普元云计算-一起来DIY一个人工智能实验室吧

转载本文需注明出处:微信公众号EAWorld,违者必究。
目录:
一、DIY一个AI实验室:原材料的选择
二、搭建“单机版”的AI实验室
三、搭建“高阶版”的AI实验室
一、DIY一个AI实验室:原材料的选择
我们的AI入门课程已经讲过两篇了,前面我们讲了AI的概念、算法、工具等内容,第三篇我们会介绍一些实际操作的内容。俗话说,工欲善其事,必先利其器,本文我们将告诉大家如何搭建一个AI实验室,并穿插一些小Demo,为后面的AI学习实践做好准备。

现在可供选择的AI开发框架很多,推荐大家从Tensorflow开始上手,原因后面会说。另外,在“高阶版”的AI实验室中,我们使用了Kubernetes + Docker做分布式训练的运行环境,所以推荐各位同学使用64位的Ubuntu 16.04或更高版本的操作系统。如果只是想玩玩“单机版”,那也可以使用Windows和Mac,操作过程和Ubuntu差别不大。
AI实践肯定要写程序,各位同学肯定都有自己喜欢的IDE或者编辑器,但是编写AI程序,和编写其他程序有个很大的区别,那就是这些程序都需要实时的输出一些图表以供调试或者查看运行结果,我们之前用的大多数开发工具都没有这个能力,所以现在大家都用Jupyter Notebook来做AI程序、尤其是机器学习程序的开发。
综上,我们将使用Tensorflow、Kubernetes和Jupyter Notebook做AI实验室的“原材料”,下面我们分别说下选型依据。
1. 为什么使用Tensorflow做开发框架:

2. 为什么使用Kubernetes做AI实验室的基础运行环境:

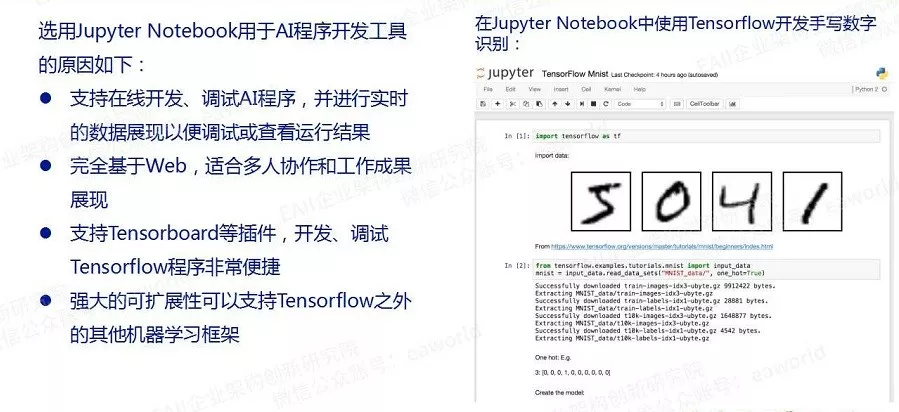
3. 为什么使用Jupyter Notebook做开发工具:
二、搭建“单机版”的AI实验室
搭建“单机版”的AI实验室非常简单,只要三步即可:
-
安装Python和Virtualenv,这里我们使用Python3:
sudo apt-get install python3-pip python3-dev python-virtualenv -
创建并激活Virtualenv环境(工作目录名为AILab,也可以换个自己喜欢的名字):
virtualenv --system-site-packages -p python3 AILab
source AILab/bin/activate -
安装Tensorflow和Jupyter Notebook,以及用来调试Tensorflow程序的Tensorboard插件:
pip3 install tensorflow
pip3 install jupyter
pip3 install jupyter-tensorboard

这里我们使用了Virtualenv,以免搞乱洁癖码农的Python环境。上述步骤完成后,在Virtualenv的提示符下执行:
(AILab)$ jupyter notebook
即可启动Jupyter Notebook
如果有同学需要使用GPU,那么还需要安装NVIDIA的CUDA工具包、cuDNN和分析工具接口,会比较麻烦。
有需要的同学可以参考链接:
https://www.tensorflow.org/install
需要在Mac和Windows上安装Tensorflow或者安装过程中遇到疑难杂症的同学也可以查询该链接。关于Jupyter Notebook和Tensorboard插件的问题。
可以查询链接:
http://jupyter.readthedocs.io/en/latest/install.html
https://github.com/lspvic/jupyter_tensorboard
现在打开jupyter notebook命令输出中的链接,就可以浏览器里编写Tensorflow程序了。为了尽快上手,我们先跳过Tensorflow的基础概念,直接运行一个来自 https://github.com/sankit1/cv-tricks.com 的小Demo。
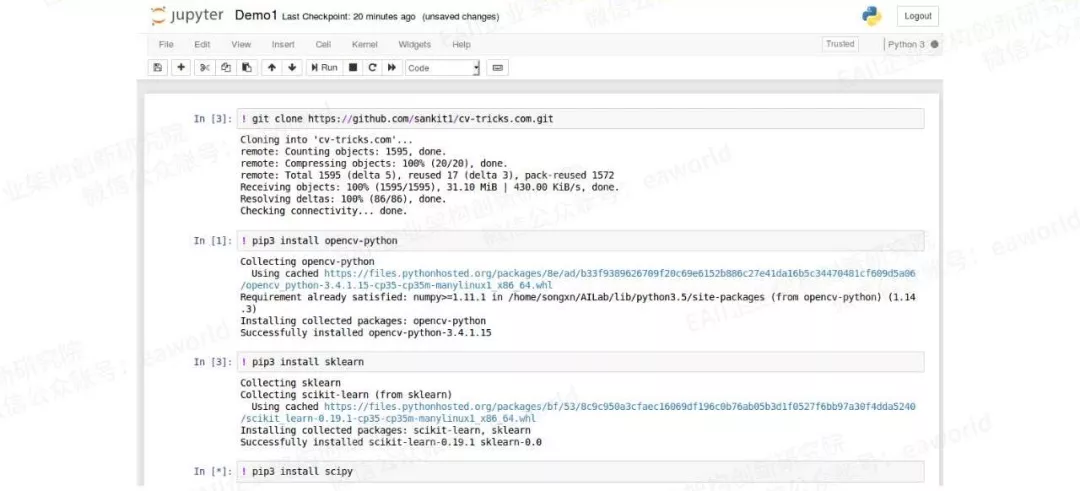
首先我们点击Jupyter Notebook Files标签页右上角的New按钮创建一个Python 3 记事本。Jupyter Notebook支持以“!”开头运行本地命令,写好命令,选中灰色的编辑框(Jupyter Notebook称其为Cell),点击工具栏的Run按钮即可执行。我们首先取出cv-tricks的代码,再安装opencv、sklearn、scipy等三个数学工具包。
然后我们再回到Files标签页,打开路径为cv-tricks.com/Tensorflow-tutorials/tutorial-2-image-classifier/train.py的Python文件。
由于这种打开方式是不能运行代码的,所以我们再创建一个Python 3记事本,把train.py的文件内容复制过来,然后执行。
相信此时一定有好学的同学到cv-tricks的GitHub里去看了,可能有人会发现里面有training_data和testing_data两个目录,里面有很多猫猫狗狗的照片,实际上train.py在做的事情就是创建一个卷积神经网络,然后读入training_data目录下的猫狗照片进行如何区分猫狗的训练。
通过程序的输出我们可以看到识别的准确度从最开始的50%逐步上升、直至收敛。50%的准确度即为瞎猜,这个输出很直观的展现了机器学习的过程。
这个程序需要跑上一段时间,根据机器的性能不同和室内温度,半小时到一小时都有可能,同学们在自己进行实验的时候请耐心等待。另外,GitHub上的代码有个小bug,这里故意不说,相信细心的同学都能知道如何修改。
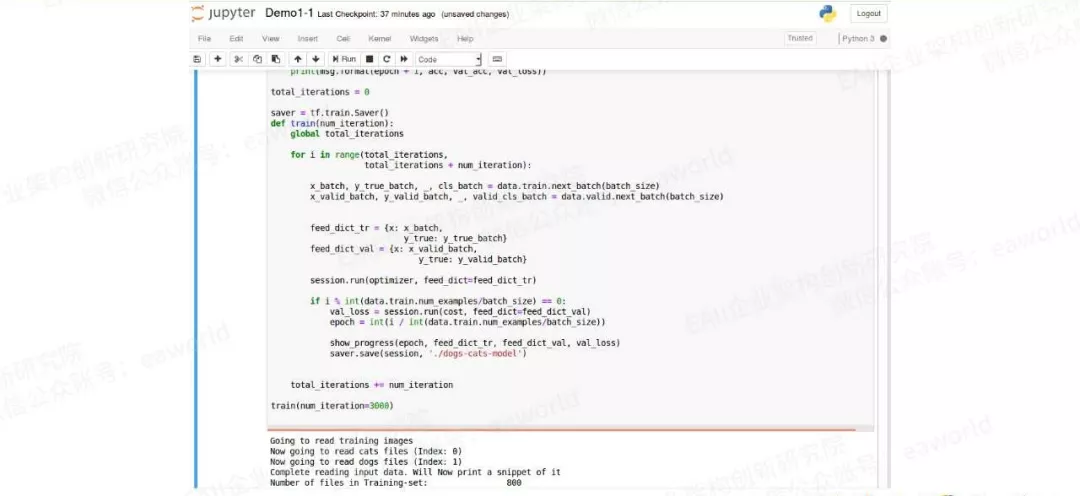
程序运行过程中会生成几个文件,就是Tensorflow的模型文件,里面存储的就是训练好的神经网络,后面就用这些文件去区分猫狗。
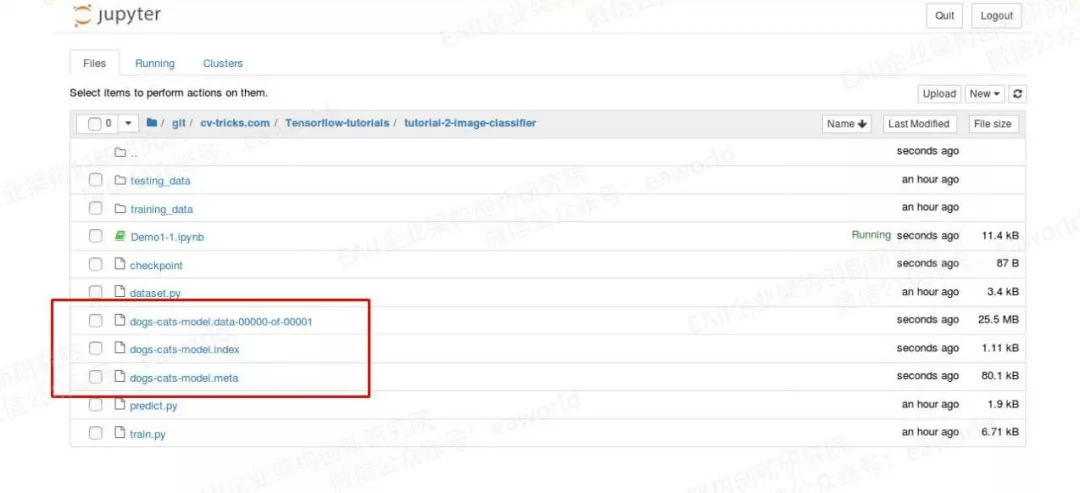
等训练结束之后,我们可以用predict.py加载这个模型,用它识别一些网上找来的猫狗图片。
识别效果还算可以,如果有同学在自己的测试里发现识别出错,那也很正常,毕竟这只是一个很简单的Demo,训练数据很少,训练时间也很短,准确率做不到太高。
现在我们的第一个AI程序就跑起来了,“单机版”的AI实验室建设完毕。
三、搭建“高阶版”的AI实验室
接下来才是本文的重头戏——AI实验室的“高阶版”。
正如前文所述,AI实验室的“高阶版”是一个分布式训练环境,一来可以进行多机并行训练以提高训练速度,二来可以通过多租户方式集约化的使用资源,适合学校、企业中的小团队一起使用。
“高阶版”的AI实验室底层使用了Kubernetes和Docker,我们公众号的老朋友应该对这两个东西都比较了解,如果有同学不了解那也没关系,暂且把它们当作一个支撑Tensorflow分布训练的资源调度器就好。整体架构见下图:
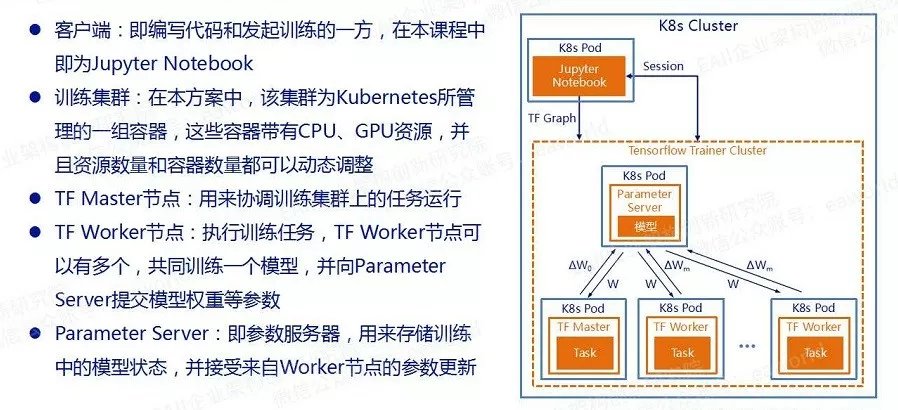
说到这里,我们需要介绍一下和Tensorflow分布式训练有关的一些概念,首先是两种训练方式——数据并行和模型并行:
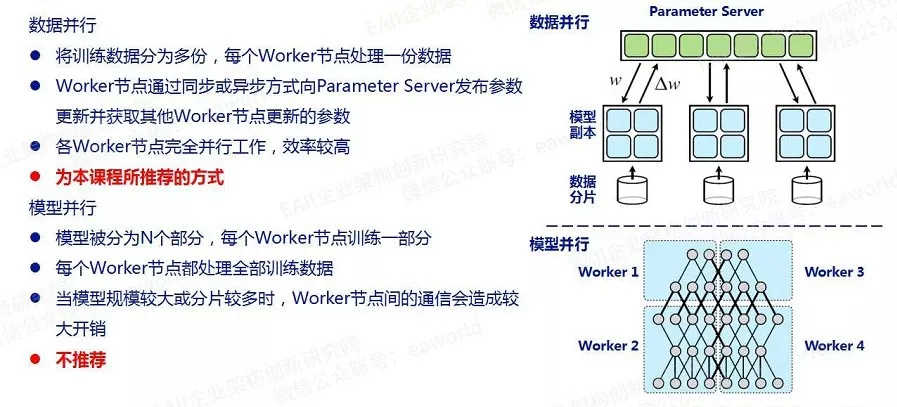
其次数据并行又分为同步数据并行和异步数据并行:
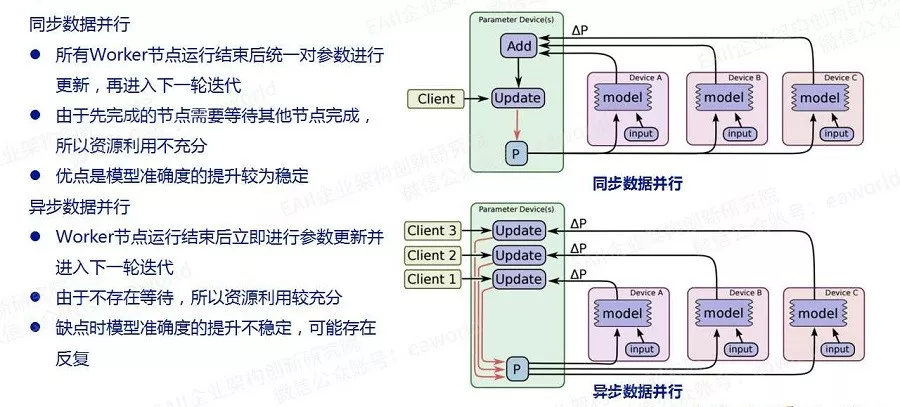
现阶段我们推荐使用同步数据并行方式,所以各位同学暂且对其他三个概念有些印象即可,以后碰到的时候再深入研究也不迟。
接下来介绍搭建“高阶版”AI实验室的步骤,要比“单机版”复杂不少。首先需要准备几台服务器,并在各服务器上安装64位的Ubuntu 16.04或更高版本。
如果只有一台服务器那也没关系,本课程介绍的方法有一个很大的优势就是可扩展性,可以先一台服务器凑合用,等以后富裕了、服务器多了,再添加进来也很容易。但是安装后一定要注意以下三点:
-
各服务器的Hostname、MAC地址和product_uuid(/sys/class/dmi/id/product_uuid)要唯一。
-
各服务都要关闭Swap,方法是在/etc/fstab中将Swap行注释掉。
-
各服务器都要关闭防火墙,方法是执行ufw disable命令。
然后各服务器重启,使上述修改生效。
准备工作完成后即可开始安装Docker和Kubernetes的集群部署工具Kubeadm,每台服务器上都要装,分为三步:
1. 添加来自Google的安装源:
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
2. 刷新安装源并安装必要工具:
apt-get update
apt-get install -y apt-transport-https curl
3. 安装Docker和Kubeadm:
apt-get install -y docker.io kubeadm kubelet kubectl
接下来是初始化管理节点,选一台你最喜欢的服务器完成以下步骤,如果你只有一台服务器,那这台就既做管理节点也做工作节点。
1. 执行命令kubeadm init --pod-network-cidr=10.244.0.0/16,该命令的执行过程中会下载几个Docker镜像,时间可能会比较久,等看到“Your Kubernetes master has initialized successfully!”输出后,就说明命令执行成功。执行过程中可能会遇到“你懂的”问题,哎,没办法,做IT就是这样举步维艰,我们后面看看能不能在国内做个镜像库,为各位同学提供便利。
2. 步骤1完成后,如果你使用的是非root用户,那么需要执行以下三行命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果你使用的是root用户,则需要设置环境变量:
export KUBECONFIG=/etc/kubernetes/admin.conf
为了日后方便,可以将该环境变量添加到shell的profile中。
3. 接下来安装Kubernetes的网络虚拟化add-on,这里我们使用的是Flannel,安装方法是:
a) 首先修改一个网络参数,执行命令sysctl net.bridge.bridge-nf-call-iptables=1,并将其添加到/etc/sysctl.conf文件中。
b) 安装Kubernetes的网络虚拟化add-on,执行命令:
kubectl apply -f \
https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml
过程中还是会遇到“你懂的”问题……
上述步骤完成之后,管理节点就初始化成功了,如果有同学觉得单独用一台服务器做管理节点有点浪费,或者是有同学只有一台服务器,既要做管理节点又要做工作节点,那么请执行命令:kubectl taint nodes --all node-role.kubernetes.io/master-。
接下来要做的就是添加工作节点了,刚才执行kubeadm init命令的时候输出里有一行内容类似于:
kubeadm join --token <token> <master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>
把这行复制到其他服务器上用root用户执行,即可将这台服务器作为工作节点添加到集群之中,只有一台服务器的同学可以等富裕了之后再执行。
到此一个Kubernetes集群就完成了,如果有同学在操作过程中遇到疑难杂症。
请查询链接:
https://kubernetes.io/docs/tasks/tools/install-kubeadm/
https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/
接下来要做的就是安装Kubeflow了,还记得这个是什么吗?前文提过,Kubeflow就是Google提供的整合Kubernetes和Tensorflow的一站式AI开源方案。由于Kubeflow使用了ksonnet作为部署工具,所以我们首先要到https://ksonnet.io/#get-started下载ksonnet的命令行工具。这里顺便提一句,ksonnet是个非常强大的工具,也比较复杂,感兴趣的同学可以查看他们的官网探明究竟,这里我们就不展开讲解了。
现在我们开始配置kubeflow,步骤比较多。
-
初始化工作目录,目录名为AILab_Advanced,执行命令:
ks init AILab_Advanced
-
创建配置文件模板,需要以下步骤:
-
切换工作目录,执行命令:cd AILab_Advanced
-
下载基本配置文件,执行以下命令:
VERSION=v0.1.2
ks registry add kubeflow \
github.com/kubeflow/kubeflow/tree/${VERSION}/kubeflow
ks pkg install kubeflow/core@${VERSION}
ks pkg install kubeflow/tf-serving@${VERSION}
ks pkg install kubeflow/tf-job@${VERSION}
这里我们使用的是0.1.2版本,过段时间会发布0.2版本,各位同学可以根据需要修改VERSION变量的值。 -
创建配置文件模板,执行命令:
ks generate core kubeflow-core --name=kubeflow-core
-
创建Kubeflow基础服务,需要的步骤:
-
创建名为AILab的运行环境,执行命令:
ks env add AILab
-
创建名为AILab的租户,执行命令:
kubectl create namespace AILab
-
创建kubeflow基础服务,执行以下命令:
ks env set AILab --namespace AILab
ks apply AILab -c kubeflow-core
创建过程中依然需要下载几个Docker镜像,各位同学在操作过程中请耐心等待。
上述步骤执行完毕后,AI实验室的”高阶版”就基本完工了,可以通过浏览器使用,访问前需要映射一下端口,执行下面两条命令:
PODNAME=`kubectl get pods --namespace=AILab --selector="app=tf-hub" \
--output=template --template="{{with index .items 0}}{{.metadata.name}}{{end}}"`
kubectl port-forward --namespace=AILab $PODNAME 8000:8000
然后就可以通过8000端口访问了,首页如下图:
因为这里没有启用安全模式,所以用户名和密码可以随便填。AI实验室的“高阶版”是支持多用户的,会为不同的用户名启动独立的实验环境,登录后的效果如下图:
点击Start My Server按钮即可启动自己的Jupyter Notebook:
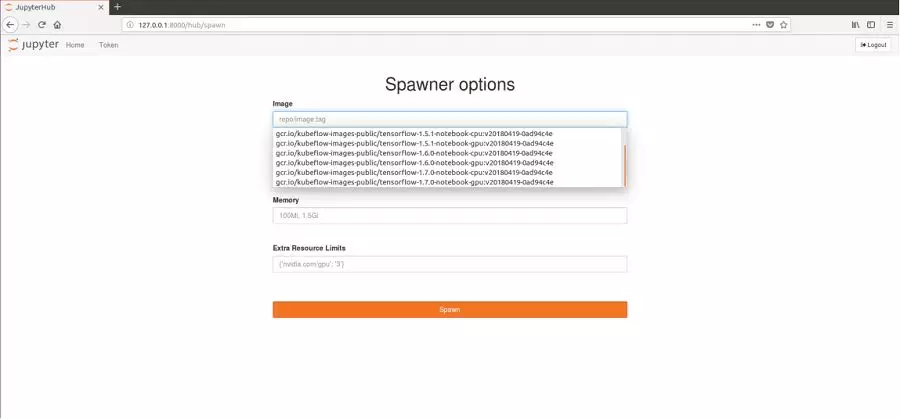
这里可以选择你喜欢的Tensorflow版本,并填写所需的资源参数。这些镜像都比较大,下载的时间会比较久。
由于首次启动需要下载镜像,如果网络环境不好,这一步很可能会超时失败,但是后台的镜像下载不会中断,等下载完成,再去启动Jupyter Notebook就很快了。此时会出现我们熟悉的Jupyter Notebook首页:
现在我们就可以像在“单机版”里那样编写代码了。每个Jupyter Notebook都运行在一个独立的Docker容器中,用户之间不会互相干扰,还可以通过New按钮创建一个Terminal,登陆到容器内部操作。
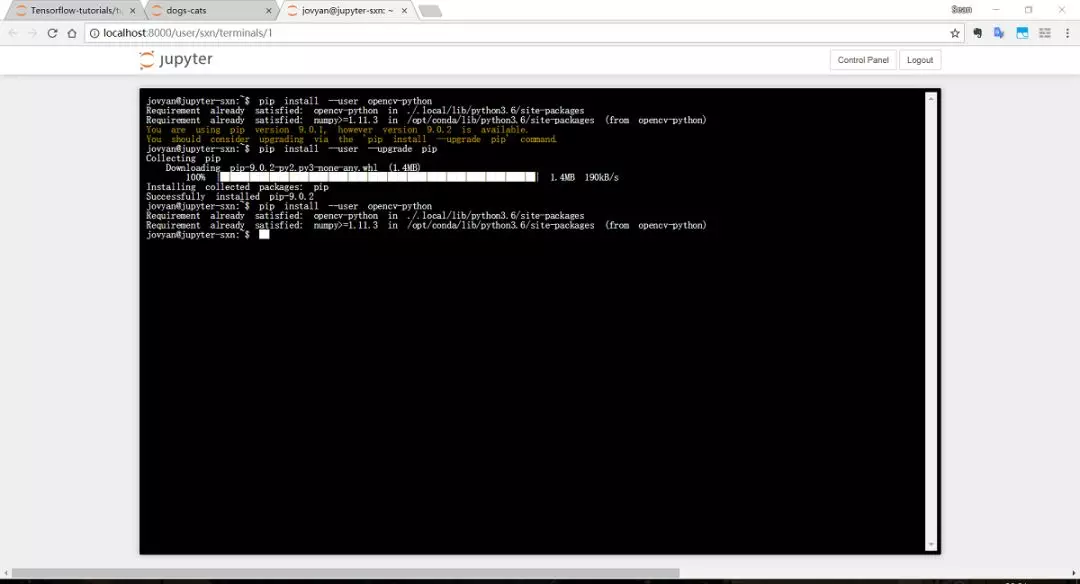
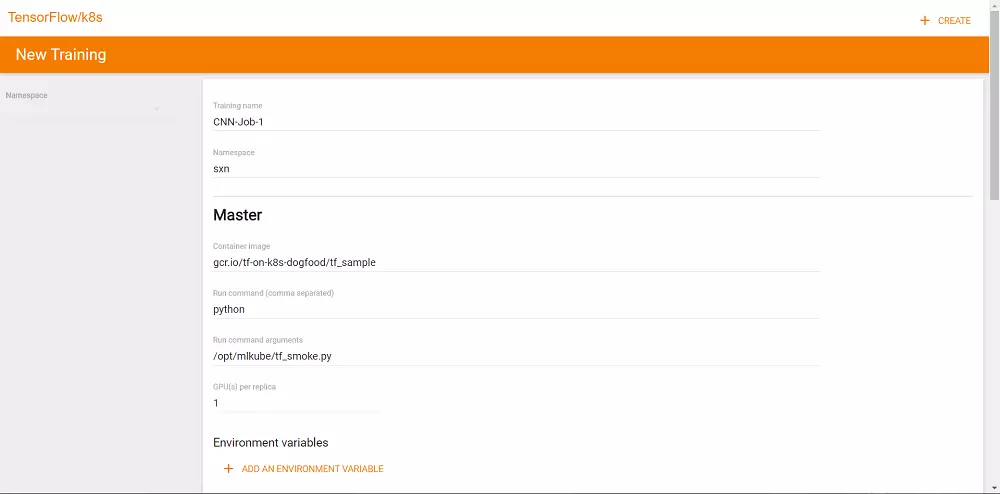
前面稍微展示了一下如何使用这个“多租户”的Jupyter Notebook,接下来开始介绍如何发起Tensorflow的分布式训练。Kubeflow提供了一个分布式训练的发起页面,在该页面填写训练名称、镜像地址、入口程序、所需资源和节点数等参数即可发起训练,如下图所示:
发起训练之后还可以通过Web页面查看运行状态,在这个页面中可以看到kubeflow通过镜像创建了一系列的容器,每个容器即为训练集群的一个节点。
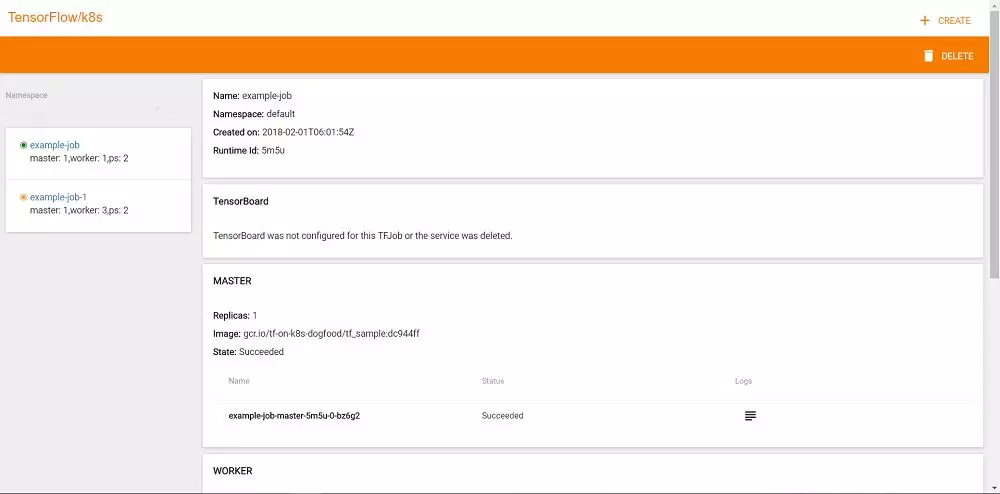
这里使用了一个Google提供的测试镜像,我们也可以自己制作镜像,只需要在“多租户”的Jupyter Notebook里把程序调试好,然后把该Jupyter Notebook所在的容器保存成一个Docker镜像即可。
另外需要注意的是,在编写Tensorflow程序的时候,也需要为分布式环境做一些适配。Tensorflow使用一个名为tf.train.ClusterSpec的constructor描述训练集群结构,由于在“高阶版”的AI实验室中,集群结构是在发起分布式训练的时候动态设置的,所以就不能像以前那也写死在代码里,需要对代码做一些修改,如下图所示:

这里的关键是名为TF_CONFIG的环境变量,kubeflow里有个有个名为tf-operator的组件,可以把它当成一个Tensorflow和Kubernetes之间的适配器,它的作用之一就是在发起分布式训练时将集群结构写到TF_CONFIG这个环境变量里,训练集群的每个节点里都会写,然后就可以在程序中通过读取这个变量来动态配置集群结构了。
各位同学可以参考链接:
https://github.com/kubeflow/tf-operator/blob/master/examples/tf_sample/tf_sample/tf_smoke.py
中的实例代码,试着把前面“单机版”的猫狗识别程序改成分布式,成功后一定会很有成就感。
到此“高阶版”的AI实验室就介绍完毕了,一定有同学会觉得这个实验室比较简陋。确实如此,一来是kubeflow还处于非常早期的开发阶段,二来是一个完善的AI实验室还需要在kubeflow之上做很多产品化工作。
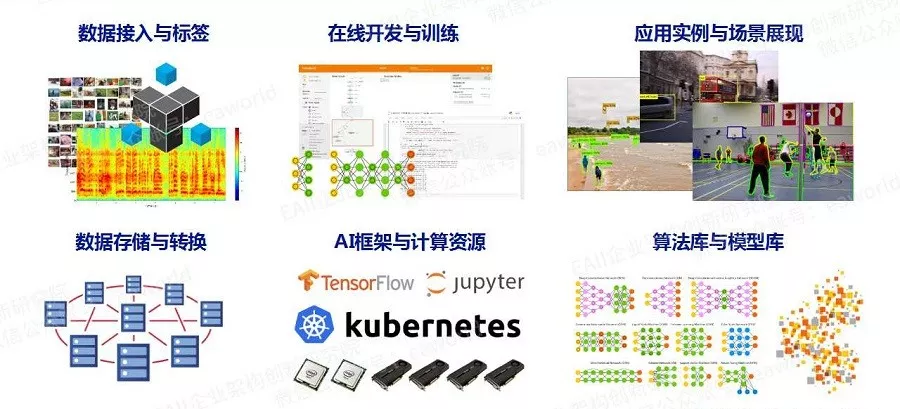
我司目前也在做这方面的工作,计划把AI实验室和我司的云平台产品整合起来,形成一个AI实验室云服务,总体架构如下图所示:
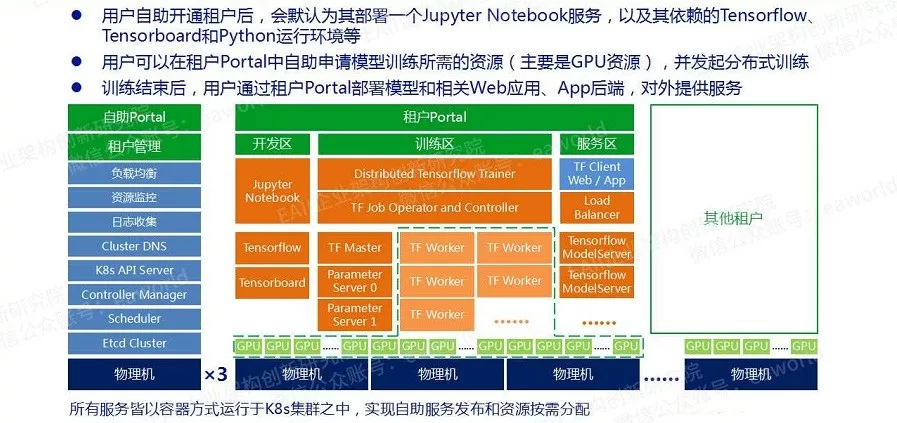
并在此之上构建AI生态:
 关于作者:宋潇男,现任普元云计算架构师,曾在华为负责云计算产品与解决方案的规划和管理工作。曾负责国家电网第一代云资源管理平台以及中国银联基于OpenStack的金融云的技术方案、架构设计和技术原型工作。
关于作者:宋潇男,现任普元云计算架构师,曾在华为负责云计算产品与解决方案的规划和管理工作。曾负责国家电网第一代云资源管理平台以及中国银联基于OpenStack的金融云的技术方案、架构设计和技术原型工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号