
Pandas高频使用技巧
import pandas as pd import numpy as np
导入文件
1.read_excel
Pandas能够读取很多文件:Excel、CSV、数据库、TXT,甚至是在线的文件都是OK的

to_csv
-
DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode='w', encoding=None) - path_or_buf :文件路径
- sep :分隔符,默认用","隔开
- columns :选择需要的列索引
- header :boolean or list of string, default True,是否写进列索引值
- index:是否写进行索引
- mode:‘w’:重写, ‘a’ 追加
举例:保存读取出来的股票数据
保存’open’列的数据,然后读取查看结果:
# 选取10行数据保存,便于观察数据 data[:10].to_csv("./data/test.csv", columns=['open']) # 读取,查看结果 pd.read_csv("./data/test.csv") Unnamed: 0 open 0 2018-02-27 23.53 1 2018-02-26 22.80 2 2018-02-23 22.88 3 2018-02-22 22.25 4 2018-02-14 21.49 5 2018-02-13 21.40 6 2018-02-12 20.70 7 2018-02-09 21.20 8 2018-02-08 21.79 9 2018-02-07 22.69会发现将索引存入到文件当中,变成单独的一列数据。如果需要删除,可以指定index参数,删除原来的文件,重新保存一次。
下面例子把index指定为False,那么保存的时候就不会保存行索引了:
# index:存储不会将索引值变成一列数据 data[:10].to_csv("./data/test.csv", columns=['open'], index=False)
当然我们也可以这么做,就是把索引保存到文件中,读取的时候变成了一列,那么可以把这个列再变成索引,如下:
# 把Unnamed: 0这一列,变成行索引 open.set_index(["Unnamed: 0"]) # 把索引名字变成index open.index.name = "index"
read_json
-
pandas.read_json(path_or_buf=None, orient=None, typ='frame', lines=False) - 按照每行读取json对象
- (1)‘split’ : dict like {index -> [index], columns -> [columns], data -> [values]}
- (2)‘records’ : list like [{column -> value}, … , {column -> value}]
- (3)‘index’ : dict like {index -> {column -> value}}
- (4)‘columns’ : dict like {column -> {index -> value}},默认该格式
- (5)‘values’ : just the values array
- split 将索引总结到索引,列名到列名,数据到数据。将三部分都分开了
- records 以columns:values的形式输出
- index 以index:{columns:values}…的形式输出
- colums 以columns:{index:values}的形式输出
- values 直接输出值
path_or_buf: 路径orient: string,以什么样的格式显示.下面是5种格式:lines: boolean, default Falsetyp: default ‘frame’, 指定转换成的对象类型series或者dataframe
案例:
- 数据介绍:
这里使用一个新闻标题讽刺数据集,格式为json。is_sarcastic:1讽刺的,否则为0;headline:新闻报道的标题;article_link:链接到原始新闻文章。存储格式为:
{"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5", "headline": "former versace store clerk sues over secret 'black code' for minority shoppers", "is_sarcastic": 0}
{"article_link": "https://www.huffingtonpost.com/entry/roseanne-revival-review_us_5ab3a497e4b054d118e04365", "headline": "the 'roseanne' revival catches up to our thorny political mood, for better and worse", "is_sarcastic": 0}
- 读取
orient指定存储的json格式,lines指定按照行去变成一个样本:
json_read = pd.read_json("./data/Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
结果为:

创建DataFrame
在以前的文章中介绍过10种DataFrame的方法

Series的创建
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。

# 导入pandas import pandas as pd pd.Series(data=None, index=None, dtype=None)
- 参数:
- data:传入的数据,可以是ndarray、list等
- index:索引,必须是唯一的,且与数据的长度相等。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
- dtype:数据的类型
通过已有数据创建:
-
(1)指定内容,默认索引:
pd.Series(np.arange(10))

# 运行结果 0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 dtype: int64
(2)指定索引:
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
# 运行结果 1 6.7 2 5.6 3 3.0 4 10.0 5 2.0 dtype: float64
(3)通过字典数据创建
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
color_count
# 运行结果 blue 200 green 500 red 100 yellow 1000 dtype: int64
(2)Series的属性
为了更方便地操作Series对象中的索引和数据,Series中提供了两个属性index和values:
index:
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
color_count.index
# 结果
Index(['blue', 'green', 'red', 'yellow'], dtype='object')
values:
color_count.values # 结果 array([ 200, 500, 100, 1000])
也可以使用索引来获取数据:
color_count[2] # 结果 100
MultiIndex
(1)MultiIndex
MultiIndex是三维的数据结构;
多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
- (1)multiIndex的特性
打印刚才的df的行索引结果
df sale year month 2012 1 55 2014 4 40 2013 7 84 2014 10 31 df.index MultiIndex(levels=[[2012, 2013, 2014], [1, 4, 7, 10]], labels=[[0, 2, 1, 2], [0, 1, 2, 3]], names=['year', 'month'])
多级或分层索引对象。
- index属性
- names:levels的名称
- levels:每个level的元组值
df.index.names # FrozenList(['year', 'month']) df.index.levels # FrozenList([[2012, 2013, 2014], [1, 4, 7, 10]])
(2)multiIndex的创建
arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']] pd.MultiIndex.from_arrays(arrays, names=('number', 'color')) # 结果 MultiIndex(levels=[[1, 2], ['blue', 'red']], codes=[[0, 0, 1, 1], [1, 0, 1, 0]], names=['number', 'color'])
T 转置
data.T

删除列
删除一些列,让数据更简单些,再去做后面的操作 data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
赋值操作
对DataFrame当中的close列进行重新赋值为1。
# 直接修改原来的值 data['close'] = 1 # 这一列都变成1 # 或者 data.close = 1
查看头尾数据
头尾都是默认5行数据,可以指定行数
# df2.head() 默认头部5行 df2.head(3) # 指定3行 # df2.tail() 默认尾部5行 df2.tail(2) # 指定尾部2行
显示全部列名

显示索引

查看列的数据类型

查看行列数

查看数据大小

查看缺失值
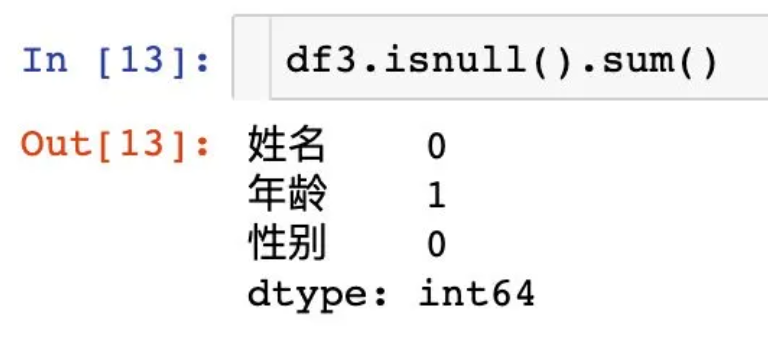
修改列名
两种方式:使用rename函数和直接使用columns属性

统计元素
统计每个元素的个数

转成列表数据

提取列中数据

提取文本数据

数值范围数据提取
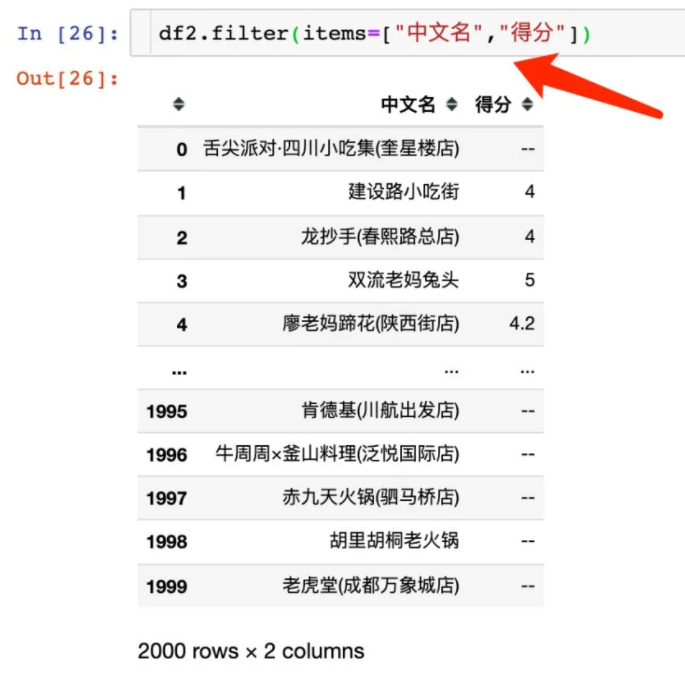
提取整列数据

缺失值填充
1、替换缺失值:fillna(value, inplace=True)
- value:替换成的值
- inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
- 指定填充的值
- 用计算值
- 用其他值
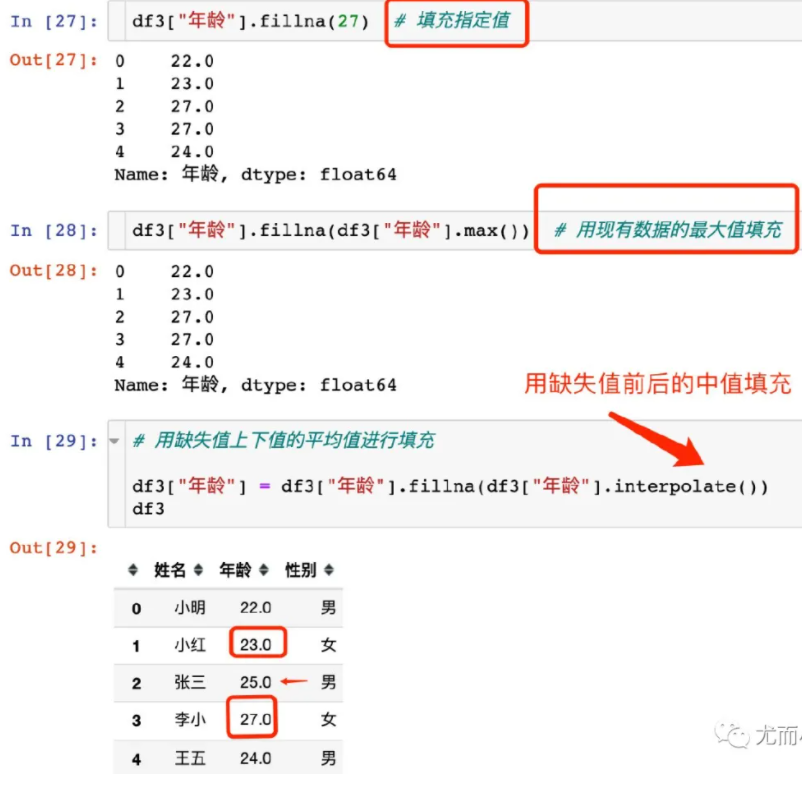
2.删除存在缺失值的:dropna(axis='rows')
注:不会修改原数据,需要接受返回值
判断数据中是否包含NaN:
pd.isnull(df),
-
这个和上面的正好相反,判断是否是缺失值,是则返回True。
# 判断是否是缺失值,是则返回True pd.isnull(movie).head() # 结果: Rank Title Genre Description Director Actors Year Runtime (Minutes) Rating Votes Revenue (Millions) Metascore 0 False False False False False False False False False False False False 1 False False False False False False False False False False False False 2 False False False False False False False False False False False False 3 False False False False False False False False False False False False 4 False False False False False False False False False False False False
这个也不好观察,我们利用np.any() 来判断是否有缺失值,若有则返回True,下面看例子:
np.any(pd.isnull(movie)) # 返回 True
存在缺失值nan:
pd.notnull(df)
# 判断是否是缺失值,是则返回False pd.notnull(movie) # 结果: Rank Title Genre Description Director Actors Year Runtime (Minutes) Rating Votes Revenue (Millions) Metascore 0 True True True True True True True True True True True True 1 True True True True True True True True True True True True 2 True True True True True True True True True True True True 3 True True True True True True True True True True True True 4 True True True True True True True True True True True True 5 True True True True True True True True True True True True 6 True True True True True True True True True True True True 7 True True True True True True True True True True False True
但是上面这样显然不好观察,我们可以借助np.all()来返回是否有缺失值。np.all()只要有一个就返回False,下面看例子:
np.all(pd.notnull(movie)) # 返回 False
存在缺失值nan,并且是np.nan 删除或替换
- 1、删除
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
# 不修改原数据 movie.dropna() # 可以定义新的变量接受或者用原来的变量名 data = movie.dropna()
2、替换缺失值
# 替换存在缺失值的样本的两列 # 替换填充平均值,中位数 movie['Revenue (Millions)'].fillna(movie['Revenue (Millions)'].mean(), inplace=True)
替换所有缺失值:
# 这个循环,每次取出一列数据,然后用均值来填充 for i in movie.columns: if np.all(pd.notnull(movie[i])) == False: print(i) movie[i].fillna(movie[i].mean(), inplace=True)
不是缺失值nan,有默认标记的
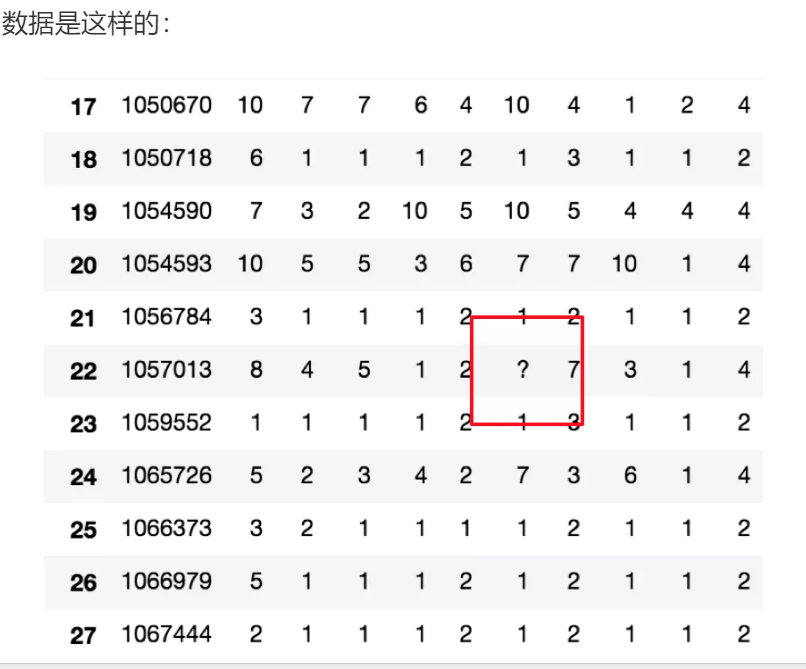
# 读入数据 wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
以上数据在读取时,可能会报如下错误:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:833)>
解决办法:
# 全局取消证书验证 import ssl ssl._create_default_https_context = ssl._create_unverified_context
处理思路分析:
- 1、先替换‘?’为np.nan
- to_replace:替换前的值
- value:替换后的值
df.replace(to_replace=, value=)
# 把一些其它值标记的缺失值,替换成np.nan wis = wis.replace(to_replace='?', value=np.nan)
2、再进行缺失值的处理
# 删除 wis = wis.dropna()
3、验证:
np.all(pd.notnull(wis)) # 返回True,说明没有了缺失值 # 或者 np.any(pd.isnull(wis)) # 返回False,说明没有了缺失值
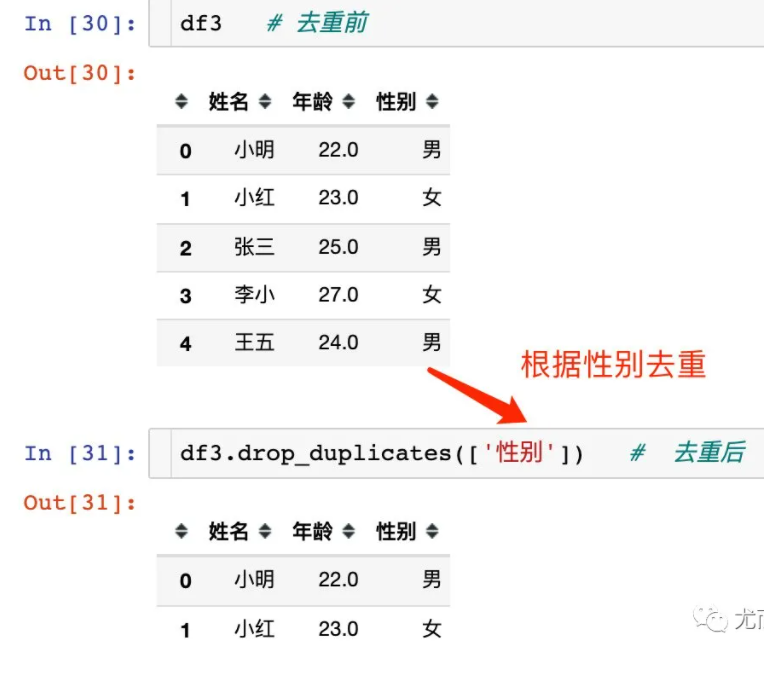
数据去重
计算统计值
计算统计值,比如最值和均值等

算术运算(1)add(other)
比如进行数学运算加上具体的一个数字
data['open'].head().add(1) 2018-02-27 24.53 2018-02-26 23.80 2018-02-23 23.88 2018-02-22 23.25 2018-02-14 22.49 Name: open, dtype: float64
算术运算(2)sub(other)
整个列减一个数
data.open.head().sub(2) 2018-02-27 21.53 2018-02-26 20.80 2018-02-23 20.88 2018-02-22 20.25 2018-02-14 19.49 Name: open, dtype: float64
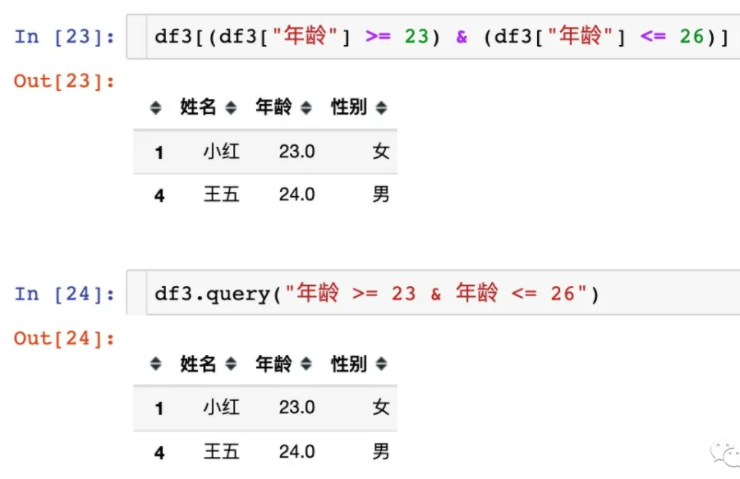
逻辑运算函数查询字符串
-
(1)
query(expr) - expr:查询字符串
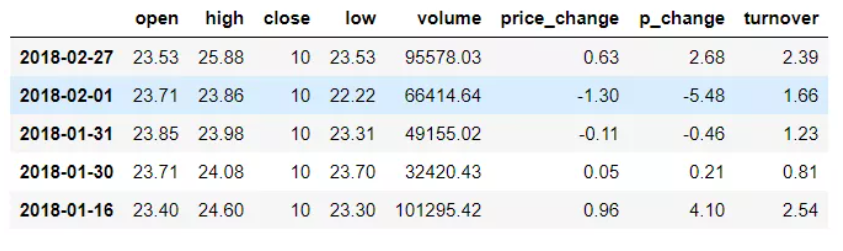
通过query使得刚才的过程更加方便简单,下面是使用的例子:
data.query("open<24 & open>23").head()
结果:
-
(2)
isin(values)
例如判断’open’是否为23.53和23.85:
# 可以指定值进行一个判断,从而进行筛选操作 data[data["open"].isin([23.53, 23.85])]


对于单个函数去进行统计的时候,坐标轴还是按照默认列“columns” (axis=0, default),如果要对行“index” 需要指定(axis=1)。
(1)max()、min()
# 使用统计函数:0 代表列求结果, 1 代表行求统计结果 data.max(axis=0) # 最大值 open 34.99 high 36.35 close 35.21 low 34.01 volume 501915.41 price_change 3.03 p_change 10.03 turnover 12.56 my_price_change 3.41 dtype: float64
(2)std()、var()
# 方差 data.var(axis=0) open 1.545255e+01 high 1.662665e+01 close 1.554572e+01 low 1.437902e+01 volume 5.458124e+09 price_change 8.072595e-01 p_change 1.664394e+01 turnover 4.323800e+00 my_price_change 6.409037e-01 dtype: float64 # 标准差 data.std(axis=0) open 3.930973 high 4.077578 close 3.942806 low 3.791968 volume 73879.119354 price_change 0.898476 p_change 4.079698 turnover 2.079375 my_price_change 0.800565 dtype: float64
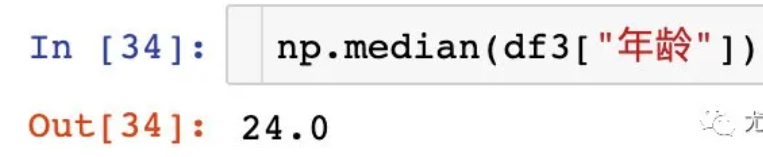
(3)median():中位数
中位数为将数据从小到大排列,在最中间的那个数为中位数。如果没有中间数,取中间两个数的平均值。
data.median(axis=0) open 21.44 high 21.97 close 10.00 low 20.98 volume 83175.93 price_change 0.05 p_change 0.26 turnover 2.50 dtype: float64
(4)idxmax()、idxmin()
# 求出最大值的位置 data.idxmax(axis=0) open 2015-06-15 high 2015-06-10 close 2015-06-12 low 2015-06-12 volume 2017-10-26 price_change 2015-06-09 p_change 2015-08-28 turnover 2017-10-26 my_price_change 2015-07-10 dtype: object # 求出最小值的位置 data.idxmin(axis=0) open 2015-03-02 high 2015-03-02 close 2015-09-02 low 2015-03-02 volume 2016-07-06 price_change 2015-06-15 p_change 2015-09-01 turnover 2016-07-06 my_price_change 2015-06-15 dtype: object
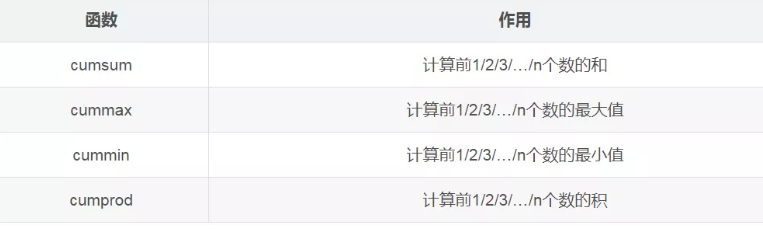
累计统计函数
统计函数
看一下min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)是怎么操作的:

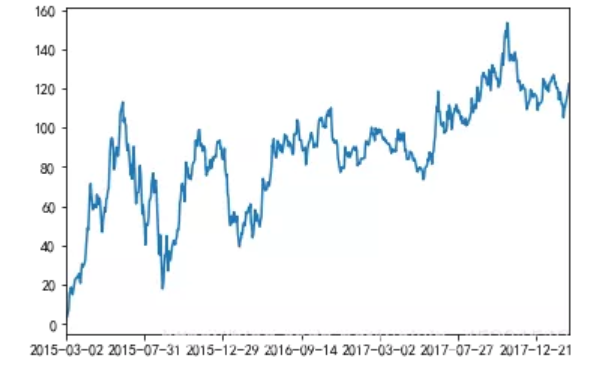
对p_change进行求和
stock_rise = data['p_change'] stock_rise.cumsum() 2015-03-02 2.62 2015-03-03 4.06 2015-03-04 5.63 2015-03-05 7.65 2015-03-06 16.16 2015-03-09 16.37 2015-03-10 18.75 2015-03-11 16.36 2015-03-12 15.03 2015-03-13 17.58 2015-03-16 20.34 2015-03-17 22.42 2015-03-18 23.28 2015-03-19 23.74 2015-03-20 23.48 2015-03-23 23.74
# plot显示图形, plot方法集成了直方图、条形图、饼图、折线图
如果要使用plot函数,需要导入matplotlib.下面是绘图代码:
-
DataFrame.plot(kind='line') - ‘line’ : 折线图
- ‘bar’ : 条形图
- ‘barh’ : 横放的条形图
- ‘hist’ : 直方图
- ‘pie’ : 饼图
- ‘scatter’ : 散点图
- kind : str,需要绘制图形的种类
import matplotlib.pyplot as plt # plot显示图形, plot方法集成了直方图、条形图、饼图、折线图 stock_rise.cumsum().plot() # 需要调用show,才能显示出结果 plt.show()
结果:
自定义运算apply(func, axis=0)
apply(func, axis=0)- func:自定义函数
- axis=0:默认是列,axis=1为行进行运算
- 定义一个对列,最大值-最小值的函数
下面看个例子:
data[['open', 'close']].apply(lambda x: x.max() - x.min(), axis=0) open 22.74 close 22.85 dtype: float64
计算中位数
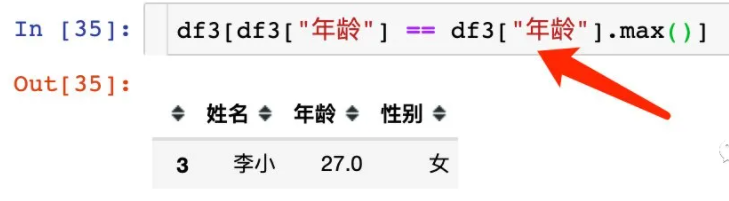
提取最值所在的行
Pandas切片
df2.iloc[22] # 提取某个行的数据 df2.iloc[:,1:6] # 行和列上的切片

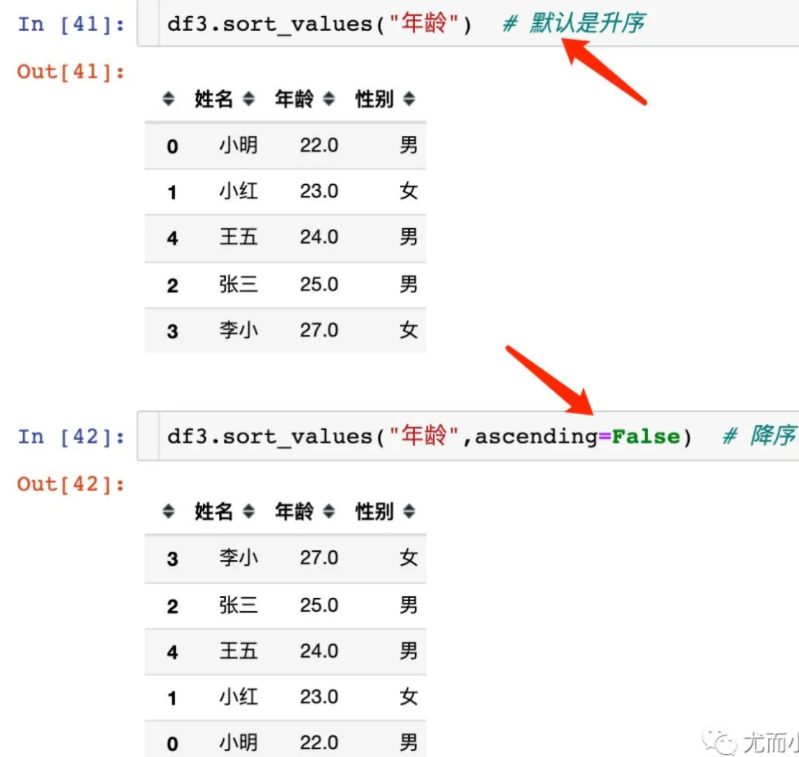
大小排序
分组聚合
使用groupby分组之后,对不同的字段可以使用不同的聚合函数
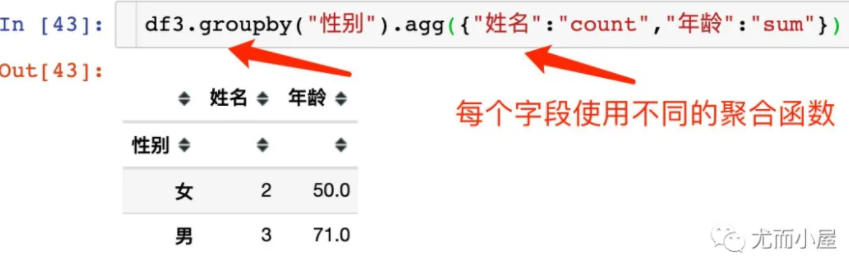
索引重排
注意和上面例子的比较。使用的是reset_index函数
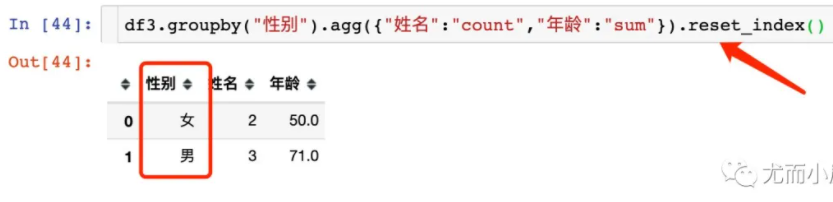
以某列值设置为新的索引
- set_index(keys, drop=True)
- keys : 列索引名成或者列索引名称的列表
- drop : boolean, default True.当做新的索引,删除原来的列
设置新索引案例:
1、创建
f = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
month sale year
0 1 55 2012
1 4 40 2014
2 7 84 2013
2、以月份设置新的索引
df.set_index('month') sale year month 1 55 2012 4 40 2014 7 84 2013 10 31 2014
3、设置多个索引,以年和月份
df = df.set_index(['year', 'month']) df sale year month 2012 1 55 2014 4 40 2013 7 84 2014 10 31
注:通过刚才的设置,这样DataFrame就变成了一个具有MultiIndex的DataFrame。
去掉原索引
使用索引重排之后我们需要去掉原来的索引;比较上下两个结果的区别。通过drop=True来实现
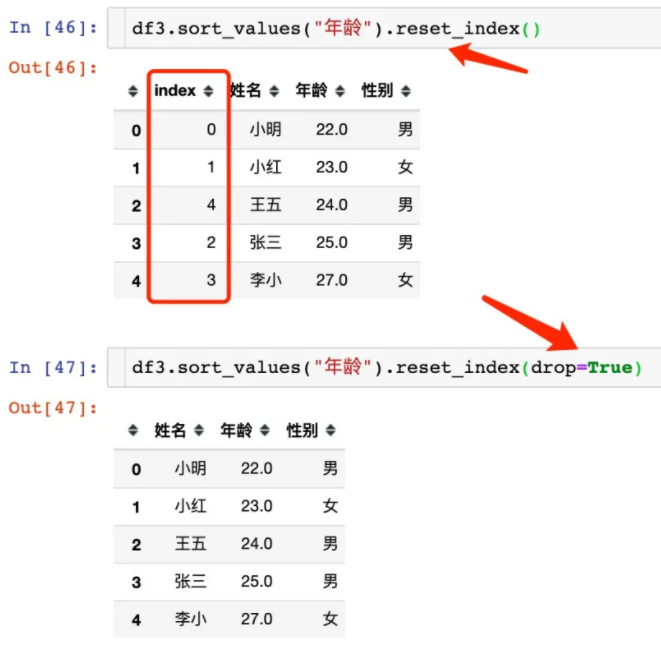
apply函数
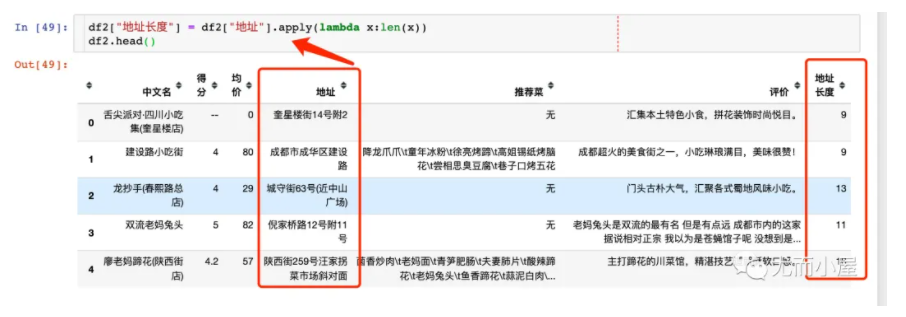
两个列相加
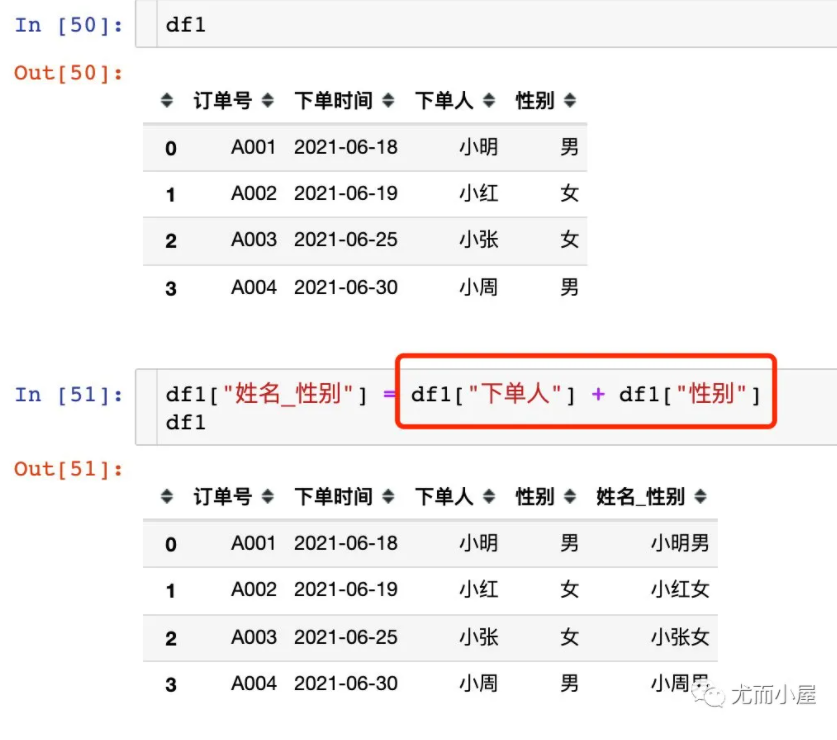

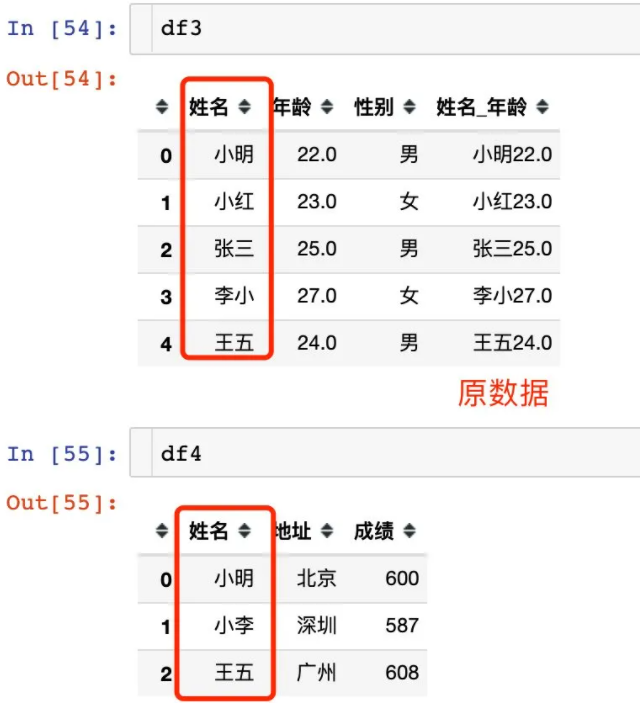
DataFrame合并
1、先看看两个原始数据
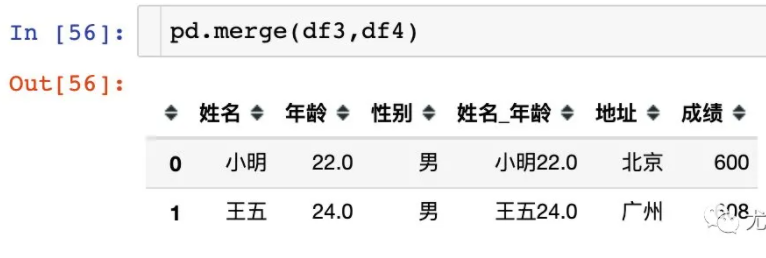
2、默认情况:求的两个DF的交集
3、保留左边全部数据

4、保留右边全部数据

how="inner"其实就是默认情况:

导出数据
导出数据的时候通常是不需要索引的

to_json
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)- 将Pandas 对象存储为json格式
- path_or_buf=None:文件地址
- orient:存储的json形式,{‘split’,’records’,’index’,’columns’,’values’}
- lines:一个对象存储为一行
案例:
- 存储文件
# 不指定lines=Treu,则保存成一行 json_read.to_json("./data/test.json", orient='records')
结果:
[{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0},{"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1},{"article_link":"https:\/\/politics.theonion.com\/boehner-just-wants-wife-to-listen-not-come-up-with-alt-1819574302","headline":"boehner just wants wife to listen, not come up with alternative debt-reduction ideas","is_sarcastic":1},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/jk-rowling-wishes-snape-happy-birthday_us_569117c4e4b0cad15e64fdcb","headline":"j.k. rowling wishes snape happy birthday in the most magical way","is_sarcastic":0},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/advancing-the-worlds-women_b_6810038.html","headline":"advancing the world's women","is_sarcastic":0},....]
修改lines参数为True
# 指定lines=True,则多行存储 json_read.to_json("./data/test.json", orient='records', lines=True)
结果:
"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0} {"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0} {"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1} {"article_link":"https:\/\/politics.theonion.com\/boehner-just-wants-wife-to-listen-not-come-up-with-alt-1819574302","headline":"boehner just wants wife to listen, not come up with alternative debt-reduction ideas","is_sarcastic":1} {"article_link":"https:\/\/www.huffingtonpost.com\/entry\/jk-rowling-wishes-snape-happy-birthday_us_569117c4e4b0cad15e64fdcb","headline":"j.k. rowling wishes snape happy birthday in the most magical way","is_sarcastic":0}...
实现行转列
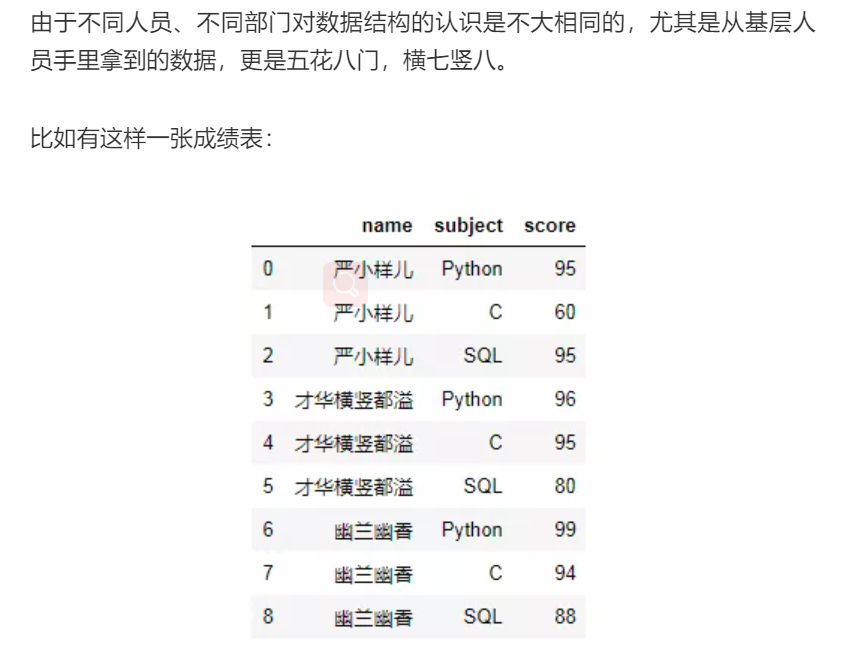
第一种:
# 遇事不要慌,先导个包吧 import pandas as pd import numpy as np # 造假数据 data = {'name':['严小样儿','严小样儿','严小样儿','才华横竖都溢','才华横竖都溢','才华横竖都溢','幽兰幽香','幽兰幽香','幽兰幽香'], 'subject':['Python','C','SQL','Python','C','SQL','Python','C','SQL'], 'score':[95,60,95,96,95,80,99,94,88]} # 生成df df = pd.DataFrame(data) df
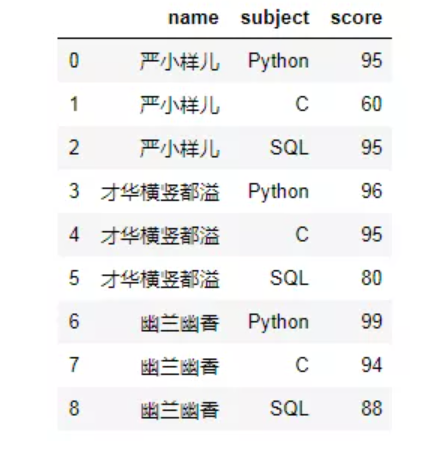
使用pivot方法即可完成行转列哦~语法如下:
#df.pivot(index=None, columns=None, values=None) df.pivot(index='name',columns='subject',values='score')

不要高兴的太早,遇到重复值就麻烦了!少侠请看:
# 造含有重复值的假数据 data1 = {'name':['严小样儿','严小样儿','严小样儿','严小样儿','才华横竖都溢','才华横竖都溢','才华横竖都溢','幽兰幽香','幽兰幽香','幽兰幽香'], 'subject':['Python','Python','C','SQL','Python','C','SQL','Python','C','SQL'], 'score':[95,95,60,95,96,95,80,99,94,88]} df1 = pd.DataFrame(data1) df1
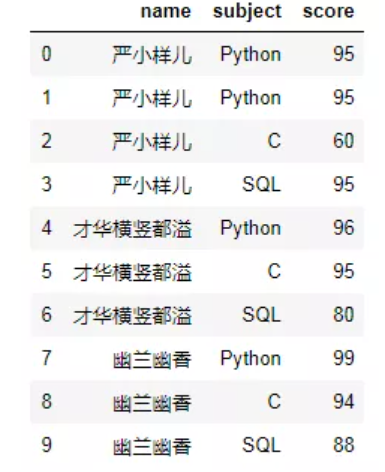
df1.pivot(index='name',columns='subject',values='score') # 一旦有重复值,就会报错。 ValueError: Index contains duplicate entries, cannot reshape
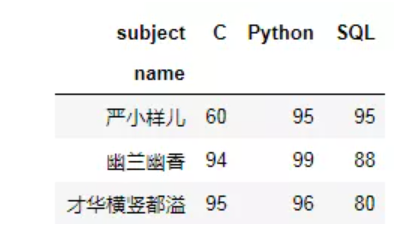
别急别急,去个重不就可以了吗?!
df1.drop_duplicates().pivot(index='name',columns='subject',values='score')
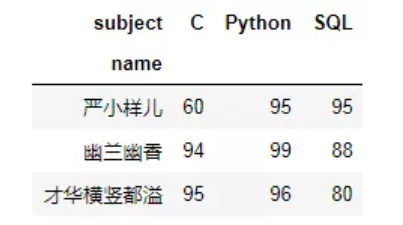
方法二:数据透视表
# pivot_table(data, values=None, index=None, columns=None, aggfunc='mean') pd.pivot_table(df1,index='name',columns='subject',values='score',aggfunc={'score':'max'})
聚合
刚刚说了,要求每个人的总分,其实使用透视表就可以完成。
不过,稍微动动脑筋哦。遇到重复值数据的话,只能使用下面的方法一,去重后的数据集,方法一,二都支持。
计算每个人的总分,语法如下:
# 重复数据集也可以 df_pivot = pd.pivot_table(df1,index='name',columns='subject',values='score',aggfunc={'score':'max'}) # 增加一个新列:Total df_pivot['Total'] = df_pivot.apply(lambda x:np.sum(x),axis = 1) df_pivot
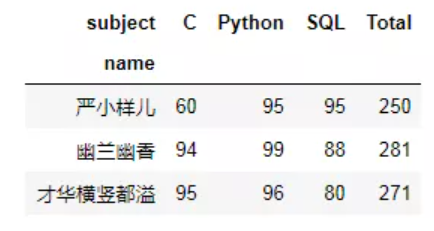
方法二,必须是去重后的数据集,否则会出现计算错误。
# 使用去重数据集才可以 pd.pivot_table(df,index='name',values='score',aggfunc='sum')
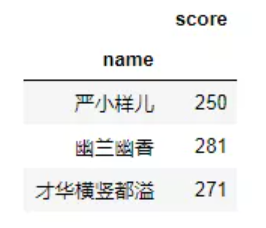
# 使用join方法把总分列加进去。 total = pd.pivot_table(df,index='name',values='score',aggfunc='sum') pd.pivot_table(df,index='name',columns='subject',values='score').join(total)
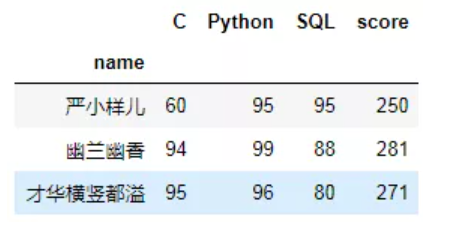
--需求方:算是算出来了,可是,这个score看着怪怪的,能不能改成“总分”呢?
--严小样儿:我改(卑微)!安排~
total1 = pd.pivot_table(df,index='name',values='score',aggfunc='sum').rename({'score':'总分'},axis=1) pd.pivot_table(df,index='name',columns='subject',values='score').join(total1)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
2018-10-22 Python之路迭代器协议、for循环机制、三元运算、列表解析式、生成器
2018-10-22 Python之路Python文件操作
2018-10-22 Python编程笔记二进制、字符编码、数据类型