
4.结构化机器学习项目
如何判断这些idea是否是有效的?我们可以尝试和改变的东西太多了。我们需要知道要调整什么,达到什么样的效果,这个过程被称之为正交化

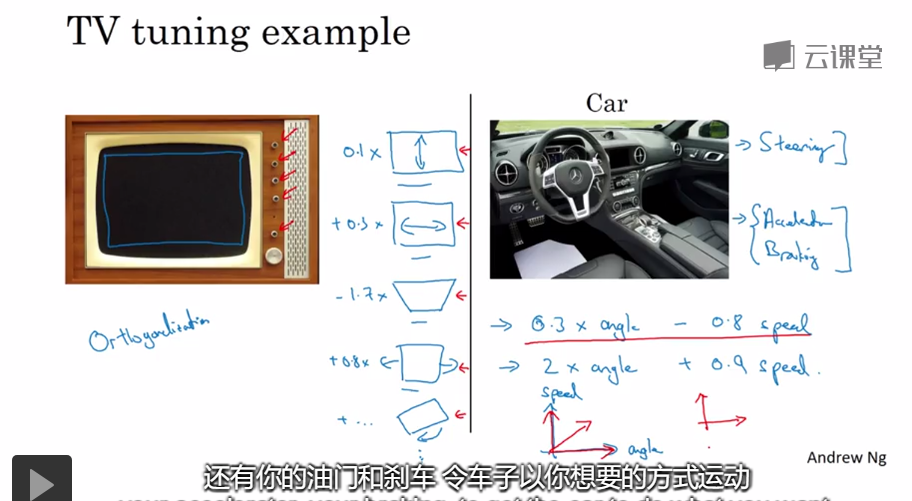
正交化就是一件事影响一件事

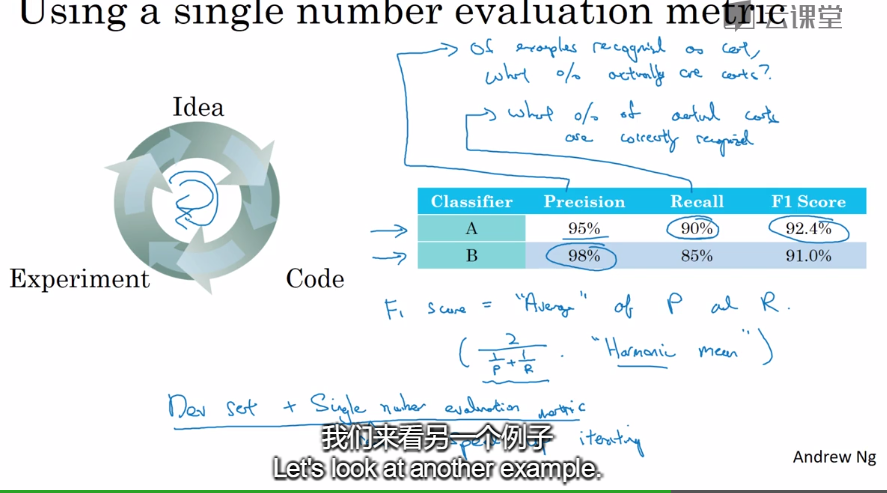
单一数字评估指标
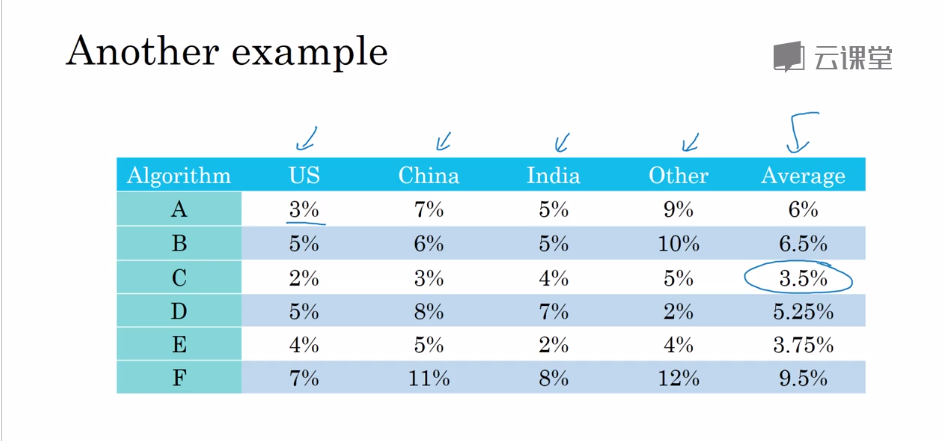
交叉验证集与测试集应该服从同一分布






训练误差比人的误差大,那么说明模型在训练集上拟合的并不好,我们应该减少偏差,选择更大的神经网络,或者跑的更久一点梯度下降。
开发误差比训练误差大,那么说明模型在数据上过拟合了,此时应该减少方差,使用正则化或者使用更多的数据。
人类的误差比较接近贝叶斯误差。
训练误差和贝叶斯误差之间的差值称为可避免偏差,所以我们可以一直提高训练集合的表现,直至接近贝叶斯误差,但不能超过他

机器学习在结构化的工程中表现超过人类。
但在自然感知领域,比如计算机视觉,自然语言处理,语音识别等领域难以超越人类

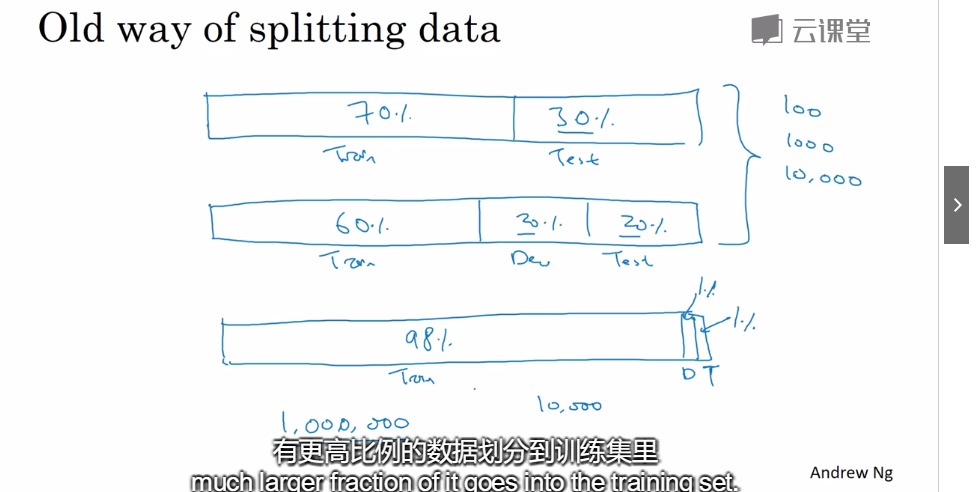
第一种划分,虽然训练集,开发集,测试集是同一分布的,但是开发集中只有非常少量的手机图片。然而开发集使我们用来瞄准用的,所以这种情况就瞄准偏了。
第二种划分,训练集中有一小部分的手机图片,开发集和测试集都是手机图片,虽然瞄准了,但缺点是训练集不太好,但比第一种好。

训练集与训练开发集是同一分布的。
上左:高方差。上右:数据不匹配(分布不同)。下左:高偏差 。下右:高偏差,数据不匹配。

从上到下依次是:偏差,方差,数据不匹配,模型对开发集过拟合程度(注意开发集和测试集是同一分布的)

数据不匹配的问题可以用人工合成的手段使得数据尽可能的匹配。但是噪声要尽可能的不重复,否则就会对部分噪声过拟合。
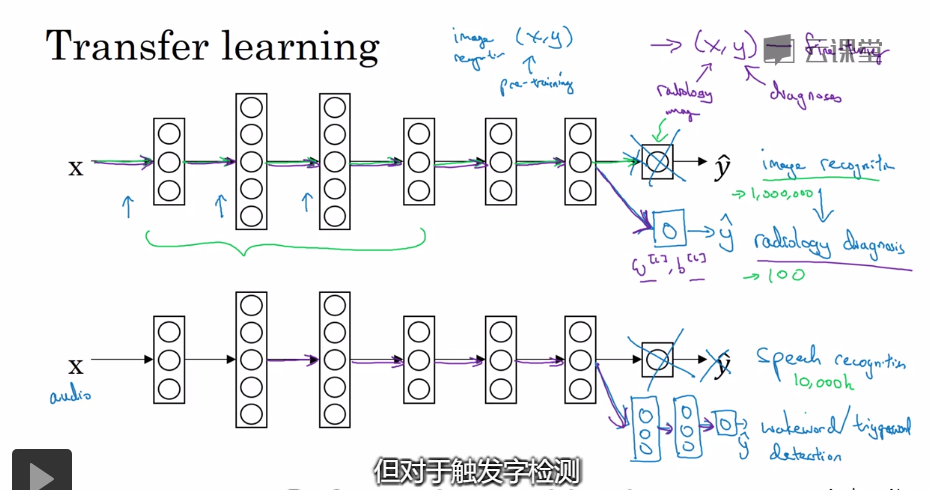
在迁移学习中,如果数据量较小,那么我们可以只训练最后的几层,如果数据量很多,那么我们可以将所有的层训练。
预训练就是未迁移之前的训练,微调就是迁移后的训练。迁移学习之所以有效,是因为迁移学习的预训练阶段已经学习到
了一些底层的特征,比如边缘检测,曲线检测等。学习到的这些点,曲线知识可以应用到后续的检测中。迁移学习往往用在,预训练有大量的数据,
微调只有少量的数据。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号