
计算机视觉从入门到放肆
计算机视觉从入门到放肆
一、基础知识
1.1 计算机视觉到底是什么?
计算机视觉是一门研究如何让机器“看”的科学
更进一步的说,就是使用摄像机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。
作为一门科学学科,计算机视觉研究相关的理论和技术,视图建立能够从图像或者多维数据中获取’信息’的人工智能系统。
1.2 图像
当程序在读取一张图片时,需要考虑以下数据:
-
高度、宽度
假如一张照片的分辨率为:1920*1080(单位为dpi,全称为 dot per inch),1920 就是照片的宽度,1080 就是图片的高度。
-
深度
存储每个像素所用的位数,比如正常RGB的深度就是 2^8 * 3 = 256 * 3 = 768 , 那么此类图片中的深度为768,每个像素点都能够代表768中颜色。
-
通道数
RGB图片就是有三通道,RGBA类图片就是有四通道
-
颜色格式
是将某种颜色表现为数字形式的模型,或者说是一种记录图像颜色的方式。比较常见的有:RGB模式、RGBA模式、CMYK模式、位图模式、灰度模式、索引颜色模式、双色调模式和多通道模式。
-
more
图像中的知识点太多,做基本图像处理,了解以上知识个人感觉可以了。等到以后如果做深入研究,或许有机会做更多的学习
1.3 视频
原始视频 = 图片序列,视频中的每张有序图片被称为“帧(frame)”。压缩后的视频,会采取各种算法减少数据的容量,其中IPB就是最常见的。
-
码率
数据传输时单位时间传送的数据位数,通俗一点的理解就是取样率,单位时间取样率越大,精度就越高,即分辨率越高
-
帧率
每秒传输的帧数,fps(有没有一种似曾相识的感觉~~~),全称为 frames per second
-
分辨率
每帧图片的分辨率
-
清晰度
平常看片中,有不同清晰度,实际上就对应着不同的分辨率
-
IPB
在网络视频流中,并不是把每一帧图片全部发送到客户端来展示,而是传输每一帧的差别数据(IPB),客户端然后对其进行解析,最终补充每一帧完整图片
1.4 摄像机
在实际应用当中,基本上都是通过不同种类的摄像机来获取数据,然后发送给服务端(AI Server)进行处理,分类有:
- 监控摄像机(网络摄像机和模拟摄像机)
- 行业摄像机(超快动态摄像机、红外摄像机、热成像摄像机等)
- 智能摄像机
- 工业摄像机
1.5 CPU和GPU
我想大家肯定是知道,目前很多人工智能计算都迁移到GPU上进行,tensorflow甚至还有cpu和gpu版本,所以其两者的差别和使用方法,这是绕不开的问题。
废话少说,先来上图:
-
架构上的对比
- 绿色:计算单元
- 橙红色:存储单元
- 橙黄色:控制单元
-
整体对比
- Cache、Local Memory : CPU > GPU
- Threads(线程数):GPU > CPU
- Registers(寄存器):GPU > CPU
- SIMD Unit(单指令多数据流):GPU > CPU
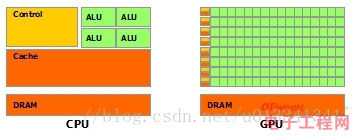
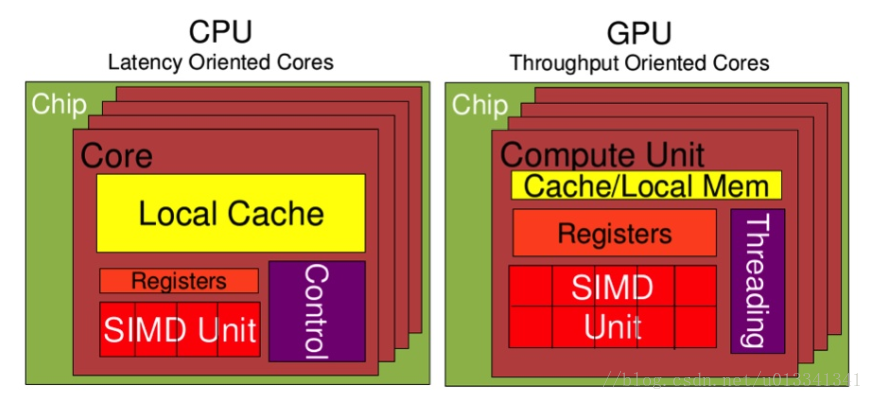
CPU在设计上,低延迟,可是低吞吐量,CPU的ALU(算数运算单元)虽然少,可是很强大,可以在很少的时钟周期内完成算数计算,或许数量少,就可以任性的减少时钟周期,所以其频率非常高,能够达到1.532 ~ 3 (千兆,10的9次方)。
大缓存容量、复杂的逻辑控制单元也可以减低延迟。
GPU在设计上,高延迟,可是高吞吐量。GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
-
Cuda (Compute Unified Device Architecture)
是显卡厂商NVIDIA推出的运算平台,采用并行计算架构,是GPU能够解决复杂的计算问题。包含了CUDA指令集架构以及GPU内部的并行计算引擎。
安装教程自行搜索脑补就行。
1.6 编程语言 + 数学基础
-
python
推荐作为入门语言,简单容易上手,需要了解一些库:numpy、pandas、matplotlib等。
-
C++
作为深入了解并尝试进行优化,C++必不可少,也是编写并修改的最佳语言。当然,如果你了解C、Matlab等语言那也是甚好的。
-
线性代数
可以把重点放在矩阵运算上。
-
概率统计
了解基本概率统计知识、高斯分布、中值、标准差和方差等概念。
-
MachineLearning
能够用公式表示代价函数、使用低度下降法来优化模型。当然机器学习内容实在是很多,建议能够完整走一遍,也可以看斯坦福的CS229课程
1.7 计算机视觉的应用
计算机视觉之于未来人工智能,就好比眼睛之于人的重要性一样。是未来很多领域自动化获取数据的主要渠道之一,也是处理数据的重要工具之一。目前可以预想到的应用主要有如下:
- 无人驾驶
- 无人安防
- 人脸识别
- 文字识别
- 车辆车牌识别
- 以图搜图
- VR/AR
- 3D重构
- 医学图像分析
- 无人机
- more ……
二、推荐参考书和公开课
2.1 参考书籍
-
《Computer Vision : Models,Learning and Inference》
理论入门书籍
-
计算机视觉必备工具
-
《Computer Vision : Algorithms and Applications》
计算机视觉算法和应用,属于进阶篇,这样的书一般都有中文译本。本人也是几经周折,找到了一些资料,供大家下载学习。
2.2 公开课
-
这个课程作为入门非常合适,里面也会分享一些干货
-
Stanford CS231N
这两门课我觉得经典的课程,如果认真学完的话,基本上是已经入门了,找一般的工作工作应该是没有问题。
2.3 网站
-
这个网站是国外大佬从1994年开始专注于计算机视觉研究,上面收录了很多与此相关文献,大家可以看一些里程碑文献,让自己能够更好地理解视觉发展历程。
-
没事上斯坦福大学计算机视觉研究团队官网看看,大佬们有没有发表一些研究成果文章,学习一番之后,将其翻译成blog也不失为一个好的学习方法(装逼方法)。
这两个网站已经足够了,不要太多,学好才是最关键的。
三、你还是需要学习一些深度学习知识
关于深度学习,评价最高的莫过于:《Deep Learning》Written by lan Goodfellow and YoshuaBengio

购买链接,这本AI圣经我就不多废话了,攒钱买回去好好修炼吧!
四、开源框架必不可少
关于开源框架,仁者见仁智者见智,我也免得引起战争,所以就罗列给一下个人不成熟的小建议。
-
Caffe
深度学习卷积神经网络开源框架。
-
Tensorflow
开源机器学习深度学习框架。
-
(Torch and Maxnet)
其他深度学习开源框架
-
ffmpeg
强大的视频处理工具
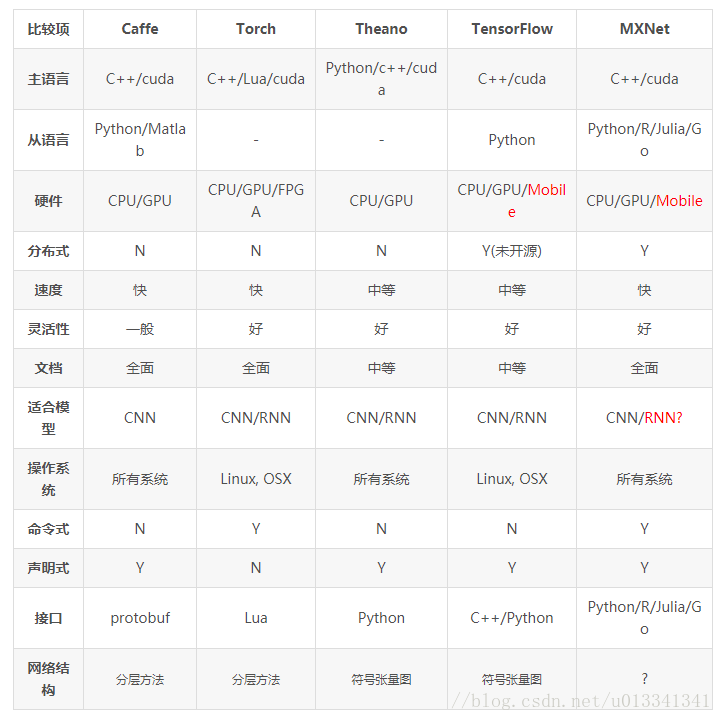
流行框架的对比图:
五、深入,则必须阅读相关文献
当我们需要学习各种经典模型的时候,到哪里去找资料呢?一般大家都会直接wikipedia,可是我只想说,上面的也只是英文版汉译过来的,最好还是找一手资料,不然你吸收的知识,就不知道是被多少人消化过多少遍后得来的。当然也是有好的,不过那些大牛都是直接看原版才能得出更加深刻的结论,所以看原版文献是一件很重要的学习途径,不然就永远装不了*(学习不到最纯正的knowledge)。
5.1 里程碑式的文献
先熟悉所在方向的发展历程,历程中的里程碑式的文献必须要精读。
例如,深度学习做目标检测,RCNN、Fast RCNN、Fater RCNN、SPPNET、SSD和YOLO等模型;又例如,深度学习做目标跟踪,DLT、SO-DLT等等;再例如,对抗网络GAN、CGAN、DCGAN、LAPGAN等等。
- 1
- 2
- 3
- 4
5.2 文献网站
[arxiv](https://arxiv.org/list/cs.CV/recent) :每天去更新一下别人最新的工作
- 1
- 2
5.3 计算视觉的顶会
- ICCV:国际计算机视觉大会
- CVPR:国际计算机视觉与模式识别大会
- ECCV:欧洲计算机视觉大会
5.4 计算机视觉的顶刊
- PAMI:IEEE 模式分析与机器智能杂志
- IJCV:国际计算机视觉杂志
六:总结
无论别人给出多好的资料,最终还是要靠自己踏实下来,对各种知识点细嚼慢咽。AI 不易,且行且珍惜

 浙公网安备 33010602011771号
浙公网安备 33010602011771号