
16 | “order by”是怎么工作的?
在你开发应用的时候,一定会经常碰到需要根据指定的字段排序来显示结果的需求。还是以我们前面举例用过的市民表为例,假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回前1000个人的姓名、年龄。
假设这个表的部分定义是这样的:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
这时,你的SQL语句可以这么写:
select city,name,age from t where city='杭州' order by name limit 1000 ;
这个语句看上去逻辑很清晰,但是你了解它的执行流程吗?今天,我就和你聊聊这个语句是怎么执行的,以及有什么参数会影响执行的行为。
全字段排序
前面我们介绍过索引,所以你现在就很清楚了,为避免全表扫描,我们需要在city字段加上索引。
在city字段上创建索引之后,我们用explain命令来看看这个语句的执行情况。

Extra这个字段中的“Using filesort”表示的就是需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
为了说明这个SQL查询语句的执行过程,我们先来看一下city这个索引的示意图。
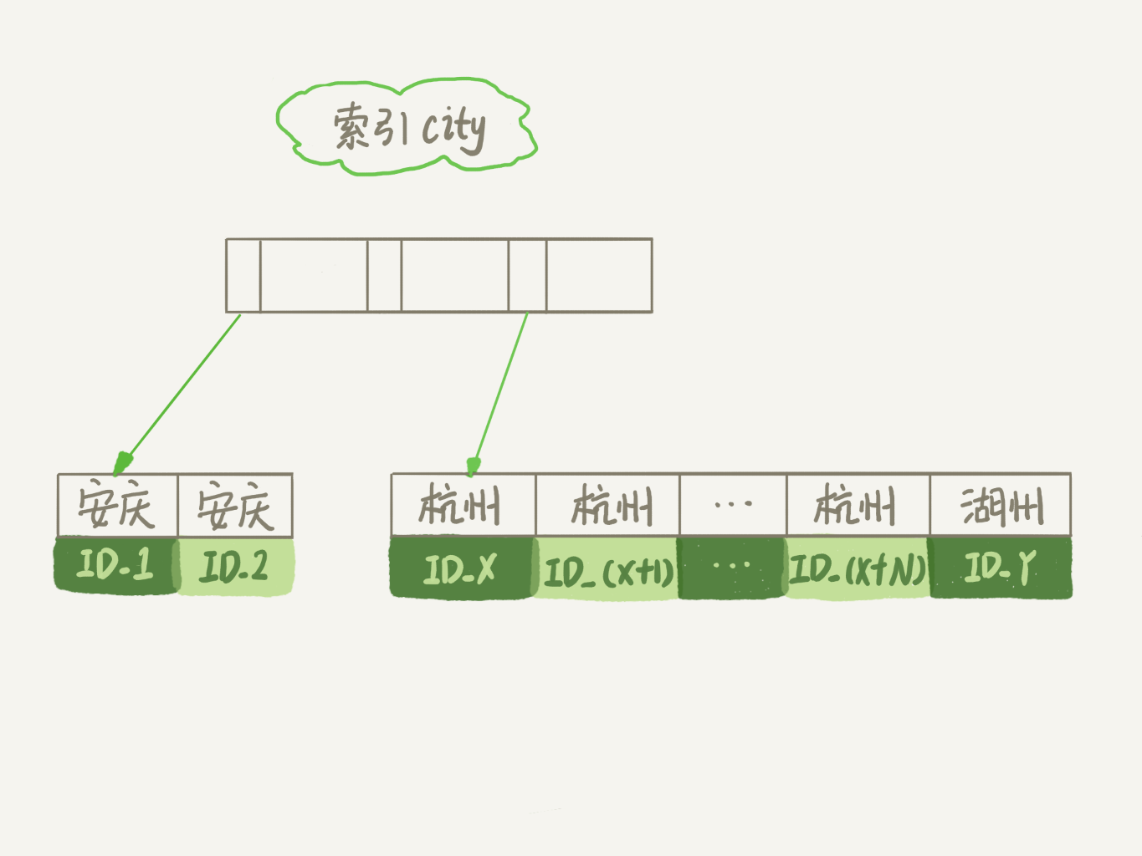
从图中可以看到,满足city='杭州’条件的行,是从ID_X到ID_(X+N)的这些记录。
通常情况下,这个语句执行流程如下所示 :
-
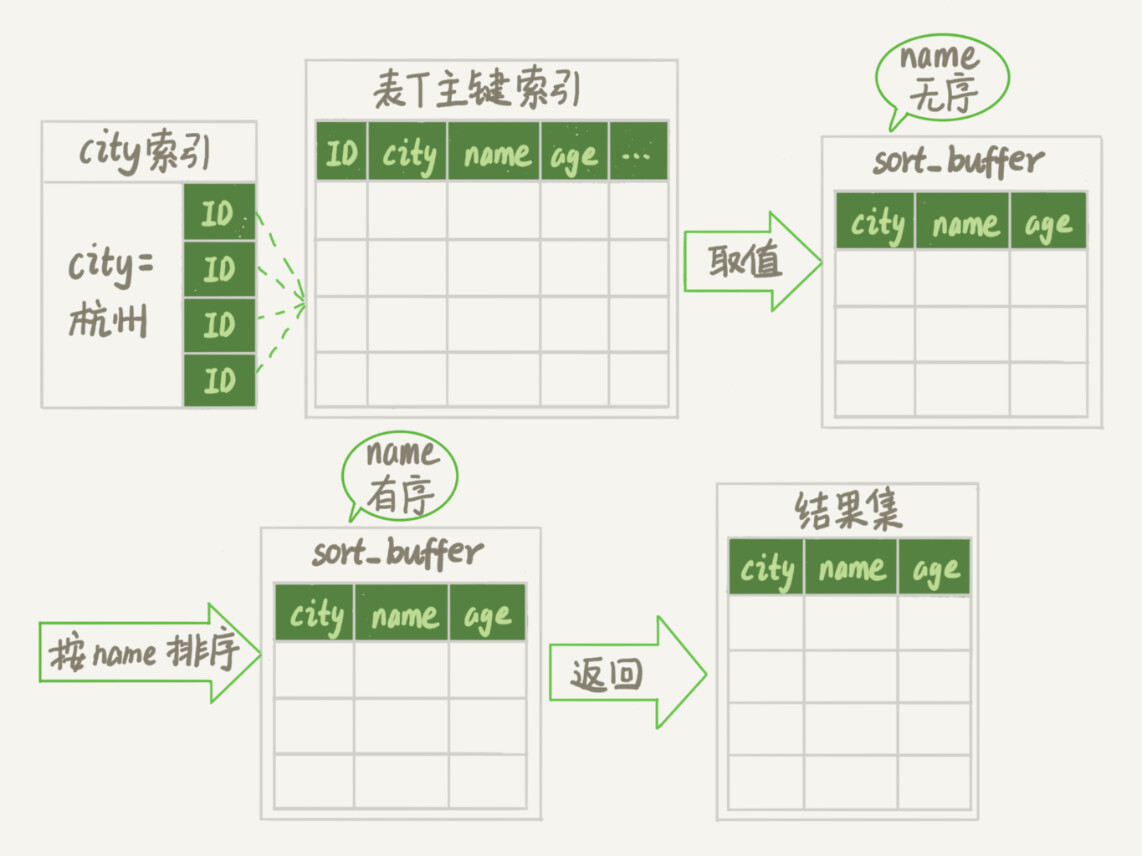
初始化sort_buffer,确定放入name、city、age这三个字段;
-
从索引city找到第一个满足city='杭州’条件的主键id,也就是图中的ID_X;
-
到主键id索引取出整行,取name、city、age三个字段的值,存入sort_buffer中;
-
从索引city取下一个记录的主键id;
-
重复步骤3、4直到city的值不满足查询条件为止,对应的主键id也就是图中的ID_Y;
-
对sort_buffer中的数据按照字段name做快速排序;
-
按照排序结果取前1000行返回给客户端。
我们暂且把这个排序过程,称为全字段排序,执行流程的示意图如下所示,下一篇文章中我们还会用到这个排序。
图中“按name排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size。
sort_buffer_size,就是MySQL为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
你可以用下面介绍的方法,来确定一个排序语句是否使用了临时文件。
/* 打开optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a保存Innodb_rows_read的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* @b保存Innodb_rows_read的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算Innodb_rows_read差值 */
select @b-@a;
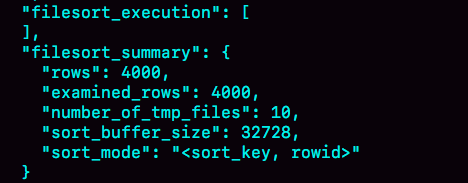
这个方法是通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files中看到是否使用了临时文件。
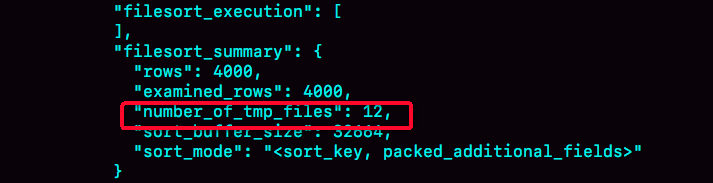
number_of_tmp_files表示的是,排序过程中使用的临时文件数。你一定奇怪,为什么需要12个文件?内存放不下时,就需要使用外部排序,外部排序一般使用归并排序算法。可以这么简单理解,MySQL将需要排序的数据分成12份,每一份单独排序后存在这些临时文件中。然后把这12个有序文件再合并成一个有序的大文件。
如果sort_buffer_size超过了需要排序的数据量的大小,number_of_tmp_files就是0,表示排序可以直接在内存中完成。
否则就需要放在临时文件中排序。sort_buffer_size越小,需要分成的份数越多,number_of_tmp_files的值就越大。
接下来,我再和你解释一下图4中其他两个值的意思。
我们的示例表中有4000条满足city='杭州’的记录,所以你可以看到 examined_rows=4000,表示参与排序的行数是4000行。
sort_mode 里面的packed_additional_fields的意思是,排序过程对字符串做了“紧凑”处理。即使name字段的定义是varchar(16),在排序过程中还是要按照实际长度来分配空间的。
同时,最后一个查询语句select @b-@a 的返回结果是4000,表示整个执行过程只扫描了4000行。
这里需要注意的是,为了避免对结论造成干扰,我把internal_tmp_disk_storage_engine设置成MyISAM。否则,select @b-@a的结果会显示为4001。
这是因为查询OPTIMIZER_TRACE这个表时,需要用到临时表,而internal_tmp_disk_storage_engine的默认值是InnoDB。如果使用的是InnoDB引擎的话,把数据从临时表取出来的时候,会让Innodb_rows_read的值加1。
rowid排序
在上面这个算法过程里面,只对原表的数据读了一遍,剩下的操作都是在sort_buffer和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么sort_buffer里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
所以如果单行很大,这个方法效率不够好。
那么,如果MySQL认为排序的单行长度太大会怎么做呢?
接下来,我来修改一个参数,让MySQL采用另外一种算法。
SET max_length_for_sort_data = 16;
max_length_for_sort_data,是MySQL中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL就认为单行太大,要换一个算法。
city、name、age 这三个字段的定义总长度是36,我把max_length_for_sort_data设置为16,我们再来看看计算过程有什么改变。
新的算法放入sort_buffer的字段,只有要排序的列(即name字段)和主键id。
但这时,排序的结果就因为少了city和age字段的值,不能直接返回了,整个执行流程就变成如下所示的样子:
-
初始化sort_buffer,确定放入两个字段,即name和id;
-
从索引city找到第一个满足city='杭州’条件的主键id,也就是图中的ID_X;
-
到主键id索引取出整行,取name、id这两个字段,存入sort_buffer中;
-
从索引city取下一个记录的主键id;
-
重复步骤3、4直到不满足city='杭州’条件为止,也就是图中的ID_Y;
-
对sort_buffer中的数据按照字段name进行排序;
-
遍历排序结果,取前1000行,并按照id的值回到原表中取出city、name和age三个字段返回给客户端。
这个执行流程的示意图如下,我把它称为rowid排序。
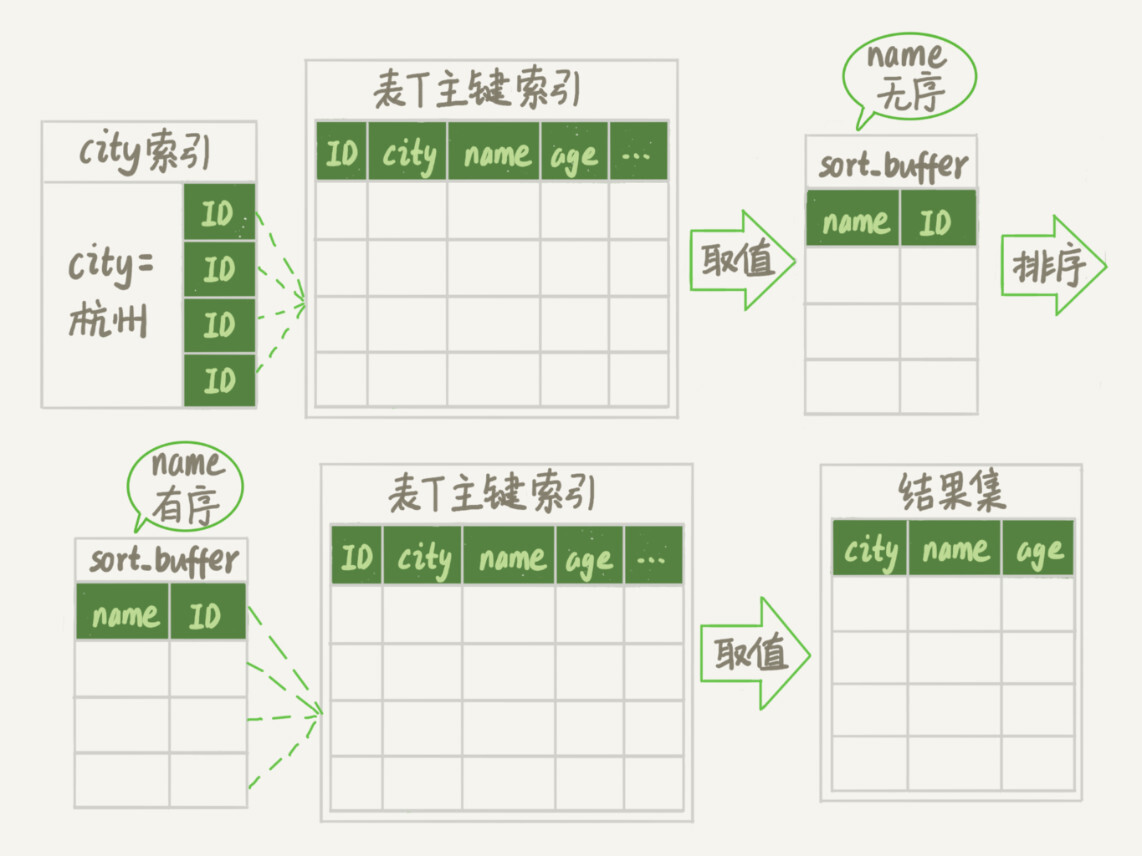
对比图3的全字段排序流程图你会发现,rowid排序多访问了一次表t的主键索引,就是步骤7。
需要说明的是,最后的“结果集”是一个逻辑概念,实际上MySQL服务端从排序后的sort_buffer中依次取出id,然后到原表查到city、name和age这三个字段的结果,不需要在服务端再耗费内存存储结果,是直接返回给客户端的。
根据这个说明过程和图示,你可以想一下,这个时候执行select @b-@a,结果会是多少呢?
现在,我们就来看看结果有什么不同。
首先,图中的examined_rows的值还是4000,表示用于排序的数据是4000行。但是select @b-@a这个语句的值变成5000了。
因为这时候除了排序过程外,在排序完成后,还要根据id去原表取值。由于语句是limit 1000,因此会多读1000行。
从OPTIMIZER_TRACE的结果中,你还能看到另外两个信息也变了。
- sort_mode变成了<sort_key, rowid>,表示参与排序的只有name和id这两个字段。
- number_of_tmp_files变成10了,是因为这时候参与排序的行数虽然仍然是4000行,但是每一行都变小了,因此需要排序的总数据量就变小了,需要的临时文件也相应地变少了。
全字段排序 VS rowid排序
我们来分析一下,从这两个执行流程里,还能得出什么结论。
如果MySQL实在是担心排序内存太小,会影响排序效率,才会采用rowid排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。
如果MySQL认为内存足够大,会优先选择全字段排序,把需要的字段都放到sort_buffer中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
这也就体现了MySQL的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
对于InnoDB表来说,rowid排序会要求回表多造成磁盘读,因此不会被优先选择。
这个结论看上去有点废话的感觉,但是你要记住它,下一篇文章我们就会用到。
看到这里,你就了解了,MySQL做排序是一个成本比较高的操作。那么你会问,是不是所有的order by都需要排序操作呢?如果不排序就能得到正确的结果,那对系统的消耗会小很多,语句的执行时间也会变得更短。
其实,并不是所有的order by语句,都需要排序操作的。从上面分析的执行过程,我们可以看到,MySQL之所以需要生成临时表,并且在临时表上做排序操作,其原因是原来的数据都是无序的。
你可以设想下,如果能够保证从city这个索引上取出来的行,天然就是按照name递增排序的话,是不是就可以不用再排序了呢?
确实是这样的。
所以,我们可以在这个市民表上创建一个city和name的联合索引,对应的SQL语句是:
alter table t add index city_user(city, name);
作为与city索引的对比,我们来看看这个索引的示意图。
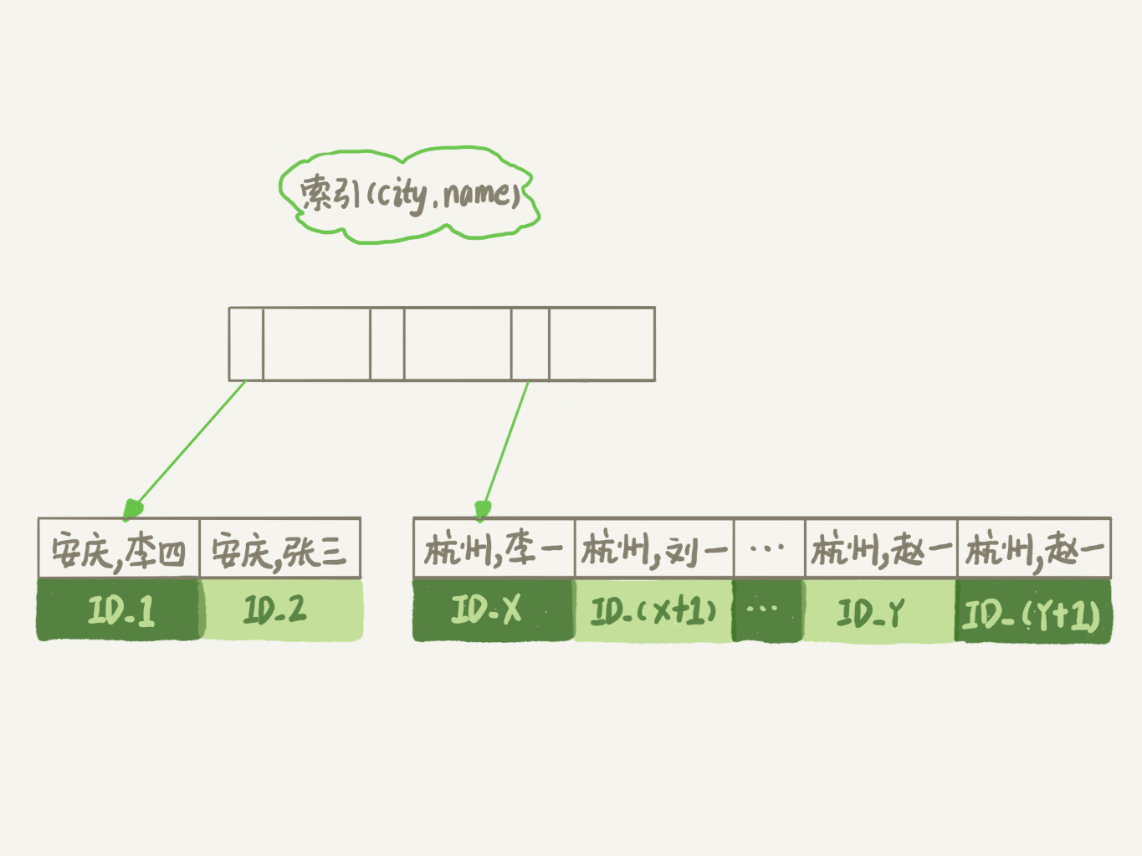
在这个索引里面,我们依然可以用树搜索的方式定位到第一个满足city='杭州’的记录,并且额外确保了,接下来按顺序取“下一条记录”的遍历过程中,只要city的值是杭州,name的值就一定是有序的。
这样整个查询过程的流程就变成了:
-
从索引(city,name)找到第一个满足city='杭州’条件的主键id;
-
到主键id索引取出整行,取name、city、age三个字段的值,作为结果集的一部分直接返回;
-
从索引(city,name)取下一个记录主键id;
-
重复步骤2、3,直到查到第1000条记录,或者是不满足city='杭州’条件时循环结束。
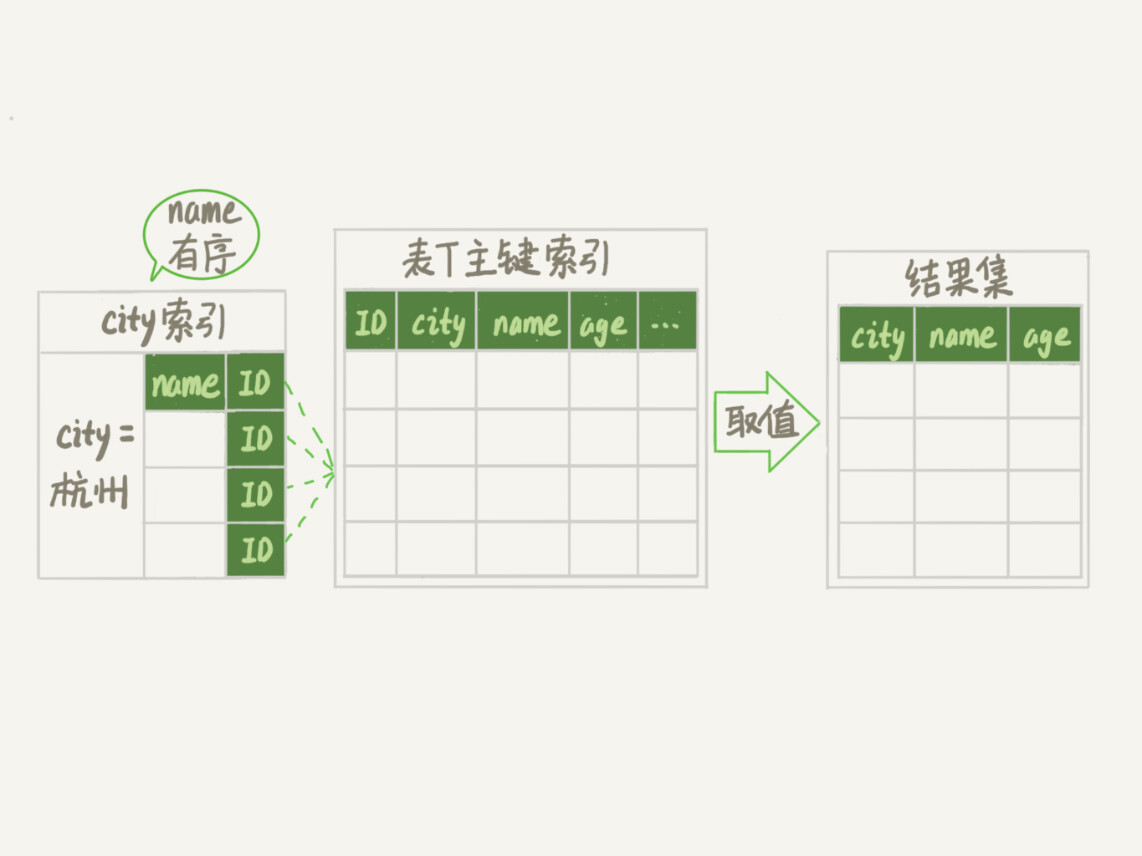
可以看到,这个查询过程不需要临时表,也不需要排序。接下来,我们用explain的结果来印证一下。

从图中可以看到,Extra字段中没有Using filesort了,也就是不需要排序了。而且由于(city,name)这个联合索引本身有序,所以这个查询也不用把4000行全都读一遍,只要找到满足条件的前1000条记录就可以退出了。也就是说,在我们这个例子里,只需要扫描1000次。
既然说到这里了,我们再往前讨论,这个语句的执行流程有没有可能进一步简化呢?不知道你还记不记得,我在第5篇文章《 深入浅出索引(下)》中,和你介绍的覆盖索引。
这里我们可以再稍微复习一下。覆盖索引是指,索引上的信息足够满足查询请求,不需要再回到主键索引上去取数据。
按照覆盖索引的概念,我们可以再优化一下这个查询语句的执行流程。
针对这个查询,我们可以创建一个city、name和age的联合索引,对应的SQL语句就是:
alter table t add index city_user_age(city, name, age);
这时,对于city字段的值相同的行来说,还是按照name字段的值递增排序的,此时的查询语句也就不再需要排序了。这样整个查询语句的执行流程就变成了:
-
从索引(city,name,age)找到第一个满足city='杭州’条件的记录,取出其中的city、name和age这三个字段的值,作为结果集的一部分直接返回;
-
从索引(city,name,age)取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
-
重复执行步骤2,直到查到第1000条记录,或者是不满足city='杭州’条件时循环结束。
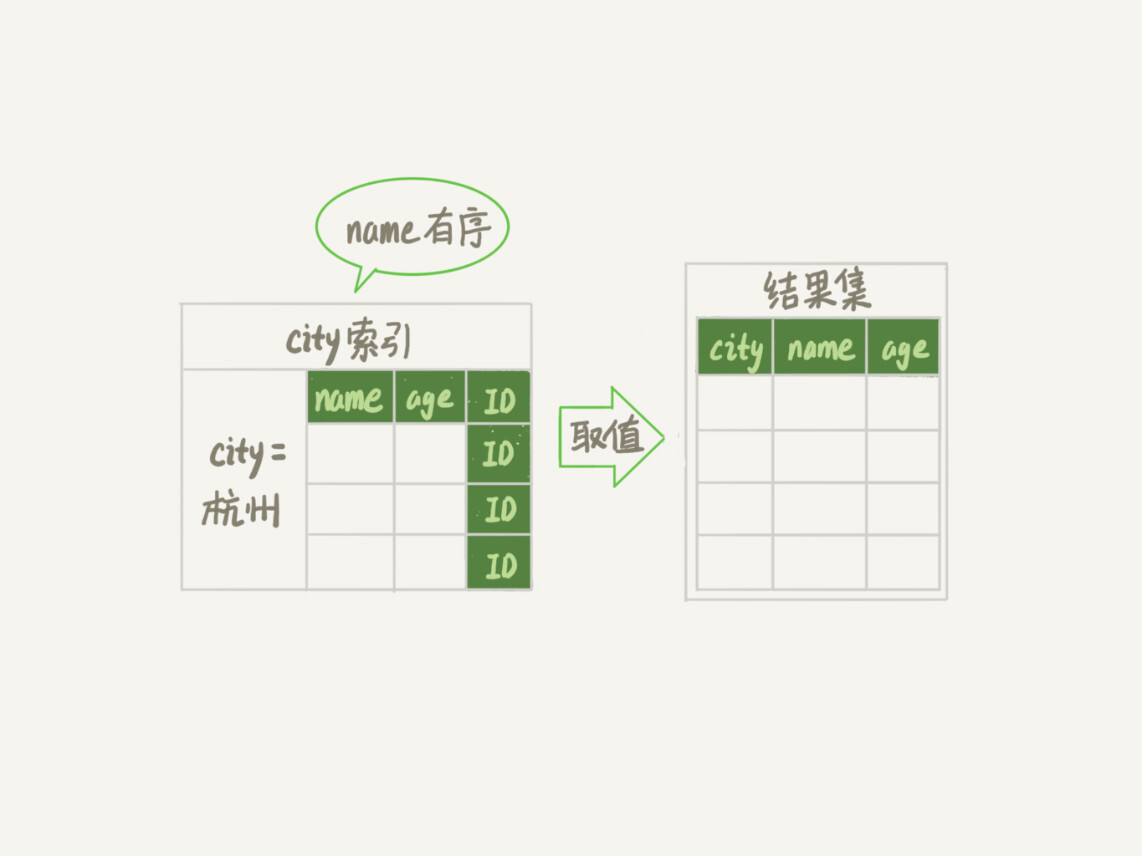
然后,我们再来看看explain的结果。

可以看到,Extra字段里面多了“Using index”,表示的就是使用了覆盖索引,性能上会快很多。
当然,这里并不是说要为了每个查询能用上覆盖索引,就要把语句中涉及的字段都建上联合索引,毕竟索引还是有维护代价的。这是一个需要权衡的决定。
小结
今天这篇文章,我和你介绍了MySQL里面order by语句的几种算法流程。
在开发系统的时候,你总是不可避免地会使用到order by语句。你心里要清楚每个语句的排序逻辑是怎么实现的,还要能够分析出在最坏情况下,每个语句的执行对系统资源的消耗,这样才能做到下笔如有神,不犯低级错误。
最后,我给你留下一个思考题吧。
假设你的表里面已经有了city_name(city, name)这个联合索引,然后你要查杭州和苏州两个城市中所有的市民的姓名,并且按名字排序,显示前100条记录。如果SQL查询语句是这么写的 :
mysql> select * from t where city in ('杭州',"苏州") order by name limit 100;
那么,这个语句执行的时候会有排序过程吗,为什么?
如果业务端代码由你来开发,需要实现一个在数据库端不需要排序的方案,你会怎么实现呢?
进一步地,如果有分页需求,要显示第101页,也就是说语句最后要改成 “limit 10000,100”, 你的实现方法又会是什么呢?
你可以把你的思考和观点写在留言区里,我会在下一篇文章的末尾和你讨论这个问题。感谢你的收听,也欢迎你把这篇文章分享给更多的朋友一起阅读。
上期问题时间
上期的问题是,当MySQL去更新一行,但是要修改的值跟原来的值是相同的,这时候MySQL会真的去执行一次修改吗?还是看到值相同就直接返回呢?
这是第一次我们课后问题的三个选项都有同学选的,所以我要和你需要详细说明一下。
第一个选项是,MySQL读出数据,发现值与原来相同,不更新,直接返回,执行结束。这里我们可以用一个锁实验来确认。
假设,当前表t里的值是(1,2)。
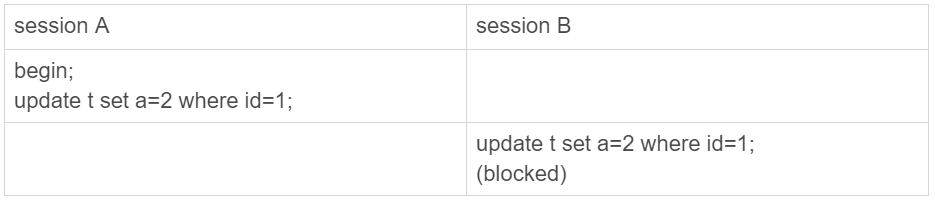
session B的update 语句被blocked了,加锁这个动作是InnoDB才能做的,所以排除选项1。
第二个选项是,MySQL调用了InnoDB引擎提供的接口,但是引擎发现值与原来相同,不更新,直接返回。有没有这种可能呢?这里我用一个可见性实验来确认。
假设当前表里的值是(1,2)。

session A的第二个select 语句是一致性读(快照读),它是不能看见session B的更新的。
现在它返回的是(1,3),表示它看见了某个新的版本,这个版本只能是session A自己的update语句做更新的时候生成。(如果你对这个逻辑有疑惑的话,可以回顾下第8篇文章《事务到底是隔离的还是不隔离的?》中的相关内容)
所以,我们上期思考题的答案应该是选项3,即:InnoDB认真执行了“把这个值修改成(1,2)"这个操作,该加锁的加锁,该更新的更新。
然后你会说,MySQL怎么这么笨,就不会更新前判断一下值是不是相同吗?如果判断一下,不就不用浪费InnoDB操作,多去更新一次了?
其实MySQL是确认了的。只是在这个语句里面,MySQL认为读出来的值,只有一个确定的 (id=1), 而要写的是(a=3),只从这两个信息是看不出来“不需要修改”的。
作为验证,你可以看一下下面这个例子。

补充说明:
上面我们的验证结果都是在binlog_format=statement格式下进行的。
@didiren 补充了一个case, 如果是binlog_format=row 并且binlog_row_image=FULL的时候,由于MySQL需要在binlog里面记录所有的字段,所以在读数据的时候就会把所有数据都读出来了。
根据上面说的规则,“既然读了数据,就会判断”, 因此在这时候,select * from t where id=1,结果就是“返回 (1,2)”。
同理,如果是binlog_row_image=NOBLOB, 会读出除blob 外的所有字段,在我们这个例子里,结果还是“返回 (1,2)”。
对应的代码如图15所示。这是MySQL 5.6版本引入的,在此之前我没有看过。所以,特此说明。

类似的,@mahonebags 同学提到了timestamp字段的问题。结论是:如果表中有timestamp字段而且设置了自动更新的话,那么更新“别的字段”的时候,MySQL会读入所有涉及的字段,这样通过判断,就会发现不需要修改。
这两个点我会在后面讲更新性能的文章中再展开。
看一遍就理解:Order By详解
前言
日常开发中,我们经常会使用到order by,亲爱的小伙伴,你是否知道order by 的工作原理呢?order by的优化思路是怎样的呢?使用order by有哪些注意的问题呢?本文将跟大家一起来学习,攻克order by~
一个使用order by 的简单例子
假设用一张员工表,表结构如下:
CREATE TABLE `staff` (
`id` BIGINT ( 11 ) AUTO_INCREMENT COMMENT '主键id',
`id_card` VARCHAR ( 20 ) NOT NULL COMMENT '身份证号码',
`name` VARCHAR ( 64 ) NOT NULL COMMENT '姓名',
`age` INT ( 4 ) NOT NULL COMMENT '年龄',
`city` VARCHAR ( 64 ) NOT NULL COMMENT '城市',
PRIMARY KEY ( `id`),
INDEX idx_city ( `city` )
) ENGINE = INNODB COMMENT '员工表';
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
表数据如下:
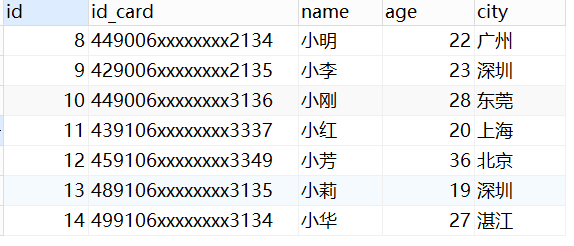
我们现在有这么一个需求:查询前10个,来自深圳员工的姓名、年龄、城市,并且按照年龄小到大排序。对应的 SQL 语句就可以这么写:
select name,age,city from staff where city = '深圳' order by age limit 10;
- 1.
这条语句的逻辑很清楚,但是它的底层执行流程是怎样的呢?
order by 工作原理
explain 执行计划
我们先用Explain关键字查看一下执行计划

- 执行计划的key这个字段,表示使用到索引idx_city
- Extra 这个字段的 Using index condition 表示索引条件
- Extra 这个字段的 Using filesort表示用到排序
我们可以发现,这条SQL使用到了索引,并且也用到排序。那么它是怎么排序的呢?
全字段排序
MySQL 会给每个查询线程分配一块小内存,用于排序的,称为 sort_buffer。什么时候把字段放进去排序呢,其实是通过idx_city索引找到对应的数据,才把数据放进去啦。
我们回顾下索引是怎么找到匹配的数据的,现在先把索引树画出来吧,idx_city索引树如下:
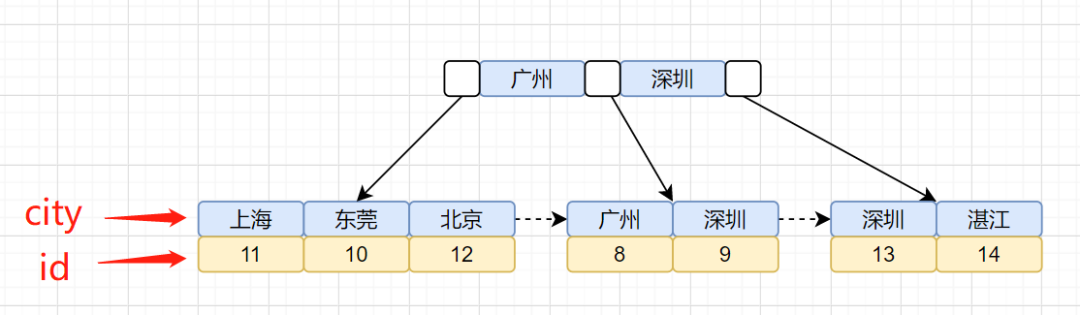
idx_city索引树,叶子节点存储的是主键id。还有一棵id主键聚族索引树,我们再画出聚族索引树图吧:
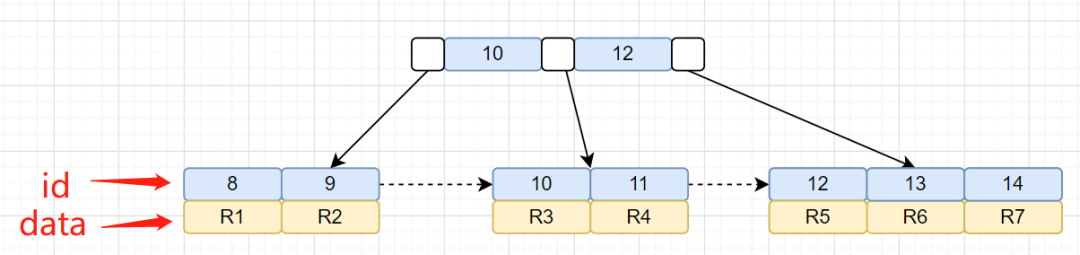
我们的查询语句是怎么找到匹配数据的呢?先通过idx_city索引树,找到对应的主键id,然后再通过拿到的主键id,搜索id主键索引树,找到对应的行数据。
加上order by之后,整体的执行流程就是:
- MySQL 为对应的线程初始化sort_buffer,放入需要查询的name、age、city字段;
- 从索引树idx_city, 找到第一个满足 city='深圳’条件的主键 id,也就是图中的id=9;
- 到主键 id 索引树拿到id=9的这一行数据, 取name、age、city三个字段的值,存到sort_buffer;
- 从索引树idx_city 拿到下一个记录的主键 id,即图中的id=13;
- 重复步骤 3、4 直到city的值不等于深圳为止;
- 前面5步已经查找到了所有city为深圳的数据,在 sort_buffer中,将所有数据根据age进行排序;
- 按照排序结果取前10行返回给客户端。
执行示意图如下:
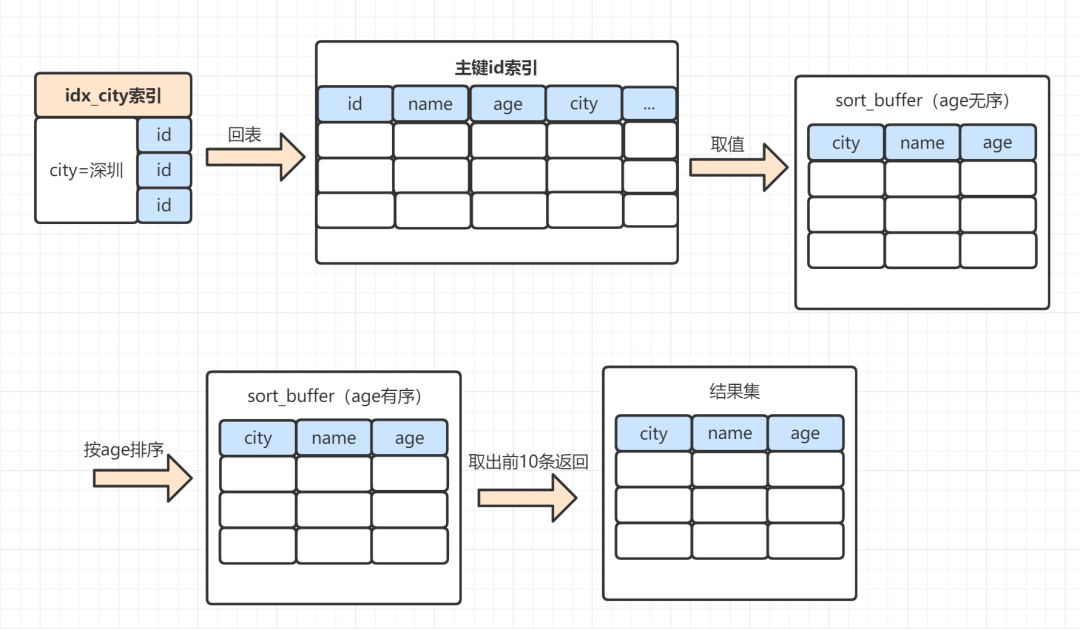
将查询所需的字段全部读取到sort_buffer中,就是全字段排序。这里面,有些小伙伴可能会有个疑问,把查询的所有字段都放到sort_buffer,而sort_buffer是一块内存来的,如果数据量太大,sort_buffer放不下怎么办呢?
磁盘临时文件辅助排序
实际上,sort_buffer的大小是由一个参数控制的:sort_buffer_size。如果要排序的数据小于sort_buffer_size,排序在sort_buffer 内存中完成,如果要排序的数据大于sort_buffer_size,则借助磁盘文件来进行排序
如何确定是否使用了磁盘文件来进行排序呢?可以使用以下这几个命令
## 打开optimizer_trace,开启统计
set optimizer_trace = "enabled=on";
## 执行SQL语句
select name,age,city from staff where city = '深圳' order by age limit 10;
## 查询输出的统计信息
select * from information_schema.optimizer_trace
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
可以从 number_of_tmp_files 中看出,是否使用了临时文件。
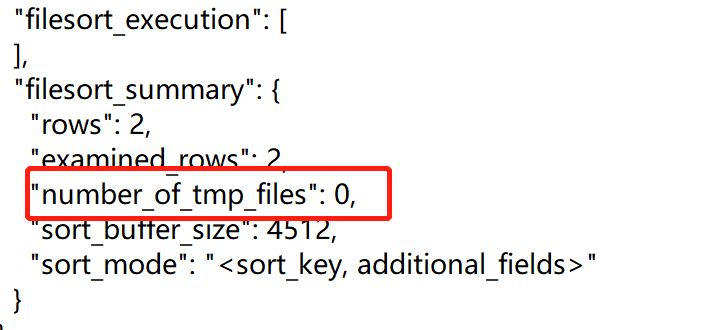
number_of_tmp_files 表示使用来排序的磁盘临时文件数。如果number_of_tmp_files>0,则表示使用了磁盘文件来进行排序。
使用了磁盘临时文件,整个排序过程又是怎样的呢?
- 从主键Id索引树,拿到需要的数据,并放到sort_buffer内存块中。当sort_buffer快要满时,就对sort_buffer中的数据排序,排完后,把数据临时放到磁盘一个小文件中。
- 继续回到主键 id 索引树取数据,继续放到sort_buffer内存中,排序后,也把这些数据写入到磁盘临时小文件中。
- 继续循环,直到取出所有满足条件的数据。最后把磁盘的临时排好序的小文件,合并成一个有序的大文件。
TPS: 借助磁盘临时小文件排序,实际上使用的是归并排序算法。
小伙伴们可能会有个疑问,既然sort_buffer放不下,就需要用到临时磁盘文件,这会影响排序效率。那为什么还要把排序不相关的字段(name,city)放到sort_buffer中呢?只放排序相关的age字段,它不香吗?可以了解下rowid 排序。
rowid 排序
rowid 排序就是,只把查询SQL需要用于排序的字段和主键id,放到sort_buffer中。那怎么确定走的是全字段排序还是rowid 排序排序呢?
实际上有个参数控制的。这个参数就是max_length_for_sort_data,它表示MySQL用于排序行数据的长度的一个参数,如果单行的长度超过这个值,MySQL 就认为单行太大,就换rowid 排序。我们可以通过命令看下这个参数取值。
show variables like 'max_length_for_sort_data';
- 1.
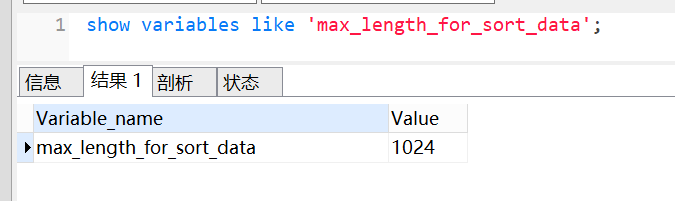
max_length_for_sort_data 默认值是1024。因为本文示例中name,age,city长度=64+4+64 =132 < 1024, 所以走的是全字段排序。我们来改下这个参数,改小一点,
## 修改排序数据最大单行长度为32
set max_length_for_sort_data = 32;
## 执行查询SQL
select name,age,city from staff where city = '深圳' order by age limit 10;
- 1.
- 2.
- 3.
- 4.
使用rowid 排序的话,整个SQL执行流程又是怎样的呢?
- MySQL 为对应的线程初始化sort_buffer,放入需要排序的age字段,以及主键id;
- 从索引树idx_city, 找到第一个满足 city='深圳’条件的主键 id,也就是图中的id=9;
- 到主键 id 索引树拿到id=9的这一行数据, 取age和主键id的值,存到sort_buffer;
- 从索引树idx_city 拿到下一个记录的主键 id,即图中的id=13;
- 重复步骤 3、4 直到city的值不等于深圳为止;
- 前面5步已经查找到了所有city为深圳的数据,在 sort_buffer中,将所有数据根据age进行排序;
- 遍历排序结果,取前10行,并按照 id 的值回到原表中,取出city、name 和 age 三个字段返回给客户端。
执行示意图如下:
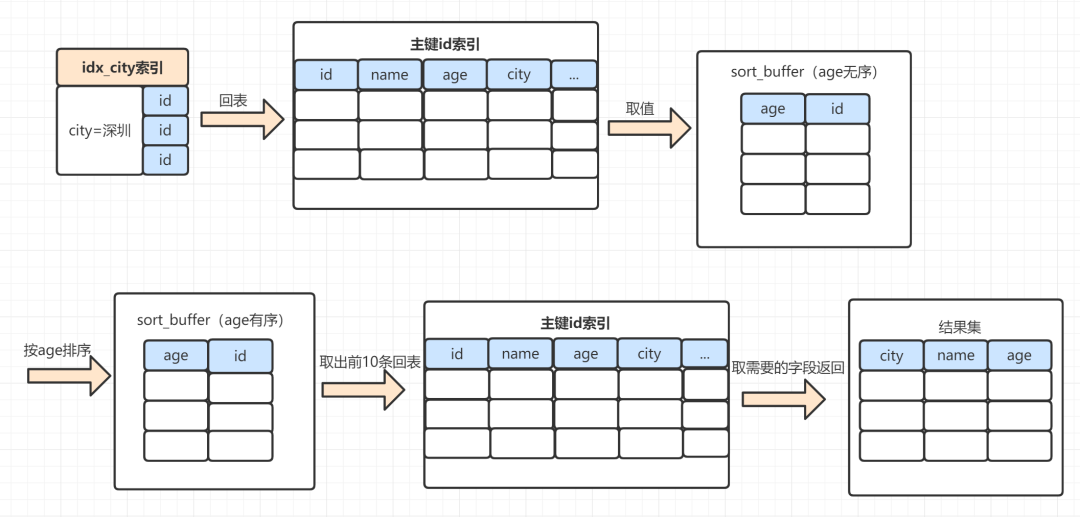
对比一下全字段排序的流程,rowid 排序多了一次回表。
- 什么是回表?拿到主键再回到主键索引查询的过程,就叫做回表”
我们通过optimizer_trace,可以看到是否使用了rowid排序的:
## 打开optimizer_trace,开启统计
set optimizer_trace = "enabled=on";
## 执行SQL语句
select name,age,city from staff where city = '深圳' order by age limit 10;
## 查询输出的统计信息
select * from information_schema.optimizer_trace
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.

全字段排序与rowid排序对比
- 全字段排序:sort_buffer内存不够的话,就需要用到磁盘临时文件,造成磁盘访问。
- rowid排序:sort_buffer可以放更多数据,但是需要再回到原表去取数据,比全字段排序多一次回表。
一般情况下,对于InnoDB存储引擎,会优先使用全字段排序。可以发现 max_length_for_sort_data 参数设置为1024,这个数比较大的。一般情况下,排序字段不会超过这个值,也就是都会走全字段排序。
order by的一些优化思路
我们如何优化order by语句呢?
- 因为数据是无序的,所以就需要排序。如果数据本身是有序的,那就不用排了。而索引数据本身是有序的,我们通过建立联合索引,优化order by 语句。
- 我们还可以通过调整max_length_for_sort_data等参数优化;
联合索引优化
再回顾下示例SQL的查询计划
explain select name,age,city from staff where city = '深圳' order by age limit 10;
- 1.

我们给查询条件city和排序字段age,加个联合索引idx_city_age。再去查看执行计划
alter table staff add index idx_city_age(city,age);
explain select name,age,city from staff where city = '深圳' order by age limit 10;
- 1.
- 2.

可以发现,加上idx_city_age联合索引,就不需要Using filesort排序了。为什么呢?因为索引本身是有序的,我们可以看下idx_city_age联合索引示意图,如下:
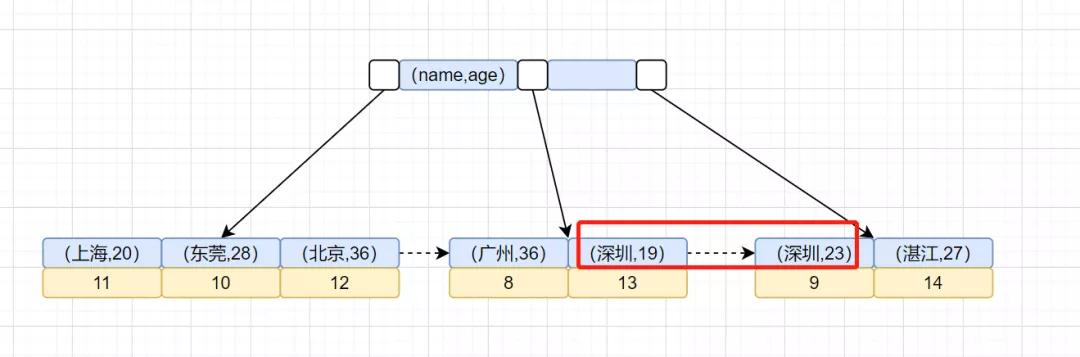
整个SQL执行流程变成酱紫:
- 从索引idx_city_age找到满足city='深圳’ 的主键 id
- 到主键 id索引取出整行,拿到 name、city、age 三个字段的值,作为结果集的一部分直接返回
- 从索引idx_city_age取下一个记录主键id
- 重复步骤 2、3,直到查到第10条记录,或者是不满足city='深圳’ 条件时循环结束。
流程示意图如下:
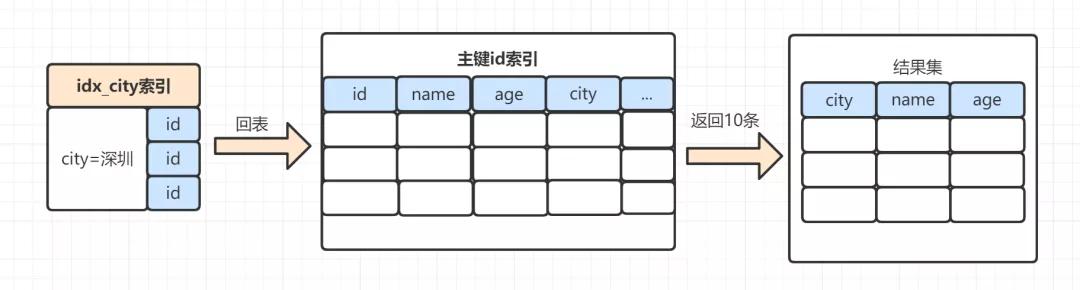
从示意图看来,还是有一次回表操作。针对本次示例,有没有更高效的方案呢?有的,可以使用覆盖索引:
- 覆盖索引:在查询的数据列里面,不需要回表去查,直接从索引列就能取到想要的结果。换句话说,你SQL用到的索引列数据,覆盖了查询结果的列,就算上覆盖索引了。”
我们给city,name,age 组成一个联合索引,即可用到了覆盖索引,这时候SQL执行时,连回表操作都可以省去啦。
调整参数优化
我们还可以通过调整参数,去优化order by的执行。比如可以调整sort_buffer_size的值。因为sort_buffer值太小,数据量大的话,会借助磁盘临时文件排序。如果MySQL服务器配置高的话,可以使用稍微调整大点。
我们还可以调整max_length_for_sort_data的值,这个值太小的话,order by会走rowid排序,会回表,降低查询性能。所以max_length_for_sort_data可以适当大一点。
当然,很多时候,这些MySQL参数值,我们直接采用默认值就可以了。
使用order by 的一些注意点
没有where条件,order by字段需要加索引吗
日常开发过程中,我们可能会遇到没有where条件的order by,那么,这时候order by后面的字段是否需要加索引呢。如有这么一个SQL,create_time是否需要加索引:
select * from A order by create_time;
- 1.
无条件查询的话,即使create_time上有索引,也不会使用到。因为MySQL优化器认为走普通二级索引,再去回表成本比全表扫描排序更高。所以选择走全表扫描,然后根据全字段排序或者rowid排序来进行。
如果查询SQL修改一下:
select * from A order by create_time limit m;
- 1.
无条件查询,如果m值较小,是可以走索引的.因为MySQL优化器认为,根据索引有序性去回表查数据,然后得到m条数据,就可以终止循环,那么成本比全表扫描小,则选择走二级索引。
分页limit过大时,会导致大量排序怎么办?
假设SQL如下:
select * from A order by a limit 100000,10
- 1.
可以记录上一页最后的id,下一页查询时,查询条件带上id,如:where id > 上一页最后id limit 10。
也可以在业务允许的情况下,限制页数。
索引存储顺序与order by不一致,如何优化?
假设有联合索引 idx_age_name, 我们需求修改为这样:查询前10个员工的姓名、年龄,并且按照年龄小到大排序,如果年龄相同,则按姓名降序排。对应的 SQL 语句就可以这么写:
select name,age from staff order by age ,name desc limit 10;
- 1.
我们看下执行计划,发现使用到Using filesort。

这是因为,idx_age_name索引树中,age从小到大排序,如果age相同,再按name从小到大排序。而order by 中,是按age从小到大排序,如果age相同,再按name从大到小排序。也就是说,索引存储顺序与order by不一致。
我们怎么优化呢?如果MySQL是8.0版本,支持Descending Indexes,可以这样修改索引:
CREATE TABLE `staff` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`id_card` varchar(20) NOT NULL COMMENT '身份证号码',
`name` varchar(64) NOT NULL COMMENT '姓名',
`age` int(4) NOT NULL COMMENT '年龄',
`city` varchar(64) NOT NULL COMMENT '城市',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name` desc) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
使用了in条件多个属性时,SQL执行是否有排序过程
如果我们有联合索引idx_city_name,执行这个SQL的话,是不会走排序过程的,如下:
select * from staff where city in ('深圳') order by age limit 10;
- 1.

但是,如果使用in条件,并且有多个条件时,就会有排序过程。
explain select * from staff where city in ('深圳','上海') order by age limit 10;
- 1.

这是因为:in有两个条件,在满足深圳时,age是排好序的,但是把满足上海的age也加进来,就不能保证满足所有的age都是排好序的。因此需要Using filesort。
sql order by与索引之间的关系(where条件出现字段才有效)
ORDER BY 通常会有两种实现方法,一个是利用有序索引自动实现,也就是说利用有序索引的有序性就不再另做排序操作了。另一个是把结果选好之后再排序。
用有序索引这种,当然是最快的,不过有一些限制条件,来看下面的测试。
测试数据:student表有两个字段id ,sid ,id是主键。一共有20W条记录,id从1到200000,sid也是从1到200000的数据。
第一种情况 :
order by的字段不在where条件也不在select中
select sid from zhuyuehua.student where sid < 50000 order by id;
第二种情况 :
order by的字段不在where条件但在select中。
select id,sid from zhuyuehua.student where sid < 50000 order by id;
第三种情况 :
order by的字段在where条件但不在select中。
select sid from zhuyuehua.student where sid < 50000 and id < 50000 order by id;
第四种情况 :
order by的字段在where条件但不在select中。倒序排列
select sid from zhuyuehua.student where sid < 50000 and id < 50000 order by id desc;
测试结果:
order by的字段不在where条件不在select中 有排序操作
order by的字段不在where条件但在select中 有排序操作
order by的字段在where条件但不在select中 无排序操作
order by的字段在where条件但不在select中(倒序) 无排序操作
结论:
当order by 字段出现在where条件中时,才会利用索引而无需排序操作。其他情况,order by不会出现排序操作。
分析:
为什么只有order by 字段出现在where条件中时,才会利用该字段的索引而避免排序。这要说到数据库如何取到我们需要的数据了。
一条SQL实际上可以分为三步。
1.得到数据
2.处理数据
3.返回处理后的数据
比如上面的这条语句select sid from zhuyuehua.student where sid < 50000 and id < 50000 order by id desc
第一步:根据where条件和统计信息生成执行计划,得到数据。
第二步:将得到的数据排序。
当执行处理数据(order by)时,数据库会先查看第一步的执行计划,看order by 的字段是否在执行计划中利用了索引。如果是,则可以利用索引顺序而直接取得已经排好序的数据。如果不是,则排序操作。
第三步:返回排序后的数据。
另外:
上面的5万的数据sort只用了25ms,也许大家觉得sort不怎么占用资源。可是,由于上面的表的数据是有序的,所以排序花费的时间较少。如果 是个比较无序的表,sort时间就会增加很多了。另外排序操作一般都是在内存里进行的,对于数据库来说是一种CPU的消耗,由于现在CPU的性能增强,对 于普通的几十条或上百条记录排序对系统的影响也不会很大。但是当你的记录集增加到上百万条以上时,你需要注意是否一定要这么做了,大记录集排序不仅增加了 CPU开销,而且可能会由于内存不足发生硬盘排序的现象,当发生硬盘排序时性能会急剧下降。
注:ORACLE或者DB2都有一个空间来供SORT操作使用(上面所说的内存排序),如ORACLE中是用户全局区(UGA),里面有SORT_AREA_SIZE等参数的设置。如果当排序的数据量大时,就会出现排序溢出(硬盘排序),这时的性能就会降低很多了。
总结:
当order by 中的字段出现在where条件中时,才会利用索引而不排序,更准确的说,order by 中的字段在执行计划中利用了索引时,不用排序操作。
这个结论不仅对order by有效,对其他需要排序的操作也有效。比如group by 、union 、distinct等。
order by 字段到底要不要加索引?[大坑]
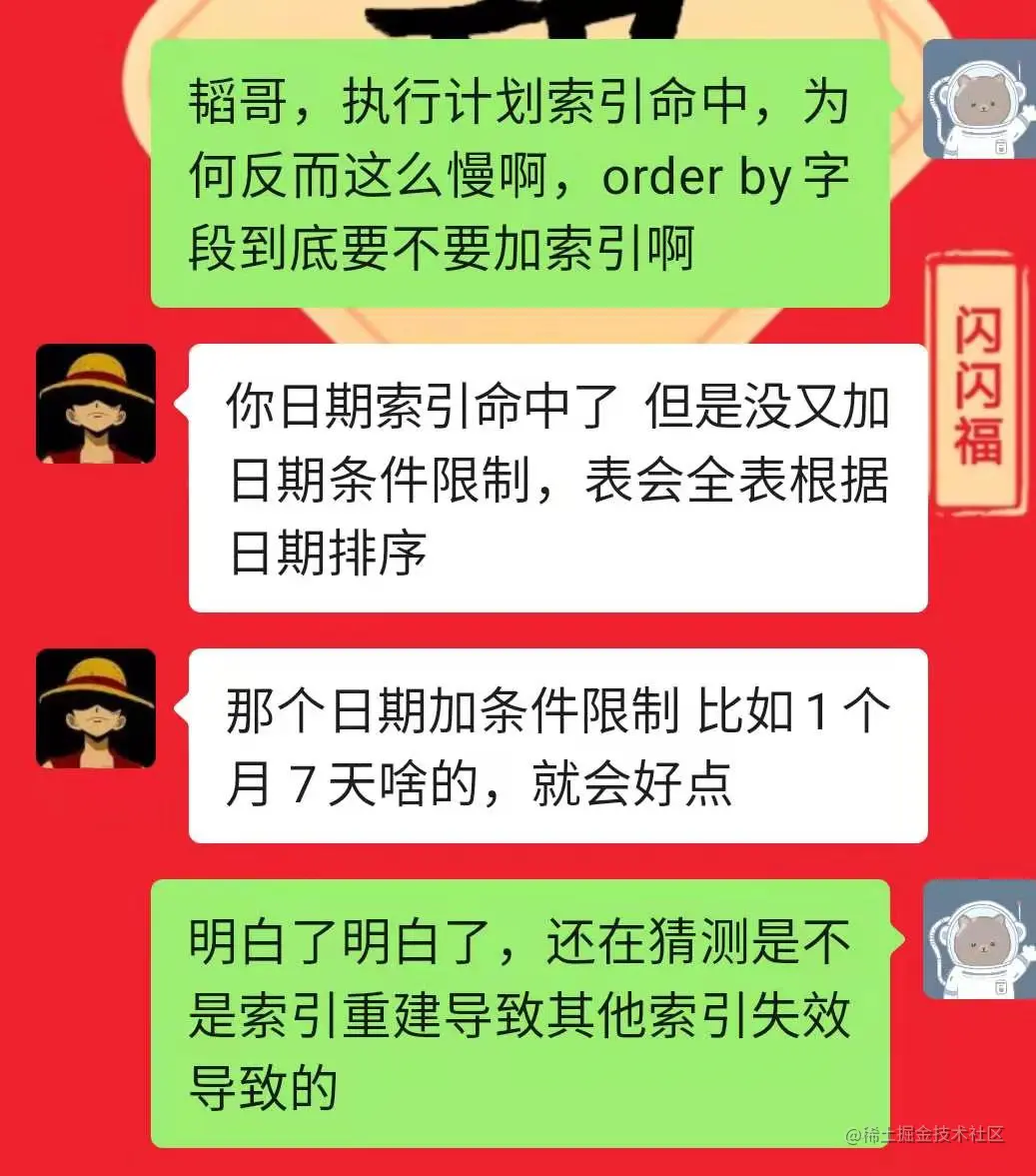
SQL是上午执行的,生产故障是立马就有的!
10:08加的索引,10.20报的错,生产服务卡死

运维定位SQL,就妥妥定位在我周一申请的sql优化部分,明明就加了个索引,为何导致生产服务直接挂掉?
desc select
a.No,
-
-
-
-
-
(find_in_set(xx, a.Id))
from
a
left join r on
a.No = r.No
where
( a.xxx = 1
or a.xxx = 1 )
and a.xx = 3
and r.xxx is null
and DATEDIFF(DATE_add(a.xxx,
interval 0 day ),
current_date()) >= 0
order by
a.submitTime desc
limit 0 ,10
复制
生产单表a表450万数据,b表实际450万数据
生产分析

可以看出,我新建的索引已经命中,并且物理扫描行数大大减少,那么为何在生产上查不出数据???
为了紧急修复问题,杀死所有服务后,删除我建的索引再次执行,4S后返回
那么实际执行的扫描行数是9行为什么还如此的慢?
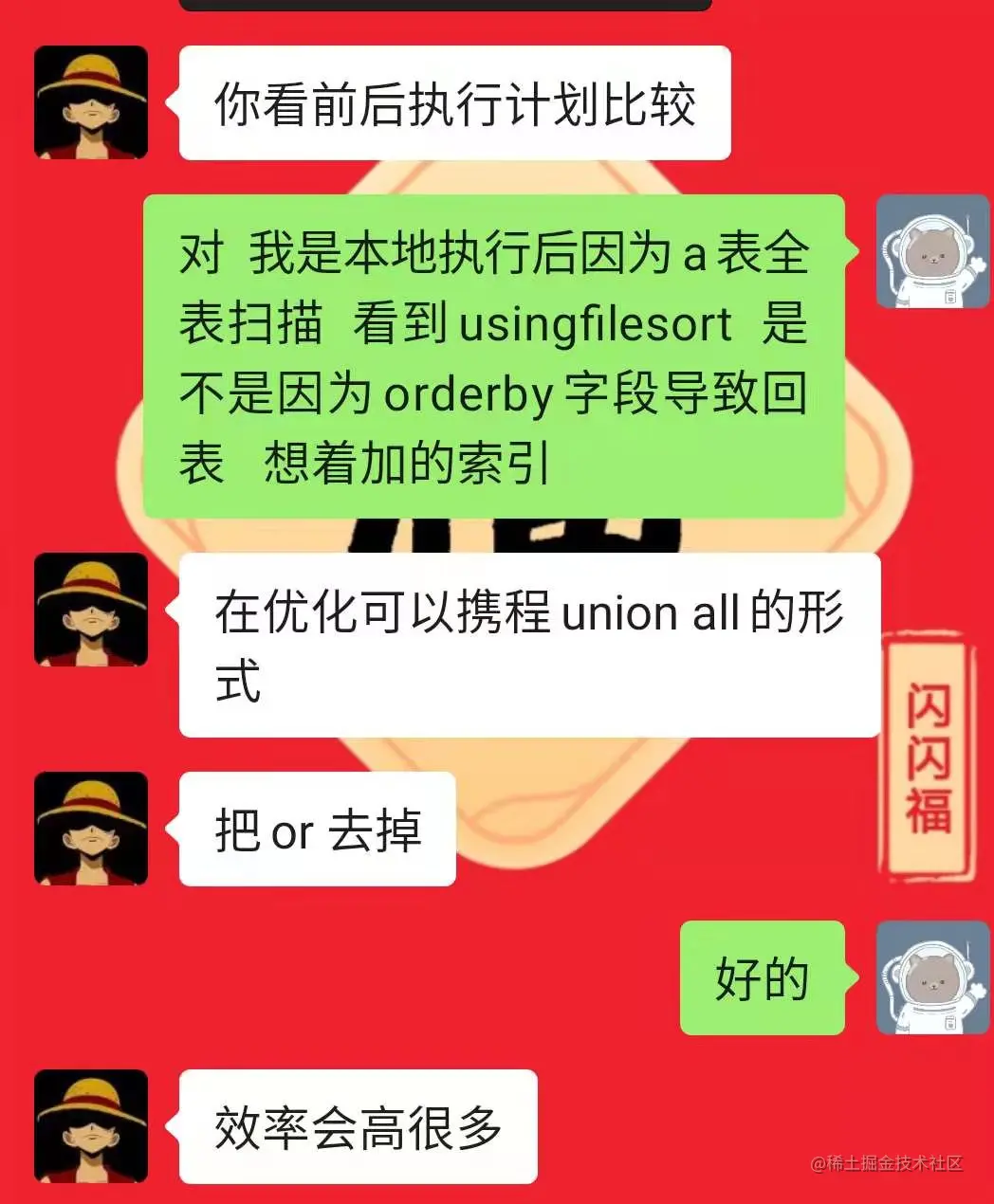
猜测:由于数据量较大,在执行索引操作时,进程正在进行加索引操作,此时刷新造成查询时不走任何索引,导致所有索引失效,或者前期进程有阻塞,造成加索引操作未完成
那么条件是根据用户来查询的,极端情况下理应查出最多数据在几百条,且limit后并不会太多啊?
https://blog.csdn.net/sky_jiangcheng/article/details/79513420
复制

强制走索引生效吗?本地环境试了是不生效的,而且生产没那么长时间给你去试
本地环境,未加order by索引全表扫描,不走索引

加了order by 索引,索引命中,物理扫描行数急剧减少

https://blog.csdn.net/asdasdasd123123123/article/details/106783196/
复制
order by 字段到底要不要加索引?
优化器直接从索引中找到了最小的10条记录,然后回表取得结果集返回。相比上一个执行计划,省去了全表扫描,省去了排序,所以执行时间和系统资源消耗都大大减少。 在这里作一个简单的分析,首先索引和数据不同,是按照有序的排列存储的,当结果集要求按照顺序取得一部分数据时,索引的功效会体现的非常明显,本次查询就是要取得object_id最小的10条记录。其次,建立索引系统只需要消耗一次资源完成排序过程,而如果没有索引,执行不同的语句可能每次都要经历排序的过程,会消耗更多的系统资源。从这个实验看,在order by字段建索引是非常划算的,而且order by字段并不一定非要加入到where条件中也可以生效。
如果这一列存在NULL值,NULL值是没有大小这一说法的,而且不会被保存在索引中。如果优化器无法确定该列没有NULL值,为了保证结果集的准确性,宁愿选择更慢的全表扫描,也不会选择走可能存在NULL的索引,即使用户指定了hint也不会选择
百思不得其解,还是问问运维老大
对于order by字段加入索引本身这个问题,如果最终的结果集是以order by字段为条件筛选的,将order by字段加入索引,并放在索引中正确的位置,会有明显的性能提升。
优化有风险,生产需谨慎!
南来地,北往的,上班的,下岗的,走过路过不要错过!
======================个性签名=====================
之前认为Apple 的iOS 设计的要比 Android 稳定,我错了吗?
下载的许多客户端程序/游戏程序,经常会Crash,是程序写的不好(内存泄漏?刚启动也会吗?)还是iOS本身的不稳定!!!
如果在Android手机中可以简单联接到ddms,就可以查看系统log,很容易看到程序为什么出错,在iPhone中如何得知呢?试试Organizer吧,分析一下Device logs,也许有用.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
2011-09-20 iPad 开发陷井1