
Welcome To Learn Dapper
This site is for developers who want to learn how to use Dapper - The micro ORM created by the people behind Stack Overflow.
QuerySingleOrDefault 查询记录集的数量

public bool IsExistXSDOrderByStockout_id(long stockout_id) { if (sqlConn.State != System.Data.ConnectionState.Open) { sqlConn.Open(); } using (SqlCommand sqlcmd = new SqlCommand()) { sqlcmd.CommandType = System.Data.CommandType.Text; sqlcmd.CommandText = string.Format(@" select count(*) from dycw{0}..tWDT_xsd_order_each where stockout_id = @stockout_id", DefaultAccID); sqlcmd.Connection = sqlConn; var resultQuery = sqlConn.QuerySingleOrDefault<int>(new CommandDefinition( sqlcmd.CommandText, new { stockout_id = stockout_id }, null, null, sqlcmd.CommandType, CommandFlags.None)); return resultQuery > 0; } }
What is Dapper?
Dapper is an open-source object-relational mapping (ORM) library for .NET and .NET Core applications. The library allows developers quickly and easily access data from databases without the need to write tedious code. Dapper allows you to execute raw SQL queries, map the results to objects, and execute stored procedures, among other things. It is available as a NuGet package.
- Dapper is lightweight and fast, making it an ideal choice for applications that require low latency and high performance.
- It is a simple yet powerful object mapping tool for any .NET language, such as C#, that enables developers to quickly and easily map query results from ADO.NET data readers to instances of business objects.
- It has excellent support for both asynchronous and synchronous database queries and batching multiple queries together into a single call.
- Additionally, dapper supports parameterized queries to help protect against SQL injection attacks.
Does Dapper support .NET Core?
Yes, Dapper has been supporting .NET Core since the release of version 1.50 in July 2016. Dapper is a cross-platform .NET library, which means that it can be used on any platform that supports .NET, including .NET Core.
Does Dapper support C#?
Yes, you can use Dapper with C# as multiple other languages, such as VB.NET and F#. In fact, Dapper was written in C# and is a popular choice for data access in C# applications because of its simplicity and efficiency.
Is Dapper an ORM?
Dapper falls into a family of tools known as micro-ORMs. These tools perform only a subset of the functionality of full-blown Object Relations Mappers, such as Entity Framework Core, but Dapper is known for its speed and simple implementation compared to others. The following table provides a general idea of the capabilities that you can expect to find in a micro ORM compared to an ORM:
| Micro ORM | ORM | |
|---|---|---|
| Map queries to objects | ||
| Caching results | ||
| Change tracking | 1 | |
| SQL generation | 2 | |
| Identity management | ||
| Association management | ||
| Lazy loading | ||
| Unit of work support | ||
| Database migrations | ||
Dapper concentrates its efforts on the O and M of ORM - Object Mapping.
[1] Some extensions have been added to Dapper that provide the minimal change-tracking capability
[2] Dapper does generate SQL but in a limited fashion. Third-party libraries such as Dapper Plus can generate the full SQL for insert, update, and delete statements
When Should You Use Dapper?
When deciding whether to use Dapper or not, one should bear in mind the primary reason for its existence - performance. The original developers of Dapper were using Entity Framework Core's predecessor - the short-lived Linq to SQL. However, they found that query performance wasn't good enough for the increasing traffic that the site in question (Stack Overflow) was experiencing, so they wrote their own micro ORM.
Dapper is, therefore, a good choice in scenarios where read-only data changes frequently and is requested often. It is particularly good in stateless scenarios (e.g. the web) where there is no need to persist complex object graphs in memory for any duration.
Dapper does not translate queries written in .NET languages to SQL like a full-blown ORM. So you need to be comfortable writing queries in SQL or have someone write them for you.
Dapper has no real expectations about the schema of your database. It is not reliant on conventions in the same way as Entity Framework Core, so Dapper is also a good choice where the database structure isn't particularly normalized.
Dapper works with an ADO.NET IDbConnection object, which means that it will work with any database system for which there is an ADO.NET provider.
There is no reason why you cannot use both an ORM and a micro ORM in the same project.
What does Dapper do?
Here is a standard ADO.NET C# code for retrieving data from a database and materializing it as a collection of Product objects:
var sql = "select * from products";
var products = new List<Product>();
using (var connection = new SqlConnection(connString))
{
connection.Open();
using (var command = new SqlCommand(sql, connection))
{
using (var reader = command.ExecuteReader())
{
var product = new Product
{
ProductId = reader.GetInt32(reader.GetOrdinal("ProductId")),
ProductName = reader.GetString(reader.GetOrdinal("ProductName")),
SupplierId = reader.GetInt32(reader.GetOrdinal("SupplierId")),
CategoryId = reader.GetInt32(reader.GetOrdinal("CategoryId")),
QuantityPerUnit = reader.GetString(reader.GetOrdinal("QuantityPerUnit")),
UnitPrice = reader.GetDecimal(reader.GetOrdinal("UnitPrice")),
UnitsInStock = reader.GetInt16(reader.GetOrdinal("UnitsInStock")),
UnitsOnOrder = reader.GetInt16(reader.GetOrdinal("UnitsOnOrder")),
ReorderLevel = reader.GetInt16(reader.GetOrdinal("ReorderLevel")),
Discontinued = reader.GetBoolean(reader.GetOrdinal("Discontinued")),
DiscontinuedDate = reader.GetDateTime(reader.GetOrdinal("DiscontinuedDate"))
};
products.Add(product);
}
}
}
At its most basic level, Dapper replaces the highlighted block of assignment code in the example above with the following:
products = connection.Query<Product>(sql).ToList();
Dapper also creates the command and opens the connection if needed. If you use Dapper to manage basic assignments like this, it will save you hours. However, Dapper is capable of doing quite a bit more.
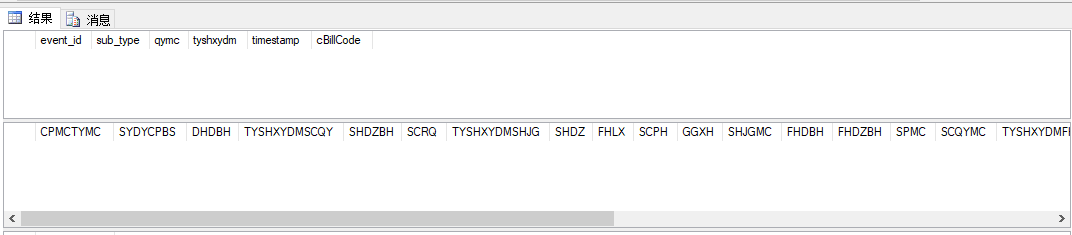
public static List<Entity_XSJL> getXSJL_ByDapper(string strConn, string accountSetsID, string accountSetsName) { using (System.Data.SqlClient.SqlConnection sqlConn = new SqlConnection(strConn)) { using (SqlCommand sqlcmd = new SqlCommand()) { sqlcmd.CommandType = System.Data.CommandType.StoredProcedure; sqlcmd.CommandText = string.Format("{0}..pGansu_Data_XSJL", accountSetsID); sqlcmd.Connection = sqlConn; using (var resultQuery = sqlConn.QueryMultiple(new CommandDefinition( sqlcmd.CommandText, new { dFromDate = Utils.BaseInfo.defaultStartDate }, null, null, sqlcmd.CommandType, CommandFlags.None))) { List<Entity_XSJL> listResult = new List<Entity_XSJL>(100); var timestamp = IoriUtilityLib.Iori.TimeUtil.GetTimeStamp(); var rowMain = resultQuery.Read<Entity_XSJL.Req>().ToList(); var rowSubAll = resultQuery.Read<Entity_XSJL.FhdInfoItem>().ToList(); foreach (var rowParent in rowMain) { rowParent.timestamp = timestamp; rowParent.dataSet.fhdInfo = rowSubAll.Where(exp => exp.cBillCode == rowParent.event_id).ToList(); Entity_XSJL entity = new Entity_XSJL() { req = rowParent, AccountSetsName = accountSetsName, AccountSetsID = accountSetsID }; listResult.Add(entity); } return listResult; } } } }
Handling Multiple Resultsets
While not a very common usage scenario, it can come handy sometimes
It may happen that you are interested in executing a batch of SQL commands whose results produce not only one resultset, but more than one. This helps to avoid doing additional roundtrips to the database. For example you can return suppliers and customers at once executing the following statement in the same command:
SELECT … FROM dbo.Suppliers;
SELECT … FROM dbo.Customers;
I’m not really fond of this approach, and if the two objects are independent from each other (like in the sample) I would rather prefer two separate asynchronous (parallel would even be better) calls to the database, but you don’t always have this option, or maybe you’re in a case where a plain and simple approach is preferred.
In any case, if you have multiple resultset, Dapper can help you, via the QueryMultiple method:
var results = conn.QueryMultiple(@"
SELECT Id, FirstName, LastName FROM dbo.Users;
SELECT Id, CompanyName FROM dbo.Companies
");
var users = results.Read<User>();
var companies = results.Read<Company>();
QueryMultiple returns a GridReader object that allows you to access the available resultset in sequence, from the first to the last. All you have to do is call the Read method, as shown in the above code, to access each results. Read behave exactly like the Query method we already discussed in the first article. In fact it supports all the specialized method that also Query supports
ReadFirstReadFirstOrDefaultReadSingleReadSingleOrDefault
all the Read methods can also be called asynchronously via ReadAsync.
A typical Use Case
So, even if not so common, a use case for such method exits, and is related to the necessity to create complex object with data coming from different tables.
Let’s go with another typical example here: Customers and Orders. You want to load a customer object with all related orders.
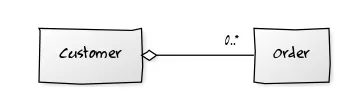
As one can guess, the Customer object has a list of Orders:

If you’re a database guy you probably immediately thought to solve the problem by joining Customers and Orders table

which will produce the following result:

Unfortunately there are a few problems with this approach from a developer perspective, even if the correct one from a database perspective.
The first problem is that we had to create column name alias, since both the tables have the Id column. By default Dapper maps columns to properties by name matching, and thus the introduced alias will prevent this native behavior to work properly. As we’ll see in a future article, we can handle this case, but it will make our code a little bit more complex. And I don’t like making the code complex of such small thing: introducing complexity when it is not really needed is always a bad idea.
The second problem is that the resultset have has many rows as many orders the customer placed. This in turn means that customer data (Id and Name in the example) is returned for each order. Now, beside the fact that this will waste bandwidth, impacting on overall performance and resource usage, we also have to make sure that we actually create just one Customer object. Dapper won’t do that for us, so, again, additional complexity needs to be introduced.
As you can understand, the two aforementioned problems prevent the usage of the SELECT…JOIN approach with Dapper. The correct solution is to query the Customer table and create the single Customer object and then query the Order table, create the Order objects and the link them to the created customer.
To avoid doing two roundtrips to the database to get customer and orders data separately, the multiple resultset feature can be used:
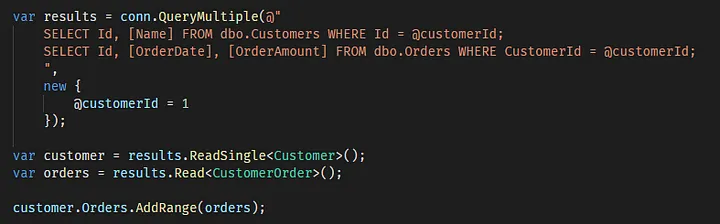
Of course in case you’re dealing with multiple commands like above you may also want to make sure you wrap everything in a transaction, to assure data consistency. Transaction support will be discussed in a future post but in case you want to go forward, know that Dapper supports transaction via the TransactionScope option.
Samples
As usual an example that shows how to use the discussed feature is available here:
yorek/dapper-samples
dapper-samples - Samples that shows how to use Dapper .NET
github.com
Conclusions
The described feature helps to solve a very specific problem, keeping the performance high and the code clean, but has a big limitation: what if, in addition to the Order we also decided to get the Order Items? The discussed feature wouldn’t have helped and we would had to do a separate query to the database, for each order, to get the related items. Really not good for performance. Luckily if your database supports JSON, (SQL Server 2016 and after and Azure SQL both supports it) there are a much better and powerful way to elegantly solve the problem of mapping rows to complex objects. We’ll discuss it very soon.
What’s next
Next article will be dedicated to a feature somehow related with what discussed here: “Multiple Mapping” or automatically mapping a single row to multiple objects.
Querying Multiple Results With Dapper
You can execute multiple queries in a single SQL statement using the QueryMultiple method (if the database provider supports it). Once executed, you can map the returned results to multiple objects using methods such as Read<T>, ReadFirst<T>, ReadSingle<T> and more.
The Dapper QueryMultiple method allows you to select multiple results from a database query. That feature is very useful for selecting multiple results sets at once, thus avoiding unnecessary round trips to the database server.
- The
QueryMultiplemethod provides a simple way of fetching data stored in different tables or views with a single database query. - By using dapper's
QueryMultiplemethod, you can select multiple rows from different tables in one go, saving time and resources. - Dapper's
QueryMultiplemethod allows you to map results from multiple queries into strongly typed collections that can be easily consumed within your application code. - Using Dapper
QueryMultipleis an efficient way to select multiple results from a single database query. - It saves time and resources by avoiding unnecessary round trips to the database server and eliminates the need for complex SQL queries.
| Method | Description |
|---|---|
QueryMultiple |
Execute multiple queries within a single database command and return a GridReader to map the results to multiple objects |
QueryMultipleAsync |
Execute multiple queries within a single database command and return a GridReader to map the results to multiple objects asynchronously |
After using the QueryMultiple or QueryMultipleAsync method, you can use the following methods with the results:
| Method | Description |
|---|---|
Read, ReadAsync |
Returns an enumerable of dynamic types |
Read<T>, ReadAsync<T> |
Returns an enumerable of the type specified by the T parameter |
ReadFirst, ReadFirstAsync |
Returns the first row as a dynamic type |
ReadFirst<T>, ReadFirstAsync<T> |
Returns the first row as an instance of the type specified by the T type parameter |
ReadFirstOrDefault, ReadFirstOrDefaultAsync |
Returns the first row as a dynamic type or null if no results are returned |
ReadFirstOrDefault<T>, ReadFirstOrDefaultAsync<T> |
Returns the first row as an instance of the type specified by the T type parameter or null if no results are returned |
ReadSingle, ReadSingleAsync |
Use when only one row is expected to be returned. Returns a dynamic type |
ReadSingle<T>, ReadSingleAsync<T> |
Use when only one row is expected to be returned. Returns an instance of the type specified by the T type parameter |
ReadSingleOrDefault, ReadSingleOrDefaultAsync |
Use when zero or one row is expected to be returned. Returns a dynamic type or null |
ReadSingleOrDefault<T>, ReadSingleOrDefaultAsync<T> |
Use when zero or one row is expected to be returned. Returns an instance of the type specified by the T type parameter or null |
Dapper QueryMultiple
The following example demonstrates how to use Dapper QueryMultiple to execute multiple SQL statements in one query.
string sql = @"
SELECT * FROM Invoices WHERE InvoiceID = @InvoiceID;
SELECT * FROM InvoiceItems WHERE InvoiceID = @InvoiceID;
";
using (var connection = new SqlConnection(connectionString))
{
using (var multi = connection.QueryMultiple(sql, new {InvoiceID = 1}))
{
var invoice = multi.First<Invoice>();
var invoiceItems = multi.Read<InvoiceItem>().ToList();
}
}
With this, we can execute multiple SQL statements in one query and read each result set from the GridReader object returned by the QueryMultiple method. That can help increase the performance of your application in cases where multiple queries need to be executed and their results combined.
Using Dapper QueryMultiple is a great way to simplify data access and ensure that your application runs quickly and efficiently. With its easy-to-use API, you can quickly set up complex queries and access the data you need.
Dapper QueryMultipleAsync
The asynchronous version of the QueryMultiple<T> method is QueryMultipleAsync<T>:
string sql = @"
SELECT * FROM Invoices WHERE InvoiceID = @InvoiceID;
SELECT * FROM InvoiceItems WHERE InvoiceID = @InvoiceID;
";
using (var connection = new SqlConnection(connectionString))
{
using (var multi = await connection.QueryMultipleAsync(sql, new {InvoiceID = 1}))
{
var invoice = await multi.FirstAsync<Invoice>();
var invoiceItems = await multi.ReadAsync<InvoiceItem>().ToList();
}
}
Related Articles
Working with database with C# (3 Part Series)
Learn how to read reference table from SQL-Server using a single method. What is shown provides an efficient way to either use a connection, command objects to read data via a SqlDataReader for conventional work using methods from SqlClient and also Dapper which requires two lines of code to read data and one line of code to store data into list.
Goal
To read from three reference table in a modified version of Microsoft NorthWind database, Categories, ContactType and Countries tables.
In all code samples all records are read from each table, in some cases not all records may be needed, simply change the SQL SELECT statement with a WHERE clause. Also, the same goes for columns.
Project type used
A console project is used although the code provided will work in any project type.
Creating the database
Open SSMS (SQL-Server Management Studio), create a new database named Northwind2020, run the script under the Scripts folder.
Required models
Each model has properties matching columns in the tables we will read from, not all columns are included in some tables.
The override ToString can be helpful in some cases for instance in a control or component that needs to know what to display, for example a ComboBox.
public class Categories
{
public int CategoryId { get; set; }
public string CategoryName { get; set; }
public override string ToString() => CategoryName;
}
public class ContactType
{
public int ContactTypeIdentifier { get; set; }
public string ContactTitle { get; set; }
public override string ToString() => ContactTitle;
}
public class Countries
{
public int CountryIdentifier { get; set; }
public string Name { get; set; }
public override string ToString() => Name;
}
Master model
Which is used to return data from two methods which could return three classes rather than one although it makes sense to return just one instance of a class.
public class ReferenceTables
{
public List<Categories> CategoriesList { get; set; } = new List<Categories>();
public List<ContactType> ContactTypesList { get; set; } = new List<ContactType>();
public List<Countries> CountriesList { get; set; } = new List<Countries>();
}
Connection string
First off, the connection string is stored in appsettings.json and read via a NuGet package ConfigurationLibrary.
Convention method to read multiple tables
The key is that the command object can handle multiple SELECT statements as done with the following. These statements are used for the following code sample and two other code samples.
- await using var reader = await cmd.ExecuteReaderAsync(); reads the data.
- The first while statements reads from Categories table as it is the first statement from the statements in SqlStatements.ReferenceTableStatements.
- await reader.NextResultAsync(); tells the reader to work on ContactType table
- The second while reads ContactType records
- await reader.NextResultAsync(); tells the reader to work on Countries table
- The third while reads Countries table data.
- If there are no exceptions, referenceTables has all three tables data populated, otherwise the call to this method tells the caller a failure occurred and returns the Exception which can be logged.
internal class SqlStatements
{
/// <summary>
/// Statements to read reference tables for Categories, ContactType and Countries tables.
/// </summary>
public static string ReferenceTableStatements =>
"""
SELECT CategoryID,CategoryName FROM dbo.Categories;
SELECT ContactTypeIdentifier,ContactTitle FROM dbo.ContactType;
SELECT CountryIdentifier,[Name] FROM dbo.Countries;
""";
}
public static async Task<(bool success, Exception exception)> GetReferenceTables(ReferenceTables referenceTables)
{
await using SqlConnection cn = new(ConnectionString());
await using SqlCommand cmd = new()
{
Connection = cn, CommandText = SqlStatements.ReferenceTableStatements
};
try
{
await cn.OpenAsync();
await using var reader = await cmd.ExecuteReaderAsync();
while (await reader.ReadAsync())
{
referenceTables.CategoriesList.Add(new Categories()
{
CategoryId = reader.GetInt32(0),
CategoryName = reader.GetString(1)
});
}
await reader.NextResultAsync();
while (await reader.ReadAsync())
{
referenceTables.ContactTypesList.Add(new ContactType()
{
ContactTypeIdentifier = reader.GetInt32(0),
ContactTitle = reader.GetString(1)
});
}
await reader.NextResultAsync();
while (await reader.ReadAsync())
{
referenceTables.CountriesList.Add(new Countries()
{
CountryIdentifier = reader.GetInt32(0),
Name = reader.GetString(1)
});
}
return (true, null);
}
catch (Exception localException)
{
return (false, localException);
}
}
DataSet method to read multiple tables
In this sample, the same SQL statement is feed to the command object as done in the prior example, a SqlDataAdapter is linked to the command object which populates all three DataTables in a DataSet.
The adapter internally populates the three tables with a private method FillInternal.
public static async Task<(bool success, Exception exception, DataSet dataSet)> GetReferenceTablesDataSet()
{
DataSet ds = new();
try
{
SqlDataAdapter adapter = new();
await using SqlConnection cn = new(ConnectionString());
SqlCommand command = new(SqlStatements.ReferenceTableStatements, cn);
adapter.SelectCommand = command;
adapter.Fill(ds);
ds.Tables[0].TableName = "Categories";
ds.Tables[1].TableName = "ContactType";
ds.Tables[2].TableName = "Countries";
return (true, null, ds);
}
catch (Exception localException)
{
return (false, localException, null);
}
}
Dapper method to read multiple tables
Using Dapper is the most efficient method, no command obect required as per below, instead we use QueryMultipleAsync to read data using the same SQL statements in the last two samples.
Once QueryMultipleAsync has executed the list are populated and available as in the first sample.
public static async Task GetReferenceTablesDapper(ReferenceTables referenceTables)
{
await using SqlConnection cn = new(ConnectionString());
SqlMapper.GridReader results = await cn.QueryMultipleAsync(SqlStatements.ReferenceTableStatements);
referenceTables.CategoriesList = results.Read<Categories>().ToList();
referenceTables.ContactTypesList = results.Read<ContactType>().ToList();
referenceTables.CountriesList = results.Read<Countries>().ToList();
}
Program.cs
Each sample is broken down into separate methods but data is not displayed. Place a break point at the end of each method and view data in the local window.
using GitHubSamples.Classes;
namespace GitHubSamples;
internal partial class Program
{
static async Task Main(string[] args)
{
await StandardSample();
await DataSetSample();
await DapperSample();
AnsiConsole.MarkupLine("[yellow]Press ENTER to exit[/]");
Console.ReadLine();
}
private static async Task StandardSample()
{
ReferenceTables referenceTables = new();
var (success, exception) = await DataOperations.GetReferenceTables(referenceTables);
Console.WriteLine(success
? "Success reading to classes"
: $"Class operation failed with \n{exception.Message}");
}
private static async Task DapperSample()
{
ReferenceTables referenceTables = new();
await DataOperations.GetReferenceTablesDapper(referenceTables);
}
private static async Task DataSetSample()
{
var (success, exception, dataSet) = await DataOperations.GetReferenceTablesDataSet();
Console.WriteLine(success
? "Success reading to DataSet"
: $"DataSet operation failed with \n{exception.Message}");
}
}
Example for the Dapper sample
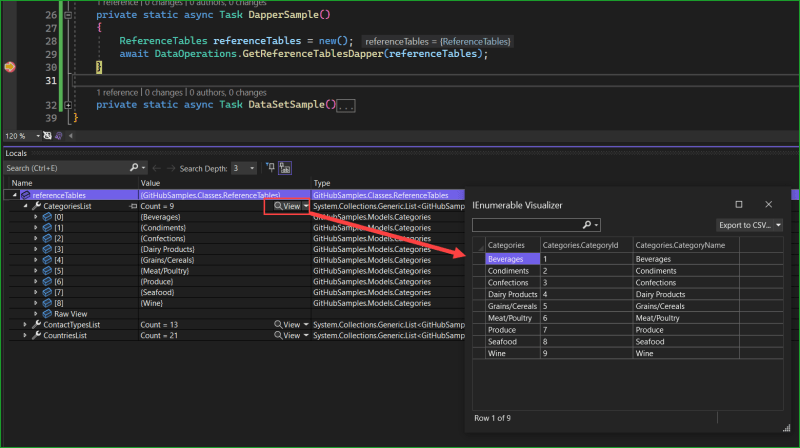
Stored procedure sample
Some developer rather using stored procedures, Dapper makes this easy.
Some benefits
- Execution Plan Retention and Reuse (SP are compiled and their execution plan is cached and used again to when the same SP is executed again)
- Network bandwidth conservation
- Improved security
- Sharing of application logic between applications
Some disadvantages
- Difficult to debug
- A DBA may be required to access the SQL and write a better stored procedure. This will automatically incur added cost.
- Complex stored procedures will not always port to upgraded versions of the same database. This is specially true in case of moving from one database type(Oracle) to another database type(MS SQL Server).
I have worked for several agencies/companies were the security was so tight a developer could not even see a stored procedure definition, that made it difficult to debug. Working as a contractor with pre-existing stored procedures can be a nightmare.
Here is the Stored Procedure
SET ANSI_NULLS ON;
GO
SET QUOTED_IDENTIFIER ON;
GO
CREATE PROCEDURE dbo.usp_SelectCatCountryContactType
AS
BEGIN
SELECT CategoryID,
CategoryName
FROM dbo.Categories;
SELECT ContactTypeIdentifier,
ContactTitle
FROM dbo.ContactType;
SELECT CountryIdentifier,
Name
FROM dbo.Countries;
END;
GO
Tips on creating stored procedures for novice developer
- Find a good course on a web site offering courses on stored procedures and/or on Pluralsight.
- Purchase Redgate SQL-Prompt which will create stored procedures from an existing SQL statement in SSMS. My favorite features are intellisense for writing SQL, formatting of SQL, statement refactoring are just a few of the cool features in SQL-Prompt.
Code
public static async Task GetReferenceTablesDapperStoredProcedure(ReferenceTables referenceTables)
{
await using SqlConnection cn = new(ConnectionString());
SqlMapper.GridReader results = await cn.QueryMultipleAsync(
"usp_SelectCatCountryContactType",
null,
null,
null,
CommandType.StoredProcedure);
referenceTables.CategoriesList = results.Read<Categories>().ToList();
referenceTables.ContactTypesList = results.Read<ContactType>().ToList();
referenceTables.CountriesList = results.Read<Countries>().ToList();
}
Produces the same results as the first Dapper example above.
Summary
What has been presented can assist with reading two or more reference tables at once without the need for multiple connection and command objects using multiple data readers and best of all for some an introduction into using Dappper.
NuGet packages
- ConfigurationLibrary for reading connection strings from appsetting when using Windows forms, Consol project where a developer is not using dependency injection.
- Dapper is an open-source object-relational mapping (ORM) library for .NET and .NET Core applications. The library allows developers quickly and easily access data from databases without the need to write tedious code.
- Microsoft.Data.SqlClient namespace is the .NET Data Provider for SQL Server.
Source code
In the following project which can be cloned from the following GitHub repository.
See also
The art of Deconstructing which explains how in this article data is returned to methods in Program.cs
数据点 - Dapper、Entity Framework 和混合应用
作者 Julie Lerman
.jpg "Julie Lerman") 你大概注意到了,自 2008 年以来,我写过许多关于 Entity Framework(即 Microsoft 对象关系映射器 (ORM))的文章,ORM 一直是主要的 .NET 数据访问 API。市面上还有许多其他 .NET ORM,但是有一个特殊类别因其强大的性能得到的关注最高,那就是微型 ORM。我听人提到最多的微型 ORM 是 Dapper。据不同的开发者说,他们使用 EF 和 Dapper 制定了混合解决方案,让每个 ORM 能够在单个应用程序中做它最擅长的事,这最终激发了我的兴趣,促使我在最近抽出时间来一探究竟。
你大概注意到了,自 2008 年以来,我写过许多关于 Entity Framework(即 Microsoft 对象关系映射器 (ORM))的文章,ORM 一直是主要的 .NET 数据访问 API。市面上还有许多其他 .NET ORM,但是有一个特殊类别因其强大的性能得到的关注最高,那就是微型 ORM。我听人提到最多的微型 ORM 是 Dapper。据不同的开发者说,他们使用 EF 和 Dapper 制定了混合解决方案,让每个 ORM 能够在单个应用程序中做它最擅长的事,这最终激发了我的兴趣,促使我在最近抽出时间来一探究竟。
在阅读大量文章和博客文章,与开发者聊过天并熟悉过 Dapper 后,我想与大家分享我的一些发现,尤其是和像我这样,可能听说过 Dapper 但并不知道它是什么或者并不知道它的工作原理的人分享,同时说说人们为什么这么喜欢它。需要提醒你的是,我根本不是什么专家。目前我只是为了满足我的好奇心而变得足够了解,并且希望激发你的兴趣,从而进一步探索。
为什么是 Dapper?
Dapper 的历史十分有趣,它是从你可能再熟悉不过的资源中衍生的: Marc Gravell 和 Sam Saffron 在研究 Stack Overflow,解决此平台的性能问题时构建了 Dapper。考虑到 Stack Overflow 是一个流量极高的站点,那么必然存在性能上的问题。根据 Stack Exchange About 网页,在 2015 年,Stack Overflow 拥有 57 亿的网页浏览量。在 2011 年,Saffron 撰写过一篇关于他和 Gravell 所做的工作的博客文章,名为“我如何学会不再担忧和编写我自己的 ORM”(bit.ly/),这篇文章介绍了 Stack 当时存在的性能问题,该问题源于 LINQ to SQL 的使用。他在文中详细介绍了为什么编写自定义 ORM,其中 Dapper 就是优化 Stack Overflow 上的数据访问的答案。五年后的今天,Dapper 已被广泛使用并已成为开源软件。Gravell 和 Stack 及团队成员 Nick Craver 继续在 github.com/StackExchange/dapper-dot-net 上积极地管理项目。
Dapper 简介
Dapper 主要能够让你练习你的 SQL 技能,按你认为的那样构建查询和命令。它接近于“金属”而非标准的 ORM,免除了解释查询的工作,例如将 LINQ to EF 解释为 SQL。Dapper 不具备炫酷的转换功能,比如打散传递到 WHERE IN 从句的列表。但在大多数情况下,你发送到 Dapper 的 SQL 已准备好运行,而查询可以更快地到达数据库。如果你擅长 SQL,那么你将有把握编写性能最高的命令。你需要创建某些类型的 IDbConnection 来执行查询,比如带有已知连接字符串的 SqlConnection。然后,Dapper 可以通过其 API 为你执行查询以及—假如查询结果的架构与目标类型的属性相匹配—自动实例化对象并向对象填充查询结果。此处还有另一个显著的性能优势: Dapper 能够有效缓存它获悉的映射,从而实现后续查询的极速反序列化。我将填充的类 DapperDesigner(如**图 1 中所示)**被定义用来管理构建整齐构架的设计器。
图 1 DapperDesigner 类
public class DapperDesigner
{
public DapperDesigner() {
Products = new List<Product>();
Clients = new List<Client>();
}
public int Id { get; set; }
public string LabelName { get; set; }
public string Founder { get; set; }
public Dapperness Dapperness { get; set; }
public List<Client> Clients { get; set; }
public List<Product> Products { get; set; }
public ContactInfo ContactInfo { get; set; }
}
我执行查询的项目引用了我通过 NuGet 获取的 Dapper(安装包 dapper)。下面是从 Dapper 调用以为 DapperDesigners 表中所有行执行查询的示例:
var designers = sqlConn.Query<DapperDesigner>("select * from DapperDesigners");
需要注意的是,对于本文中的代码清单,当我希望使用表中的所有列时,我使用的是 select * 而非明确投影的查询列。sqlConn 连同其连接字符串是现有的实例化 SqlConnection 对象,但是尚未打开过。
Query 方法是 Dapper 提供的扩展方法。在此行执行时,Dapper 打开连接,创建 DbCommand,准确地按照我编写的内容执行查询,实例化结果中的每行的 DapperDesigner 对象并将值从查询结果推送到对象的属性。Dapper 可以通过几种方式将结果值与属性进行匹配,即使属性名称与列名称不相匹配,又或者即使属性的顺序与匹配的列的顺序不同。它不会读心术,所以别期望它弄清涉及的映射,例如列的顺序或名称和属性不同步的大量字符串值。我确实用它做了几个奇怪的实验,我想看看它如何响应,同时我也配置了控制 Dapper 如何推断映射的目标设置。
Dapper 和关系查询
我的 DapperDesigner 类型拥有多种关系,比如一对多(与产品)、一对一 (ContactInfo) 和多对多(客户端)。我已经试验过跨这些关系执行查询,而且 Dapper 能够处理这些关系。这绝对不像使用 Include 方法或投影表述 LINQ to EF 查询那么简单。我的 TSQL 技能被推到极限,这是因为 EF 在过去几年让我变得如此懒惰。
下面是使用我在数据库中使用 SQL 进行跨一对多关系的查询的示例:
var sql = @"select * from DapperDesigners D
JOIN Products P
ON P.DapperDesignerId = D.Id";
var designers= conn.Query<DapperDesigner, Product,DapperDesigner>
(sql,(designer, product) => { designer.Products.Add(product);
return designer; });
注意 Query 方法要求我指定两种必须构建的类型,并指示要返回的类型—由最终类型参数 (DapperDesigner) 表述。我首先使用多行匿名函数构建图表,将相关产品添加到其父设计器对象,然后将每个设计器返回到 Query 方法返回的 IEnumerable。
通过我对 SQL 的最佳尝试,这样做的不利之处在于结果是扁平的,就像使用 EF Include 方法时一样。每个产品我将获取一行并复制一下设计器。Dapper 拥有可以返回多个结果集的 MultiQuery 方法。与 Dapper 的 GridReader 组合,这些查询的性能肯定将胜过 EF Includes。
编码难度加大,执行速度变快
表述 SQL 并填充相关对象是我让 EF 在此背景中处理的任务,所以需要更多精力来编码。但是如果你要处理的数据量很大,那么运行时性能非常重要,这当然值得努力。在我的示例数据库中拥有 30,000 个设计器。仅有几个拥有产品。我做了一些简单的基准测试,确保我所做的是同类比较。在查看测试结果前,有些关于我如何测量的重点需要大家理解。
请记住,默认情况下,EF 的设计目的是跟踪为查询结果的对象。这意味着它创建了额外的跟踪对象(需要做一些工作),并且它也需要与这些跟踪对象互动。而 Dapper 只是将结果转储到内存。所以当进行性能对比时,让 EF 的更改跟踪不再循环非常重要。为此,我使用 AsNoTracking 方法定义我的所有 EF 查询。同时,当对比性能时,你需要应用大量的标准基准模式,比如给数据库热身、反复执行查询以及抛弃最慢时间和最快时间。你可以看到我如何在下载示例中构建我的基准测试的详情。我仍然认为这些测试是“轻量级”基准测试,此处只是为了展现差异。对于较高的基准,你需要多次迭代(500 次以上),而我只进行了 25 次,这是远远不够的,同时还需要将你运行的系统的性能考虑在内。我在笔记本上使用 SQL Server LocalDB 实例进行这些测试,所以我的结果仅用于比较。
我在测试中跟踪的的时间为执行查询和构建结果的时间。未计入实例化连接或 DbContexts 的时间。因为反复使用 DbContext,所以构建内存内模型的时间不计入内,因为每个应用程序示例仅构建一次,而不是每个查询都要构建。
图 2 显示了 Dapper 和 EF LINQ 查询的“select *”测试,从中你可以看到我的测试模式的基本构造。注意,除收集实际时间外,我还在收集每次迭代的时间并整理到列表(名为“时间”)中以供进一步分析。
图 2 查询所有 DapperDesigners 时 EF 与 Dapper 的对比测试
[TestMethod,TestCategory("EF"),TestCategory("EF,NoTrack")]
public void GetAllDesignersAsNoTracking() {
List<long> times = new List<long>();
for (int i = 0; i < 25; i++) {
using (var context = new DapperDesignerContext()) {
_sw.Reset();
_sw.Start();
var designers = context.Designers.AsNoTracking().ToList();
_sw.Stop();
times.Add(_sw.ElapsedMilliseconds);
_trackedObjects = context.ChangeTracker.Entries().Count();
}
}
var analyzer = new TimeAnalyzer(times);
Assert.IsTrue(true);
}
[TestMethod,TestCategory("Dapper")
public void GetAllDesigners() {
List<long> times = new List<long>();
for (int i = 0; i < 25; i++) {
using (var conn = Utils.CreateOpenConnection()) {
_sw.Reset();
_sw.Start();
var designers = conn.Query<DapperDesigner>("select * from DapperDesigners");
_sw.Stop();
times.Add(_sw.ElapsedMilliseconds);
_retrievedObjects = designers.Count();
}
}
var analyzer = new TimeAnalyzer(times);
Assert.IsTrue(true);
}
关于同类对比,还有一个问题。 Dapper 使用原始 SQL。默认情况下,使用 LINQ to EF 表述 EF 查询并且必须做一些工作才能为你构建 SQL。一旦构建好 SQL,即使是依靠参数的 SQL,它将被缓存到应用程序的内存,以减少重复工作。此外,EF 可以使用原始 SQL 执行查询,所以我考虑到了这两种方法。图 3 列出了四组测试的对比结果。下载包含更多测试。
图 3 基于 25 次迭代执行查询和填充对象的平均时间(以毫秒计),排除最快和最慢时间
| *AsNoTracking 查询 | 关系 | LINQ to EF* | EF Raw SQL* | Dapper Raw SQL |
| 所有设计器(3 万行) | – | 96 | 98 | 77 |
| 所有带产品的设计器(3 万行) | 1 : * | 251 | 107 | 91 |
| 所有带客户端的设计器(3 万行) | * : * | 255 | 106 | 63 |
| 所有带联系人的设计器(3 万行) | 1 : 1 | 322 | 122 | 116 |
在 图 3 显示的场景中,我们可以很容易地跨 LINQ to Entities 使用 Dapper 制作一个案例。但是原始 SQL 查询之间的细微差异可能不总是在使用 EF 的系统中为特定任务切换到 Dapper 的正当理由。理所当然,大家的需求各有不同,所以这可能影响 EF 查询和 Dapper 之间的差异程度。但是,在 Stack Overflow 等高流量系统中,甚至是每个查询保存的大量毫秒时间都可能至关重要。
用于其他暂留需求的 Dapper 和 EF
到目前为止,我测量了简单查询,并在其中从所返回类型的准确匹配属性的表中回拉所有列。如果你将查询投影到类型会如何呢? 只要结果构架与类型相匹配,Dapper 将无法观察到创建对象的差异。但是,如果投影结果与为属于模型一部分的类型不一致,EF 不得不多做些工作。
DapperDesignerContext 拥有一个针对 DapperDesigner 类型的 DbSet。在我的系统中有另一个名为 MiniDesigner 的类型,它拥有一个 DapperDesigner 属性的子集。
public class MiniDesigner {
public int Id { get; set; }
public string Name { get; set; }
public string FoundedBy { get; set; }
}
MiniDesigner 不属于我的 EF 数据模型,所以 DapperDesignerContext 不知道这种类型。我发现与使用借用原始 SQL 的 EF 相比,使用 Dapper 查询所有这 30,000 行并将其投影到 30,000 个 MiniDesigner 对象要快 25%。我再次建议你做自己的性能分析,并为你自己的系统做出决策。
Dapper 也可用于将数据推送到数据库,其中包含允许你识别必须用于命令指定参数的属性的方法,不论你使用的是原始 INSERT 或 UPDATE 命令,还是对数据库执行函数或存储过程。我并没有对这些任务做任何性能对比。
现实世界中的混合 Dapper 和 EF
有许多将 Dapper 用于 100% 数据暂留的系统。但是回忆起来,我的兴趣是由谈论混合解决方案的开发者激起的。在某些情况下,还存在已有 EF 并希望微调特定问题区域的系统。在其他情况下,团队选择使用 Dapper 执行所有查询,使用 EF 执行所有保存。
有人回复了我在 Twitter 上发布的关于这方面的问题,答案千变万化。
@garypochron 告诉我他的团队“将 Dapper 用于高需区域并使用资源文件维护 SQL 的组织。“ 而热门 EF Reverse POCO Generator 的作者 Simon Hughes (@s1monhughes) 的习惯恰好相反—默认使用 Dapper,遇到棘手问题时则使用 EF,对此我感到很吃惊。他告诉我“只要可能,我都会使用 Dapper。如果是比较复杂的更新,我会使用 EF。”
我也见过各种混合方法是由于要分离关注点而非提高性能而推动的讨论。最常见的讨论是利用 EF 上的 ASP.NET Identity 的默认依赖性,然后在解决方案中使用 Dapper 进行其余存储。
除性能外,更直接地处理数据库还拥有其他优点。SQL Server 专家 Rob Sullivan (@datachomp) 和 Mike Campbell (@angrypets) 也对 Dapper 青睐有加。Rob 指出你可以利用 EF 不允许访问的数据库功能,比如全文搜索。从长期来看,特殊功能是关于性能的。
另一方面,有些任务只能使用 EF 完成,使用 Dapper 根本完成不了(更改跟踪除外)。一个很好的例子是我在构建为本文创建的解决方案时利用的功能—即使用 EF Code First Migrations 在模型更改时迁移数据库的能力。
Dapper 并不适合每一个人。@damiangray 告诉我 Dapper 不是他的解决方案之选,因为他需要能够将 IQueryables(不是真实数据)从系统的一部分返回到另一部分。这个推迟执行查询的主题已在 Dapper 的 GitHub 存储库中提出,如果你想详细了解此主题,请访问 bit.ly/22CJzJl。在设计混合系统时,使用 Command Query Separation (CQS) 是个不错的方法,你可以在其中为特定类型的交易设计独立的模型,至少我着迷于此。这样一来,你不必设法去构建普通的数据访问代码以使用 EF 和 Dapper,因为构建此代码通常会牺牲每个 ORM 的好处。在我创作这篇文章时,Kurt Dowswell 发布了一篇名为“Dapper、EF 和 CQS”(bit.ly/1LEjYvA) 的博文。对我来说得心应手,对你来说亦是如此。
对于那些期待 CoreCLR 和 ASP.NET Core 的人来说,Dapper 已演变为能够支持这些功能的软件。你可以在 Dapper 的 GitHub 存储库中的文章 (bit.ly/1T5m5Ko) 中找到更多信息。
最后,我看了看 Dapper。我认为怎么样?
我怎么样? 我很遗憾没能尽早正视 Dapper,同时也因最终实现了愿望而感到很高兴。我始终推荐 AsNoTracking 或建议使用数据库中的视图或过程缓解性能问题。它从未让我或我的客户失望过。但是现在我知道我还有另一招妙计要推荐给对从使用 EF 的系统中榨出更多性能感兴趣的开发者。这不是我们所谓的稳操胜券。我的建议将用来探索 Dapper、测量性能差异(大规模)以及找到性能与编码难度之间的平衡点。想想 StackOverflow 的显著用途:查询问题、注释和答案,然后连同一些元数据(编辑)和用户信息返回附有注释和答案的问题图表。它们反复执行相同类型的查询并标绘出相同形状的结果。Dapper 的设计更擅长这种类型的反复查询,并且每次都会变得更智能、更快速。即使你的系统中没有设计为供 Dapper 处理的海量交易,你也可能找到满足你需求的混合解决方案。
Julie Lerman是 Microsoft MVP、.NET 导师和顾问,住在佛蒙特州的山区。您可以在全球的用户组和会议中看到她对数据访问和其他 .NET 主题的演示。她的博客地址是 thedatafarm.com/blog。她是“Entity Framework 编程”及其 Code First 和 DbContext 版本(全都出版自 O’Reilly Media)的作者。通过 Twitter 关注她:@julielerman 并在 juliel.me/PS-Videos 上观看其 Pluralsight 课程。
衷心感谢以下 Stack Overflow 技术专家对本文的审阅: Nick Craver 和 Marc Gravell
Nick Craver (@Nick_Craver) 既是开发者,又是网站可靠性工程师,同时兼职 Stack Overflow 的 DBA。他擅长各层、总体系统体系结构和数据中心硬件的性能调节以及 Opserver 等开源项目的维护。访问 了解他的相关信息。
Marc Gravell 是 Stack Overflow 的开发者,主要专注于高性能库和 .NET 工具,尤其是数据访问、序列化、网络 API,为这些领域的一系列开源项目做出了贡献。
南来地,北往的,上班的,下岗的,走过路过不要错过!
======================个性签名=====================
之前认为Apple 的iOS 设计的要比 Android 稳定,我错了吗?
下载的许多客户端程序/游戏程序,经常会Crash,是程序写的不好(内存泄漏?刚启动也会吗?)还是iOS本身的不稳定!!!
如果在Android手机中可以简单联接到ddms,就可以查看系统log,很容易看到程序为什么出错,在iPhone中如何得知呢?试试Organizer吧,分析一下Device logs,也许有用.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
2015-06-19 Mac OS 后台服务注册