
本人毕业设计系统附完整文档和项目代码
大四期间9月到11月写的毕业系统,仿照百度文库设计的,融合了session共享,nginx负载均衡,lucene全文检索,敏感词过滤算法,office文件转pdf并提供免下载在线预览功能,登录邮件通知等功能。页面都是趴的51CTO网站套用的。
下面是截取的部分内容,完整文档和完整代码见 https://github.com/intsmaze/FileManage
2系统开发工具与技术
本文件共享管理系统的开发工具使用Eclipse,数据库采用的是MySQL,服务器采用Tomcat6.0,Nginx。在开发中采用Java语言进行开发,项目整体使用Struts2,hibernate,spring三大框架作为开发的基本环境,使用Lucene全文检索框架进行文件的搜索,MyCat中间件处理分布式数据库和分布式事务问题等问题,OpenOfiice技术对office文件转换为swf文件时数据内容的提取,页面采用JSP+HTML+CSS+DIV等技术,Ajax进行请求的异步发送,Java Mail技术对用户账号进行验证,Memached技术实现内存级缓存,同时在项目开发中使用SVN进行项目的版本控制。
3系统规划与系统分析
3.1系统的总体结构
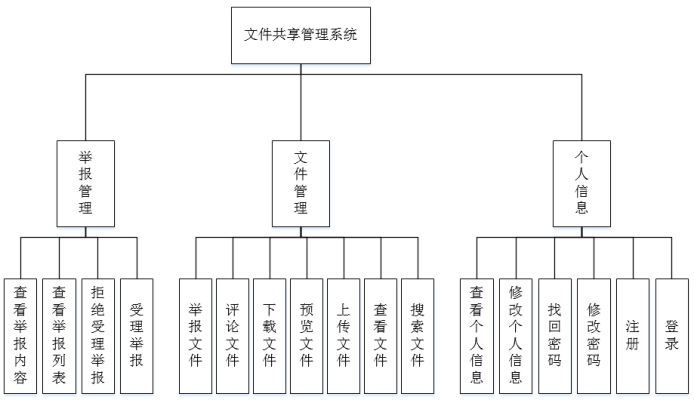
根据文件共享管理系统的设计需求,确定本系统平台的整体运作模式要求用户通过web端进入文件共享系统的首页系统搜索自己需要的文件,用户根据系统呈现的数据选择满足自己需要的,进而点击该文件在线预览以验证该文件是否符合自己的需要,从而再进行文件的下载。最后用户也可以上传自己的文件资源供其他用户检索下载,从而达到资源共享的目的。
按照每个用户可以操作的功能来理清系统整体功能,系统功能模块图如图3.1所示的。
4系统设计与实现
4.1系统用户功能设计
系统用户分为三种角色:游客、用户、管理员。这三个角色的功能如下所述:
(1)游客
搜索资料:游客可以在搜索框输入要搜索文件的关键字进行搜索;
查看文件信息:游客可以点击搜索结果列表的文件查看该文件的详细信息以及其他用户对该文件的评论;
预览文件:游客可以对查看的文件进行在线预览;
(2)用户
搜索资料:用户可以在搜索框输入要搜索文件的关键字进行搜索;
查看文件信息:用户可以点击搜索结果列表的文件查看该文件的详细信息以及其他用户对该文件的评论;
下载文件:用户可以下载该文件;
评论文件:用户可以评论下载过的文件,但只能评论一次;
举报文件:用户可以举报下载过的文件,但只能举报一次;
上传文件:用户可以上传office文件供其他用户下载;
用户注册:用户通过邮箱验证的方式进行注册;
用户登录:用户登录成功的同时系统会向用户手机发送短信告知;
查看个人信息:用户可以查看个人信息;
修改个人信息:用户可以修改个人信息;
找回密码:用户通过注册的邮箱信息重设密码;
(3)管理员
查看投诉列表:管理员查看用户投诉列表;
处理投诉:对用户的投诉信息进行查看并处理;
用户登录:用户登录成功的同时系统会向用户手机发送短信告知;
查看个人信息:用户可以查看个人信息;
6软件开发中主要解决的问题
本系统是一个面向互联网用户的项目,本系统不仅要保证用户的账号安全不被盗用,还有保证本系统中内容的健康性,不散播低俗淫秽内容和用户体验的友好和及时性。另外本系统是一个分布式系统,相比以往的传统系统有很多挑战需要解决。
6.1帐号登录的安全性
因为系统的网络连接采用基于socket的http协议,所以用户的输入的账号密码在网络传输过程中存在被人劫持而暴露用户密码的风险。采用传统方式web页面对前端用户输入的明文密码进行加密,然后在网络中传输加密后的密码,服务器接收到加密码后与数据库中的加密的密码进行比较来验证用户是否可以登录,但是这种方式下盗号者完全不需要知道用户的明文密码是多少,只需要劫持到网络传输中的加密后密码,以后直接发加密密码即可登录系统。
因为以上原因,我们想到的是,用户在登录页面,服务器根据用户存在与服务器的session生成一个随机码保存在服务器中,同时把这个值传给登录页面,登录页面获取这个值后拼接到用户的密码明文后面进行加密后通过网络传输到服务器,服务器接受到加密后密码后,通过服务器存储的随机值与数据库的原始密码也拼接起来加密后进行比较来验证用户登录,这样就可以保证用户每一次登录时通过网络发送的加密密码不一样,这样就算被劫持,也无法被人使用。
6.2搜索的精准与快速
如何人性化为用户提供精准服务,采用全文检索——垂直化搜索引擎主要针对系统内部的自有数据的检索,通过对系统内部数据建立索引提供给用户进行检索。
它既能满足用户对全文检索,模糊匹配的需求,解决数据库like查询效率低下的问题,又能够解决分布式环境下,由于采用分库分表或使用NoSQL数据库,导致无法进行多表关联或者进行复杂查询的问题。
lucene将文档中的词作为关键字,建立词与文档的映射关系,通过对倒排索引的检索,可以根据词快速获取包含这个词的文档列表。
能对句子或段落进行切割,从中取出包含固定语义的词。
当输入一个关键字进行搜索时,可能会命中许多文档,搜索引擎给用户的价值就是快速地找到需要的文档,根据排序算法,将相关度更大的内容排在前面,命中多次的文档比命中一次的文档有更高的相关性。
6.3文件的处理
传统系统用户只能下载文件后才能查看文件内容,并不能让用户在文件下载之前就能查看文件的内容,经常导致用户下载文件后发现文件不是自己想要的,不仅影响用户的体验,同时也给网站带来流量开销和连接的压力。为了实现文件预览,我们需要将文件转换为swf文件,实现flash播放达到预览,在这里面我们不仅要考虑不用版本office文件处理问题,还要考虑如果文件里面有图片如何准确提取出来把数据正确的存储到swf文件中。在这我们通过java代码使用OpenOffice服务把文件转换为swf文件,使用FlexPaper,swfTools在线预览,从而达到用户不需下载文件就能看到文件内容。
6.4敏感词过滤
由于本系统收录的敏感词库中包含上万个敏感词,系统要对用户输入的文件信息进行处理,检查用户输入的信息是否含有敏感词,但是这里带来一个效率问题,采用传统思路,系统会对用户输入的一个文本数据比对上万次,来验证文本数据是否包含敏感词库的词。显然这是十分耗时的。NFA是非确定性的状态机,DFA是确定性的状态机。确定性和非确定性的最大区 别就是:从一个状态读入一个字符,确定性的状态机得到一个状态,而非确定性的状态机得到一个状态的集合。如果我们把NFA的起始状态S看成一个集合{S} 的话,对于一个状态集合S’,给定一个输入,就可以用NFA计算出对应的状态集合T’。因此我们在构造DFA的时候,只需要把起始状态对应到S’,并且找 到所有可能在NFA同时出现的状态集合,把这些集合都转换成DFA的一个状态,那么任务就完成了。因为NFA的状态是有限的,所以NFA所有状态的集合的 幂集的元素个数也是有限的,因此使用这个方法构造DFA是完全可能的。
6.5网站高并发
一台tomcat服务器最大能支持的稳定并发数在100—120之间,因为本系统是面向互联网用户的,所以在同一时刻本系统面对的并发数远远大于120,当实际并发数大于tomcat服务器的支持数量后,会导致服务器因为压力过大而无法及时处理其他请求,甚至导致服务器宕机。考虑到高并发访问的情况,本系统使用Nginx服务器的负载均衡技术构建一个由多台服务器组成的服务器集群,将来自客户端的并发访问请求分发到多台服务器上处理,避免单一服务器出现负载压力过大的情况。
为了保证当任意一台或多台服务器宕机,Nginx服务器将请求提交给集群中其他任意一台可用服务器能够正确处理处理,本系统需要设置每一台服务器不保存请求的状态,这样所有的服务器完全对等,服务器就可以成功处理其他服务器之前处理的请求了。
6.6服务器集群下状态共享
集群中所有的应用服务器都是无状态的,但是在业务上系统总是有状态的,因为系统需要记录用户当前的登录状态来确定用户是否可以执行接下来的操作。web应用中将这些多次请求使用的上下文对象称作会话(session),单机情况下,session可由部署在服务器上的web容器管理。在使用负载均衡的集群环境中,请求由负载均衡服务器分发到集群上任意一台应用服务器上,如何保证任意一台应用服务器对每次请求依然能够获得正确的session是一个挑战。
通过将一部分数据存储在cookie中,来解决分布式环境下session操作同步的问题。但是这样做的弊端有很多,比如cookie的安全性,cookie存储数据的大小的限制。
本系统的解决方案是将session统一存储在缓存集群memcache上,这样保证较高的读,写性能,再从安全性上看,利用缓存的失效机制,达到控制session有效期的的作业。
6.7高并发下磁盘读写速度
系统在面对高并发的情况下,大量的读,写请求涌向数据库,磁盘的处理速度与内存显然不在一个量级,为了能提高系统对数据的读取速度,通常将常用的数据放在内存中,这样就避免了应用程序读取硬盘而增加时间开销。
memcache是一个高性能的内存对象缓存系统,为了提高在内存中查找数据的速度,memcache在内存中维护一张巨大的HashTable,使得对数据查询的时间复杂度降低到O(1)。内存的空间总是有限的,当内存没有更多的空间来存储新数据时,memcache会使用LRU算法,将最近不常访问的数据淘汰掉,以腾出空间来存放新的数据。
6.8分布式数据库事务一致性
软件系统对单个数据库内部的多个DML操作都会组成一个局部事务,因为这些操作不会跨越多个事务性资源,软件系统可以直接使用底层数据库的事务支持;但是当软件系统的功能操作涉及对多个数据库的修改时,就面临多个数据库事务的一致性问题,这些数据库的操作要么全部成功要么全部不成功,这就是分布式事务,分布式事务处理的对象是全局事务。
使用JTA编程就可以用一种与事务管理器无关的方式来开始,提交或回滚事务,Java EE应用服务器通过java事务服务来实现事务管理器。JTA事务由java EE事务管理器负责控制,它可以保证多个数据库更新的一致性,通过JTA即可实现全局事务控制。
6.9集群下quartz协调处理
在集群环境下,大家会碰到一直困扰的问题,即多个应用程序下如何用quartz协调处理自动化工作。比如现在有A,B,C三台服务器同时作为集群服务器对外统一提供服务;A,B,C三台台机器上各有一个Quarzt,他们会按照即定的时间频率自动执行各自的任务。这样的架构其实有点像多线程,那多线程里就会存在“资源竞争”的问题,即可能产生脏读,脏写,由于三台应用服务器里都有Quarzt,因此会存在重复处理任务的现象。quartz的任务实例化如数据库,基于数据库引擎及High-Available的策略(集群的一种策略)自动协调每个节点的quartz,当任一一节点的quartz非正常关闭或出错时,另几个节点的quartz会自动启动;这样每台作为集群点的应用程序上都可以布署quartz;无需开发人员更改原已经实现的quartz,使用Spring类反射的机制对原有程序作切面重构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号