Storm学习笔记 - Storm初识
1. Strom是什么?
- Storm是一个开源免费的分布式计算框架,可以实时处理大量的数据流。
2. Storm的特点
- 高性能,低延迟。
- 分布式:可解决数据量大,单机搞不定的场景。
- 可扩展:随着业务的发展,数据量越来越大,系统可以水平扩展。
- 容错:单个节点挂了,不影响整个应用。
3. Storm与其他框架的比较
3.1 Storm和Hadoop的比较
- Storm用于实时计算,Hadoop用于离线计算。
- Storm处理的数据保存在内存中,源源不断。Hadoop处理的数据保存在文件系统中,一批一批。
- Storm与Hadoop的编程模型相似。
3.2 Storm与Spark streaming的比较
- Spark streaming采用小批量的方式,提高了吞吐性能。
- 处理数据的粒度变大,导致Spark streaming的数据延时不如Storm,Spark streaming是秒级返回结果(与设置的batch间隔有关),Storm则是毫秒级。
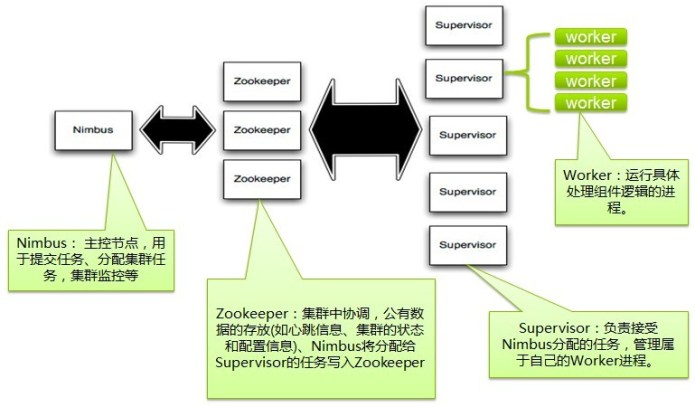
4. Storm集群架构
![Storm集群架构]()
- Nimbus:Storm集群的主节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
- Supervisor,Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker的启动和终止。可以通过配置项决定在一个Supervisor上最大可以运行多少个Slot,每个Slot通过端口号来唯一标识,一个端口号对应一个Worker进程。
- Worker:运行处理具体组件逻辑的进程,Worker运行的进程只有两种,一种是Spout进程,一种是Bolt进程。
- Task:Worker中每一个Spout/bolt的线程称为一个Task。
- Zookeeper:用来协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配Topology到其他可用的Supervisor上运行。
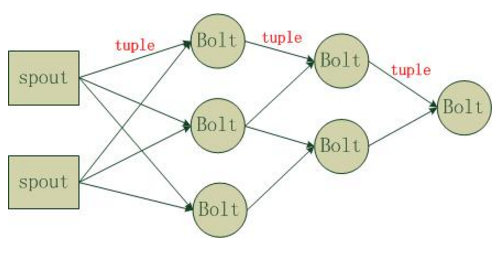
5. Storm编程模型
![Storm编程模型]()
- Topology:Storm中运行的一个实时应用程序的名称。将 Spout、 Bolt整合起来的拓扑图。定义了 Spout和Bolt的结合关系、并发数量、配置等等。
- Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
- Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
- Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
- Stream:Tuple的集合。表示数据的流向。
6. 总结
- 拓扑(Topology):打包好的实时应用计算任务,同Hadoop的MapReduce任务相似。
- 元组(Tuple):是Storm提供的一个轻量级的数据格式,可以用来包装你需要实际处理的数据。
- 流(Streams):数据流(Stream)是Storm中对数据进行的抽象,它是时间上无界的tuple元组序列(无限的元组序列)。
- Spout(喷嘴):Storm中流的来源。Spout从外部数据源,如消息队列中读取元组数据并吐到拓扑里。
- Bolts:在拓扑中所有的计算逻辑都是在Bolt中实现的。
- 任务(Tasks):每个Spout和Bolt会以多个任务(Task)的形式在集群上运行。
- 组件(Component):是对Bolt和Spout的统称。
- 流分组(Stream groupings):流分组定义了一个流在一个消费它的Bolt内的多个任务(task)之间如何分组。
- 可靠性(Reliability):Storm保证了拓扑中Spout产生的每个元组都会被处理。
- Workers(工作进程):拓扑以一个或多个Worker进程的方式运行。每个Worker进程是一个物理的Java虚拟机,执行拓扑的一部分任务。
- Executor(线程):是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component。
- Nimbus:Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
- Supervisor:Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。
posted @
2018-10-26 10:35
云端笑猿
阅读(
389)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号