
C++中函数返回值与拷贝
五一假期最后一天,看JUC看的头疼,写写blog放松一下。作为自己的第一篇blog,自己就先来谈谈对C++中函数返回return的理解,自己本来在学Java,但是平时学校的项目是用的C++,所以在平时搬砖时经常会有一些问题,今天就来谈谈前段时间注意到的一个很小的知识点,话不多说,先上列子。
首先我们创建一个简单的Man类,实现它的无参构造函数、有参构造函数和析构函数:
class Man
{
public:
Man() {
cout << "构造" << endl;
data = new int(0); }
Man(const Man& m)
{
cout << "拷贝构造" << endl;
this->data = m.data;//IORI 标注这里应该作深拷贝处理,重新申请一块自已的Data内存 否则析构时,就会两次delete.
}
~Man()
{
cout << "析构" << endl;
delete data;
}
int* data;
};
声明一个get函数获取一个Man的对象
Man get(Man& m)
{
cout << "----" << endl;
return m;
}
在main函数中执行下列代码
void main()
{
Man m, n;
//cout << "before m=" << &m << "n=" << &n << endl;
*m.data = 5;
printf("m.data is %d\n", *m.data);
n = get(m);
printf("m.data is %d\n", *m.data);
printf("n.data is %d\n", *n.data);
system("pause");
}
你可以试着想一想三个printf的输出结果分别是多少
执行结果如下图所示:
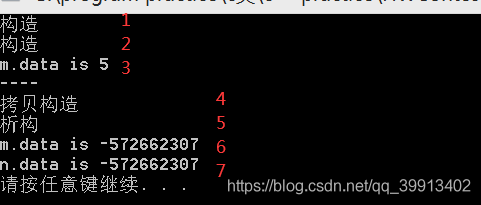
在输出结果里我们可以清楚的看到,Man m, n; 创建了m,n两个对象,调用了构造函数,对m对象中的data赋值,然后我们调用get(Man& man) 函数,注意这里函数参数是引用类型,因此传入的对象是m对象本身,这里我们要区别get(Man man) 两种函数参数类型的区别,我稍后再提。get(Man& man) 函数调用完毕后,返回对象m。
按照我们过去的分析会认为对象n等于get函数返回的m对象 (n=m) (注意这里等号=被重载过),m对象中的int* data 成员值直接赋值给了n对象中的data成员,输出时照理说m和n的data值都应该等于5的,但是:
为什么这里输出结果却表明这个data指针指向的空间被销毁了?
为什么get函数执行里会多出了拷贝构造和析构这两个过程呢?
如果我们返回值为Man&会有什么区别变化呢?
这里我们做一个对比,填加一个getR函数,返回值为Man& 引用类型:
Man& getR(Man& m)
{
cout << "----" << endl;
return m;
}
接下来我们调用getR这个函数看一看输出结果:
void main()
{
Man m, n;
*m.data = 5;
printf("m.data is %d\n", *m.data);
n = getR(m);
printf("m.data is %d\n", *m.data);
printf("n.data is %d\n", *n.data);
system("pause");
}
执行结果如下图所示:

可以看到,当我们返回的是m对象的的引用时,getR 函数执行时没有调用拷贝构造和析构函数
这里我向你详细的解释一下返回值不是引用的情况时整个函数执行的过程(个人拙劣的理解)
我们再回到get这个函数:
Man get(Man& m)
{
cout << "----" << endl;
return m;
}
首先函数参数传入m这个对象的引用我们毋庸置疑,关键就在return这里。我们捋一捋函数从开始到结束这个过程,随着Main函数调用get函数,get函数入栈,同时get方法对应的栈帧(储存函数局部变量、返回地址等信息)也入栈,这里的局部变量也就是m对象的引用。
当我们return这个m对象时,会在内存中创建一个临时的Man temp对象,同时这个temp对象调用其拷贝构造函数,也就是Man temp(m) 。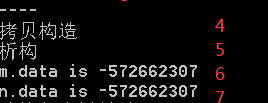
完成temp对象的创建后,get函数出栈,对应的栈区内容被销毁,这时系统会调用m对象的析构函数,注意这里有一个陷阱!!!!,由于m对象是在main方法下的栈区创建的,因此get方法出栈后,系统调用m析构函数并没有真正把m对象在栈区销毁(因为它根本就不是在get方法的栈区上),调用析构函数仅仅是将data指针所指向的内存空间被销毁了(delete data;),这也解释了为什么m.data的值为-572662307。当main方法执行完毕后,m对象才会调用析构函数真正被销毁,当然,这也会带来另一个问题,data指向的内存区被执行了两次delete,运行结束后你也就会发现还会有一个**“析构”**和一个内存问题报错。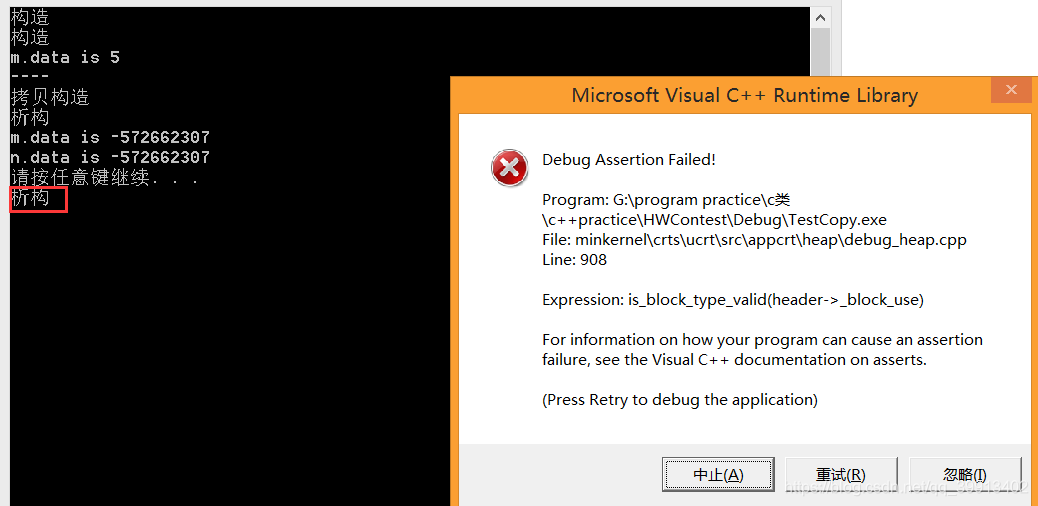
回到我们返回的值上:
n = get(m);
这里实际上可以理解成
Man temp(m);
n=temp;
当然由于get函数的退出调用析构函数时,data指针指向的内存区域数据已经被销毁,自然n和m得到的值是一个错误值了。
总结
对于函数返回值类型为非引用类型(当然引用类型也可以理解为Man& temp=m),都是会在内存中创建一个临时变量,将返回值拷贝到临时变量中,而返回值是作为函数调用栈区中的局部变量,随着函数的返回,栈区的销毁,而被销毁。
如果有理解上的错误还请各位指正!~
-
 day风土2023.12.01
day风土2023.12.01 你这个错误是 temp 被析构了、temp.data 已经被删除了,但是实际值已经赋予了n。 这个时候 n.data 之前的数据泄露同时 n.data 新指向的地址已经被temp 析构了、这个时候程序结束。n被西沟 发现data 已经被删除的就程序崩溃了、本质上是你的程序写的有问题
你这个错误是 temp 被析构了、temp.data 已经被删除了,但是实际值已经赋予了n。 这个时候 n.data 之前的数据泄露同时 n.data 新指向的地址已经被temp 析构了、这个时候程序结束。n被西沟 发现data 已经被删除的就程序崩溃了、本质上是你的程序写的有问题
-
 NoOneIsAlive2022.12.132你自己都写了拷贝构造函数,还写成了浅拷贝
NoOneIsAlive2022.12.132你自己都写了拷贝构造函数,还写成了浅拷贝
-
-
NoOneIsAlive回复NoOneIsAlive2022.12.131还存在拷贝赋值,编译器自动生成的也是浅拷贝
-
-
 its been long time2021.09.145博主你好,我认为在get函数执行完后调用的不是m的析构函数,而是temp的析构函数,由于将data是一个指针,所以temp,n,m的data指向同一个位置,而当temp的data被销毁就意味着m,n的data都指向了一块被释放的空间
its been long time2021.09.145博主你好,我认为在get函数执行完后调用的不是m的析构函数,而是temp的析构函数,由于将data是一个指针,所以temp,n,m的data指向同一个位置,而当temp的data被销毁就意味着m,n的data都指向了一块被释放的空间
-
 姚文洲2020.12.192字符限制我就不粘我的代码了,你在拷贝构造函数中打印一下this,同时在get方法调用前打印一下m和n的地址,另外你重载一下赋值操作符,你就知道了。准确说,return会产生一个临时对象,此时调用的是临时对象的拷贝构造函数,然后调用n的重载的赋值操作符,接着析构临时对象,这样才算整个带哦用过程执行完毕。
姚文洲2020.12.192字符限制我就不粘我的代码了,你在拷贝构造函数中打印一下this,同时在get方法调用前打印一下m和n的地址,另外你重载一下赋值操作符,你就知道了。准确说,return会产生一个临时对象,此时调用的是临时对象的拷贝构造函数,然后调用n的重载的赋值操作符,接着析构临时对象,这样才算整个带哦用过程执行完毕。
-
姚文洲2020.12.192博主,你的代码有问题,博客也有问题。
返回的时候,创建了一个临时对象,调用的是临时对象的拷贝构造函数
然后退出前析构的也是该临时对象,并没有调用m的析构函数
-
dawnButterfly2020.05.15博主你好,小白想问下:在返回的时候会创建一个临时的内存用于复制返回值,看输出的内容,应该是先将m复制到了temp这个临时空间中,接着在析构m造成data空间的销毁,那么这个temp空间的data数值不应该是5吗?导致n的data也应该是5为什么是乱码呢?
-



C++函数返回对象效率以及使用建议



函数的传参和传返回值,分为两种模式:传值和传引用。
传值就是传整个对象,传引用就是传对象的引用(地址)。当对象本身比较小时,可以直接传值,但当对象比较大时我们一般会传引用以节省内存和减少拷贝。这是C++的机制,在java中都是传引用,所以不用像C++一样区分值语义和引用语义。
对于传参一般建议都使用传引用,但对于返回值而言,我们不能直接返回对象引用,因为,函数调用完后会清栈,引用指飞。但传值我们又担心临时变量的拷贝降低性能,所以我们可能写出如下代码,返回值用指针包裹。
shared_ptr<A> fun()
{
make_shared<A> ptr;
...
return ptr;
}这当然万无一失,但明显变麻烦了。实际上我们可以放心大胆地返回对象。下面进行论述:
C/C++函数返回对象的原理:
A fun2()
{
A a1();
...
return a1;
}
void fun1()
{
A a2=fun2();
}
a1是在函数fun2中堆栈中的对象,在return时,会将其拷贝构造到外层函数fun1的堆栈中(这个对象是一个匿名对象,是一个右值,马上会被析构),之后将其拷贝构造产生对象a2。这是没有任何编译器优化的情况。
一般情况下,编译器会采用RVO(return value optimization)优化,参看《深度探索C++对象模型》。下面是一个例子
//原函数
Point3d factory()
{
Point3d po(1,2,3)
return po;
}
int main()
{
Point3d p = factory();
return 1;
}
//
编译器优化后的示例代码
//
factory(const Point3d &_result)
{
Point3d po;
po.Point3d::Point3d(1,2,3);
_result.Point3d::Point3d(po); //用po拷贝构造_result;
po.Point3d::~Point3d(); //po对象析构
return;
}
int main()
{
Point3d _result;
factory(_result);
Point3d p=result;
return 1;
}大体意思是说,会在值传递返回值的函数中,将返回值改写成传引用参数。这样可以少一次临时变量的构造。这是编译器优化时帮我们做的。
总结起来就是放心大胆地返回一个对象实体,这并不会有多余的开销,编译器会帮我们优化。
c++ 如何高效传递对象,避免不必要的复制

#include <iostream>
class A {
public:
A() {
std::cout << " constructor" << std::endl;
}
A(const A& orig) {
std::cout << " copy constructor" << std::endl;
}
~A() {
std::cout << " destructor" << std::endl;
}
A& operator=(const A& orig) {
std::cout << " operator=" << std::endl;
}
};
A func() {
return A();
}
int main() {
A a = func();
return 0;
}
按我之前的认知,应该输出
constructor
copy constructor
destructor
copy constructor
destructor
destructor
在func中调用复制构造函数来复制return语句中创建的对象,用于返回到main函数,然后析构return语句中创建的对象;func函数返回后,调用a的复制构造函数来复制func返回后的临时对象,然后析构临时对象。最后main函数返回后再析构a。
然而实际在gcc中输出是
constructor
destructor
网上查,才知道编译器做了点手脚,它把main中的a直接指向了func中return那句构造的对象,然后func返回时,构造的对象当然不会被析构。这个手脚就是返回值优化(RVO)。不过我们也可以关闭这个优化,只要加上编译选项 -fno-elide-constructors。当加上这个选项后,运行输出
constructor
copy constructor
destructor
copy constructor
destructor
destructor
输出时,同时再输出this指针地址,能更直观的看出整个过程:
#include <iostream>
class A {
public:
A() {
std::cout << this << " constructor" << std::endl;
}
A(const A& orig) {
std::cout << this << " copy constructor" << std::endl;
}
~A() {
std::cout << this << " destructor" << std::endl;
}
A& operator=(const A& orig) {
std::cout << this << " operator=" << std::endl;
}
void printAddr() {
std::cout << this << std::endl;
}
};
A func() {
return A();
}
int main() {
A a = func();
a.printAddr();
return 0;
}
0x7ffd892d9d6f constructor
0x7ffd892d9d9f copy constructor
0x7ffd892d9d6f destructor
0x7ffd892d9d9e copy constructor
0x7ffd892d9d9f destructor
0x7ffd892d9d9e
0x7ffd892d9d9e destructor
不加-fno-elide-constructors编译运行输出
0x7ffde009f03f constructor
0x7ffde009f03f
0x7ffde009f03f destructor
另外,若func函数改为返回有名对象:
A func() {
A local;
return local;
}
若func中传入A对象的引用,再直接返回:
A func(A& r) {
return r;
}
int main() {
A f;
A a = func(f);
a.printAddr();
return 0;
}0x7ffe76589caf constructor
0x7ffe76589cae copy constructor
0x7ffe76589cae
0x7ffe76589cae destructor
0x7ffe76589caf destructor
嗯,知道r到a应该复制一份,合情合理,编译器还挺聪明的嘛。若func中直接传入A对象,再直接返回:
A func(A r) {
return r;
}
int main() {
A f;
A a = func(f);
a.printAddr();
return 0;
}0x7ffead26280e constructor
0x7ffead26280f copy constructor
0x7ffead26280d copy constructor
0x7ffead26280f destructor
0x7ffead26280d
0x7ffead26280d destructor
0x7ffead26280e destructor
除了会多一个从形参到实参的复制,还会多一个形参到a的复制。
接下来讲一个c11右值引用的例子,A中新增一个显式移动构造函数:
#include <iostream>
class A {
public:
A() {
std::cout << this << " constructor" << std::endl;
}
A(const A& orig) {
std::cout << this << " copy constructor" << std::endl;
}
A(A&& orig) {
std::cout << this << " move constructor" << std::endl;
}
~A() {
std::cout << this << " destructor" << std::endl;
}
A& operator=(const A& orig) {
std::cout << this << " operator=" << std::endl;
}
void printAddr() {
std::cout << this << std::endl;
}
};
A func() {
return std::move(A());
}
int main() {
A a = func();
return 0;
}0x7ffc248d7c8f constructor
0x7ffc248d7c8f destructor
控制变量,我们需要看到新特性右值引用的作用,去掉编译器优化,加上-fno-elide-constructors编译运行输出
0x7ffe158f029f constructor
0x7ffe158f02cf move constructor
0x7ffe158f029f destructor
0x7ffe158f02ce move constructor
0x7ffe158f02cf destructor
0x7ffe158f02ce destructor
从结果能看出,通过std::move()函数,我们可以“移动”对象内存所有权,使得免去逻辑上多余复制的操作,达到资源再利用,提高效率。以上是显式移动,得益于c11新特性,c11从语义上默认支持移动,所以还可以隐式移动,把func改为:
A func() {
// return std::move(A());
return A();
}综上在c11下写返回局部对象的函数,编译器会先自动优化,若某些场景下优化未触发(具体哪些场景可搜索关键字RVO),还会通过移动来避免复制。
此外,还能通过移动来避免右值传参过程中的复制,如下,A不变,新增函数func2:
void func2(A s) {
}
int main() {
A a;
std::cout << "copy" << std::endl;
func2(a);
std::cout << "\nexplicit move" << std::endl;
func2(std::move(a));
std::cout << "\nimplicit move" << std::endl;
func2(A());
std::cout << "\ndone" << std::endl;
return 0;
}0x7fff2b988efb constructor
copy
0x7fff2b988efc copy constructor
0x7fff2b988efc destructor
explicit move
0x7fff2b988efd move constructor
0x7fff2b988efd destructor
implicit move
0x7fff2b988eff constructor
0x7fff2b988efe move constructor
0x7fff2b988efe destructor
0x7fff2b988eff destructor
done
0x7fff2b988efb destructor
以上std::move(a)和A()都是右值,逻辑上没必要复制到形参,得益于c11新特性,可以通过移动来避免实参到形参的复制。需要注意的:
1. std::move(a)后,a虽没有被立即释放,访问其对象语法上是可以的,但我们清楚其资源已经是别的对象的了,所以访问成员变量(包括析构时析构成员变量)是不允许的,所以在移动构造函数中,形参orig的成员必须被置为nullptr,以防止其访问已不再属于它的资源。
2. 要尽量保证移动构造函数不发生异常(大概因为实参移动到实参或者临时对象返回时抛异常不好处理?),可以通过noexcept关键字,这里可以保证移动构造函数中抛出来的异常会直接调用terminate终止程序。
参考:
https://www.zhihu.com/question/22111546
http://www.cnblogs.com/lengender-12/p/6659833.html
http://book.2cto.com/201306/25367.html
http://blog.csdn.net/immiao/article/details/46876799
http://blog.csdn.net/virtual_func/article/details/48709617
C++以对象作为返回值时编译器的优化,以及临时变量的析构时机

印象中,函数调用的时候,参数past by value、返回值return by value,总是伴随着对象的复制。
实际上参数传递是这样的,但是返回值有可能不是这样的(虽然大部分都是面临拷贝构造函数的调用),这取决于编译器。
#include<string>
#include<list>
#include<iostream>
using namespace std;
class C
{
public:
C()
{
cout<<"C default constructor(),this="<<this<<endl;
}
C(const C &c)
{
cout<<"C const copy constructor(),this="<<this<<",reference="<<&c<<endl;
}
C(C &c)
{
cout<<"C nonconst copy constructor(),this="<<this<<",reference="<<&c<<endl;
}
const C & operator=(const C &c)
{
cout<<"C assignment(),this="<<this<<endl;
return *this;
}
~C()
{
cout<<"C destructor(),this="<<this<<endl;
}
};
C test_1(int i)
{
cout<<"entering test_1"<<endl;
C x;
C a; //a会析构
cout<<"leaving test_1"<<endl;
return x; //return之后栈不清空,x不会析构,即使编译器已经将优化设置成-O0
}
C test_2(int i)
{
cout<<"entering test_2"<<endl;
C x;
C a;
cout<<"leaving test_2"<<endl;
if(i>0)
return x;
else
return a; //x和a都会析构,返回的时候,先调用拷贝构造函数,初始化返回值(此处为main里面的z),
//然后再析构a和x
}
C test_3(C t)
{
return t; //此处导致t的构造和析构
}
C test_4(C t)
{
C x=t;
return x; //此处导致t的构造和析构,但是x只会构造不会析构
}
int main()
{
cout<<"invoking test_1"<<endl;
C y=test_1(1); //这种调用不会有拷贝构造函数,y直接为test_1函数栈里面生成的对象,编译器优化的结果
cout<<"end invoke test_1"<<endl;
cout<<"================华丽分割线================="<<endl;
cout<<"invoking test_2"<<endl;
C z=test_2(1); //这种情况会调用拷贝构造函数(nonconst版本),初始化z
cout<<"end invoke test_2"<<endl;
cout<<"================华丽分割线================="<<endl;
cout<<"invoking test_3"<<endl;
C a=test_3(y);
cout<<"end invoke test_3"<<endl;
cout<<"================华丽分割线================="<<endl;
cout<<"invoking test_4"<<endl;
C b=test_4(y);
cout<<"end invoke test_4"<<endl;
cout<<"================华丽分割线================="<<endl;
cout<<"开始测试临时变量何时析构"<<endl;
test_2(1), //(注意结束处是逗号)此处返回的C没有指定任何变量,编译器会生成临时变量
cout<<"结束测试临时变量何时析构"<<endl;//临时变量会再语句的第一个分号处析构,cout完成之后析构
cout<<"================华丽分割线================="<<endl;
cout<<"开始测试临时变量何时析构"<<endl;
test_2(1); //(注意结束处是分号)此处返回的C没有指定任何变量,编译器会生成临时变量
cout<<"结束测试临时变量何时析构"<<endl;//临时变量会再语句的第一个分号处析构,cout开始之前析构
cout<<"================华丽分割线================="<<endl;
cout<<"================下面开始析构栈里面的变量了,啦啦啦================="<<endl;
cout<<"================析构顺序按照入栈的顺序,后进先出,后构造,先析构==========="<<endl;
return 0;
}
运行结果:
AlexdeMacBook-Pro:~ alex$ a.out
invoking test_1
entering test_1
C default constructor(),this=0x7fff5929baa8
C default constructor(),this=0x7fff5929b8d8
leaving test_1
C destructor(),this=0x7fff5929b8d8
end invoke test_1
================华丽分割线=================
invoking test_2
entering test_2
C default constructor(),this=0x7fff5929b8d8
C default constructor(),this=0x7fff5929b8d0
leaving test_2
C nonconst copy constructor(),this=0x7fff5929ba98,reference=0x7fff5929b8d8
C destructor(),this=0x7fff5929b8d0
C destructor(),this=0x7fff5929b8d8
end invoke test_2
================华丽分割线=================
invoking test_3
C nonconst copy constructor(),this=0x7fff5929ba88,reference=0x7fff5929baa8
C nonconst copy constructor(),this=0x7fff5929ba90,reference=0x7fff5929ba88
C destructor(),this=0x7fff5929ba88
end invoke test_3
================华丽分割线=================
invoking test_4
C nonconst copy constructor(),this=0x7fff5929ba78,reference=0x7fff5929baa8
C nonconst copy constructor(),this=0x7fff5929ba80,reference=0x7fff5929ba78
C destructor(),this=0x7fff5929ba78
end invoke test_4
================华丽分割线=================
开始测试临时变量何时析构
entering test_2
C default constructor(),this=0x7fff5929b8d8
C default constructor(),this=0x7fff5929b8d0
leaving test_2
C nonconst copy constructor(),this=0x7fff5929ba70,reference=0x7fff5929b8d8
C destructor(),this=0x7fff5929b8d0
C destructor(),this=0x7fff5929b8d8
结束测试临时变量何时析构
C destructor(),this=0x7fff5929ba70
================华丽分割线=================
开始测试临时变量何时析构
entering test_2
C default constructor(),this=0x7fff5929b8d8
C default constructor(),this=0x7fff5929b8d0
leaving test_2
C nonconst copy constructor(),this=0x7fff5929ba68,reference=0x7fff5929b8d8
C destructor(),this=0x7fff5929b8d0
C destructor(),this=0x7fff5929b8d8
C destructor(),this=0x7fff5929ba68
结束测试临时变量何时析构
================华丽分割线=================
================下面开始析构栈里面的变量了,啦啦啦=================
================析构顺序按照入栈的顺序,后进先出,后构造,先析构===========
C destructor(),this=0x7fff5929ba80
C destructor(),this=0x7fff5929ba90
C destructor(),this=0x7fff5929ba98
C destructor(),this=0x7fff5929baa8
AlexdeMacBook-Pro:~ alex$
AlexdeMacBook-Pro:~ alex$
结论:
一:return by value时候编译器的优化
编译器在能够做优化的时候,会尽量帮你做优化,比如test_1,总是将栈里面的x直接给调用者,避免了多一次的析构和构造。即使在关闭编译器优化的时候,它依然给你做了这个动作。但是在test_2里面,返回值是动态的,随着参数变动而变动,编译器是没有办法得知保留哪个的,于是索性都析构了。
在Effective C++ Item 21,page 94, Don't try to return a reference when you must return an object.
作者说:C++和所有编程语言一样,允许编译器实现者施行最优化,用以改善产出码的效率却不改变其可观察的行为。
g++确实对此做了优化,但是动态返回值,编译器却无能为力。你无法要求编译器按照每个分支,生成不同的代码。否则在复杂的程序下,生成的可执行文件大小那将无法估计了
二:临时变了的析构时机
临时变量,总是在执行完生成临时变量的那一行代码之后析构
(是不是比较拗口?)
那就这样说吧:生成临时变量之后,遇到第一个分号,析构函数开始调用
C++函数返回值,你必须注意的问题

C++太繁杂了,先接触C++后接触python这样的语言,你就再也不想碰它,因为,就连一个函数返回值都一大堆的说道,这里面的玄机,连工作三年的C++熟手都未必能准确的理解和运用。
归根结底,C++所面临的问题要求它提供各种各样的机制以保证性能,也许,这辈子也见不到C++能安全有效的自己进行内存垃圾回收。。。。。
老程序猿都会提醒菜鸟,注意函数的返回值,因为,很可能,你的函数返回的数据在后续的使用中会出错。那么函数在返回值时要注意什么呢?
本篇博客尝试用最简练的普通大白话,讲解函数返回值的问题。
C++把内存交给了程序猿,但是,请你注意,它可没把所有的内存都交给你,交给你的只是堆上的内存,也就是你通过malloc函数 和new 关键字申请来的内存,除了这些内存以外,其他的内存,你最好别碰,最好别碰,最好别碰,重要的事情说三遍。
如果你的函数返回值在后续使用中出错了,尤其是返回函数内的局部变量这种事情,那么,基本可以肯定,你碰了不该碰的内存。这时候,你会觉得自己很冤枉啊,我没有啊。但事实是,没有冤枉你,所以,为了不被bug检察院起诉你,作为一个C++程序猿,你必须学会甄别那些内存是能碰的,那些内存是不能碰的。
char *pstr = "This is the buffer text";
return pstr;如果你的函数是这么写的,那么恭喜你,返回正确,因为这个pstr指向的是常量存储区,这里的内存,你是可以碰的,但是注意,这个碰,仅仅是读,你想修改,那是万万不可以的。
char buffer[] = "This is the buffer text";
return buffer; static char buffer[] = "This is the buffer text";
return buffer;函数返回的都是值拷贝,栈上的内存,在函数结束的时候,都会被收回。在函数内部,你可以碰栈上的内存,那是因为这个时候你是在栈的家里做客,那他们家的内存小花园当然允许你访问,可是函数结束了,就相当于你离开了栈的家,栈把内存小花园的门关上了,你怎么可以进去,你进去了,就会被bug联邦法院起诉!
但是呢,总有一些奇怪的现象让你以为你可以在函数结束后仍然可以访问栈上的内存。
我们定义一个结构体
struct person
{
int age;
}写一个函数
person* getperson2()
{
person p;
p.age = 99;
return &p;
} person *p2 = getperson2();
cout<<p2->age<<endl;你会发现,这段代码居然可以正确执行!在函数getperson2内部,p这个变量是局部变量,必然是在栈上申请的,返回的是&p,这不就是栈上的内存地址么,那为啥在函数外部,却仍然可以输出age呢?
虽然,函数结束后,对象被销毁,但是销毁的不够彻底,似乎计算机在管理内存时也不需要那么彻底的销毁一个对象,你之所以能输出age,那是因为那个区域,没有被彻底销毁,这一小块的内存(存储age的4个byte)没有发生变化。你可以暂时的碰这块内存,但迟早是要出问题的,如果某一刻,计算机打算用这块内存,发现你在非法使用,那么必然会报警,然后bug联邦检察院会起诉你。
为了让问题更透明一些,我们修改一下结构体
struct person
{
int age;
char* name;
person()
{
name = new char(10);
strcpy(name,"sheng");
}
~person()
{
name = NULL;
}
};person* getperson2()
{
person p;
p.age = 99;
return &p;
} person *p2 = getperson2();
cout<<p2->age<<endl;
cout<<p2->name<<endl;这一次,函数结束后,对象的销毁要比上一次彻底的多,虽然,age的区域还是没有被彻底销毁,但是name区域被彻底销毁了,如果你访问name的区域,就必然出错,这就好比啊,私家花园关门了,可是花园好大的,所以不是每一处都安装了摄像头和报警器,比如age这片区域,所以,你偷偷的从age这个区域溜进去时,花园的主人没发现,直到花园的巡防大队到age区域巡防时,发现你竟然在这里偷偷菜花,结果就是把你打的崩溃了。而name这边区域,在~person这个析构函数中安装了摄像头和报警器,你只要来,就立刻报警,然后把你打的崩溃。
千言万语,汇成一句话,函数不要返回指向栈的内存地址,切记,是地址,别被吓的所有的函数内的变量都不敢返回,只要不是栈的内存地址,你尽管放心的返回。
char *strA()
{
char str[] = "hello word";
return str;
}
上述程序有什么问题?
简单的来说,str是个局部变量的地址,作为返回值,有可能被提前回收。
那么局部变量可以作为函数的返回值吗,这个问题不能一概而论。局部变量作为返回值时,一般是系统先申请一个临时对象存储局部变量,也就是找个替代品,这样系统就可以回收局部变量,返回的只是个替代品。
了解完局部变量返回的过程,那么如果返回的是一个基本类型的变量,比如:
int a;
a = 5;
return a;
那么就会有一个临时对象也等于a的一个拷贝,即5返回,然后a就被销毁了。尽管a被销毁了,但它的副本5还是成功地返回了,所以这样做没有问题。
那么如果是指针,这么返回就问题很大,因为你返回的局部变量是地址,地址虽然返回了,但地址所指向的内存中的值已经被回收了,你主函数再去调,就有问题了。这个问题也是可以解决的,可以把局部变量变为静态变量或者全局变量,这样就不存放在栈中了,而是存放在静态存储区,不会被回收。
char str[] = "hello word";//分配一个局部变量
char *str= "hello word";//分配一个全局变量
C++中函数返回值是一个对象时的问题
问题描述
在C++程序中,一个函数返回值是一个对象时,返回的是函数内部的局部变量本身,
还是会产生一个中间对象(匿名对象)呢?
经过测试,在win平台和Linux平台效果不同
代码如下
//
// Created by YANHAI on 2019/5/28.
//
#include <iostream>
using namespace std;
class Test {
public:
Test(const char *name)
{
this->name = name;
printf("%s: 执行了构造函数, 我的地址是 %p\n", name, this);
}
Test(const Test &obj)
{
this->name = obj.name;
printf("%s: 执行了拷贝构造函数,我的地址是 %p,拷贝来自%s %p\n",
name.c_str(), this, obj.name.c_str(), &obj);
}
~Test()
{
printf("%s: 执行了析构函数, 我的地址是 %p\n", name.c_str(), this);
}
public:
string name;
};
Test fun()
{
Test t("我是在fun函数中创建的");
printf("in fun: %p\n", &t);
return t;
}
void test1()
{
// 这里t1对象就是fun函数里面创建的?
cout << "fun start.." << endl;
Test t1 = fun();
cout << "fun end.." << endl;
t1.name = "我是在test函数中被创建的";
printf("我是在test函数中被创建的对象,我的地址是: %p\n", &t1);
}
int main()
{
cout << "--------test1 start ...-----" << endl;
test1();
cout << "--------test1 end ...-----" << endl;
return 0;
}
测试过程
在win平台
使用VS2019编译并运行
运行结果:
--------test1 start ...-----
fun start..
我是在fun函数中创建的: 执行了构造函数, 我的地址是 010FFAC4
in fun: 010FFAC4
我是在fun函数中创建的: 执行了拷贝构造函数,我的地址是 010FFBD4,拷贝来自我是在fun函数中创建的 010FFAC4
我是在fun函数中创建的: 执行了析构函数, 我的地址是 010FFAC4
fun end..
我是在test函数中被创建的对象,我的地址是: 010FFBD4
我是在test函数中被创建的: 执行了析构函数, 我的地址是 010FFBD4
--------test1 end ...-----
过程解释:
- 在fun函数中,t对象被创建,执行t对象的构造函数(t对象地址为 010FFAC4)
- 在fun函数执行return时,会产生一个匿名对象,会执行匿名对象的拷贝构造函数,相当于执行了 Test tmp = t; (匿名对象tmp地址为010FFBD4)
- fun函数执行结束,局部变量对象t被释放,执行t对象的析构函数,fun函数将匿名对象(tmp)返回(返回的是010FFBD4地址的匿名对象)
- 在test1函数中,t1对象被创建时 使用了fun函数的返回值,故匿名对象tmp直接变为t1对象(而不是执行拷贝构造函数给t1,就比如执行了Test t1 = Test("xx");)(t1对象的地址即为匿名对象地址 010FFBD4)
- test1函数执行完毕后,t1对象被释放,执行t1的析构函数
在linux平台
使用g++编译
运行结果:
--------test1 start ...-----
fun start..
我是在fun函数中创建的: 执行了构造函数, 我的地址是 0x7ffe5a2488c0
in fun: 0x7ffe5a2488c0
fun end..
我是在test函数中被创建的对象,我的地址是: 0x7ffe5a2488c0
我是在test函数中被创建的: 执行了析构函数, 我的地址是 0x7ffe5a2488c0
--------test1 end ...-----
过程解释:
- 在fun函数中,t对象被创建,执行t对象的构造函数(t对象地址为 0x7ffe5a2488c0)
- 在fun函数结束时,并没有产生匿名对象,而是将t对象返回(返回的是0x7ffe5a2488c0地址的对象t)
- 在test1函数中,t1对象被创建时 使用了fun函数的返回值,故返回对象t直接变为t1对象(而不是执行拷贝构造函数给t1,就比如执行了Test t1 = Test("xx");)(t1对象的地址即为t对象地址 0x7ffe5a2488c0)
- test1函数执行完毕后,t1对象被释放,执行t1的析构函数
结论
- 在linux平台上,少产生了一个匿名对象,提高了执行效率
- 原本仅在fun函数内有效(局部变量生存周期)的t对象,由于被返回,在test1函数中仍然有效
南来地,北往的,上班的,下岗的,走过路过不要错过!
======================个性签名=====================
之前认为Apple 的iOS 设计的要比 Android 稳定,我错了吗?
下载的许多客户端程序/游戏程序,经常会Crash,是程序写的不好(内存泄漏?刚启动也会吗?)还是iOS本身的不稳定!!!
如果在Android手机中可以简单联接到ddms,就可以查看系统log,很容易看到程序为什么出错,在iPhone中如何得知呢?试试Organizer吧,分析一下Device logs,也许有用.

