机器学习基础概念-阿里大学课程学习笔记
https://edu.aliyun.com/course/11/learn#lesson/12 的学习笔记
第一章 机器学习概念、原理和应用场景
课时1 机器学习的基础概念
概述:
ArtificialIntelligence ⊆ MachineLearning ⊆ DeepLearning
AI: 1950s - now 使得机器能做一般只能由人做的事
ML:1980s - now 用经验改进性能的计算方法
DL: 2010s - now
一些例子:
垃圾邮件分类:通过词频,使用朴素贝叶斯进行垃圾邮件分类

课时2:机器学习的领域


任务判断:

1 看样本数,样本数<50需继续收集数据
2 有无label 有label,且是category,一般为分类任务
3 如果label是数值,且需要预测,一般为回归任务
4 如果label是数值,不需要预测,只是看数据,用降维合适






A
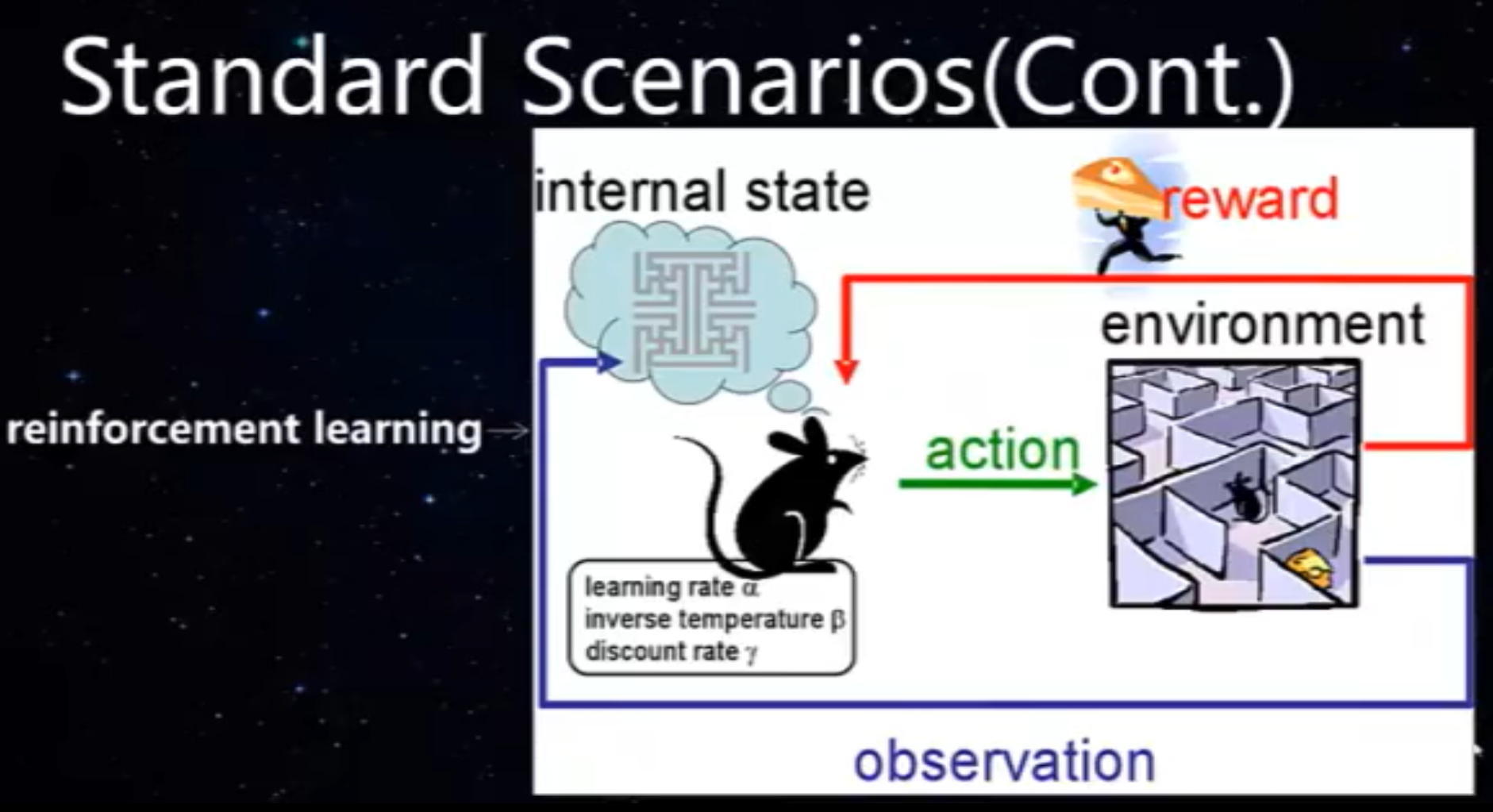
课时3:机器为什么能学习
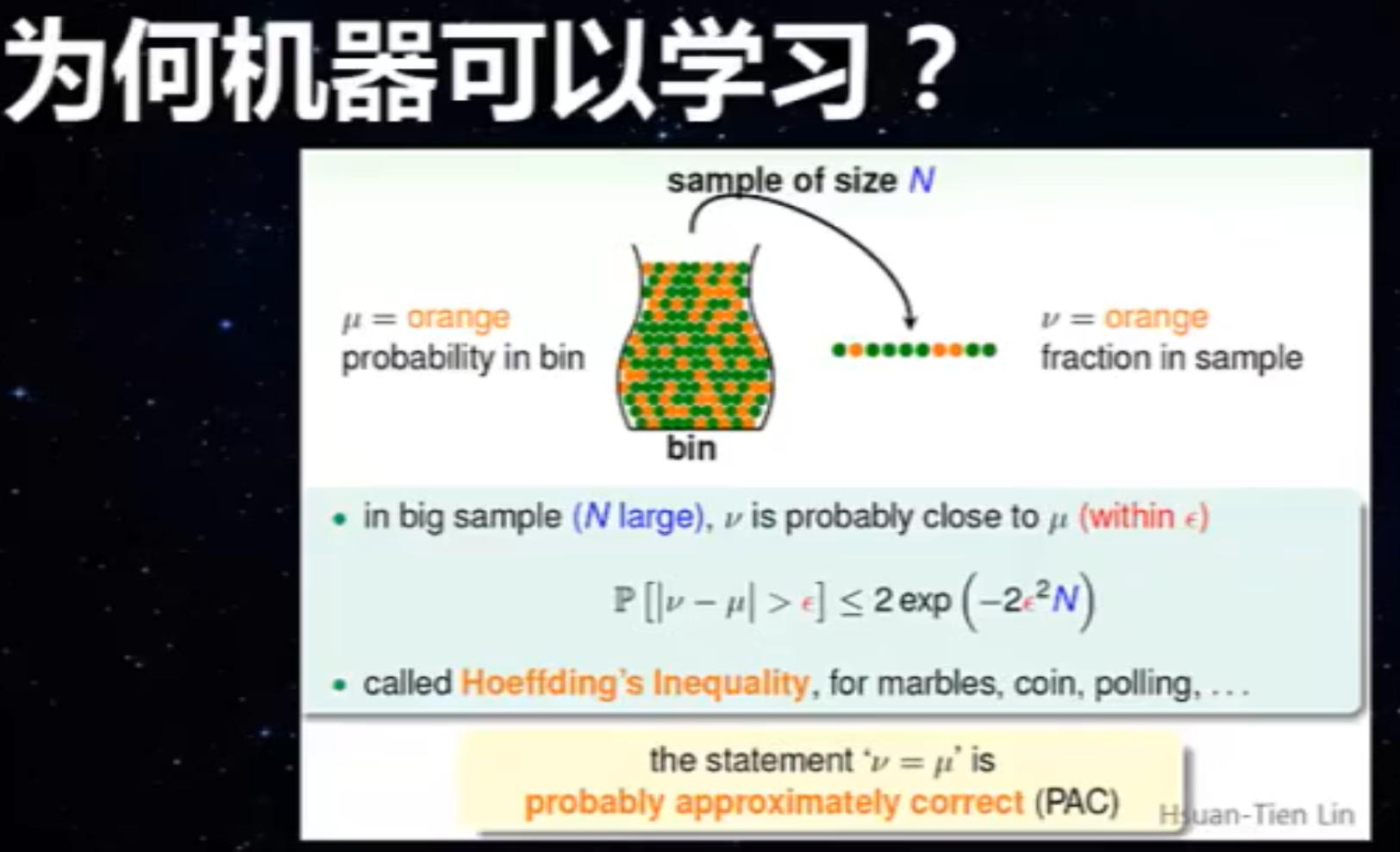
PAC:近似相等。图片描述的是采样原理,采样样本越大,黄球比例越接近真实

直观理解为何机器能学习:类似采样统计样本比例可以猜测球的颜色占比,在独立同分布情况下,通过足够大样本学习推测映射函数h(x),能使得h(x)接近f(x)

ERM:经验分析最小化。容易过拟合
SRM:结构风险最小化。在ERM的后面加正则项,通过惩罚的引入使得模型较为简单

欠拟合:模型太简单
过拟合:模型太复杂

房价欠拟合、适合拟合、过拟合实例



第二章 机器学习常用算法
课时4 监督学习-线性回归

线性回归:
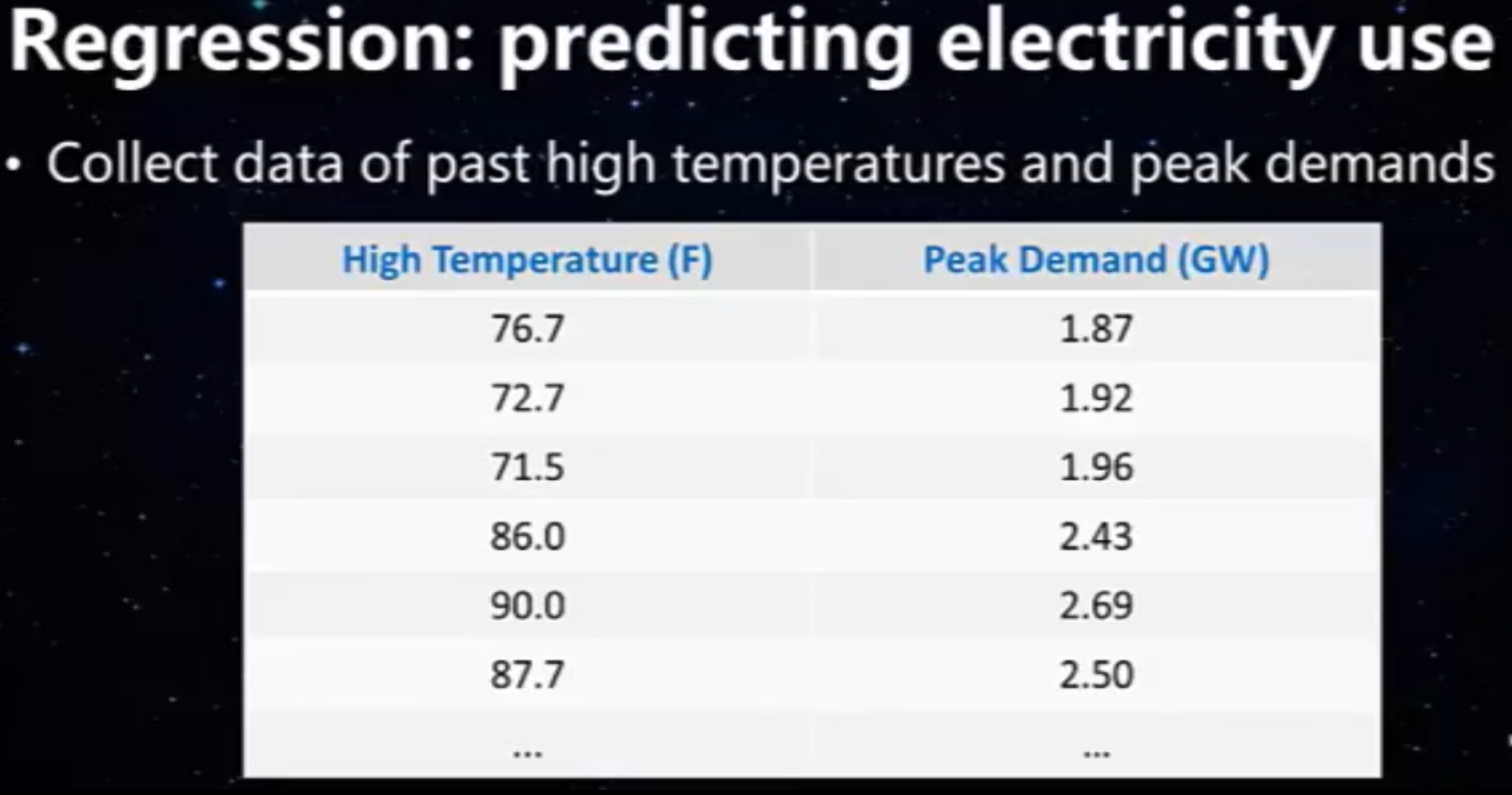
二维情况下的数据示例
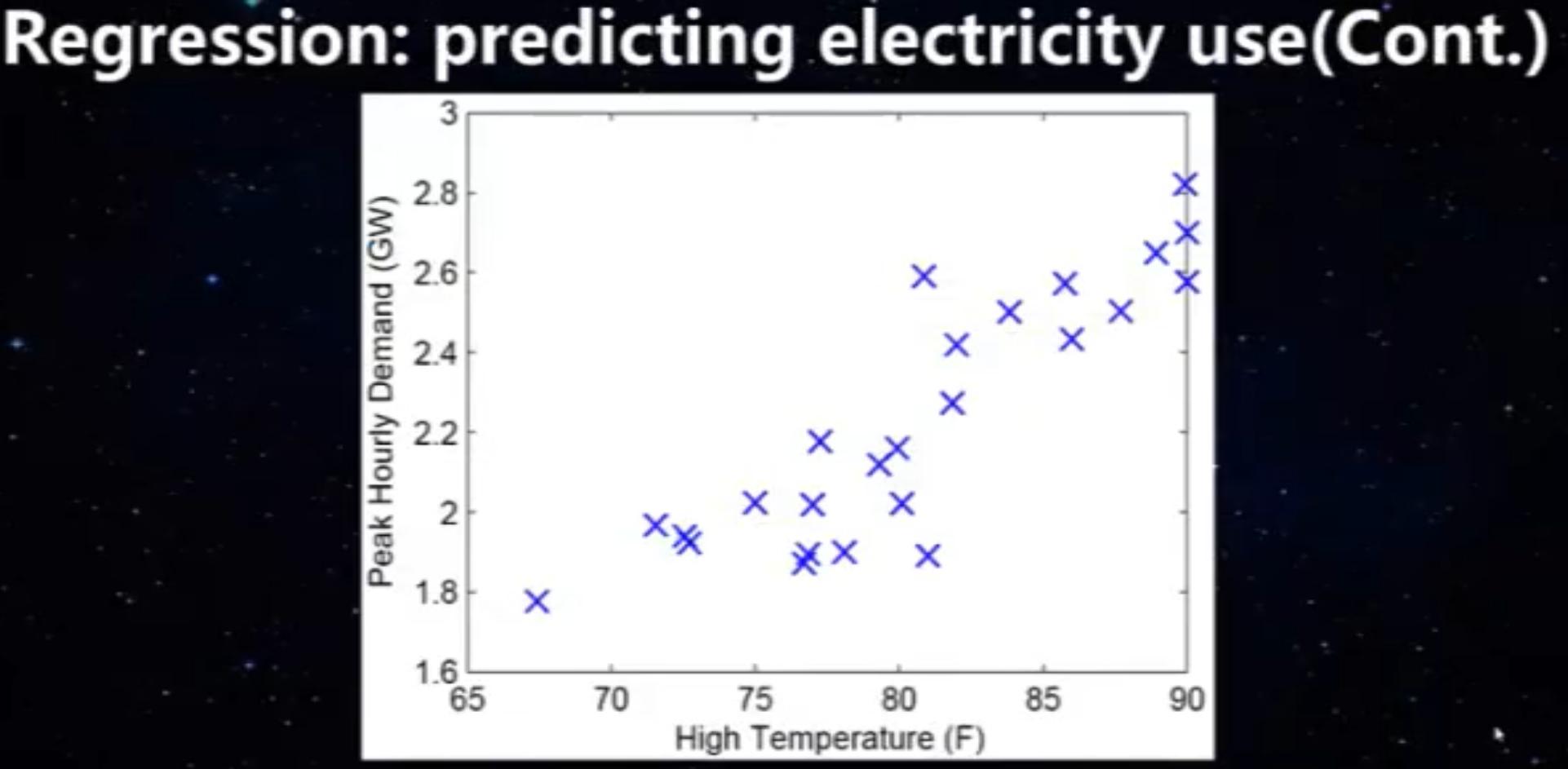
图示化

二维说明

三维示例


通过损失函数评估线性回归效果

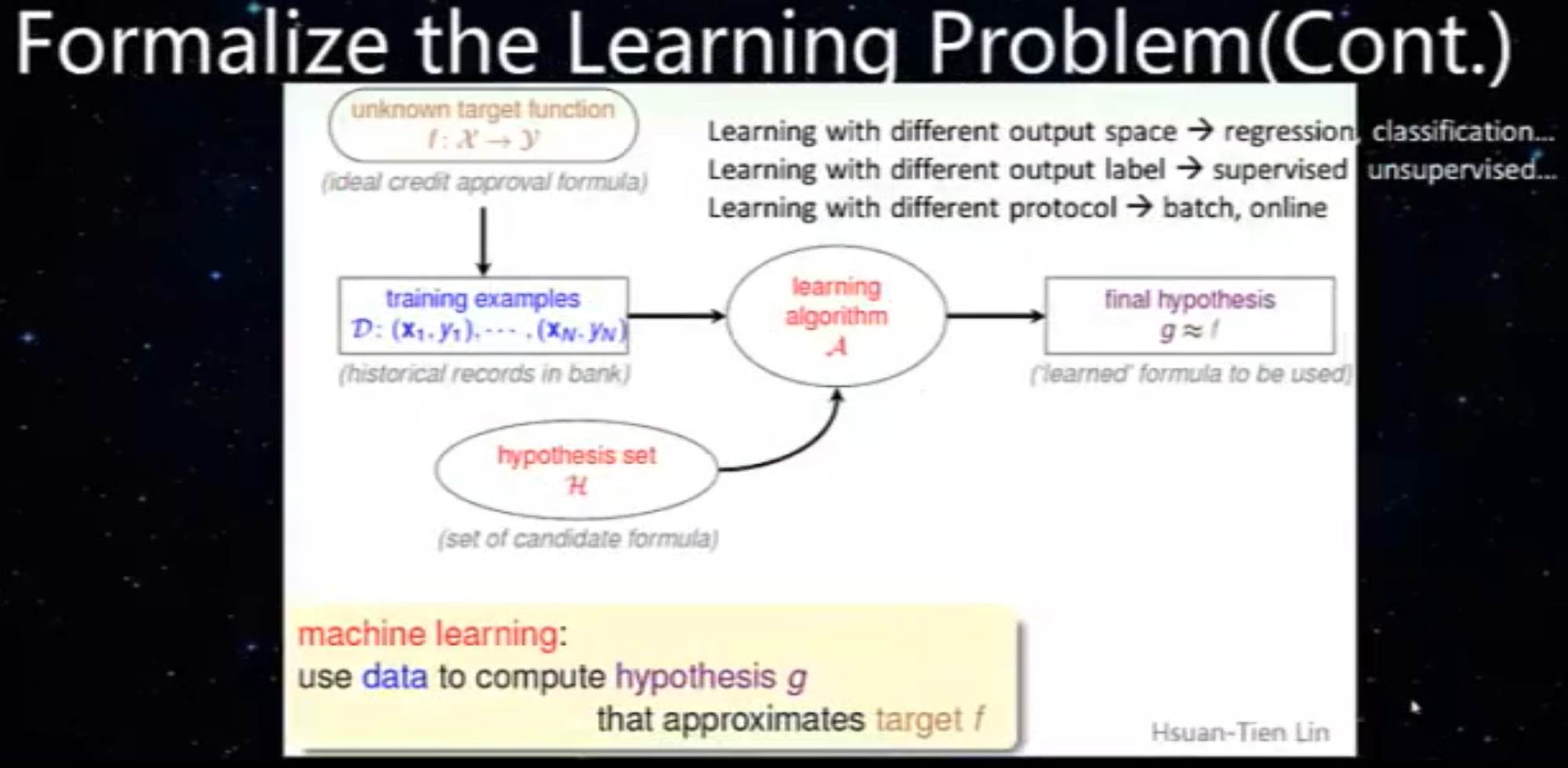
线性回归数学定义

经典机器学习的数学描述


梯度下降迭代θ。如何求二范式梯度?


上面两页推导,说明:二范式最小化,也就是数据集在受高斯噪声影响模型下的,数据集D出现概率最大化。通过数学推导证明二范式的合理性。

B

代码化的逻辑回归。矩阵如何求导?
注:我判断x[:,1] = 1
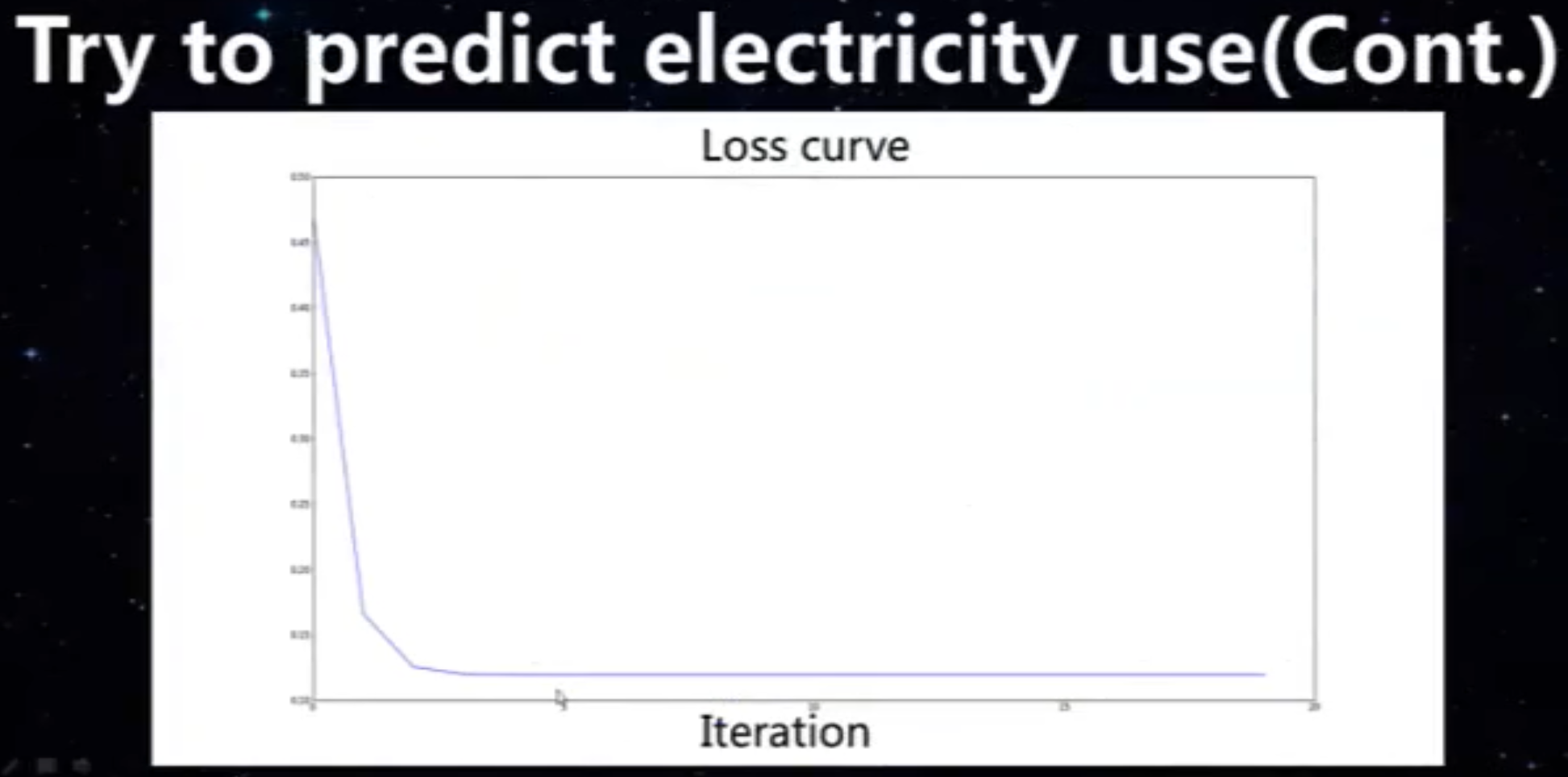

练习:


课时5:非线性回归、过度拟合、模型选择

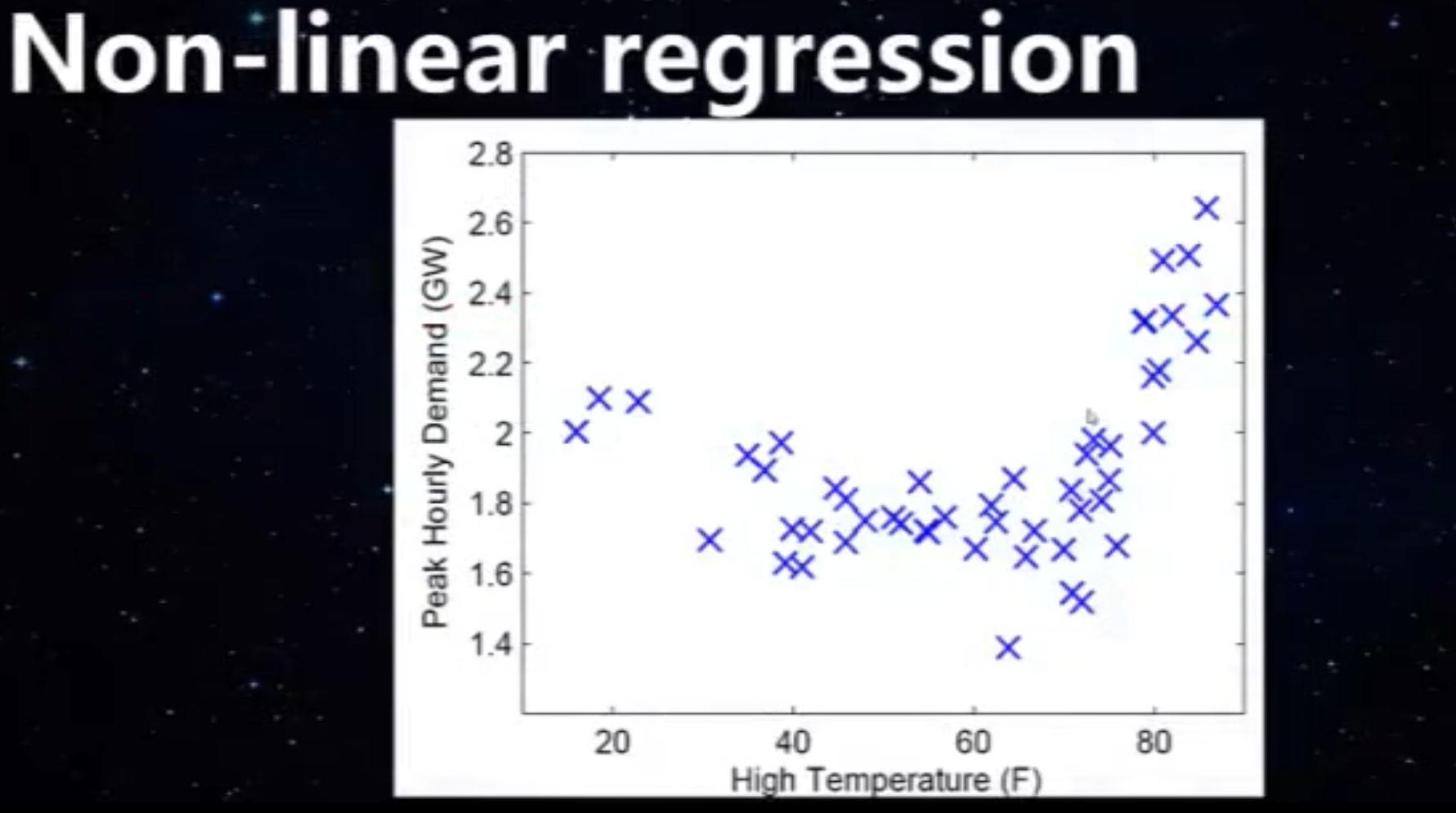
图片的点看起来用二次回归合适,二次回归就属于非线性回归的一种



30维看起来就过拟合了
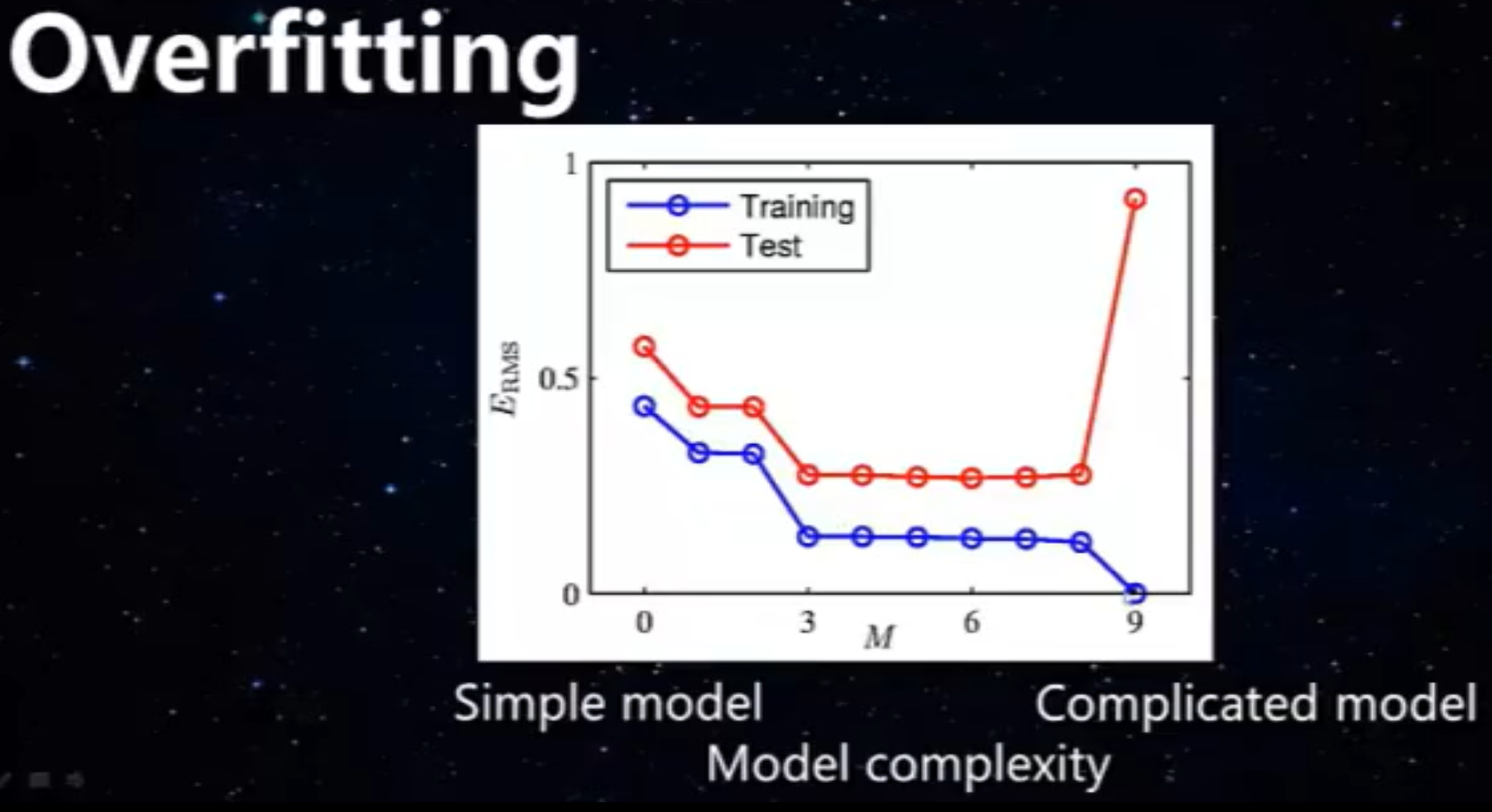
从上图看出,随着维度增加,在训练集上误差逐渐减少,而在测试集上误差先减小后增大。
降低模型过拟合常用方法之一:正则化
下面采用加入参数平方值作为正则化项

如何评价机器学习算法:

把所有数据按7:3分成训练集、测试集,再把训练集再按7:3分成训练集、验证集。



D
课时6:有监督学习分类

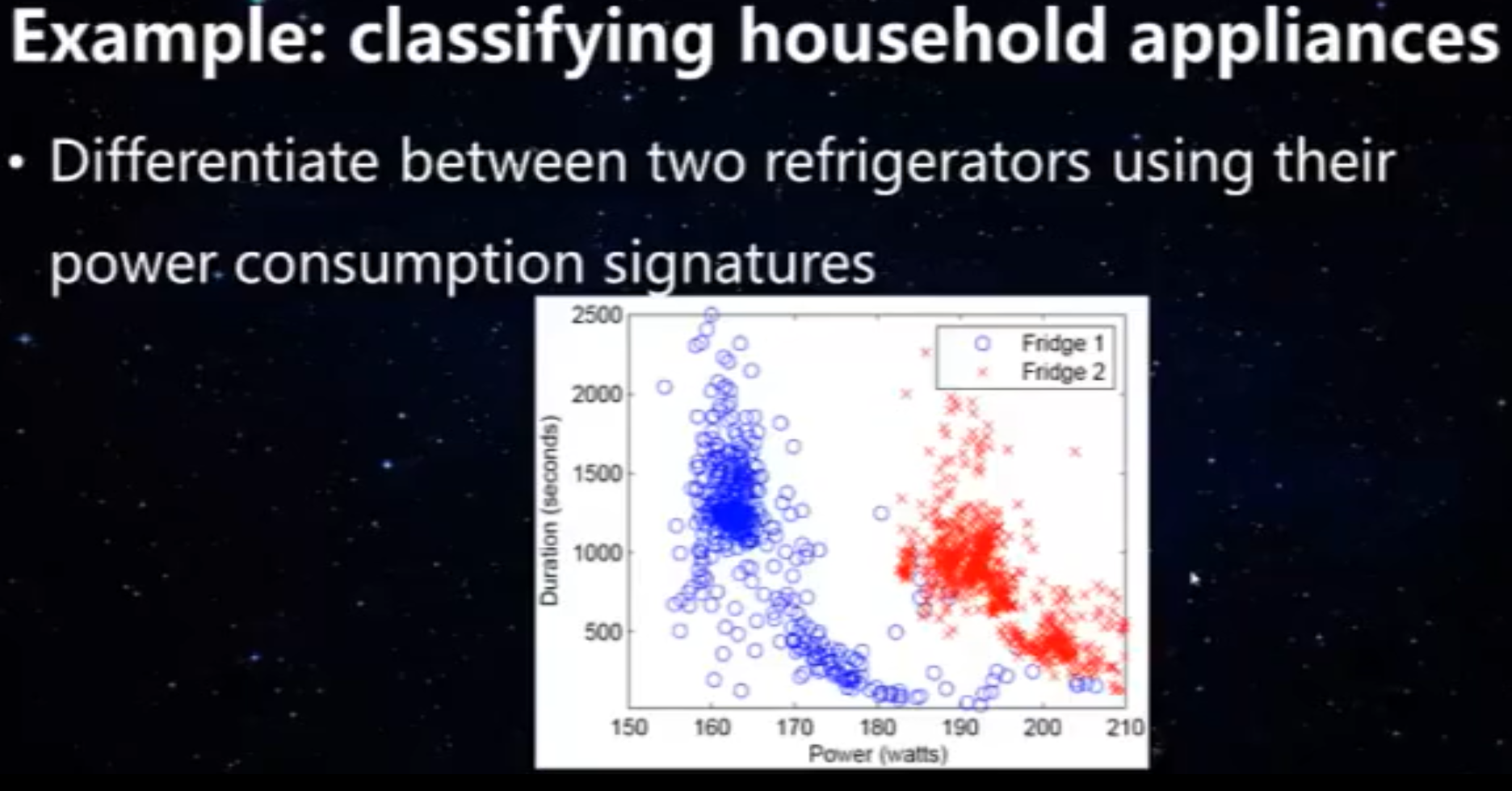








B
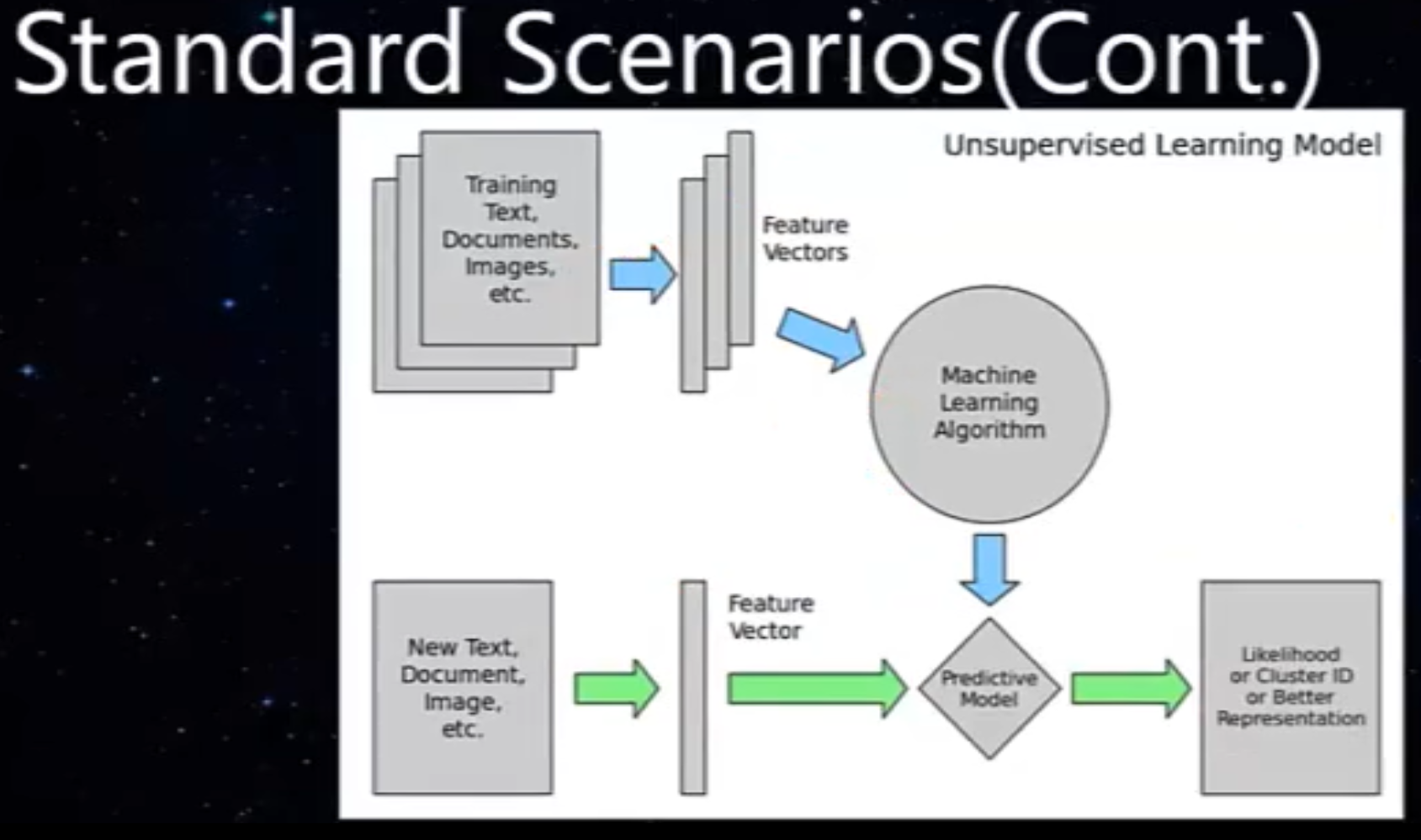
课时7:无监督学习





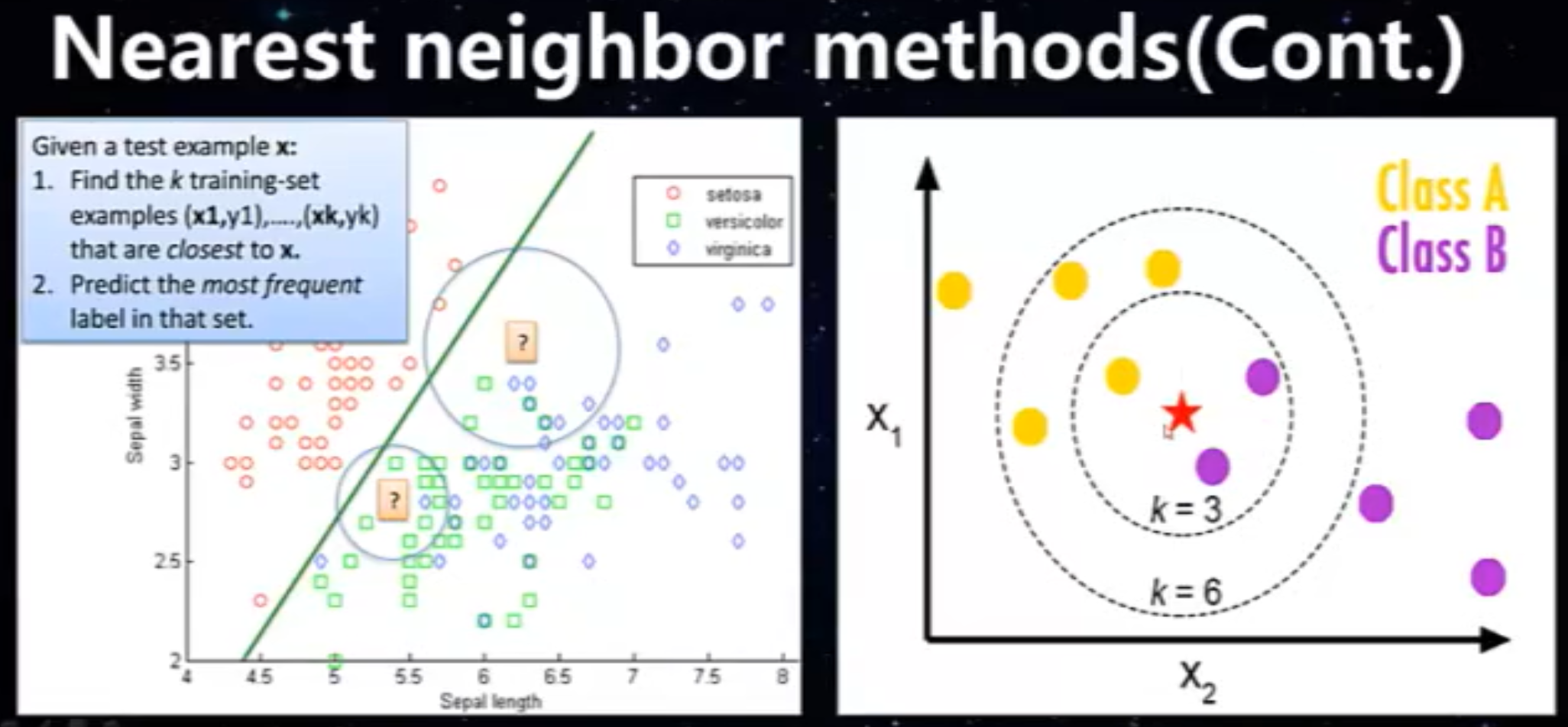

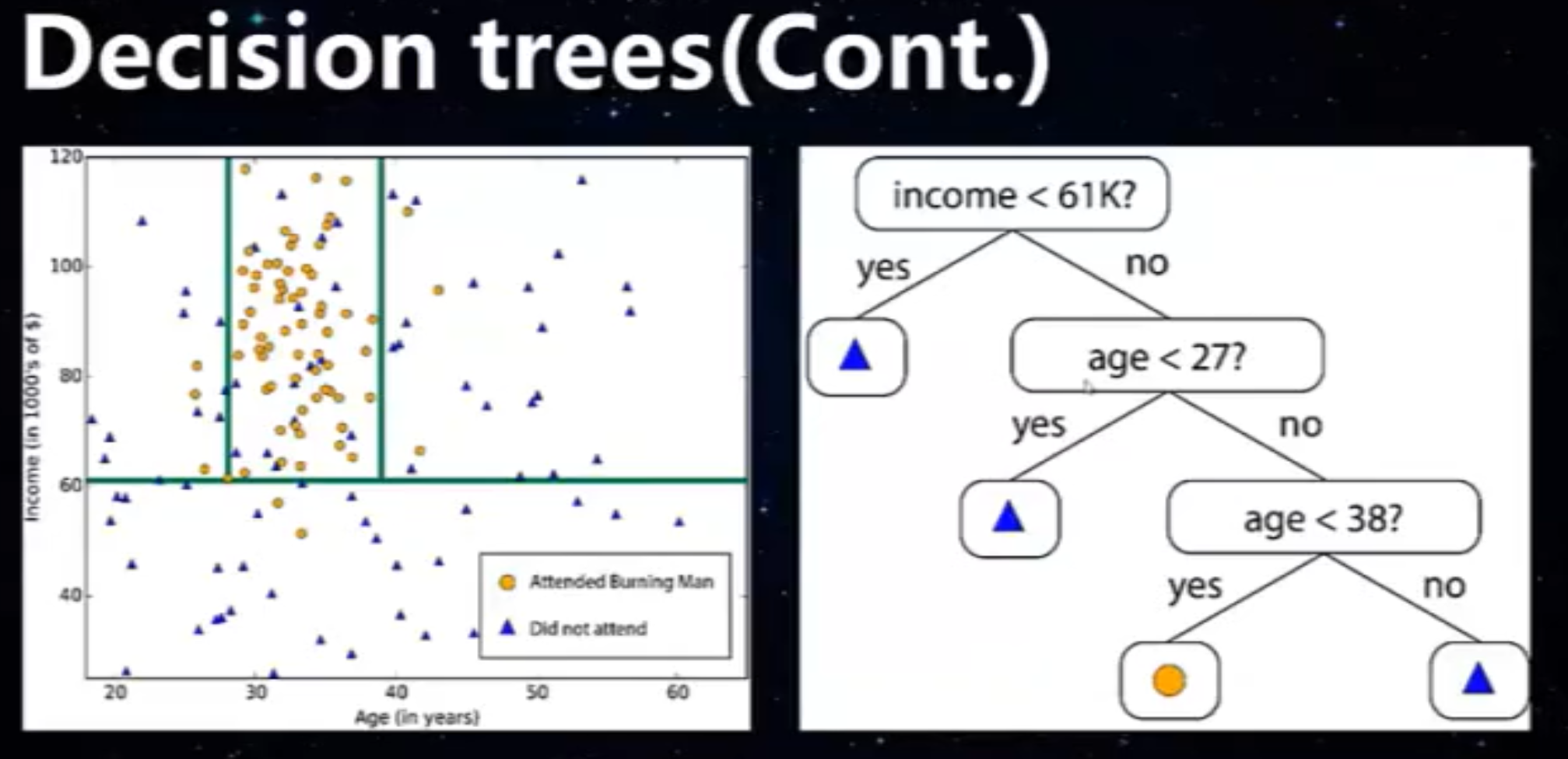

C
。
集成学习:
随机森林:用不同训练集的子集训练决策树,最后用不同决策树的训练结果求平均
boosting:加权使用不同模型。常用算法GDBT










 浙公网安备 33010602011771号
浙公网安备 33010602011771号