

一个网站新闻页通用的正文抽取组件libnpce
一、背景
在舆情系统中,通常会有一个网络新闻爬虫子系统,准实时的采集互联网上的媒体新闻数据,以供上层聚类事件分析。这类新闻数据的组成元素包括:
- 标题
- 发布时间
- 来源及其URL链接地址
- 正文文本内容
- 正文图片信息(图片位置、图片的URL路径等)
- 其他
二、libnpce组件
新闻文章正文抽取News Passage Content Extractor (NPCE),是为抽取HTML中的文章正文而设计的。该组件提供给予so动态链接库的调用接口和给予RESTful服务调用的接口形式。并支持python调用接口。
详细介绍可参考:https://tangyibo.github.io/libariry/2020/01/17/a-news-passage-content-extractor-library/
三、组件演示
打开页面: https://gitee.com/inrgihc/libnpce/releases/v1.0
下载httpd_npce_py-v1.0-bin.tar.gz文件,在centos环境下解压,然后执行:
cd httpd_npce_py/
./startup.sh
命令启动服务,打开浏览器访问服务器上的服务:http://XXX.XXX.XXX.XXX:7645
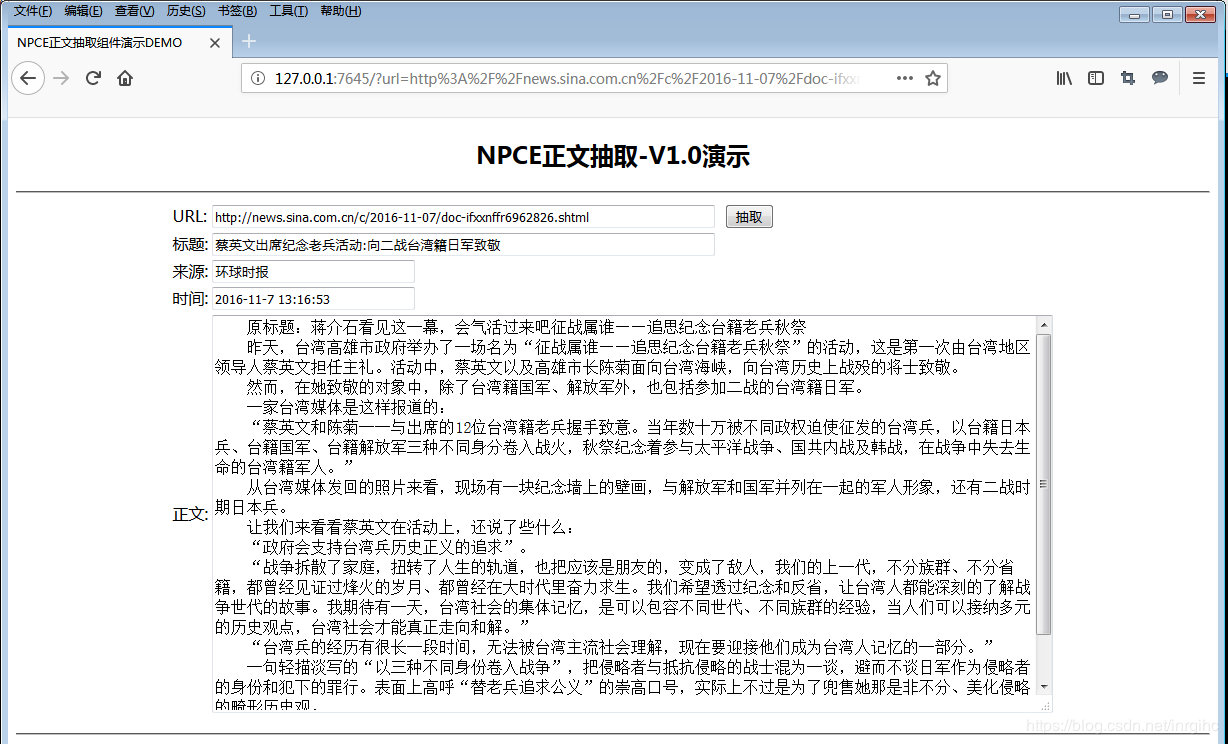
在页面中的URL栏中粘贴一个新闻页面的URL地址,然后点击右侧的“抽取”按钮查看效果,我的截图如下:
抽取的URL地址:http://news.sina.com.cn/c/2016-11-07/doc-ifxxnffr6962826.shtml
三、性能测试
经本人工作期间,将libnpce与计算所的constor组件(闭源)进行比较测试,性能相当,并应用在公司底层的爬虫模块中进行实时正文抽取。

