
UnicodeEncodeError: 'latin-1' codec can't encode characters,python3 中文乱码
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 9-13: ordinal not in range(256)
后来苦思冥想找资料,最后发现一个办法,可以解决上述问题,就是:
在下图所示处加上下面箭头所指那句,即图后蓝色代码
account = accountraw.encode("utf-8").decode("latin1")
file="中国.xls".decode("utf-8")#将中文进行decode解码也就是将utf-8转为unicode
data=xlrd.open_workbook(file)
2.控制台输出中文乱码
解决方法:
print("中国").decode('utf-8').encode('gbk')
#源码是utf-8,控制台是默认gbk输出,
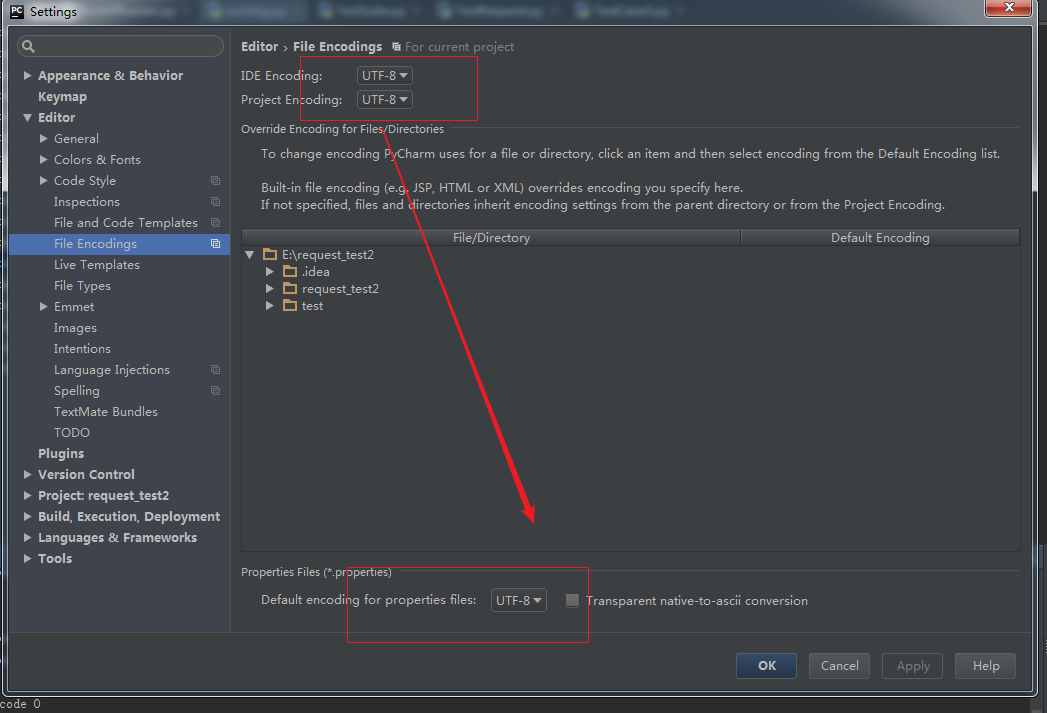
最好自己去更改一下设置就好(在file-settings-fileEncodings-utf-8)两个都选成utf-8,这样就可以直接输出
原因:
主要原因是Excel中读取数据乱码解决办法如下:
每天一点点,感受自己存在的意义。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2018-05-23 Linux nl --让输出的文件内容自动加上行号
2018-05-23 修改linux的文件时,如何快速找到要修改的内容
2018-05-23 ps与grep组合命令使用
2018-05-23 python+selenium 定位隐藏元素
2018-05-23 数据库的几种去重方法总结
2018-05-23 用例设计方法与测试实践相结合思路