| 26 | BITAND | BITAND(A,B) | A & B |
| 27 | MINUS | MINUS语句 | 以EXCEPT语句来替代 |
| 28 | BIN_ | SELECT BIN_TO_NUM(1,0,1,0) AS VALUE1 FROM DUAL | SELECT CAST(B'1010' AS INTEGER) AS VALUE1 |
| 29 | UPDATE语句列列表 | UPDATE accounts SET (contact_last_name, contact_first_name) =(SELECT last_name, first_name FROM salesmen WHERE salesmen.id = accounts.sales_id); | 不支持该语法,需要拆分为多个单独的列 |
| 30 | SUBSTR函数 | 如果从第一个开始取子串,可以从0开始,也可以从1开始,如果不是第一个开始,则从1开始计数,可以为负值,从字符串结尾计数,用于取最后几位。 | 从1开始计数。如果要取最后几位,可以用RIGHT函数解决。 |
| 31 | 子查询别名 | 如果FROM后只有一个子查询,该子查询可以没有别名 | 必须有别名 |
| 32 | 列(别)名为关键字 | Oracle中比如name,type这样的关键字可以直接作为列的别名,比如:select xx name from t | 需要加as,比如select xx as name from t |
| 33 | 当前登录用户 | SELECT USER FROM DUAL | select current_user |
| 34 | ALL_COL_COMMENTS | 通过SELECT * FROM ALL_COL_COMMENTS可以获得列注释信息 | select s.column_name as COLUMN_NAME,coalesce(col_description(c.oid,ordinal_position) ,s.column_name) as COMMENTS |
| from information_schema.columns s,pg_class c | |||
| where s.table_name = 'ac01_si' and s.table_name = c.relname | |||
| and s.table_schema = current_schema() | |||
| PG需要通过col_description获得列注释信息 | |||
| 35 | 修改表字段类型 | 1.如果字段无数据,可直接修改 | 1.如果新类型和原类型兼容,可直接修改 |
| 2.如果有数据且新类型和原类型兼容,也可以直接修改 | 2.如果不兼容,需要使用USING关键字然后提供一个类型转换的表达式 | ||
| 3.如果不兼容,可通过对原字段改名,然后增加新字段,再通过UPDATE语句对数据进行处理 | |||
Pgsql系统列名:
| 列名 | 含义 |
| oid | 一行的对象标识符(对象ID)。该列只有在表使用WITH OIDS创建时或者default_with_oids配置变量被设置时才存在。该列的类型为oid(与列名一致)。tableoid |
| tableoid | 包含这一行的表的OID。该列是特别为从继承层次中选择的查询而准备,因为如果没有它将很难知道一行来自于哪个表。tableoid可以与pg_class的oid列进行连接来获得表的名称。 |
| xmin | 插入该行版本的事务身份(事务ID)。一个行版本是一个行的一个特别版本,对一个逻辑行的每一次更新都将创建一个新的行版本。 |
| cmin | 插入事务中的命令标识符(从0开始)。 |
| xmax | 删除事务的身份(事务ID),对于未删除的行版本为0。对于一个可见的行版本,该列值也可能为非零。这通常表示删除事务还没有提交,或者一个删除尝试被回滚。 |
| cmax | 删除事务中的命令标识符,或者为0。 |
| ctid | 行版本在其表中的物理位置。注意尽管ctid可以被用来非常快速地定位行版本,但是一个行的ctid会在被更新或者被VACUUM FULL移动时改变。因此,ctid不能作为一个长期行标识符。OID或者最好是一个用户定义的序列号才应该被用来标识逻辑行。 |
| 修改前 | 修改后 |
| tableoid | “tableoid” |
| FREEZE | ”FREEZE“ |
| Using | “Using” |
| cTID | “cTID” |
PostgreSQL: 系统字段
在 PostgreSQL 中,当我们创建一个数据表时,数据库会隐式增加几个系统字段。这些字段由系统进行维护,用户一般不会感知它们的存在。例如,以下语句创建了一个简单的表:
从定义上来看,表 test 中只有一个字段;但是当我们查询数据字典表 pg_attribute 时,结果却不是如此:
1 hrdb=> select version(); 2 version 3 --------------------------------------------------------------------------------------------------------- 4 PostgreSQL 12.3 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39), 64-bit 5 (1 row) 6 7 hrdb=> select attname, attnum, atttypid::regtype 8 hrdb-> from pg_attribute 9 hrdb-> where attrelid = 'test'::regclass; 10 attname | attnum | atttypid 11 ----------+--------+---------- 12 tableoid | -6 | oid 13 cmax | -5 | cid 14 xmax | -4 | xid 15 cmin | -3 | cid 16 xmin | -2 | xid 17 ctid | -1 | tid 18 col | 1 | integer 19 (7 rows) 20
查询结果显示,表 test 中一共包含 7 个字段。PostgreSQL 为我们增加了 6 个额外的系统字段,它们的 attnum 属性都是负数。
下面让我们分别看看这些系统字段的作用。
tableoid
tableoid 字段代表了数据所在表的对象 id(OID),也就是数据字典表 pg_class 中与该表信息相关的数据行。
1 hrdb=> select oid, relname from pg_class where relname = 'test'; 2 oid | relname 3 -------+--------- 4 90277 | test 5 (1 row) 6 7 hrdb=> select t.tableoid, t.col, c.relname 8 hrdb-> from test t 9 hrdb-> join pg_class c on (c.oid = t.tableoid); 10 tableoid | col | relname 11 ----------+-----+--------- 12 90277 | 1 | test 13 90277 | 2 | test 14 90277 | 3 | test 15 (3 rows) 16tableoid 的另一个用途就是在涉及分区表查询或者 UNION 操作时标识数据行所在的具体表。例如存在以下分区表:
1 create table part_t 2 (id integer) partition by hash (id); 3 create table part_t_p1 4 partition of part_t for values with (modulus 4, remainder 0); 5 create table part_t_p2 6 partition of part_t for values with (modulus 4, remainder 1); 7 create table part_t_p3 8 partition of part_t for values with (modulus 4, remainder 2); 9 create table part_t_p4 10 partition of part_t for values with (modulus 4, remainder 3); 11 12 insert into part_t select generate_series(1,100); 13
我们可以通过以下查询返回每行数据所在的分区
1 hrdb=> select tableoid::regclass, id 2 hrdb-> from part_t 3 hrdb-> order by id 4 hrdb-> limit 10; 5 tableoid | id 6 -----------+---- 7 part_t_p1 | 1 8 part_t_p3 | 2 9 part_t_p2 | 3 10 part_t_p4 | 4 11 part_t_p2 | 5 12 part_t_p4 | 6 13 part_t_p4 | 7 14 part_t_p2 | 8 15 part_t_p2 | 9 16 part_t_p4 | 10 17 (10 rows) 18
对于集合操作 UNION、INTERSECT、EXCEPT 也是如此:
1 hrdb=> select tableoid::regclass, col from test 2 hrdb-> union all 3 hrdb-> select tableoid::regclass, id from part_t where id < 4 4 hrdb-> order by 2; 5 tableoid | col 6 -----------+----- 7 test | 1 8 part_t_p1 | 1 9 test | 2 10 part_t_p3 | 2 11 test | 3 12 part_t_p2 | 3 13 (6 rows) 14
ctid
ctid 字段代表了数据行在表中的物理位置,也就是行标识(tuple identifier),由一对数值组成(块编号和行索引)。ctid 类似于 Oracle 中的伪列 ROWID。ctid 可以用于快速查找表中的数据行,也可以用于修复数据损坏。另外,它也可以用于查找并删除表中的重复数据。例如:
1 insert into test(col) 2 values (1),(2),(3); 3 4 hrdb=> select ctid, * from test; 5 ctid | col 6 -------+----- 7 (0,1) | 1 8 (0,2) | 2 9 (0,3) | 3 10 (0,4) | 1 11 (0,5) | 2 12 (0,6) | 3 13 (6 rows) 14我们为 test 表插入了 3 条重复的数据。接下来利用 ctid 删除重复的数据:
1 hrdb=> delete from test 2 hrdb-> where ctid not in 3 hrdb-> ( 4 hrdb(> select max(ctid) 5 hrdb(> from test 6 hrdb(> group by col 7 hrdb(> ); 8 DELETE 3 9
需要注意的是,ctid 的值有可能会改变(例如 VACUUM FULL);因此,ctid 不适合作为一个长期的行标识,应该使用主键作为行的逻辑标识。
xmin
xmin 代表了该行版本(row version )的插入事务 ID(XID)。行版本是数据行的具体状态,每次更新操作都会为相同的逻辑行创建一个新的行版本(多版本并发控制,MVCC)。事务 ID 是一个 32 bit 数字。我们继续为 test 表插入几条数据,并查看它们的 xmin:
1 hrdb=> insert into test(col) values(4); 2 INSERT 0 1 3 hrdb=> insert into test(col) values(5); 4 INSERT 0 1 5 6 hrdb=> select xmin,col from test; 7 xmin | col 8 ------+----- 9 2852 | 1 10 2852 | 2 11 2852 | 3 12 2854 | 4 13 2855 | 5 14 (5 rows) 15xmin 字段可以用于查看数据行的插入时间:
1 hrdb=> select col, 2 hrdb-> to_char(pg_xact_commit_timestamp(xmin) ,'YYYY-MM-DD HH24:MI:SS') AS insert_time 3 hrdb-> from test; 4 col | insert_time 5 -----+--------------------- 6 1 | 2020-05-28 16:52:08 7 2 | 2020-05-28 16:52:08 8 3 | 2020-05-28 16:52:08 9 4 | 2020-05-28 17:03:33 10 5 | 2020-05-28 17:03:35 11 (5 rows) 12
注意,系统函数 pg_xact_commit_timestamp 需要将配置参数 track_commit_timestamp 设置为 on 才能使用。
xmax
xmax 字段代表了删除改行的事务 ID,对于未删除的行版本显示为 0。非零的 xmax 通常意味着删除事务还没有提交,或者删除操作被回滚。我们查看一下 test 表中的 xmax:
1 hrdb=> select txid_current(); 2 txid_current 3 -------------- 4 2858 5 (1 row) 6 7 hrdb=> select xmax, col from test; 8 xmax | col 9 ------+----- 10 0 | 1 11 0 | 2 12 0 | 3 13 0 | 4 14 0 | 5 15 (5 rows) 16
然后打开另一个会话,在事务中修改 test 表中的数据:
回到第一个会话,再次查看 xmax:
1 hrdb=> select xmax, col from test; 2 xmax | col 3 ------+----- 4 2858 | 1 5 2858 | 2 6 2858 | 3 7 2858 | 4 8 2858 | 5 9 (5 rows) 102858 是第二个会话的事务 ID,它是删除这些行版本的事务。PostgreSQL 中的 UPDATE 相当于 DELETE 加 INSERT。
将第二个事务回滚:
如果再次查询 test 表中的 xmax,仍然返回 2858。
xmax 还有可能表示当前正在占用行锁的事务 ID,利用 PostgreSQL 扩展插件 pageinspect 可以获取详细信息:
1 create extension pageinspect; 2 3 select t.col, 4 t.xmax 5 case 6 when (t_infomask & 128)::boolean then 'LOCK' 7 when (t_infomask & 1024)::boolean then 'COMMITTED' 8 when (t_infomask & 2048)::boolean then 'ROLLBACKED' 9 when (t_infomask & 4096)::boolean then 'MULTI XACT' 10 end as xmax_info 11 from test t 12 left outer join heap_page_items(get_raw_page('test', 0)) hp on (t.ctid = hp.t_ctid) 13 where hp.t_xmax = t.xmax; 14cmin
cmin 代表了插入事务中的命令标识符(从 0 开始)。命令标识符是一个 32 bit 数字。
cmax
cmax 代表了删除事务中的命令标识符,或者 0。
我们先查看一下 test 表中的
1 hrdb=> select cmin, cmax, col from test; 2 cmin | cmax | col 3 ------+------+----- 4 0 | 0 | 1 5 0 | 0 | 2 6 0 | 0 | 3 7 0 | 0 | 4 8 0 | 0 | 5 9 (5 rows) 10然后在事务中修改数据:
1 hrdb=> begin; 2 BEGIN 3 hrdb=> select txid_current(); 4 txid_current 5 -------------- 6 2859 7 (1 row) 8 9 hrdb=> insert into test(col) values(6); 10 INSERT 0 1 11 hrdb=> insert into test(col) values(7); 12 INSERT 0 1 13 hrdb=> insert into test(col) values(8); 14 INSERT 0 1 15 16 hrdb=> select cmin, cmax, col from test; 17 cmin | cmax | col 18 ------+------+----- 19 0 | 0 | 1 20 0 | 0 | 2 21 0 | 0 | 3 22 0 | 0 | 4 23 0 | 0 | 5 24 0 | 0 | 6 25 1 | 1 | 7 26 2 | 2 | 8 27 (8 rows) 28然后删除一条记录:
此时,从另一个会话中查看:
1 -- 会话 2 2 hrdb=> select cmin, cmax, col from test; 3 cmin | cmax | col 4 ------+------+----- 5 3 | 3 | 1 6 0 | 0 | 2 7 0 | 0 | 3 8 0 | 0 | 4 9 0 | 0 | 5 10 (5 rows) 11
oid
如果使用 PostgreSQL 11 或者更早版本,还有一个隐藏的系统字段:oid。它代表了数据行的对象 ID,只有当创建表时使用了 WITH OIDS 选项或者配置参数 default_with_oids 设置为 true 时才会创建这个字段。从 PostgreSQL 12 开始,不再支持 WITH OIDS 选项,oid 只用于系统内部。
总结
PostgreSQL 中的每个表都包含了 6 个隐藏的系统字段,可以用于获取关于数据行的一些内部信息。这些字段名称不能用于创建普通的字段,即使使用双引号包含也不可以
————————————————
pgsql语法
用 ALTER TABLE 在一张已存在的表上添加列的语法如下:
在一张已存在的表上 DROP COLUMN(删除列),语法如下:
修改表中某列的 DATA TYPE(数据类型),语法如下:
给表中某列添加 NOT NULL 约束,语法如下:
添加新列,并设默认值:
添加多列:
1 alter table table add colname1 NUMERIC(5) default 9 not null, add colname2 NUMERIC(5) default 0 not null;
类型转化:
分页查询:
1 ----row_number() OVER():查询行号 2 --pages : 单页数 3 --start : 起始位置 4 5 SELECT 6 * 7 --,ROW_NUMBER ( ) OVER ( ) 8 FROM 9 DBNMSVER 10 ORDER BY 11 createtime DESC, 12 labelNo DESC 13 LIMIT 5 OFFSET 10; 14
表空间
Oracle 创建表空间:
1 create tablespace DATA_128 datafile '/opt/oracle/db02/oradata/orcl/DATA_128.dbf'size 1000M online; 2
oracle表空间操作详解
1 ----1.创建表空间: 2 3 create tablespace <tablespace_name> datafile '<filepath>' size filesize autoextend on next <autosize> maxsize <maxsize [unlimited]> 4 5 ----eg: 6 7 create tablespace sales datafile 'c:\1.txt' size 10m autoextend on next 1m maxsize 100m 8 9 ----2.为表空间增加数据文件: 10 11 alter tablespace <tablespace_name> add datafile 'filepath' size <filesize> autoextend on next <autosize> maxsize filemaxsize[unlimited]; 12 13 ----eg: 14 15 alter tablespace users add datafile '/opt/oracle/oradata/ge01/users06.dbf' size 100m autoextend on next 10m maxsize unlimited; 16 17 ----3.调整表空间: 18 19 alter database datafile 'filepath' resize <filesize>;--重置表空间的大小 20 21 ----eg: 22 23 alter database datafile 'c:\2.txt' resize 10m 24 25 ----在实际使用中我们经常会遇到oracle某个表空间占用了大量的空间而其中的数据量却只占用了少量空间,此时我们可以用ALTER DATABASE DATAFILE '***.dbf' RESIZE nnM的命令来收缩表空间,但在收缩的过程中会遇到ora-03297错误,表示在所定义的空间之后有数据存在,不能收缩,此时的解决办法有: 26 27 ----(1). 先估算该表空间内各个数据文件的空间使用情况: 28 29 SQL>select file#,name from v$datafile; 30 31 SQL>select max(block_id) from dba_extents where file_id=11; 32 33 MAX(BLOCK_ID) 34 ------------- 35 13657 36 37 SQL>show parameter db_block_size 38 39 NAME TYPE VALUE 40 ----------------------------- ------- ----------- db_block_size integer 8192 41 SQL>select 13657*8/1024 from dual; 42 43 13657*8/1024 44 ----------- 45 106.695313 46 47 ----这说明该文件中最大使用块位于106M与107M之间, 48 49 SQL> alter database datafile '/ora_data/cninsite/insitedev02.dbf' resize 100M; 50 alter database datafile '/ora_data/cninsite/insitedev02.dbf' resize 100M 51 * 52 ERROR at line 1: 53 ORA-03297: file contains used data beyond requested RESIZE value 54 55 SQL> alter database datafile '/ora_data/cninsite/insitedev02.dbf' resize 107M; 56 57 Database altered. 58 59 ----(2).如果某些表占用了数据文件的最后一些块,则需要先将该表导出或移动到其他的表空间中,然后删除表,再进行收缩。不过如果是移动到其他的表空间,需要重建其索引。 60 61 SQL> alter table t_obj move tablespace t_tbs1; 62 63 ----4.关闭表空间的自动扩展属性: 64 65 alter database datafile 'filepath' autoextend off 66 67 eg: 68 69 alter database datafile 'c:\2.txt' autoextend off 70 71 ----5.打开表空间的自动扩展属性: 72 73 alter database datafile 'filepath' autoextend on 74 75 eg: 76 77 alter database datafile 'c:\2.txt' autoextend on 78 79 ----6.使表空间脱机: 80 81 alter tablespace tablespace_name offline 82 83 ----7.使表空间联机: 84 85 alter tablespace tablespace_name online 86 87 ----8.设置表空间为只读: 88 89 alter tablespace tablespace_name read only 90 91 ----9.设置表空间为读写: 92 93 alter tablespace tablespace_name read write 94 95 ----11.删除表空间: 96 97 drop tablespace <tablespace_name> 98 99 ----12.删除表空间的同时,删除数据文件 100 drop tablespace tablespace_name including contents and datefiles 101 ----使用offline数据文件的方法 102 ----非归档模式使用: 103 alter database datafile '...' offline drop; 104 ----归档模式使用: 105 alter database datafile '...' offline; 106 ----说明: 107 ----1) 以上命令只是将该数据文件OFFLINE,而不是在数据库中删除数据文件。该数据文件的信息在控制文件种仍存在。查询v$datafile,仍显示该文件。 108 ----2) 归档模式下offline和offline drop效果是一样的 109 ----3) offline后,存在此datafile上的对象将不能访问 110 ----4) noarchivelog模式下,只要online redo日志没有被重写,可以对这个文件recover后进行online操作 111 112 ----Oracle 10G R2开始,可以采用:Alter tablespace tablespace_name drop datafile file_name;来删除一个空数据文件,并且相应的数据字典信息也会清除: 113 ----确认表空间文件信息: 114 SQL> select file_name,file_id from dba_data_files where tablespace_name='USERS'; 115 ----确认表空间未被存储占用: 116 SQL> select segment_name,file_id,blocks from dba_extents where file_id=5; 117 no rows selected 118 119 alter tablespace users drop datafile '/opt/oracle/oradata/ge01/users04.dbf'; 120 121 ----oracle 10g可以删除临时表空间的文件 122 alter database tempfile '/home/oracle/temp01.dbf' drop including datafiles 123 124 ----13.查看每个表空间占用空间的大小: 125 126 select tablespace_name,sum(bytes)/1024/1024 from dba_segments group by tablespace_name 127 128 ----10.oracle中如何移动控制文件,数据文件,日志文件 129 130 ----oracle9i/10G-xG中移动控制文件,数据文件,日志文件 131 132 ----ORACLE数据库由数据文件,控制文件和联机日志文件三种文件组成。 133 ----windows环境中用: host copy 或 host move 其它均相同。 134 ----以下是unix或linux环境中, 135 136 ---- 一.移动数据文件: 137 138 ALTER TABLESPACE方法(联机状态): 139 ----用此方法,要求此数据文件既不属于SYSTEM表空间,也不属于含有ACTIVE回滚段或临时段的表空间。 140 $ sqlplus '/as sysdba' 141 ----#把需要移动的数据文件对应的表空间offline 142 SQL> alter tablespace ipas_acct_data offline 143 ----#把数据文件cp到想要放的目录下。 144 SQL> !mv /opt/oracle/wacosdata/ipas_acct_data001.dbf /opt/oracle/nms/oradata/ipas_acct_data001.dbf 145 ----#修改表空间中数据库文件的位置。 146 SQL> alter tablespace ipas_acct_data rename datafile '/opt/oracle/wacosdata/ipas_acct_data001.dbf' to '/opt/oracle/nms/oradata/ipas_acct_data001.dbf' 147 ----#把表空间online。 148 SQL> alter tablespace ipas_acct_data online 149 ----#查看修改结果。 150 SQL> select file_name from dba_data_files where tablespace_name = 'IPAS_ACCT_DATA'; 151 152 ----ALTER DATABASE方法(脱机状态): 153 ----用此方法,可以移动任何表空间的数据文件。 154 $ sqlplus '/as sysdba' 155 SQL> shutdown immediate 156 SQL> !mv /opt/oracle/oradata/wacos002.dbf /ora10g/oradata/wacos002.dbf 157 SQL> startup mount 158 SQL> alter database rename file '/opt/oracle/oradata/wacos002.dbf' to '/ora10g/oradata/wacos002.dbf'; 159 SQL> alter database open; 160 SQL> set head off 161 SQL> SELECT file_name from dba_data_files where tablespace_name = 'WACOS'; 162 163 ----二. 移动控制文件: 164 165 $ sqlplus '/as sysdba' 166 ----#我是用的spfile启动的,spfile文件不能修改,所以要做这一步。 167 SQL> create pfile from spfile 168 ----#关闭数据库。 169 SQL> shutdown immediate 170 ----#cp控制文件到目标位置。 171 SQL>cp /opt/oracle/oradata/control* /opt/oracle/oratest/ 172 ----修改$ORACLE_HOME/dbs/init$ORACLE_SID.ora 文件中的控制文件的位置。 173 ----#启动数据库指定参数文件。 174 SQL> startup pfile='/opt/oracle/product/9.2.0.4/dbs/init$ORACLE_SID.ora' 175 ----#下次启动数据库是直接就可以用startup启动了。 176 SQL> create spfile from pfile; 177 178 ----三. 移动重做日志文件: 179 180 $ sqlplus '/as sysdba' 181 ----#关闭数据库。 182 SQL> shutdown immediate 183 ----#cp日志文件到目标位置。 184 SQL> !cp /opt/oracle/oradata/redo* /opt/oracle/oratest/ 185 ----#让数据库以mount模式启动。 186 SQL>startup mount; 187 ----#修改数据库中日志文件的位置。 188 SQL> alter database rename file '/opt/oracle/oradata/redo01.log' to '/opt/oracle/oratest/redo01.log' 189 SQL> alter database rename file '/opt/oracle/oradata/redo02.log' to '/opt/oracle/oratest/redo02.log' 190 SQL> alter database rename file '/opt/oracle/oradata/redo03.log' to '/opt/oracle/oratest/redo03.log' 191 ----#修改数据库的状态。 192 SQL> alter database open; 193 ----#查看修改结果。 194 SQL> select * from v$logfile; 195 196 ----增加重做日志文件 197 alter database add logfile 'D:\oracle\oradata\ge01\redo04.log' size 100M; 198 199 ----==================================================================================== 200 ----注意:TEMP数据文件不能移动,只能通过重建临时表空间来重建,方法如下: 201 ----尤其值得注意:重建临时表空间的大小一定要足够大,一定要大于或等于现有临时表空间的大小,否则会出现:提示:无法通过128(在表空间temp中)扩展 temp段。 202 ----==================================================================================== 203 ----Oracle9i为我们提供了一个全局的临时表空间。有的时候我们会发现在做了大量的排序操作后,temp表空间并没有去释放,而且在更大的程度上面占用了我们的磁盘空间,其实我们可以通过重建或者切换的手段来使我们的temp表空间得到重生。 204 205 ----首先我们可以先看一下,当前用户所属的临时表空间有那些 206 SQL> select username ,temporary_tablespace from dba_users; 207 208 USERNAME TEMPORARY_TABLESPACE 209 ------------------------------ ------------------------------ 210 SYS TEMP 211 SYSTEM TEMP 212 DBSNMP TEMP 213 HUJINPEI TEMP 214 ALAN1 TEMP 215 PERFUSER TEMP 216 ALAN2 TEMP 217 MYUSER TEMP 218 OUTLN TEMP 219 WMSYS TEMP 220 221 已选择10行。 222 223 ----查看当前有那些临时文件 224 SQL> select name from v$tempfile; 225 226 NAME 227 -------------------------------------------------------------------------------- 228 D:\ORACLE\ORADATA\ICMNLSDB\TEMP_01.DBF 229 D:\ORACLE\ORADATA\ICMNLSDB\TEMP_02.DBF 230 231 ----为了切换这个临时文件,我们可以重新建立一个临时表空间 232 SQL> create temporary tablespace temp2 tempfile 'D:\ORACLE\ORADATA\ICMNLSDB\TEMP01.DBF' size 10M ; 233 234 ----表空间已创建。 235 236 SQL> alter tablespace temp2 add tempfile 'D:\ORACLE\ORADATA\ICMNLSDB\TEMP02.DBF' size 10M; 237 238 ----表空间已更改。 239 240 ----这个时候我们就可以将刚刚建好的TEMP表空间设置为我们数据库默认的临时表空间: 241 SQL> alter database default temporary tablespace temp2; 242 243 数据库已更改。 244 245 SQL> select username,temporary_tablespace from dba_users; 246 247 USERNAME TEMPORARY_TABLESPACE 248 ------------------------------ --------------------------- 249 SYS TEMP2 250 SYSTEM TEMP2 251 DBSNMP TEMP2 252 HUJINPEI TEMP2 253 ALAN1 TEMP2 254 PERFUSER TEMP2 255 ALAN2 TEMP2 256 MYUSER TEMP2 257 OUTLN TEMP2 258 WMSYS TEMP2 259 260 已选择10行。 261 262 ----当然我们还可以选择DROP掉以前旧的TEMP的表空间 263 SQL> drop tablespace temp including contents ; 264 265 表空间已丢弃。 266 267 ----11.查询表空间的信息: 268 269 select tablespace_name,bytes/1024/1024 file_size_mb,file_name from DBA_DATA_FILES 270 ------注意数据库中的实体都是以大写表示 271 272 ----12 如果在数据库创建期间没有指定默认表空间,它将默认为 SYSTEM。但您如何才能知道现有的数据库的默认表空间是哪一个?发出以下查询: 273 SELECT PROPERTY_VALUE FROM DATABASE_PROPERTIES WHERE PROPERTY_NAME = 'DEFAULT_PERMANENT_TABLESPACE'; 274 ----DATABASE_PROPERTIES 视图显示默认表空间之外,还显示一些非常重要的信息 — 例如默认临时表空间、全局数据库名、时区等 275 276 ----13 在 Oracle Database 10g 中,您可以类似地为用户指定一个默认表空间。在数据库创建期间,REATE DATABASE 命令可以包含子句 DEFAULT TABLESPACE 。在创建之后,您可以通过发出以下命令来使一个表空间变成默认表空间: 277 278 ALTER DATABASE DEFAULT TABLESPACE <tsname>; 279 ----14 重命名一个表空间 280 281 ----在数据仓库环境中(典型地,对于数据中心体系结构),在数据库之间传输表空间是很常见的。但源数据库和目标数据库必须不存在拥有相同名称的表空间。如果存在两个拥有相同名称的表空间,则目标表空间中的段必须转移到一个不同的表空间中,然后重新创建这个表空间— 这个任务说起来容易做起来难。 282 283 ----Oracle Database 10g 提供了一个方便的解决方案:您可以用以下命令来简单地重命名一个现有的表空间(SYSTEM 和 SYSAUX 除外) — 无论是永久表空间还是临时表空间: 284 285 ALTER TABLESPACE <oldname> RENAME TO <newname>; 286 287 ----Oracle 10g临时表空间组 288 ----Oracle 10g 引进了临时表空间组(temporary tablespace group)的概念,它允许用户在不同的会话中同时利用多个临时表空间。 289 290 ----1. 临时表空间组的主要特征 291 292 ---- 一个临时表空间组必须由至少一个临时表空间组成,并且无明确的最大数量限制。 293 294 ---- 如果删除了一个临时表空间组的所有成员,该组也自动被删除。 295 296 ---- 临时表空间的名字不能与临时表空间组的名字相同。 297 298 ---- 在给用户分配一个临时表空间时,可以使用临时表空间组的名字代替实际的临时表空间名;在给数据库分配默认临时表空间时也可以使用临时表空间组的名字。 299 300 ----2. 临时表空间组的优点 301 302 ----使用临时表空间组而非普通的临时表空间,有如下好处: 303 304 ---- 由于SQL查询可以并发使用几个临时表空间进行排序操作,因此SQL查询很少会出现排序空间超出,避免当临时表空间不足时所引起的磁盘排序问题。 305 306 ---- 可以在数据库级指定多个默认临时表空间。 307 308 ---- 一个并行操作的并行服务器将有效地利用多个临时表空间。 309 310 ---- 一个用户在不同会话中可以同时使用多个临时表空间。 311 312 ----3. 管理临时表空间组 313 314 ----临时表空间组是在创建临时表空间时通过指定GROUP字句创建的。可以将一个表空间从一个组移动另一个组,或是从一个组中删除临时表空间,或是往组里添加新的表空间。 315 316 ----1). 创建临时表空间组 317 318 ----创建临时表空间时指定GROUP: 319 320 CREATE SMALLFILE 321 TEMPORARY TABLESPACE "TEMP01" 322 TEMPFILE 323 '/opt/oracle/oradata/ge01/temp_tbs_01a.dbf' SIZE 5M REUSE 324 AUTOEXTEND ON NEXT 640K MAXSIZE UNLIMITED 325 EXTENT MANAGEMENT LOCAL 326 UNIFORM. SIZE 1M 327 TABLESPACE GROUP TBS_GROUP_1 328 GO 329 330 CREATE SMALLFILE 331 TEMPORARY TABLESPACE "TEMP02" 332 TEMPFILE 333 '/opt/oracle/oradata/orcl/temp_tbs_02a.dbf' SIZE 5M REUSE 334 AUTOEXTEND ON NEXT 640K MAXSIZE UNLIMITED 335 EXTENT MANAGEMENT LOCAL 336 UNIFORM. SIZE 1M 337 TABLESPACE GROUP TBS_GROUP_1 338 GO 339 340 CREATE SMALLFILE 341 TEMPORARY TABLESPACE "TEMP03" 342 TEMPFILE 343 '/u01/app/oracle/oradata/orcl/temp_tbs_03a.dbf' SIZE 5M REUSE 344 AUTOEXTEND ON NEXT 640K MAXSIZE UNLIMITED 345 EXTENT MANAGEMENT LOCAL 346 UNIFORM. SIZE 1M 347 TABLESPACE GROUP TBS_GROUP_2 348 GO 349 350 CREATE SMALLFILE 351 TEMPORARY TABLESPACE "TEMP04" 352 TEMPFILE 353 '/u01/app/oracle/oradata/orcl/temp_tbs_04a.dbf' SIZE 5M REUSE 354 AUTOEXTEND ON NEXT 640K MAXSIZE UNLIMITED 355 EXTENT MANAGEMENT LOCAL 356 UNIFORM. SIZE 1M 357 TABLESPACE GROUP TBS_GROUP_2 358 GO 359 360 ----2)、修改数据库默认临时表空间 361 362 alter database default temporary tablespace TBS_GROUP_1; 363 364 ----3)、临时表空间组无法显式创建,当第一个临时表空间分配给该组时自动创建,当组内所有临时表空间被移除时自动删除 365 366 ----注意:从Oracle10gR2开始,使用RMAN恢复数据库之后,Oracle会自动重新创建临时文档,由于临时文档是Sparse File,所以创建会很迅速,通常您不会感觉得到。 367 368 ----一个重要的包DBMS_SPACE_ADMIN: 369 370 ----这个包为本地管理的所有表空间提供带有故障诊断和修复功能的管理程序。 371 372 ----包含的管理程序有: 373 374 ----SEGMENT_VERIFY:验证该段盘区映射的一致性 375 376 ----SEGMENT_CURRUPT:标注该段为损坏或有效,以便执行恰当的错误恢复 377 378 ----SEGMENT_DROP_CORRUPT:取消一个当前标注为损坏的段(不回收空间) 379 380 ----SEGMENT_DUMP:卸下一个给定段的段头部和盘区映射 381 382 ----TABLESPACE_VERIFY:验证该表空间中段的位图和盘区映射是否同步 383 384 ----TABLESPACE_REBUILD_BITMAPS: 重建适当的位图 385 386 ----TABLESPACE_FIX_BITMAPS:在位图中标注适当的数据块地址范围为空闲或已用 387 388 ----vTABLESPACE_REBUILED_QUOTAS:为给定表空间重建限额 389 390 ----TABLESPACE_MIGERATE_FROM_LOCAL:将一个本地管理的表空间移植为字典管理的表空间 391 392 ----TABLESPACE_MIGRATE_TO_LOCAL:将一个字典管理的表空间移植为本地管理的表空间 393 394 ----TABLESPACE_RELOCATE_BITMAPES:将位图重定位到指定的目的地 395 396 ----TABLESPACE_FIX_SEGMENT_STATES:修改移植被放弃的表空间中数据段的状态 397 398 ----一些有关表空间信息的表或视图: 399 400 ----V$TABLESPACE:来自控制文件的所有表空间的名称和编号 401 402 ----DBA_TABLESPACE,USER_TABLESPACE:所有用户的表空间说明 403 404 ----DBA_SEGMENTS,USER_SEGMENTS:所有用户表空间种段的信息 405 406 ----DBA_EXTENTS,USER_EXTENTS:所有用户表空间中数据盘区的信息 407 408 ----DBA_FREE_SPACE,USER_FREE_SPACE:所有用户表空间中的空闲盘区的信息 409 410 ----V$DATAFILE:关于所有数据文件的信息,包括所属表空间和表空间号 411 412 ----V$TEMPFILE:关于所有临时文件的信息,包括所属表空间和表空间号 413 414 ----DBA_DATA_FILES:显示属于表空间的数据文件 415 416 ----DBA_TEMP_FILES:显示属于表空间的临时文件 417 418 ----V$TEMP_EXTENT_MAP:所有本地管理的临时表空间中所有盘区的信息 419 420 ----V$TEMP_EXTENT_POOL:由每个实例缓存和使用临时表空间(本地管理的)的状态 421 422 ----V$TEMP_SPACE_HEADER:显示每个临时文件的已用/空闲空间 423 424 ----DBA_USERS:所有用户默认的和临时表空间 425 426 ----DBA_TS_QUOTAS:列出所有用户表空间限额 427 428 ----V$SORT_SEGMENT:关于一个给定实例的每个排序段的信息,只有在表空间是TEMPOARY:类型时更新 429 430 ----V$SORT_USER:用户使用的临时排序空间和临时的/永久的表空间
Pgsql 表空间:
postgresql 表空间创建、删除
1 -----postgresql 表空间创建、删除 2 -----表空间:字面上理解就是表存储的物理空间,其实包括数据库的表、索引、序列等。 3 4 -----可以将表空间创建在服务器的不同分区,这样做的好处有: 5 6 ----- 一、如果初始化集群所在分区已经用光,可以方便的其他分区上创建表空间已达到扩容的目的。 7 8 ----- 二、对于频繁访问的数据可以存储在性能较高、较快的磁盘分区上,而不常用的数据存储在便宜的较慢的磁盘分区上。 9 10 11 12 ----- 语法: 13 14 postgres=# \h create tablespace 15 Command: CREATE TABLESPACE 16 Description: define a new tablespace 17 Syntax: 18 CREATE TABLESPACE tablespace_name 19 [ OWNER user_name ] 20 LOCATION 'directory' 21 [ WITH ( tablespace_option = value [, ... ] ) ] 22 23 ----- 用户必须有表空间所在目录访问权限,所以在创建表空间之前需要在对应分区下创建相应的目录,并为其分配权限。 24 25 [root@localhost ~]# mkdir /usr/local/pgdata 26 [root@localhost ~]# chown postgres:postgres /usr/local/pgdata/ 27 28 29 30 ----- 创建表空间示例: 31 32 postgres=# create tablespace tbs_test owner postgres location '/usr/local/pgdata'; 33 CREATE TABLESPACE 34 35 36 ----- 创建表空间成功后,可在数据库集群目录下看到一个新增的目录pg_tblspc下有一个连接文件51276,指向到/usr/local/pgdata下 37 38 [root@localhost ~]# ll /mnt/syncdata/pgsql941/data/pg_tblspc/ 39 total 0 40 lrwxrwxrwx. 1 postgres postgres 17 Aug 30 02:06 51276 -> /usr/local/pgdata 41 42 43 [root@localhost ~]# ll /usr/local/pgdata/ 44 total 4 45 drwx------. 2 postgres postgres 4096 Aug 30 02:06 PG_9.4_201409291 46 ----- 在此表空间内创建表: 47 48 postgres=# create table test(a int) tablespace tbs_test; 49 CREATE TABLE 50 ----- 现在在表空间目录下就会新增一个test表对应的文件: 51 52 [root@localhost ~]# ll /usr/local/pgdata/PG_9.4_201409291/13003/51277 53 -rw-------. 1 postgres postgres 0 Aug 30 02:15 /usr/local/pgdata/PG_9.4_201409291/13003/51277 54 55 56 57 ----- 其中51277对应的是test表的relfilenode,13003是数据库postgres的oid。 58 59 60 postgres=# select oid,datname from pg_database where datname = 'postgres'; 61 oid | datname 62 -------+---------- 63 13003 | postgres 64 (1 row) 65 66 postgres=# select relname,relfilenode from pg_class where relname='test'; 67 relname | relfilenode 68 ---------+------------- 69 test | 51277 70 (1 row) 71 72 73 74 ----- 删除表空间: 75 76 postgres=# \h drop tablespace 77 Command: DROP TABLESPACE 78 Description: remove a tablespace 79 Syntax: 80 DROP TABLESPACE [ IF EXISTS ] name 81 82 83 84 ----- 删除表空间前必须要删除该表空间下的所有数据库对象,否则无法删除。 85 86 如: 87 88 postgres=# drop tablespace if exists tbs_test; 89 ERROR: tablespace "tbs_test" is not empty 90 91 92 ----- 删除刚才在此表空间创建的表test,然后再删除表空间。 93 94 postgres=# drop table if exists test; 95 DROP TABLE 96 postgres=# drop tablespace if exists tbs_test; 97 DROP TABLESPACE 98
1、创建表空间:
用户必须有表空间所在目录访问权限
1 [root@localhost ~]# mkdir /usr/local/pgdata 2 [root@localhost ~]# chown postgres:postgres /usr/local/pgdata/
--创建表空间
1 create tablespace tbs_test owner postgres location '/usr/local/pgdata';
--建表
2、删除表空间
删除表空间前必须要删除该表空间下的所有数据库对象,否则无法删除。
3、删除数据库
1 DROP DATABASE mydb; 2 3 ---删除,都会报错提示 4 5 ERROR: database "mydb" is being accessed by other users 6 DETAIL: There are 3 other sessions using the database. 7 8 --解决方式,在执行 9 10 SELECT pg_terminate_backend(pg_stat_activity.pid) 11 FROM pg_stat_activity 12 WHERE datname='mydb' AND pid<>pg_backend_pid(); 13
函数
函数
| 描述 | PostgreSQL | Oracle |
| 当前时间 | current_date,now() | sysdate |
| 日期格式化 | to_date(text, text) | to_date(text) |
| 对时间或者数字截取 | date_trunc() | trunc() |
| 空判断 | coalesce(a, 0) | nvl(a, 0) |
| 数值类型转换 |
to_number(int, text) 例: to_number(123, "666666") : text表示精度 |
to_number(int) |
| 字符类型转换 | to_char(int, text) 例如 to_char(123,"666666") : text表示精度 | to_char(int) |
| 条件判断 | case...when...then | decode() |
| 伪表dual | 不支持 | 支持 |
函数修改点:
| Oracle | Pgsql |
| Raise_application_error(-20001,‘message’); | RAISE EXCEPTION ‘message’ USING ERRCODE = -20001; |
| topoTriggerEventSeq.nextval | nextval(‘topoTriggerEventSeq’) |

序列
对应修改点:
| Oracle | Pgsql |
| NOCACHE | CACHE=1(默认) |
| 对比内容 | Oracle | Pgsql |
| 创建序列号 | ||
| 查询序列: | 1 select nextval('topoTriggerEventSeq'); | |
| 修改序列: | ||
| 删除序列: | ||
触发器
对应修改点:
| Oracle | Pgsql |
| :new.xxx | new.xxx |
| :old.xxx | old.xxx |
对比点
| 对比内容 | Oracle | Pgsql |
| 触发器语法 | 1 //创建函数 2 CREATE OR REPLACE FUNCTION rigger_function() RETURNS TRIGGER AS $rigger_function$ 3 BEGIN 4 [-- 触发器逻辑....] 5 END 6 $rigger_function$ LANGUAGE plpgsql; 7 8 //创建触发器 9 CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name:[INSERT|UPDATE|DELETE] 10 ON table_name 11 for each row EXECUTE PROCEDURE trigger_function(); | |
| 创建触发器: | 1 create or replace trigger ifentity_trigger 2 before update on w_IFEntity 3 for each row 4 begin 5 insert into w_TopoTriggerEvent(id,type,oldValue,newValue) values(topoTriggerEventSeq.nextval, 13, :old.NEEntityId, :new.AVAILABLESTATUS); 6 end; |
1 --创建触发函数 2 CREATE OR REPLACE FUNCTION ifentity_trigger_function() RETURNS TRIGGER AS $ifentity_trigger_function$ 3 BEGIN 4 insert into w_TopoTriggerEvent(id,type,oldValue,newValue) values(nextval('topoTriggerEventSeq'), 13, old.NEEntityId, new.AVAILABLESTATUS); 5 RETURN NEW; 6 END 7 $ifentity_trigger_function$ LANGUAGE plpgsql; 8 9 --声明触发器 10 CREATE TRIGGER ifentity_trigger before update on w_IFEntity FOR EACH ROW EXECUTE PROCEDURE ifentity_trigger_function() |
| 删除触发器: | ||
| 声明增删改多条件触发器INSERT OR UPDATE OR DELETE | 1 CREATE TRIGGER GWV5PortChange After INSERT OR UPDATE OR DELETE ON nms_conf_v5portnew 2 for each row EXECUTE PROCEDURE GWV5PortChange_function(); | |
| 定义变量DECLARE | 1 CREATE or REPLACE FUNCTION GWV5PortChange_function() RETURNS TRIGGER AS $GWV5PortChange_function$ 2 --定义变量 3 DECLARE 4 iBnum NUMERIC(10); 5 BEGIN 6 --变量赋值 7 iBnum:=new.v5portStartNo; 8 [-- 触发器逻辑....] 9 END 10 $GWV5PortChange_function$ LANGUAGE plpgsql; 11 CREATE TRIGGER GWV5PortChange After INSERT ON nms_conf_v5portnew 12 for each row EXECUTE PROCEDURE GWV5PortChange_function(); | |
| 创建游标函数 | 1 create or replace function package_return_data1() 2 RETURNS refcursor AS $$ 3 DECLARE 4 r_return_data refcursor; 5 BEGIN 6 return r_return_data; 7 END 8 $$ language plpgsql; | |
| 自定义类型:创建type类型 | 1 创建基本类型 2 CREATE table pgty1 3 ( 4 add VARCHAR(80), 5 age NUMERIC(2) 6 ); 7 8 创建组合类型 9 CREATE TYPE pgty2 AS ( pgty2 pgty1[] ); | |
| 自定义类型: 复合类型建表两种方式: 1、使用基本类型创建数组类型: |
1 create table pgtbl 2 ( 3 id NUMERIC(10) not null, 4 name pgty1[], 5 primary key(id) 6 ); 7 8 插入数据 9 INSERT INTO pgtbl (id, name) values(1, ARRAY[('aaa',1)::pgty1,('bbb',2)::pgty1]); | |
| 自定义类型: 复合类型建表两种方式: 2、使用组合类型创建: |
1 create table pgtb2 2 ( 3 id NUMERIC(10) not null, 4 name pgty2, 5 primary key(id) 6 ); 7 8 插入数据 9 INSERT INTO pgtb2 (id, name) values(1,row(ARRAY[('aaa',1)::pgty1,('bbb',2)::pgty1])); | |
| 使用unnest可以解开Nested Table的内容。 | 1 create table pgtbl 2 ( 3 id NUMERIC(10) not null, 4 name pgty1[], 5 primary key(id) 6 ); 7 INSERT INTO pgtbl (id, name) values(1, ARRAY[('aaa',1)::pgty1,('bbb',2)::pgty1]); 8 select id,(unnest(name)).* from pgtbl ; | |
查询Sql
表连接(左连接,右连接)
oracle: 左连接 : a.id = b.id(+) ;
右连接 : a.id(+) = b.id
postgreSQL: 左连接:a left join b on a.id = b.id;
右连接:a right join b on a.id = b.id
分页
oracle使用rownum分页, postgreSQL使用limit.
oracle 与postgreSql 选择对比
我为什么会选择PostgreSQL?一个很重要的原因是不少同行在用,比如,平安科技。那抛开同行业,PostgreSQL自身有哪些优势?
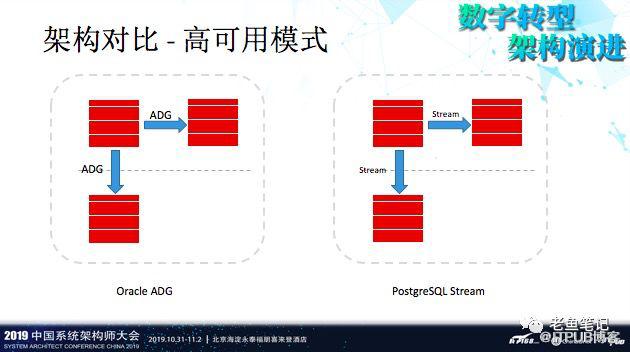
我们做了PostgreSQL与Oracle的对比,就单体模式来说, PostgreSQL完全不输给Oracle,可以做到完全实时的同步,单体保持数据同步方面一点问题都没有。
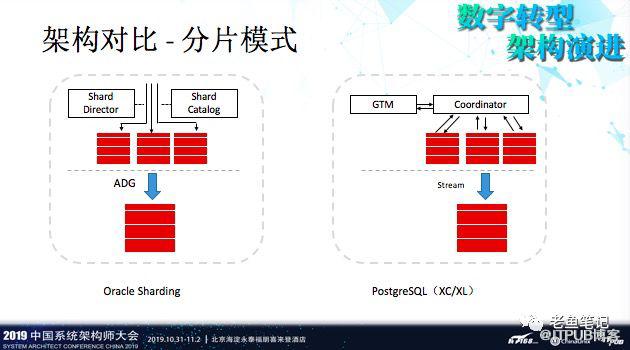
分片模式, Oracle提供了一个Sharding模式。相对应的PostgreSQL有XC/XL解决方案。当然咯,这个方案也不是完美的,比如说GTM可能会成为性能的瓶颈点,很有可能会成为一个瓶颈。
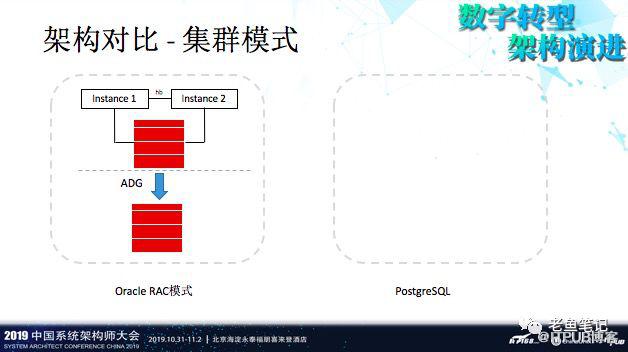
另外,Oracle有个非常强大的功能RAC,这个在PostgreSQL里是没有的。不过PostgreSQL有读写分离的解决方案,在读多写少的场景下,能达到不错的吞吐量。
目前,不管是商业的还是开源的数据库,基本上逃不脱这四种架构。
看下来,PostgreSQL和Oracle是非常像的,包括架构以及数据安全方面,都与Oracle非常像。这也是我们选择PostgreSQL重要的原因。同时,PostgreSQL提供了丰富的可选架构,能满足各种不同场景。PostgreSQL有效遵循SQL标准,让应用迁移难度降低,PostgreSQL有丰富的可选组件,极易扩展等。
让应用跑起来要注意的问题点:
下面,涉及到很多往PostgreSQL迁应用时遇到的问题,总结如下:
1、 字符集问题:
PostgreSQL服务端是不支持GBK的,我们用UTF8。PostgreSQL还有个编码EUC CN,这个我们之前测过很多次,有很多生僻字是无法编码的。 比如“瑄”在EUC_CN下就无法编码。因此,不推荐使用EUC_CN。
2、多行注释问题:
/* some comments
/* other comments
/*******************/
• 上述注释在Oracle中是合法的
• 在POSTGRESQL中是非法的
• -- 合法的PostgreSQL注释格式:
• -- This is a standard SQL comment
• /* multiline comment
• * with nesting: /* nested comment */
• */
• 可以使用PLY(Python-Lex-Yacc)将注释自动改写掉3、NUMERIC类型问题:

• 上述声明在Oracle中是合法的
• 但在POSTGRESQL中是非法的
• POSTGRESQL不支持负值的scale
• 也不支持scale大于precision
• 负值scale的解决方法:
{ 使用触发器,在触发器中调用round函数 }SELECT round(123.6, -2);
round
-------
100
(1 row)
scale大于precision的解决方法:
{ NUMBER(2,3) => NUMERIC(3,3) }
{ 增加CHECK (col < 0.1) }
DECLARE
c NUMBER := 1;
pi NUMBER := 3.142;
r NUMBER := 10;
BEGIN
FOR i IN 1..10000 LOOP
c := pi * (r * r) + (mod(r, c) * pi + i);
END LOOP;
END;
/
上述代码在Oracle中是没有任何问题
DO $$
DECLARE
c NUMERIC := 1;
pi NUMERIC := 3.142;
r NUMERIC := 10;
BEGIN
FOR i IN 1..10000 LOOP
c := pi * (r * r) + (mod(r, c) * pi + i);
END LOOP;
END;
$$ LANGUAGE plpgsql;
ERROR: value overflows numeric format
解决方法: 显式指定NUMERIC的精度
DO $$
DECLARE
c NUMERIC(32,2) := 1;
pi NUMERIC := 3.142;
r NUMERIC := 10;
BEGIN
FOR i IN 1..10000 LOOP
c := pi * (r * r) + (mod(r, c) * pi + i);
END LOOP;
END;
$$ LANGUAGE plpgsql;
4、VARCHAR类型问题

上面是经常碰到的VARCHAR问题,值已经超出了目标长度,肯定会报错。但在PostgreSQL里面不一样,会截断但不报错,这要特别注意,因为没有报错,你的应用如果没有注意到这个问题,很有可能你的数据就丢失了,计算结果就出错了,那这个就是很严重的问题了。
5、CHAR类型问题
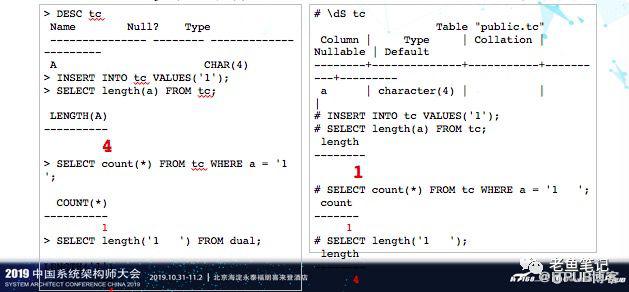
在PostgreSQL中,CHAR类型的长度是实际有效字符的长度,这个和Oracle很不一样。这个在应用中如果不注意的话,就会报很多错误。而且,有时候查起来非常困难。当然我们也可以通过重载函数的方式来模拟Oracle中的行为。
6、SEQUENCE最大值问题
•POSTGRESQL的SEQUENCE最大值:9223372036854775807(bigint)
•而Oracle中的SEQUENCE最大值可达28位十进制值•一般情况下POSTGRESQL的SEQUENCE是足够的
•但可能也存在一些特殊情况
{LISCODE.SEQ_YBTBATTRANS_ID '10000000000000072561' }
{ 该值明显已超出最大值}
{ 使用NUMERIC类型,配合触发器使用}通常情况下PostgreSQL中SEQUENCE足够使用。但上面这个值已经超出最大值,目前,我的解决办法是把它用NUMERIC类型配合触发器使用,用触发器模拟序列类型,如果你是频繁插入,性能下降会非常严重,这是需要注意的问题。
7、类型转换
# CREATE TABLE t1 (id VARCHAR(32));
# SELECT * FROM t1 WHERE id = 27;
ERROR: operator does not exist: character varying = integer
LINE 1: SELECT * FROM t1 WHERE id = 27;
^
HINT: No operator matches the given name and argument type(s). You might need to add explicit type casts.
CREATE CAST (varchar AS integer)
WITH INOUT
AS IMPLICIT;
# SELECT * FROM t1 WHERE id = 27;
id
----
(0 rows)
# EXPLAIN verbose SELECT * FROM t1 WHERE id = 27;
QUERY PLAN
-----------------------------------------------------------
Seq Scan on public.t1 (cost=0.00..22.95 rows=4 width=82)
Output: id
Filter: ((t1.id)::integer = 27)
(3 rows)• 善用CAST
• 根据自己的需求,绘制类型转换矩阵
如果对Oracle熟悉,就会知道Oracle是由明确的类型转换矩阵的,在PostgreSQL里,这方面就差一点。但PostgreSQL提供了自定义创建CAST的特性。在我们实际迁移过程当中,如果你能够把CAST利用好是能解决很大一部分问题的。
7、操作符重载
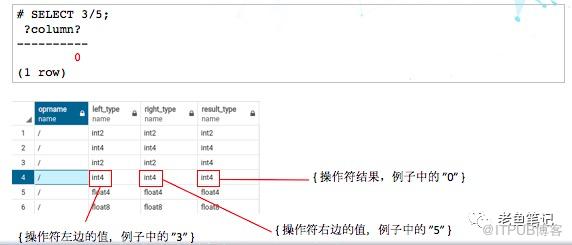
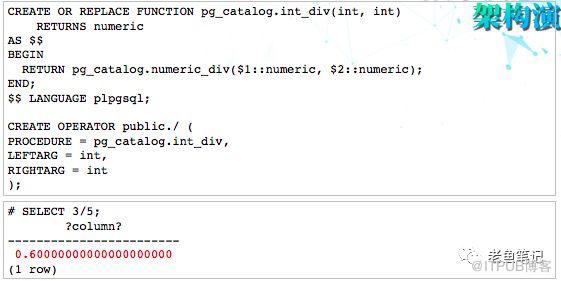
比如说SELECT 3/5是个雷,除了它本身3对应的是INT4,5对应的也是INT4,所以它本身是一个非整型数字,但是,它也是会被截断掉。进行一个重载就可以解决,我们重新定义一个函数,可以用系统的numeric div,这样用户不需要做任何的修改就可以达到跟Oracle一样的效果。
总结一下,操作符重载是PostgreSQL提供的一个非常好的特性,善用操作符重载可以解决一些兼容性问题,以及前面说的CAST是可以解决很多监管系统问题的,在这个过程中也是有很多问题需要注意的。
第一、POSTGRESQL本身它设置了很多类型转换和操作符,这个一定要考虑是否有冲突。
第二、类型转化的操作也需要相互配合,因为在调用操作符时,是要判断类型转换是否需要自己去做的,所以,这两个是需要密切配合才能完美的使用好。
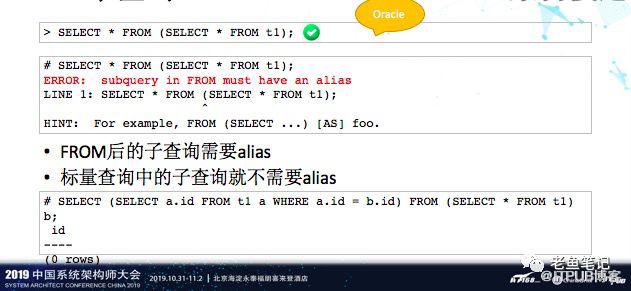
8、子查询
Oracle当中子查询不需要别名alias,但在PostgreSQL当中是不行的。
9、SELECT表达式别名问题
下种这种语句在Oracle里面没有任何问题,但在PostgreSQL就会出问题。
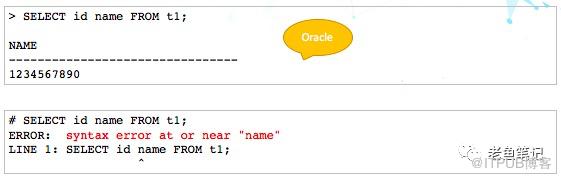


究其原因,是PostgreSQL认为name是关键字,不能使用。但是这也有矛盾的地方。比如uncommited这个关键字和name是一样的级别,但是uncommited就可以用来做别名。这个问题还需要研究。
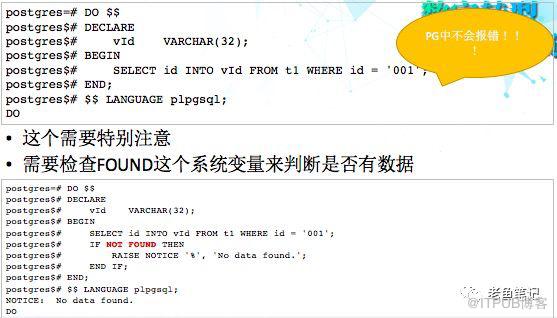
9、SELECT INTO
这个问题也是需要特别注意,如果本身的代码没有这方面的错误处理,很有可能就会导致结果错误。

10、UPDATE语句问题
UPDATE语句中不能使用下面这个在Oracle可能很常见的写法。INSERT也一样。这个也不能说谁对谁错,因为本身SQL标准中就不支持这样的写法的,PostgreSQL只是遵从了这个标准而已。

11、Oracle访问PostgreSQL
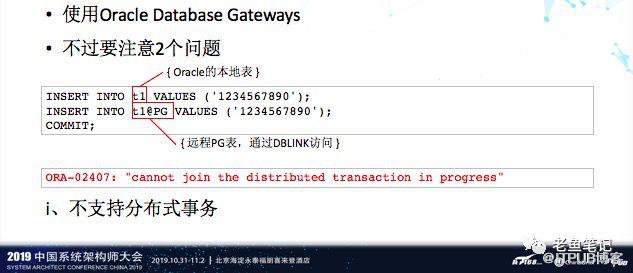
在我们的系统中是有很多通过DBLINK来进行数据交互的,那迁移不太可能所有的系统一起签掉,所以原有的DBLINK功能还得继续保留。我们使用的方法是用Oracle Database Gateway。但是这里面有两个问题,1是分布式事务的问题,在Oracle和Oracle之间没有任何问题,是可以做分布式事务的,如果是PostgreSQL,这个时候是不支持的,Database Gateway还不支持异构数据库间的2PC,这个要特别注意。
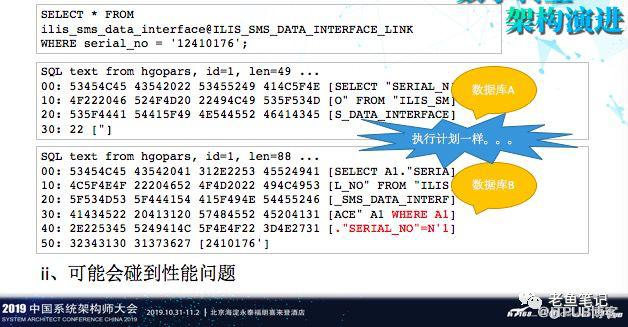
访问的时候还会碰到性能问题,这个问题到目前为止我们也是一直没有解决掉,这个语句非常简单,这个库我们已经给迁走了,迁到PostgreSQL里,通过DBLINK取PostgreSQL里面的数据。
我们发现,在生产环境当中,性能较差,但在测试环境里面性能很好。我们跟踪了一下,发现同样的一个SQL发过去,在Oracle虽然执行计划是一样的,但到达Database Gateway,再由Database Gateway出去后,生产环境它缺少一个WHERE条件。这个问题,我们找Oracle也沟通过好几次,但他们也解决不了。我们用了好多办法去复现测试环境,均告失败,这个问题,也非常诡异,也值得深入研究。
12、PostgreSQL访问Oracle
这是个非常强的现实需求。那我们使用oracle_fdw,Oracle fdw在日常的使用下没有什么问题,而且性能也还不错。但可能会碰到一个错误,发现这个错误的原因主要是Oracle fdw当中使用的事务级别是serializable,那如果有并发更新,就可能会报这样的错误。

这就需要增加一个重试机制。 不过我们觉得Oracle_fdw事务级别设置的过于严格了,所以我们对源码做了简单的修改,把事务级别降下来.
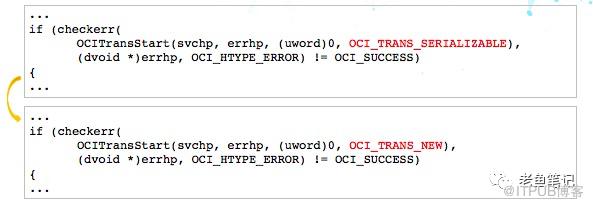
修改后,实际使用中运行良好。
13、空串(”)、NULL问题
空串和NULL也是非常头疼的问题,因为在Oracle当中空串和NULL是等价的,我个人更加偏向于PostgreSQL设计,更严谨。PostgreSQL里面空串是空串,NULL是NULL,但从Oracle牵引过来会碰到很多的问题。
比如说涉及到字符串判断的地方都需要修改,有时候开发不会特别注意这方面的内容。还有涉及到字符串连接的地方都需要修改。另外,所有涉及到字符串转为数值型的都需要修改,空串强制转换会报错。
在我们现在迁移项目中,如果都要修改的话,代码里面差不多有几十万的修改量,这个是非常大的修改量,因为你修改了以后还要重新测试。
我们对PostgreSQL进行了定制化工作,从内核层面使空串与NULL进行等价。
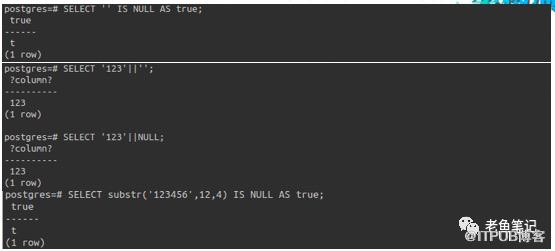
大家可以看到,这是我们修改后的PostgreSQL执行情况,这个时候空串、NULL是等价的。

在做连接的时候,其实也是和Oracle里面的行为是一致的,包括函数的返回,比如说substr,正常应该返回空串,但是在Oracle返回的是NULL,我们修改了以后行为变成一致了。
类型转换,空串的转换也都没有任何问题了。
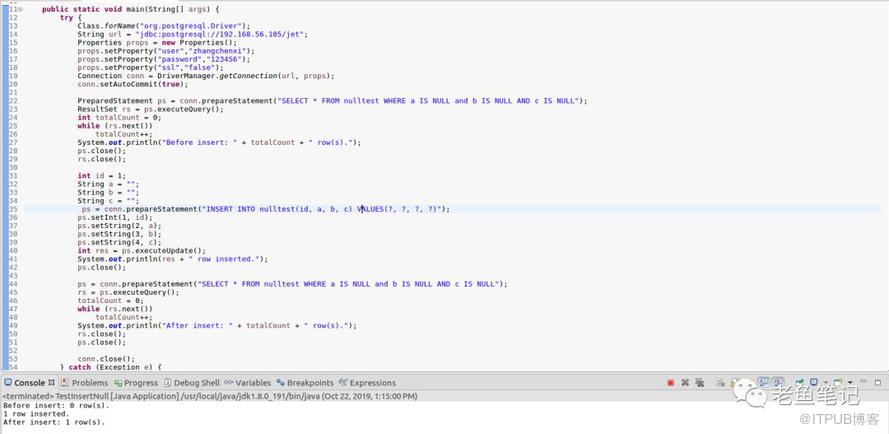
从应用代码当中执行,代码当中包括绑定变量的方式,比如我们先选一下当前有没有NULL值,当前是零,这里是空串,再去执行同样的语句,会发现已经正确插进去了。这个是我们对PostgreSQL本身开源技术上做的一些小优化。
14、SYNONYM问题
PostgreSQL中是没有SYNONYM这个概念的
1、可以通过调整search_path来解决
2、配合使用VIEW
15、列名大小写问题
Oracle中的列名是大写表示的
PostgreSQL中的列名是小写表示的
在使用类似MyBatis这样的工具时,需要将大写转为小写,否则会导致你的列名找不到的问题,这个是需要特别注意的一个地方。
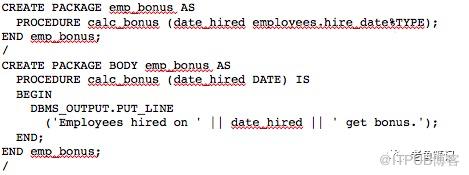
16、如何支持PACKAGE?
PostgreSQL中没有PACKAGE这个概念我们使用了schema来模拟。这是Oracle官方网站里的一个案例,大家可以自己看一下。

17、其他
其他的还有,decode函数,Wm conca为函数,dual,utl_file,dbms_pipe,dbms_output,package,
我们非常推荐使用orafce开源组件,功能挺强大的。
以上是在实际迁移系统过程中,可能会遇到的各种“坑”点,趟过所有这些“坑”,应用才可以完成生存的第一步:活着!
让应用跑的更好、更快!
在数据库系统里,我认为有两个核心是最重要的。一个是事务管理器,还有一个叫做查询处理器,这两个其实是构成了一个关系与数据库的核心。
其中,代价模型是查询处理器中非常重要的内容,在我们没办法对查询优化器做更多优化的工作时,那我们只能理解系统是怎么来估算执行成本的,那这个对于系统优化也好,SQL优化也好都有非常重要的意义。
(接下来的内容是PostgreSQL中走全表扫描及走索引的成本估算算法的详细介绍,因内容比较难懂,感兴趣的可下载其PPT进行研读)。
另外一种优化方式
SELECT phone
FROM lcaddress
WHERE customerno IN (
SELECT insuredno
FROM lcinsured
WHERE contno = '100005522831'
AND sequenceno = 1
AND addressno = lcaddress.addressno
);这个在Oracle里面只要几十毫秒,但是POSTGRESQL里面几十秒才出来。
对SQL进行简单重写
SELECT phone
FROM lcaddress
WHERE (customerno, addressno) IN (
SELECT insuredno, addressno
FROM lcinsured
WHERE contno = '100005522831'
AND sequenceno = 1
);重写后SQL在Oracle在Plan不变,在PostgreSQL当中的执行计划,已经与Oracle一致了。所以我们方式就是说以Oracle的执行计划为蓝本来优化SQL。
让应用跑的更稳定、更安全
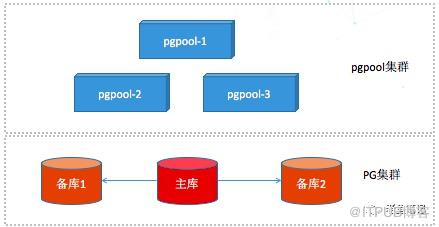
PostgreSQL高可用架构,通过PGpool进行数据库的负载均衡,一主两备的方式,主库与备库间通过stream的方式实现实时同步(配置策略为备库1和备库2只要有一个写完成主库就返回,防止因为某些原因备库1\2均不能用时将主库hang住,提高可用性),这样在备库当中任何一个出现问题不会影响主库的数。
最后一句,备份重如山,对于搞IT的,尤其是做数据库的,这个要时刻牢记在心,谢谢大家!
SQL执行计划干预
从使用postgresql来看,想要改变执行计划只能通过対表进行分析,不能通过添加hint的方式来改变执行计划;
oracle不仅可以通过对表进行收集统计来改变执行计划,而且很重要的一点支持通过添加hint的方式以达到自己想要的执行计划。
查询效率
从整体上比,不管是在离散数据的获取,还是在大数据量的统计分析,oracle的查询效率要好于postgresql,尤其在大数据量的统计分析(比较、排序、去重、表关联。。。);
有一个比较奇怪的地方是大表数据的加载,比方说link7的数据量有2G多,执行总数查询:
select count(*) from link7; -----------------------------第一次执行时间比方说120s;
在第二次执行时,执行时间可能是20s,但link7并没有全部加载到缓存中,只是有10%-20%的数据加载到缓存中,但执行时间缩短到了首次的1/10-1/9
--------我猜想的是应该是首次执行完后,加载了表link7的位置信息到缓存中,再次查询时,可以快速定位数据。
语法功能
在单条数据的功能上postgresql要强,尤其空间查询、转换,支持很多的方法函数
在统计分析上oracle要强,如分析函数、sql model等
数据加载
在使用门槛上,postgresql要简单,如数据导入导出,copy 表 to '' with csv; copy 表 from '' with csv;
在效率、多样性上oracle要强要多,如imp/exp、数据泵、sqlload等
事务
postgresql基本上自动提交事务,如果要控制自动提交,需要使用begin end;
oracle默认是需要commit才会进行数据持久化,或者执行DDL
总结体会
postgresql开源免费、单数据处理转换、查询比较适用
学问:纸上得来终觉浅,绝知此事要躬行
为事:工欲善其事,必先利其器。
态度:道阻且长,行则将至;行而不辍,未来可期
.....................................................................
------- 桃之夭夭,灼灼其华。之子于归,宜其室家。 ---------------
------- 桃之夭夭,有蕡其实。之子于归,宜其家室。 ---------------
------- 桃之夭夭,其叶蓁蓁。之子于归,宜其家人。 ---------------
=====================================================================
* 博客文章部分截图及内容来自于学习的书本及相应培训课程以及网络其他博客,仅做学习讨论之用,不做商业用途。
* 如有侵权,马上联系我,我立马删除对应链接。 * @author Alan -liu * @Email no008@foxmail.com
转载请标注出处! ✧*꧁一品堂.技术学习笔记꧂*✧. ---> https://www.cnblogs.com/ios9/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号