

使用PG的部分索引
PG 又带来一个惊喜。
现在有一张表,每天增加几十万数据,数据量迅速超过 1亿。此时 create_at 上的索引已经非常庞大,检索速度很慢。
接下来要分表分区了?
NO,PG 有一个非常有意思的特性,部分索引。
https://dba.stackexchange.com/questions/81456/slow-index-scans-in-large-table
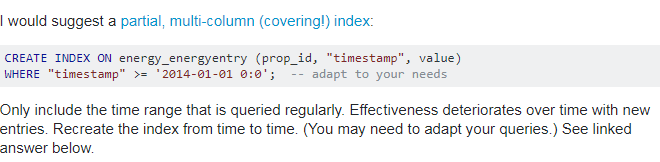
这样,每个月都搞一个索引,索引数据的规模大大缩小,查询速度当然也就暴增了。
PG 的表分区做的不太好,没有 mysql 方便。
https://www.postgresql.org/docs/10/static/ddl-partitioning.html
需要自己搞一个 pg_partman 插件,要想很爽可能要用 Greenplum。
PG10 已经支持 native partioning: https://www.dbrnd.com/2017/12/postgresql-10-introduced-native-table-partitioning/
唯文档没有更新

