机器学习——车牌号码识别
一、选题背景
车牌号识别是指对车辆的车牌号进行自动识别的技术。它的主要作用是在交通管理、汽车出租、停车场、车辆监控等领域中使用。车牌号识别技术主要利用图像处理技术和机器学习算法来识别车牌号。比如:商场地下车库的监控可以进行识别车牌号码,达到识别号码并让其进去,当用户想要离开车库时,可以自动识别并放行。
二、机器学习案例设计方案
下载数据集,整理和处理好数据集,利用keras建立训练模型,对图片进行识别。
数据集来源:kaggle,网址:https://www.kaggle.com/
三、机器学习的实现步骤
1.下载数据集
数据集目录:
└─dataset
├─map.py ---->映射关系文件
├─test ---->测试集
├─train ---->训练集
│ ├─area
│ ├─letter
│ └─province
└─val ----->验证集
├─area
├─letter
└─province
2.数据分析处理
数据处理模块,仿照minist数据集的写法,定义了一个类的初始化函数,定义了若干个变量,用于保存各种数据集的信息
1 def __init__(self,aspect='area',seperate_ratio=0.1): 2 ''' 3 :param aspect: 打开什么样的训练集,[area,letter,province] 三选一 4 :param seperate_ratio: 测试集划分比例 ,从训练集和验证集里面随机抽取seperate_ratio作为训练集 5 :return: 6 ''' 7 self.train_dir = "dataset\\train\\%s\\" %aspect 8 self.val_dir = "dataset\\val\\%s\\" % aspect 9 self.seperate_ratio = seperate_ratio 10 self.data_vector_set = [] #保存所有的图片向量 11 self.data_label_set = [] #保存所有的标签 12 self.train_set = [] #保存训练集的下标 13 self.train_batch_index = 0 14 self.train_epoch =0 15 self.valid_set = [] #保存验证集的下标 16 self.valid_batch_index = 0 17 self.test_set = [] #保存测试集的下标 18 self.test_batch_index = 0 19 self.classes = 0 #最大的classes为34,这个值会在载入train和test后有所变化 20 self.data_set_cnt = 0 21 self.load_train() 22 self.load_valid()
递归遍历给定目录的所有文件和子目录
1 def load_train(self): 2 for rt,dirs,files in os.walk(self.train_dir): 3 self.classes = max(self.classes,len(dirs)) 4 if len(dirs)==0 : 5 #说明到了叶子目录,里面放着就是图片 6 label = int(rt.split('\\')[-1]) 7 for name in files: 8 #将当前目录的路径和文件名拼接起来,得到该文件的完整路径 9 img_filename = os.path.join(rt,name) 10 #将文件转换为矩阵 11 vec = img2mat(img_filename) 12 #将矩阵和对应的标签添加到训练数据集的向量集合和标签集合中。 13 self.data_vector_set.append(vec) 14 self.data_label_set.append(label) 15 #随机决定将该图像文件放到训练集还是测试集中 16 if random.random() < self.seperate_ratio: 17 self.test_set.append(self.data_set_cnt) 18 else: 19 self.train_set.append(self.data_set_cnt) 20 self.data_set_cnt +=1
获取训练集批次数据的函数,批次数据、标签和当前训练轮数返回
1 def next_train_batch(self,batch=100): 2 input_x =[] 3 input_y =[] 4 #每次循环使用 self.train_set 列表的索引来获取训练数据集的向量和标签 5 for i in range(batch): 6 input_x.append(self.data_vector_set[self.train_set[(self.train_batch_index + i)%len(self.train_set)]]) 7 y = [0] * 34 8 y[self.data_label_set[self.train_set[(self.train_batch_index +i)%len(self.train_set)]]] = 1 9 input_y.append(y) 10 self.train_batch_index +=batch 11 if self.train_batch_index > len(self.train_set) : 12 self.train_epoch +=1 13 self.train_batch_index %=len(self.train_set) 14 #返回输入数据、标签和当前训练的轮数。 15 return input_x,input_y,self.train_epoch
将代码封装成模块,然后通过导入模块的方式使用。
1 if __name__ == '__main__': 2 data_gen = data_generator() 3 print(len(data_gen.test_set)) 4 print(data_gen.next_train_batch(100)) 5 print(data_gen.next_valid_batch(100)) 6 print(data_gen.next_test_batch(100))
预测字典
1 maps={
2 "province":
3 {
4 "0":"皖",
5 "1":"沪",
6 "2":"津",
7 "3":"渝",
8 "4":"冀",
9 "5":"晋",
10 "6":"蒙",
11 "7":"辽",
12 "8":"吉",
13 "9":"黑",
14 "10":"苏",
15 "11":"浙",
16 "12":"京",
17 "13":"闽",
18 "14":"赣",
19 "15":"鲁",
20 "16":"豫",
21 "17":"鄂",
22 "18":"湘",
23 "19":"粤",
24 "20":"桂",
25 "21":"琼",
26 "22":"川",
27 "23":"贵",
28 "24":"云",
29 "25":"藏",
30 "26":"陕",
31 "27":"甘",
32 "28":"青",
33 "29":"宁",
34 "30":"新"
35 },
36 "area":
37 {
38 "0":"A",
39 "1":"B",
40 "2":"C",
41 "3":"D",
42 "4":"E",
43 "5":"F",
44 "6":"G",
45 "7":"H",
46 "8":"I",
47 "9":"J",
48 "10":"K",
49 "11":"L",
50 "12":"M",
51 "13":"N",
52 "14":"O",
53 "15":"P",
54 "16":"Q",
55 "17":"R",
56 "18":"S",
57 "19":"T",
58 "20":"U",
59 "21":"V",
60 "22":"W",
61 "23":"X",
62 "24":"Y",
63 "25":"Z"
64 },
65 "letter":
66 {
67 "0":"0",
68 "1":"1",
69 "2":"2",
70 "3":"3",
71 "4":"4",
72 "5":"5",
73 "6":"6",
74 "7":"7",
75 "8":"8",
76 "9":"9",
77 "10":"A",
78 "11":"B",
79 "12":"C",
80 "13":"D",
81 "14":"E",
82 "15":"F",
83 "16":"G",
84 "17":"H",
85 "18":"J",
86 "19":"K",
87 "20":"L",
88 "21":"M",
89 "22":"N",
90 "23":"P",
91 "24":"Q",
92 "25":"R",
93 "26":"S",
94 "27":"T",
95 "28":"U",
96 "29":"V",
97 "30":"W",
98 "31":"X",
99 "32":"Y",
100 "33":"Z"
101 }
102 }
3.模型设计
数据集把车牌的三个部分分开,所以设计三个模型分别去识别这三部分。三个部分都用一个CNN 网络结构,但是每个网络结构里面的具体参数是各自独立的。
CNN网络结构
1 #定义三个卷积层'conv1'、'conv2' 、'conv3',并用TensorFlow计算输出进行非线性变换。 2 #定义二个池化层'pooling2' 、 'pooling3',执行最大值池化操作。 3 with tf.name_scope('conv1'): 4 #卷积层的权重矩阵 5 W_C1 = tf.Variable(tf.compat.v1.truncated_normal(shape=[3,3,1,32],stddev=0.1)) 6 #卷积层的偏置向量 7 b_C1 = tf.Variable(tf.constant(0.1, tf.float32, shape=[32])) 8 #将 input_x 转换为四维矩阵 X 9 X=tf.reshape(input_x,[-1,20,20,1]) 10 #使用 tf.nn.conv2d 函数计算卷积层的输出,步长为[1,1,1,1],并使用 "SAME" 11 featureMap_C1 = tf.nn.relu(tf.nn.conv2d(X,W_C1,strides=[1,1,1,1],padding='SAME') + b_C1 ) 12 with tf.name_scope('conv2'): 13 W_C2 = tf.Variable(tf.compat.v1.truncated_normal(shape=[3, 3, 32, 64], stddev=0.1)) 14 b_C2 = tf.Variable(tf.constant(0.1, tf.float32, shape=[64])) 15 featureMap_C2 = tf.nn.relu(tf.nn.conv2d(featureMap_C1, W_C2, strides=[1, 1, 1, 1], padding='SAME') + b_C2) 16 17 with tf.name_scope('pooling2'): 18 #ksize参数指定了池化窗口的大小为[1,2,2,1],strides 参数指定了池化窗口的滑动步长为[1,2,2,1],padding参数设置为'VALID'表示不使用边缘填充 19 featureMap_S2 = tf.nn.max_pool(featureMap_C2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='VALID') 20 21 with tf.name_scope('conv3'): 22 W_C3 = tf.Variable(tf.compat.v1.truncated_normal(shape=[3, 3, 64, 8], stddev=0.1)) 23 b_C3 = tf.Variable(tf.constant(0.1, shape=[8], dtype=tf.float32)) 24 featureMap_C3 = tf.nn.relu(tf.nn.conv2d(featureMap_S2, filters=W_C3, strides=[1, 1, 1, 1], padding='SAME') + b_C3) 25 26 with tf.name_scope('pooling3'): 27 featureMap_S3 = tf.nn.max_pool(featureMap_C3,[1,2,2,1],[1,2,2,1],padding='VALID') 28 29 #定义了全连接层'fulnet' 30 with tf.name_scope('fulnet'): 31 #将featureMap_S3 转换为一个二维的矩阵 32 featureMap_flatten = tf.reshape(featureMap_S3, [-1, 5 * 5 * 8]) 33 # 定义全连接层的权重矩阵和偏置向量 34 W_F4 = tf.Variable(tf.compat.v1.truncated_normal(shape=[5 * 5 * 8, 512], stddev=0.1)) 35 b_F4 = tf.Variable(tf.constant(0.1, shape=[512], dtype=tf.float32)) 36 # 使用matmul 计算矩阵乘法,将结果加上偏置向量 b_F4,并对结果进行非线性变换 37 out_F4 = tf.nn.relu(tf.matmul(featureMap_flatten,W_F4) + b_F4) 38 #使用dropout 操作随机将一部分输出置为0,减少过拟合的风险 39 out_F4 =tf.nn.dropout(out_F4,rate=0.5) 40 #定义输出层'output' 41 with tf.name_scope('output'): 42 #定义输出层的权重矩阵和偏置向量 43 W_OUTPUT = tf.Variable(tf.compat.v1.truncated_normal(shape=[512, 34], stddev=0.1))#权重矩阵有 512 行和 34 列 44 b_OUTPUT = tf.Variable(tf.constant(0.1,shape=[34],dtype=tf.float32))#输出层有 34 个输出 45 #使用matmul函数计算矩阵乘法,将输入out_F4与权重矩阵W_OUTPUT相乘,并将结果加上偏置向量b_OUTPUT。logits 就是模型的预测结果。 46 logits = tf.matmul(out_F4, W_OUTPUT) + b_OUTPUT

4.数据预处理,创建优化器,采用最小化交叉熵损失
1 #输入了标签和输入数据的 logit(即网络的输出),并计算了两者之间的交叉熵损失 2 loss = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(labels=input_y,logits=logits)) 3 #创建了一个 Adam 优化器,并使用优化器的 minimize 方法最小化交叉熵损失 4 train_op = tf.compat.v1.train.AdamOptimizer(learning_rate=input_learning_rate).minimize(loss) 5 #将模型的输出转换为概率分布 6 predictY = tf.nn.softmax(logits) 7 #从概率分布中选取最大概率对应的类别 8 y_pred=tf.compat.v1.arg_max(predictY,1) 9 #比较标签和预测的类别是否相同 10 bool_pred=tf.equal(tf.compat.v1.arg_max(input_y,1),y_pred) 11 #计算正确率 12 right_rate=tf.reduce_mean(tf.compat.v1.to_float(bool_pred)) 13 saver = tf.compat.v1.train.Saver() 14 15 #从给定的目录加载最近保存的TensorFlow模型 16 def load_model(sess,dir,modelname): 17 #从给定的目录中获取检查点状态 18 ckpt=tf.train.get_checkpoint_state(dir) 19 if ckpt and ckpt.model_checkpoint_path: 20 print("*"*30) 21 print("load lastest model......") 22 saver.restore(sess,dir+".\\"+modelname) 23 print("*"*30) 24 #将当前模型保存到给定的目录 25 def save_model(sess,dir,modelname): 26 saver.save(sess,dir+modelname) 27 #saver.save(sess,"C:/Users/instant_s/Desktop/python/车牌识别/model/model.ckpt") 28 #要加载的目录 29 dir = r"C:/Users/instant_s/Desktop/python/车牌识别/model/%s/"%aspect 30 #保存模型的名称 31 modelname = aspect
5.模型训练
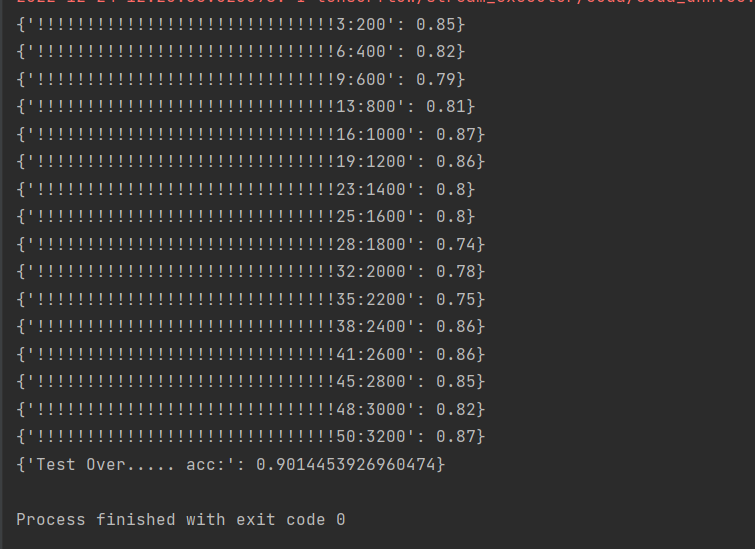
训练模型达到最大的准确值,训练之后的模型保存下来
1 #创建了一个 TensorFlow 会话 2 with tf.compat.v1.Session() as sess: 3 sess.run(tf.compat.v1.initialize_all_variables()) 4 step = 1 #用于保存训练步数。 5 display_interval=200 #用于保存输出信息的间隔。 6 max_epoch = 50 #用于保存最大训练轮数。 7 epoch = 1 #用于保存当前训练轮数。 8 acc = 0 #用于保存训练准确率。 9 load_model(sess,dir=dir,modelname=modelname) 10 11 while True : 12 #检查当前步数是否是 display_interval 的倍数 13 if step % display_interval ==0: 14 #获取验证集批次数据 15 image_batch,label_batch,epoch = data_gen.next_valid_batch(batch_size) 16 #使用 sess.run 函数计算准确率。然后使用 print 函数输出准确率。 17 acc = sess.run(right_rate,feed_dict={input_x:image_batch,input_y:label_batch,input_learning_rate:lr}) 18 print({'!'*30+str(epoch)+":"+str(step):acc}) 19 #获取训练集批次数据 20 image_batch,label_batch,epoch = data_gen.next_train_batch(batch_size) 21 #计算损失和训练操作 22 sess.run([loss,train_op],{input_x:image_batch,input_y:label_batch,input_learning_rate:lr}) 23 #检查当前训练轮数是否大于最大训练轮数,是则退出循环 24 if(epoch> max_epoch): 25 break 26 step +=1 27 if (epoch % 20) ==0: 28 lr =lr * 0.8 29 while True : 30 #获取测试集批次数据 31 test_img,test_lab,test_epoch = data_gen.next_test_batch(batch_size) 32 #计算准确率 33 test_acc = sess.run(right_rate,feed_dict={input_x:test_img,input_y:test_lab,input_learning_rate:lr}) 34 #使用指数滑动平均的方式计算出新的准确率 35 acc = test_acc * 0.8 + acc * 0.2 36 #检查当前测试轮数是否和上一次的轮数相同,如果不同则退出循环,并输出准确率 37 if(test_epoch!=epoch): 38 print({"Test Over..... acc:":acc}) 39 break
6.使用PIL读取图片,进行处理
1 from PIL import Image 2 def img2mat(img_filename): 3 #把所有的图片都resize为20x20 4 img = Image.open(img_filename) 5 img = img.resize((20,20)) 6 mat = [[img.getpixel((x,y)) for x in range(0,img.size[0])] for y in range(0,img.size[1])] 7 return mat 8 def test(): 9 mat = img2mat("C:\\Users\\instant_s\\Desktop\\python\\车牌识别\\123.png") 10 for row in mat: 11 print(mat) 12 print(mat[0][0],len(mat),len(mat[0])) 13 14 if __name__ == '__main__': 15 test()
最后的加载图片进行预测结果,并输出准确率,由于一直出错,所以没发出来。
四、总结
在建立卷积神经网络的时候有一些小问题,在建立的时候,模型还是太浅了一些,下次应该建立多一些神经层。在训练集上的训练精度达到了0.9,已经达到了较高精度。但是由于能力不足,通过调用训练集进行预测处理仍有许多问题,比如调用tensorflow方法进行预测处理结果并不能很好的实现出来,导致预测结果并没有达到我想要的效果,所以这是一个缺少测试模块的代码。我后续会继续学习这个模块内容,然后进行完善代码。通过这次课程设计,使我更加了解了数据分析、构造模型等知识点,为以后设计相关程序奠定了基础,也让我了解许多能力上的不足。
五、全部代码
1 from dataset.map import maps as aspectMap 2 import os 3 from picReader import img2mat 4 import random 5 class data_generator: 6 #定义了一个类的初始化函数,定义了若干个变量,用于保存各种数据集的信息 7 def __init__(self,aspect='area',seperate_ratio=0.1): 8 ''' 9 :param aspect: 打开什么样的训练集,[area,letter,province] 三选一 10 :param seperate_ratio: 测试集划分比例 ,从训练集和验证集里面随机抽取seperate_ratio作为训练集 11 :return: 12 ''' 13 self.train_dir = "dataset\\train\\%s\\" %aspect 14 self.val_dir = "dataset\\val\\%s\\" % aspect 15 self.seperate_ratio = seperate_ratio 16 self.data_vector_set = [] #保存所有的图片向量 17 self.data_label_set = [] #保存所有的标签 18 self.train_set = [] #保存训练集的下标 19 self.train_batch_index = 0 20 self.train_epoch =0 21 self.valid_set = [] #保存验证集的下标 22 self.valid_batch_index = 0 23 self.test_set = [] #保存测试集的下标 24 self.test_batch_index = 0 25 self.classes = 0 #最大的classes为34,这个值会在载入train和test后有所变化 26 self.data_set_cnt = 0 27 self.load_train() 28 self.load_valid() 29 #递归遍历给定目录中的所有文件和子目录。 30 def load_train(self): 31 for rt,dirs,files in os.walk(self.train_dir): 32 self.classes = max(self.classes,len(dirs)) 33 if len(dirs)==0 : 34 #说明到了叶子目录,里面放着就是图片 35 label = int(rt.split('\\')[-1]) 36 for name in files: 37 #将当前目录的路径和文件名拼接起来,得到该文件的完整路径 38 img_filename = os.path.join(rt,name) 39 #将文件转换为矩阵 40 vec = img2mat(img_filename) 41 #将矩阵和对应的标签添加到训练数据集的向量集合和标签集合中。 42 self.data_vector_set.append(vec) 43 self.data_label_set.append(label) 44 #随机决定将该图像文件放到训练集还是测试集中 45 if random.random() < self.seperate_ratio: 46 self.test_set.append(self.data_set_cnt) 47 else: 48 self.train_set.append(self.data_set_cnt) 49 self.data_set_cnt +=1 50 def load_valid(self): 51 for rt,dirs,files in os.walk(self.val_dir): 52 self.classes = max(self.classes,len(dirs)) 53 if len(dirs)==0 : 54 #说明到了叶子目录,里面放着就是图片 55 label = int(rt.split('\\')[-1]) 56 #print(label,self.data_set_cnt) 57 for name in files: 58 img_filename = os.path.join(rt,name) 59 vec = img2mat(img_filename) 60 self.data_vector_set.append(vec) 61 self.data_label_set.append(label) 62 if random.random() < self.seperate_ratio: 63 self.test_set.append(self.data_set_cnt) 64 else: 65 self.valid_set.append(self.data_set_cnt) 66 self.data_set_cnt +=1 67 #用于获取训练集批次数据的函数,批次数据、标签和当前训练轮数返回 68 def next_train_batch(self,batch=100): 69 input_x =[] 70 input_y =[] 71 #每次循环使用 self.train_set 列表的索引来获取训练数据集的向量和标签 72 for i in range(batch): 73 input_x.append(self.data_vector_set[self.train_set[(self.train_batch_index + i)%len(self.train_set)]]) 74 y = [0] * 34 75 y[self.data_label_set[self.train_set[(self.train_batch_index +i)%len(self.train_set)]]] = 1 76 input_y.append(y) 77 self.train_batch_index +=batch 78 if self.train_batch_index > len(self.train_set) : 79 self.train_epoch +=1 80 self.train_batch_index %=len(self.train_set) 81 #返回输入数据、标签和当前训练的轮数。 82 return input_x,input_y,self.train_epoch 83 84 def next_valid_batch(self,batch=100): 85 input_x =[] 86 input_y =[] 87 for i in range(batch): 88 index = random.randint(0,len(self.valid_set)-1) 89 input_x.append(self.data_vector_set[index]) 90 y = [0] * 34 91 y[self.data_label_set[index]] = 1 92 input_y.append(y) 93 self.valid_batch_index +=batch 94 95 self.valid_batch_index %=len(self.valid_set) 96 return input_x,input_y,self.train_epoch 97 def next_test_batch(self,batch=100): 98 input_x =[] 99 input_y =[] 100 for i in range(batch): 101 input_x.append(self.data_vector_set[self.test_set[(self.test_batch_index + i)%len(self.test_set)]]) 102 y = [0] * 34 103 y[self.data_label_set[self.test_set[(self.test_batch_index +i)%(len(self.test_set))]]] = 1 104 input_y.append(y) 105 self.test_batch_index +=batch 106 if self.test_batch_index > len(self.test_set) : 107 self.train_epoch +=1 108 self.test_batch_index %=len(self.test_set) 109 return input_x,input_y,self.train_epoch 110 #将代码封装成模块,然后通过导入模块的方式使用。 111 if __name__ == '__main__': 112 data_gen = data_generator() 113 print(len(data_gen.test_set)) 114 print(data_gen.next_train_batch(100)) 115 print(data_gen.next_valid_batch(100)) 116 print(data_gen.next_test_batch(100)) 117 118 119 import tensorflow as tf 120 import cv2 121 from BaseTool import data_generator 122 batch_size = 100 # 每个batch的大小 123 lr=1e-4 # 学习速率 124 aspect = "area" 125 data_gen = data_generator(aspect)#将aspect作为参数赋值给变量 data_gen 126 #创建TensorFlow的占位符,表示将在模型训练过程中用于输入、输出的数据 127 tf.compat.v1.disable_eager_execution() 128 input_x =tf.compat.v1.placeholder(dtype=tf.float32,shape=[None,20,20],name='input_x') 129 input_y =tf.compat.v1.placeholder(dtype=tf.float32,shape=[None,34],name='input_y') 130 #创建TensorFlow的占位符,表示将在模型训练过程中用于学习率的值。 131 input_learning_rate = tf.compat.v1.placeholder(dtype=tf.float32,name='learning_rate') 132 #定义三个卷积层'conv1'、'conv2' 、'conv3',并用TensorFlow计算输出进行非线性变换。 133 #定义二个池化层'pooling2' 、 'pooling3',执行最大值池化操作。 134 with tf.name_scope('conv1'): 135 #卷积层的权重矩阵 136 W_C1 = tf.Variable(tf.compat.v1.truncated_normal(shape=[3,3,1,32],stddev=0.1)) 137 #卷积层的偏置向量 138 b_C1 = tf.Variable(tf.constant(0.1, tf.float32, shape=[32])) 139 #将 input_x 转换为四维矩阵 X 140 X=tf.reshape(input_x,[-1,20,20,1]) 141 #使用 tf.nn.conv2d 函数计算卷积层的输出,步长为[1,1,1,1],并使用 "SAME" 142 featureMap_C1 = tf.nn.relu(tf.nn.conv2d(X,W_C1,strides=[1,1,1,1],padding='SAME') + b_C1 ) 143 with tf.name_scope('conv2'): 144 W_C2 = tf.Variable(tf.compat.v1.truncated_normal(shape=[3, 3, 32, 64], stddev=0.1)) 145 b_C2 = tf.Variable(tf.constant(0.1, tf.float32, shape=[64])) 146 featureMap_C2 = tf.nn.relu(tf.nn.conv2d(featureMap_C1, W_C2, strides=[1, 1, 1, 1], padding='SAME') + b_C2) 147 148 with tf.name_scope('pooling2'): 149 #ksize参数指定了池化窗口的大小为[1,2,2,1],strides 参数指定了池化窗口的滑动步长为[1,2,2,1],padding参数设置为'VALID'表示不使用边缘填充 150 featureMap_S2 = tf.nn.max_pool(featureMap_C2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='VALID') 151 152 with tf.name_scope('conv3'): 153 W_C3 = tf.Variable(tf.compat.v1.truncated_normal(shape=[3, 3, 64, 8], stddev=0.1)) 154 b_C3 = tf.Variable(tf.constant(0.1, shape=[8], dtype=tf.float32)) 155 featureMap_C3 = tf.nn.relu(tf.nn.conv2d(featureMap_S2, filters=W_C3, strides=[1, 1, 1, 1], padding='SAME') + b_C3) 156 157 with tf.name_scope('pooling3'): 158 featureMap_S3 = tf.nn.max_pool(featureMap_C3,[1,2,2,1],[1,2,2,1],padding='VALID') 159 160 #定义了全连接层'fulnet' 161 with tf.name_scope('fulnet'): 162 #将featureMap_S3 转换为一个二维的矩阵 163 featureMap_flatten = tf.reshape(featureMap_S3, [-1, 5 * 5 * 8]) 164 # 定义全连接层的权重矩阵和偏置向量 165 W_F4 = tf.Variable(tf.compat.v1.truncated_normal(shape=[5 * 5 * 8, 512], stddev=0.1)) 166 b_F4 = tf.Variable(tf.constant(0.1, shape=[512], dtype=tf.float32)) 167 # 使用matmul 计算矩阵乘法,将结果加上偏置向量 b_F4,并对结果进行非线性变换 168 out_F4 = tf.nn.relu(tf.matmul(featureMap_flatten,W_F4) + b_F4) 169 #使用dropout 操作随机将一部分输出置为0,减少过拟合的风险 170 out_F4 =tf.nn.dropout(out_F4,rate=0.5) 171 #定义输出层'output' 172 with tf.name_scope('output'): 173 #定义输出层的权重矩阵和偏置向量 174 W_OUTPUT = tf.Variable(tf.compat.v1.truncated_normal(shape=[512, 34], stddev=0.1))#权重矩阵有 512 行和 34 列 175 b_OUTPUT = tf.Variable(tf.constant(0.1,shape=[34],dtype=tf.float32))#输出层有 34 个输出 176 #使用matmul函数计算矩阵乘法,将输入out_F4与权重矩阵W_OUTPUT相乘,并将结果加上偏置向量b_OUTPUT。logits 就是模型的预测结果。 177 logits = tf.matmul(out_F4, W_OUTPUT) + b_OUTPUT 178 #输入了标签和输入数据的 logit(即网络的输出),并计算了两者之间的交叉熵损失 179 loss = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(labels=input_y,logits=logits)) 180 #创建了一个 Adam 优化器,并使用优化器的 minimize 方法最小化交叉熵损失 181 train_op = tf.compat.v1.train.AdamOptimizer(learning_rate=input_learning_rate).minimize(loss) 182 #将模型的输出转换为概率分布 183 predictY = tf.nn.softmax(logits) 184 #从概率分布中选取最大概率对应的类别 185 y_pred=tf.compat.v1.arg_max(predictY,1) 186 #比较标签和预测的类别是否相同 187 bool_pred=tf.equal(tf.compat.v1.arg_max(input_y,1),y_pred) 188 #计算正确率 189 right_rate=tf.reduce_mean(tf.compat.v1.to_float(bool_pred)) 190 saver = tf.compat.v1.train.Saver() 191 192 #从给定的目录加载最近保存的TensorFlow模型 193 def load_model(sess,dir,modelname): 194 #从给定的目录中获取检查点状态 195 ckpt=tf.train.get_checkpoint_state(dir) 196 if ckpt and ckpt.model_checkpoint_path: 197 print("*"*30) 198 print("load lastest model......") 199 saver.restore(sess,dir+".\\"+modelname) 200 print("*"*30) 201 #将当前模型保存到给定的目录 202 def save_model(sess,dir,modelname): 203 saver.save(sess,dir+modelname) 204 #saver.save(sess,"C:/Users/instant_s/Desktop/python/车牌识别/model/model.ckpt") 205 #要加载的目录 206 dir = r"C:/Users/instant_s/Desktop/python/车牌识别/model/%s/"%aspect 207 #保存模型的名称 208 modelname = aspect 209 210 #创建了一个 TensorFlow 会话 211 with tf.compat.v1.Session() as sess: 212 sess.run(tf.compat.v1.initialize_all_variables()) 213 step = 1 #用于保存训练步数。 214 display_interval=200 #用于保存输出信息的间隔。 215 max_epoch = 50 #用于保存最大训练轮数。 216 epoch = 1 #用于保存当前训练轮数。 217 acc = 0 #用于保存训练准确率。 218 load_model(sess,dir=dir,modelname=modelname) 219 while True : 220 #检查当前步数是否是 display_interval 的倍数 221 if step % display_interval ==0: 222 #获取验证集批次数据 223 image_batch,label_batch,epoch = data_gen.next_valid_batch(batch_size) 224 #使用 sess.run 函数计算准确率。然后使用 print 函数输出准确率。 225 acc = sess.run(right_rate,feed_dict={input_x:image_batch,input_y:label_batch,input_learning_rate:lr}) 226 print({'!'*30+str(epoch)+":"+str(step):acc}) 227 #获取训练集批次数据 228 image_batch,label_batch,epoch = data_gen.next_train_batch(batch_size) 229 #计算损失和训练操作 230 sess.run([loss,train_op],{input_x:image_batch,input_y:label_batch,input_learning_rate:lr}) 231 #检查当前训练轮数是否大于最大训练轮数,是则退出循环 232 if(epoch> max_epoch): 233 break 234 step +=1 235 if (epoch % 20) ==0: 236 lr =lr * 0.8 237 while True : 238 #获取测试集批次数据 239 test_img,test_lab,test_epoch = data_gen.next_test_batch(batch_size) 240 #计算准确率 241 test_acc = sess.run(right_rate,feed_dict={input_x:test_img,input_y:test_lab,input_learning_rate:lr}) 242 #使用指数滑动平均的方式计算出新的准确率 243 acc = test_acc * 0.8 + acc * 0.2 244 #检查当前测试轮数是否和上一次的轮数相同,如果不同则退出循环,并输出准确率 245 if(test_epoch!=epoch): 246 print({"Test Over..... acc:":acc}) 247 break 248 249 save_model(sess,dir,modelname) 250 251 from PIL import Image 252 def img2mat(img_filename): 253 #把所有的图片都resize为20x20 254 img = Image.open(img_filename) 255 img = img.resize((20,20)) 256 mat = [[img.getpixel((x,y)) for x in range(0,img.size[0])] for y in range(0,img.size[1])] 257 return mat 258 def test(): 259 mat = img2mat("C:\\Users\\instant_s\\Desktop\\python\\车牌识别\\dataset\\test\\1.bmp") 260 for row in mat: 261 print(mat) 262 print(mat[0][0],len(mat),len(mat[0])) 263 264 265 if __name__ == '__main__': 266 test()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号