
文档数字化采集与智能处理:图像弯曲矫正技术概述
由于电子文档更容易存档、编辑、签名和共享的特点,文档电子化的趋势逐年显著,而随着高质量摄像头在手机等移动设备上的普及,利用移动设备对文档进行数字化采集已经非常普遍。
移动设备让每一位使用者能够便捷采集文档图像,不过,这也使原始文档图像的情况变得复杂多变:页面弯曲、阴影遮挡、摩尔纹、图片模糊、字迹不清晰等问题都是文本图像处理中常见的干扰状况,阻碍了文档的智能化处理,导致OCR识别、信息提取、版面分析和还原等任务难度增加。
在本篇中,我们将从图像弯曲矫正这一图像处理技术重点出发,讨论其发展过程与前沿技术。
首先,让我们先来看看图像形变矫正技术对OCR、信息提取等智能处理下游任务的重要性。
图1 图像矫正对比
如图中所示,形变矫正前后,同一个解析引擎对图像中的表格进行提取,得到的结果相差甚远,矫正技术对正确的信息获取具有关键影响。
为解决文档弯曲矫正问题,学术界已有多种方案。在2015年之前,主流方案是基于文本行线拟合和坐标变换方法,通过文本行检测、使用数学模型进行文本行线拟合与坐标变换,使得文本行变得水平或垂直。但是,其校正效果受文字行检测准确度的限制,对文档版式、清晰度和规律性比较敏感,无法处理存在大量图表的文档,且误检的文字行有可能会对校正造成严重干扰。
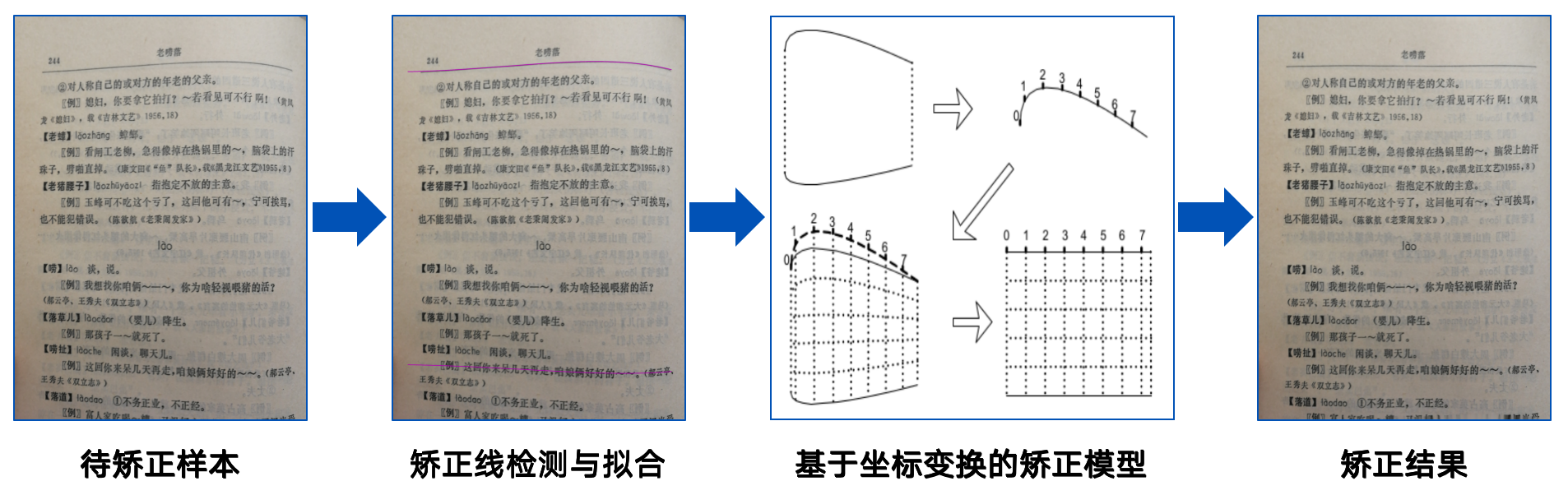
图2 基于文本行线坐标变换的方法
在这种背景下,基于文本行线拟合的优化方法被提出,利用损失函数缓慢迭代优化以获得形变矫正结果,但它的缺点在于时间较长,不适合实时应用。

图3 基于文本行线坐标变换的优化方法
2019年后,基于学习的方法因大型数据集的可用性而越来越受到欢迎。基于数据驱动的位移场学习方法是一种利用深度学习技术从数据中直接学习位移场的方法,它的核心在于使用神经网络来模拟和预测位移场,从而实现对物体变形的高精度测量。
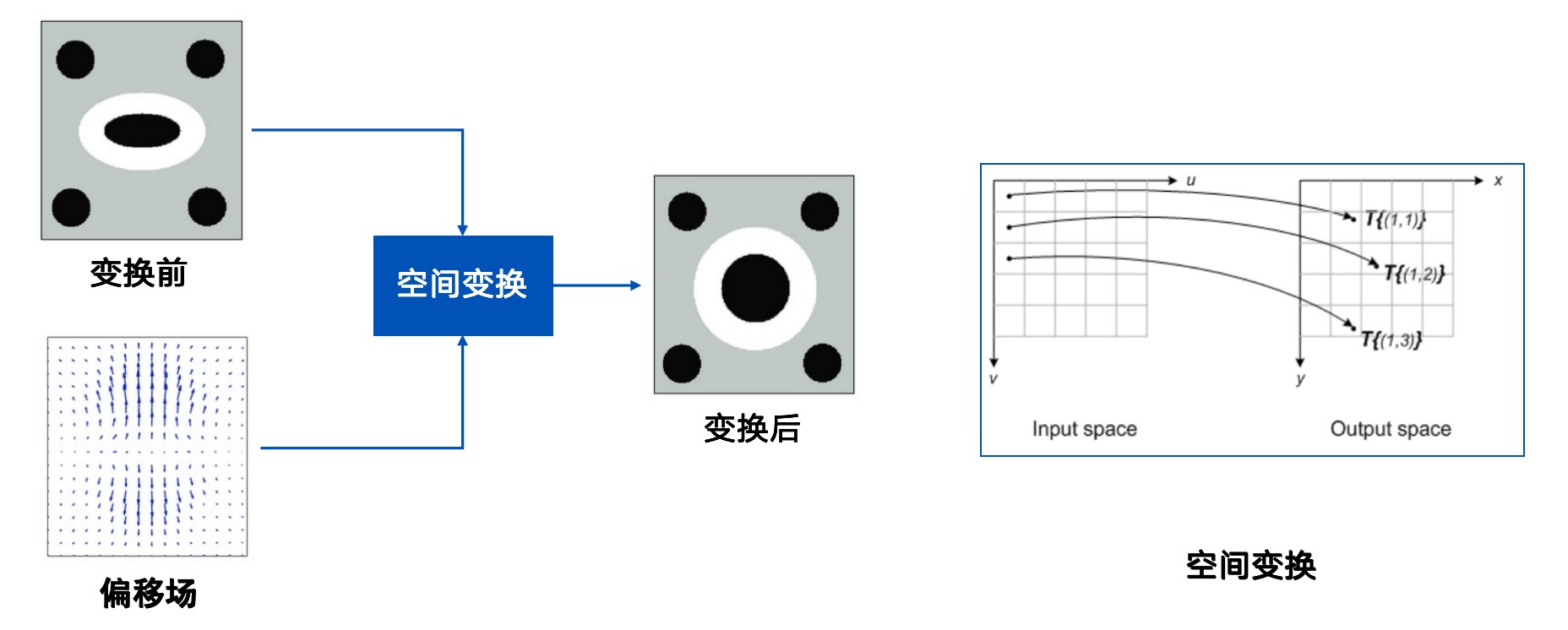
图4 基于偏移场学习的方法
Das等人[2]首次在这项任务中使用卷积神经网络(CNNs),他们采用CNNs来检测折痕,并将文件分割成多个块进行矫正,这种方法能够解决简单变形和单调背景下的问题。
Ma等人[4]提出了一个堆叠的 U-Net,它经过训练端到端预测翘曲的前向映射。Das等人[1]认为当合成训练数据集仅使用 2D 变形进行训练时,弯曲矫正模型并不总是表现良好,因此他们创建了一个 Doc3D 数据集,该数据集具有多种类型的像素级文档图像偏移场,同时使用真实世界文档和渲染软件。
Feng等人[3]使用Transformer[5]作为网络架构,取得了进一步优化的性能。然而,在实际应用中,这些方法的去畸变性能仍有不足之处。
Reference:
[1] Sagnik Das, Ke Ma, Zhixin Shu, Dimitris Samaras, and Roy Shilkrot. 2019. DewarpNet: Single-image document unwarping with stacked 3D and 2D regression networks. In ICCV. 131–140.
[2] Sagnik Das, Gaurav Mishra, Akshay Sudharshana, and Roy Shilkrot. 2017. The common fold: utilizing the four-fold to dewarp printed documents from a single image. In DocEng. 125–128.
[3] Hao Feng, Yuechen Wang, Wengang Zhou, Jiajun Deng, and Houqiang Li. 2021. DocTr: Document image transformer for geometric unwarping and illumination correction. In ACM MM. 273–281.
[4] Ke Ma, Zhixin Shu, Xue Bai, Jue Wang, and Dimitris Samaras. 2018. DocUNet: Document image unwarping via a stacked U-Net. In CVPR. 4700–4709.
[5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In NeurIPS. 5998–6008.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号