

[RPA-Python]自动化脚本入门使用---1
RPA Python
RPA for Python 简单而强大的 API 让机器人流程自动化变得有趣!您可以使用它快速自动化网站、桌面应用程序或命令行上重复的耗时任务。
相关链接
安装(windows)
- 将下载好的
TagUI v6.46 for Windows解压放在C:\Users\PX_Lenovo\AppData\Roaming文件夹下 - 安装OpenJDK for Windows
- 下载chrome
- 安装python
- 安装pip
- 下载pip源码包:https://pypi.org/project/pip/#files
- 下载
pip-22.0.4.tar.gz不是*.whl文件 - 解压该压缩包
- 通过
命令行或者windows powershell进入解压后的目录 - 执行
python setup.py install - 在环境变量
Path中加入C:\Users\Administrator\AppData\Local\Programs\Python\Python39\Scriptspip的安装目录 - 可以使用pip了,执行
pip list测试一些
- 执行命令
pip install rpa
使用Jupyter运行
安装Jupyter
windows powershell执行pip install jupyterlab- 安装完成后再
windows powershell执行jupyter notebook,会自动的打开一个网页,在网页上编辑代码
使用Jupyter
启动Jupyter,尽量新建一个空文件夹启动,因为从powershell 启动后,Jupyter会自动视该文件夹为工作目录。
在网页上点击new,创建python脚本:
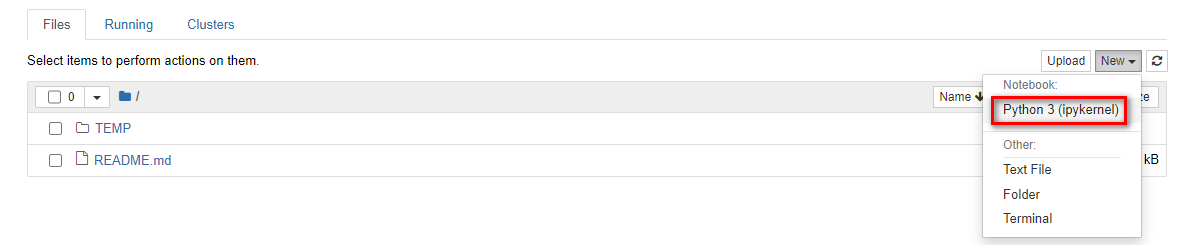
一个In中可以写多行代码,也可以写一行,运行按钮可以单独执行某个In,shift+enter添加新的In:
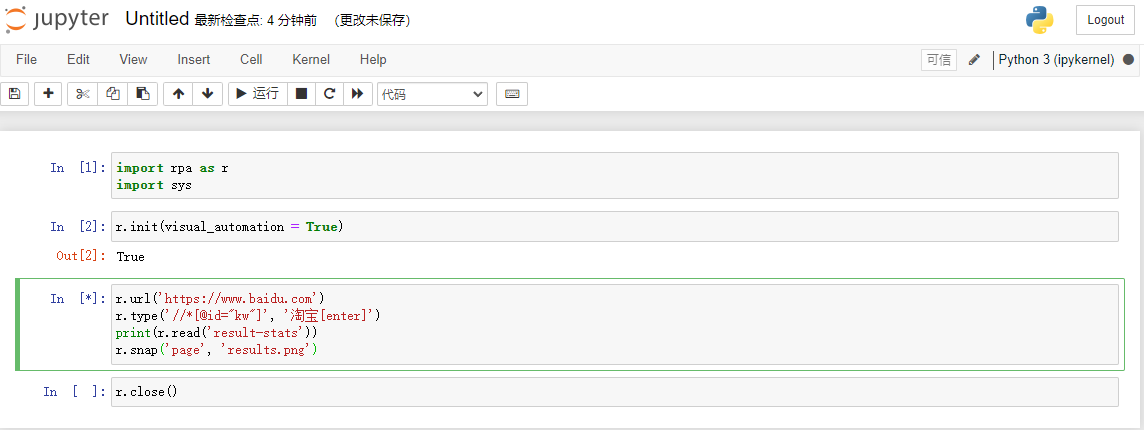
鼠标可以选择单个In来执行,比如import一次后就不必再import,类似init也只需要一次,除非重启内核(界面上的刷新按钮)。
第一次执行,一定要跑import和init,例如图中只需要执行一次In[1]与In[2] ,In[3]可以多次执行。
练习
基础知识
这里的r是import rpa as r
r.init( visual_automation = True, chrome = false)
这个是可以这样写r.init(),visual_automation = True表示动画可见。
r.url()
要输入一个网址,例如:r.url('https://www.baidu.com/')
r.type( xpath, words)用法1
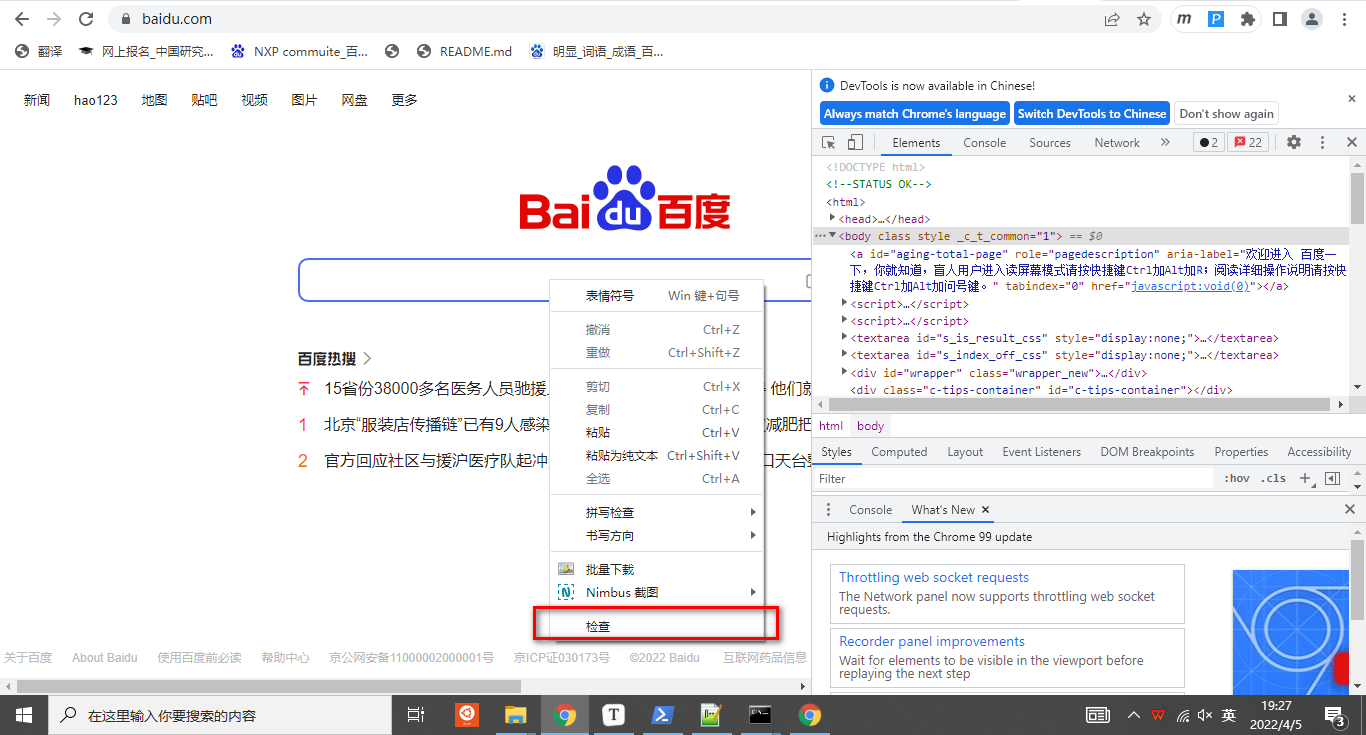
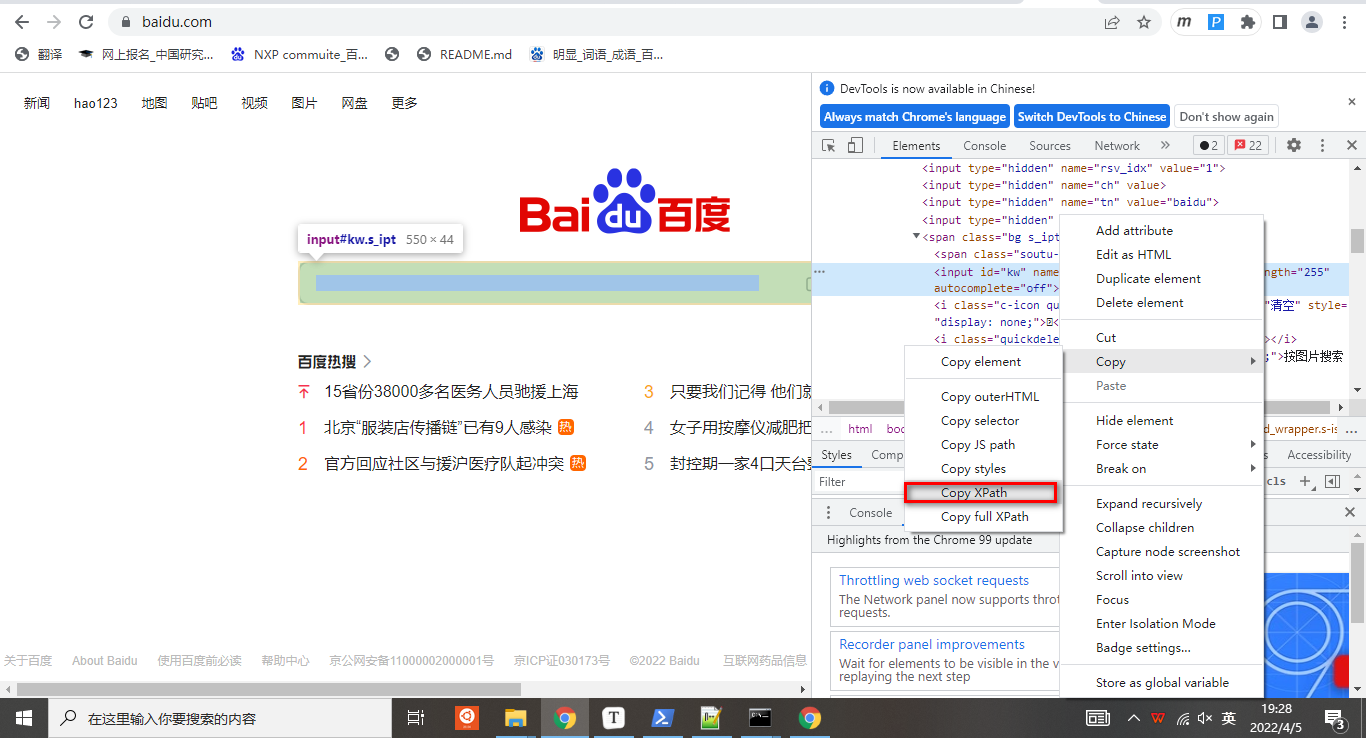
xpath表示输入的网页xpath,words表示输入的是什么内容。xpath获取方式如下,谷歌浏览器按F12,然后在想要查看位置右键检查:
r.type( image, words)用法2
例如:r.type('message_box.png', 'Hi Gillian,[enter]This is...')这个该网页或者图的某一部位的图,它会在该网页(或其他)找到message_box.png图所指示的位置,在该位置输入数据。其中[enter]表示按下Enter按键。
r.read( DOM/XPath/Region/Image)
**注:DOM 和 XPath 标识符仅适用于 Chrome/Edge。要自动化其他浏览器,请使用点/区域和图像标识符。**
# DOM
这匹配网页的 DOM(文档对象模型)中的元素,匹配id、名称、类属性或元素本身的文本。
`click Getting started`
# XPath
这与网页中元素的XPath匹配。这是一种更明确、更强大的定位 Web 元素的方式。
**注:您也可以使用 CSS 选择器代替 XPath,但首选 XPath。**
`click //body/div[1]/nav/div/div[1]/a`
# Point
点击屏幕中的点。
`click (200,500)`
这与屏幕上距屏幕左侧 200 像素和距屏幕顶部 500 像素的点相匹配。
# Region
某个区域。
`read (300,400)-(500,550) to some-variable`
这与两点 (300,400) 和 (500,550) 之间形成的矩形相匹配。
# Image
点击某个图片,实际上是利用图形识别完成。
`click button.png`
这匹配屏幕上看起来类似于图像文件的任何区域button.png(在流程的文件夹中)。您首先需要截取button.png. 这使用了视觉自动化。
`click image/button.png`
这允许您button.png在image文件夹中查找。
这里可以通过OCR读取图片中的文字,例如:
print(r.read('//*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]'))print(r.read('pdf_window.png'))
r.snap( DOM/XPath/Region/Image/page, filename)
这个表示截图,前面表示从哪里截图,后面表示保存的路径和文件名。例如:
r.snap('page', 'TEMP/results.png')
支持的按键如下:
[shift] [ctrl] [alt] [win] [cmd] [enter]
[space] [tab] [esc] [backspace] [delete] [clear]
[up] [down] [left] [right] [pageup] [pagedown]
[home] [end] [insert] [f1] .. [f15]
[printscreen] [scrolllock] [pause] [capslock] [numlock]
网页搜索采集数据
无
点击特定元素
无
使用按键打开应用
r.keyboard('[win]r')
r.keyboard('explorer[enter]')
r.type('TEMP/explorer_add_bar.png', 'C:\\Users\\PX_Lenovo\\Documents\\TEMP[enter]')
使用鼠标打开右键打开文件
r.keyboard('[win]r')
r.keyboard('explorer[enter]')
r.type('TEMP/explorer_add_bar.png', 'C:\\Users\\PX_Lenovo\\Pictures[enter]')
r.click('TEMP/window_max_bt.png');
r.hover('TEMP/aim_pic_name.png')
r.rclick('TEMP/aim_pic_name.png')
r.click('TEMP/r_key_open_ways.png');
r.click('TEMP/r_key_open_ways_org_pic.png');
使用滚轮
r.vision('wheel(WHEEL_UP, 120)')
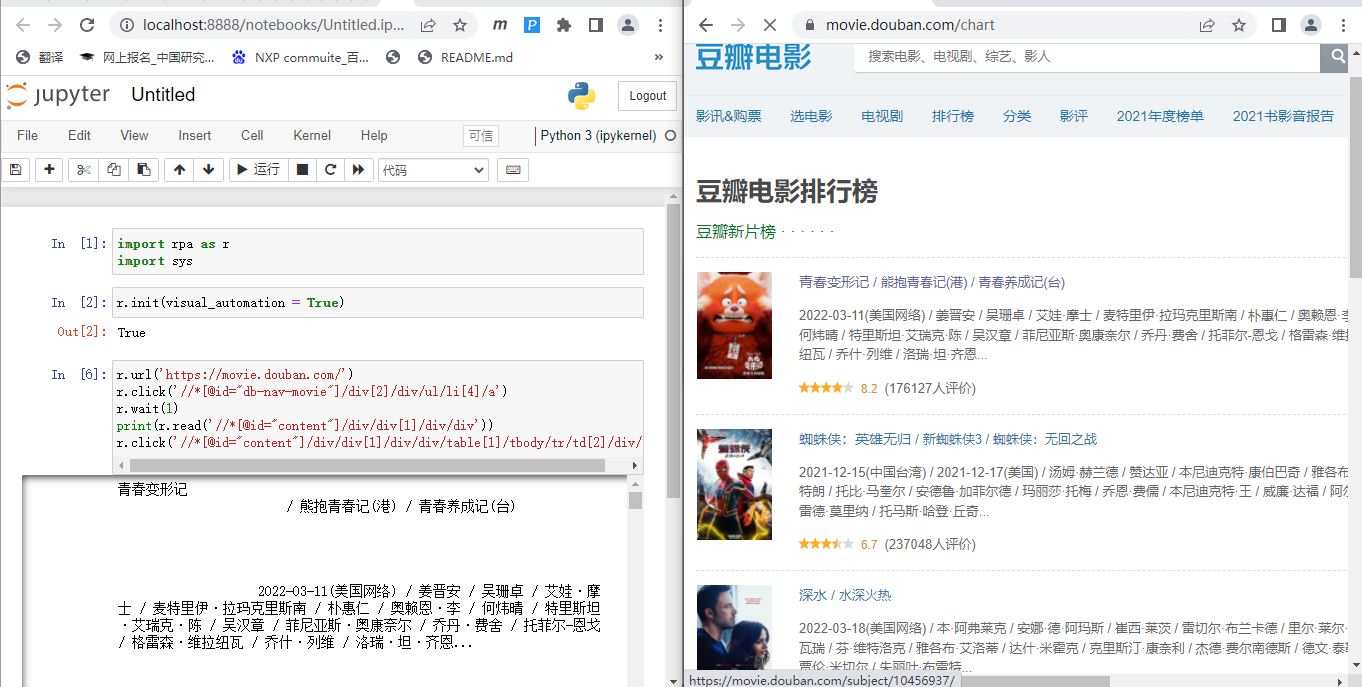
获取豆瓣最新电影排行
r.url('https://movie.douban.com/')
r.click('//*[@id="db-nav-movie"]/div[2]/div/ul/li[4]/a')
r.wait(1)
print(r.read('//*[@id="content"]/div/div[1]/div/div'))
r.click('//*[@id="content"]/div/div[1]/div/div/table[1]/tbody/tr/td[2]/div/a')
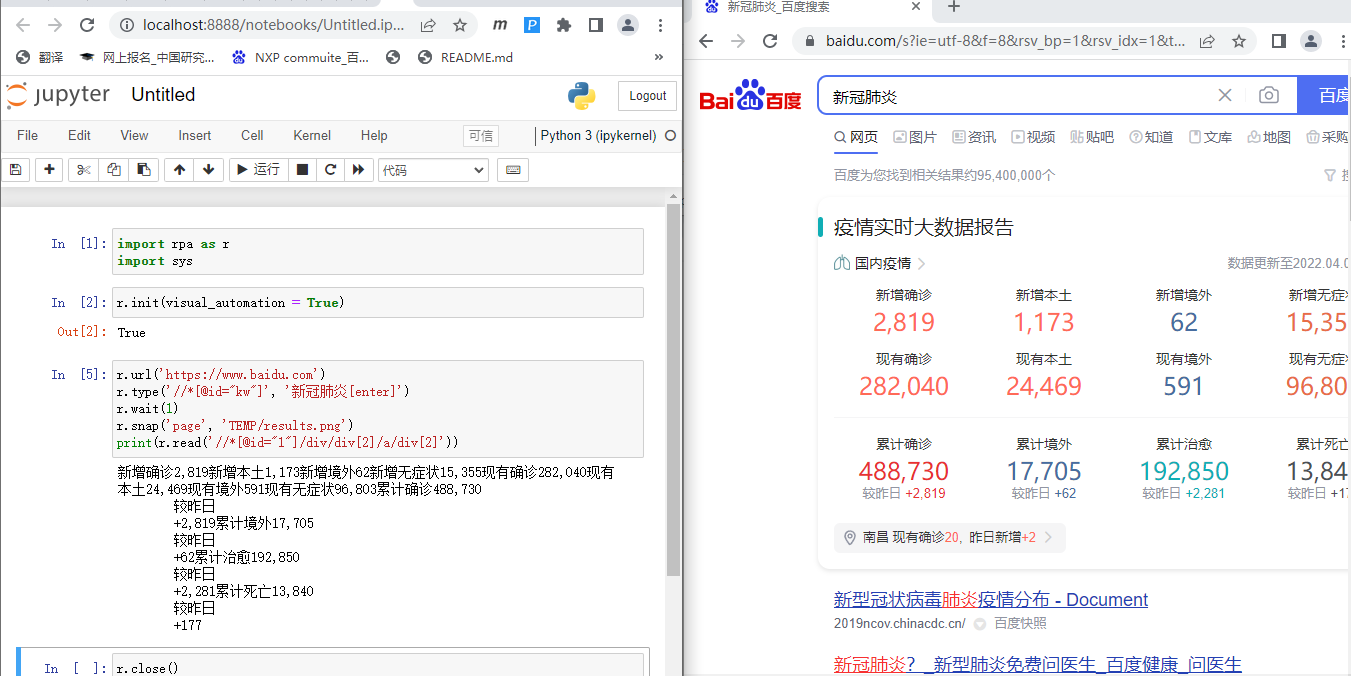
OCR
ocr主要是使用read函数
r.url('https://www.baidu.com')
r.type('//*[@id="kw"]', '新冠肺炎[enter]')
r.wait(1)
r.snap('page', 'TEMP/results.png')
print(r.read('//*[@id="1"]/div/div[2]/a/div[2]'))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· Open-Sora 2.0 重磅开源!