
12.Adaboost算法简介
本文由中山大学In+ Lab整理完成,转载注明出处
团队介绍 传送门
1. 序言
Adaboost算法的思想是将多个弱分类器组合成一个强分类器的过程,Adaboost全称Adaptive Boosting意思就是自适应提升算法,也就是自适应地完成弱分类器的学习和组合过程。
2. Adaboost算法
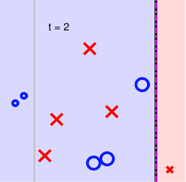
下面以量化选股中的多因子模型作为例子,基本原理是采用一系列的因子作为选股标准,满足这些因子的股票则被买入,不满足的则卖出。为方便可视化,这里我们只选两个因子,正样本表示收益为正的股票,负样本表示收益为负的股票。如图1中所示,O代表正样本,x代表负样本。
Adaboost算法主要分成两步,第一步:迭代地学习多个弱分类器,第二步:组合学习到的弱分类器。

2.1 迭代学习弱分类器
第一步要学习到的分类器需要满足什么条件呢?第一,分类器可以很简单,也就是说在图中的分界线可以选择为平行于坐标轴的,第二,是最小化分类错误率,于是我们得图2中所示的分类边界,错误率最小为0.3。下一步迭代如何进行呢,直观点的方式是对分类错误的样本提高重视,分类正确的降低重视,实现的方式就是根据分类正确与否调整样本权重。在图1中,就是将划分错误的正样本的比例画的大了一些表示提高权重。
同样的,第二步要学习到的分类器仍然是最小化错误率的简单分类器,在调整样本权重后分类器的边界自然会不一致,这一点的是通过样本权重的更新公式得到保证的。样本权重的更新公式是在保证在更新样本权重后第一个分类器的错误率为最高值0.5,而第二个分类器的错误率在学习后误差率为最小值,通过简单的数学推导可以得出样本权重的更新公式。
2.2 组合弱分类器
在保证分类器差异性的前提下我们可以通过组合这些这些分类边界,得到复杂有效的分类边界,也就是一个新的强分类器,将不同迭代次数学习到分类器于之前的分类组合后得到的边界,如下图所示。
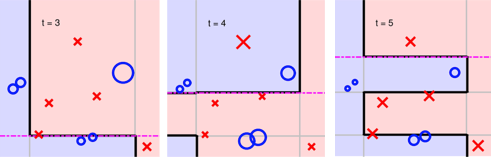
可以很明显的看到,多个简单边界的分类通过自适应的学习过程可以组合成一个分类效果更好的复杂边界。
Adaboost的过程可以很简单的抽象:
- 抽取简单边界的分类器;
- 增加被分类错误样本的权重;
- 重复迭代1、2,直到没有分类错误或达到自定义错误率界限;
- 按权重组合各个分类器。
2.3 总结
到这里Adaboost就写完了,前面提到的弱分类器是特定的一种。理论上任何学习器都可以用于Adaboost.但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。
这里对Adaboost算法的优缺点做一个总结。
Adaboost的主要优点有:
1)Adaboost作为分类器时,分类精度很高
2)在Adaboost的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活。
3)作为简单的二元分类器时,构造简单,结果可理解。
4)不容易发生过拟合
Adaboost的主要缺点有:
1)对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
由于adaboost算法是一种实现简单,应用也很简单的算法。Adaboost算法通过组合弱分类器而得到强分类器,同时具有分类错误率上界随着训练增加而稳定下降,不会过拟合等的性质,应该说是一种很适合于在各种分类场景下应用的算法。
3. 参考文献
- 林轩田 《机器学习技法》
- http://www.cnblogs.com/pinard/p/6133937.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号