


异常处理过程:
当我们遇到异常时,我们首先需要把当前程序P的状态保存起来,而后跳到异常处理程序进行诊断。
- 这里我们从指令集状态机S = {<R,M>}的视角来讨论咯 R为寄存器,M为内存。
异常处理程序和P事两个不同的程序,它们使用不同的M,所以:只要异常处理程序不随意修改P的M,则不必进行实质性的保存操作。
但是R只有一份,即P和异常处理程序共用寄存器,所以我们需要把P的寄存器状态保存起来。
但是R保存到哪里呢??
有几种方法:
1.保存到R:也就是增加新的一组寄存器,把P的寄存器状态复制到新寄存器中。
2.保存到M:也就是存到内存中,但是需要找到一处空闲的内存呢
3.保存到栈:栈有空间的话,这个可以有。
谁来保存?
- 硬件保存:在CPU状态机的控制下保存
- 软件保存: 通过指令控制CPU进行保存
所以保存R的设计,共有四种方法
| R | M | |
|---|---|---|
| 硬件保存 | 硬件保存到R_save | 硬件保存到M |
| 软件保存 | 软件保存到R_save | 软件保存到M |
当发生异常时的流程如下:P发生异常->硬件保存->跳转到异常处理程序->软件保存
这里要注意的是,当异常处理程序诊断时需要读取R_save。所以CPU还要添加相应的读取等指令。
RISCV硬件将PC保存到mepc这个特殊的寄存器中,也叫控制状态寄存器(CSR,control and status register)
CSR
用于控制和反映处理器状态的特殊寄存器(eg:mepc)
- 硬件发生某些事会自动更新CSR,或者从CSR中读出值直接用
- 软件也可以通过CSR指令来访问CSR
- 所以每个CSR都有一个软件可见的编号(CSR地址空间)
下面的图片中最上就是一条CSR指令,其中0x341代表mepc寄存器的地址空间(也是编号:-)
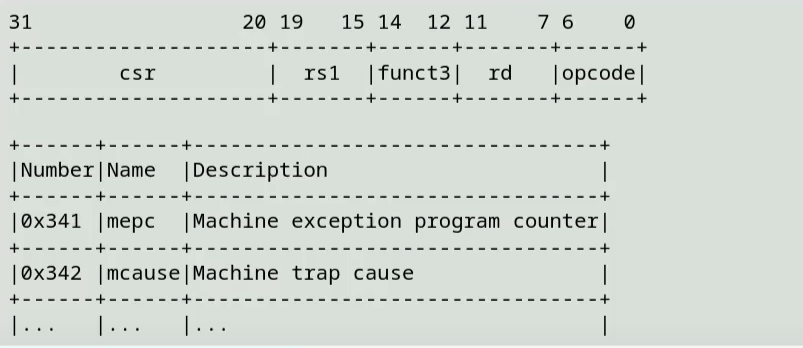
我们这里用到的CSR又: - mtvec寄存器 - 存放了发生异常时处理器需要跳转到的地址
- mepc寄存器 - 存放发生异常的指令地址,用与异常处理返回时能回到原本程序执行的位置
- mstatus寄存器 - 存放处理器的状态
- mcause寄存器 - 存放异常的种类
详细的解释如下:
mtvec:异常处理程序的入口地址,即当发生异常时CPU自动跳转到这个地址
一个简单的异常处理程序
#include <klib.h> void handler() { uintptr_t mepc; // 定义一个变量来存储异常发生时的程序计数器 (Program Counter) // 使用内联汇编读取 mepc 寄存器的值 asm volatile ("csrr %0, mepc" : "=r"(mepc)); printf("exception at mepc = %p\n", mepc); // 打印异常发生的地址 while (1); // 无限循环,防止返回 } int main() { // 设置 mtvec 寄存器,指向异常处理程序 handler asm volatile ("csrw mtvec, %0" : :"r"(handler)); // 触发非法指令异常 asm volatile (".word 0"); // 这行代码试图执行一个无效的指令 printf("I am alive!\n"); while (1); }
类似的还有mcause寄存器,即发生异常时,CPU将异常号写入这个CSR
具体的异常号如下
# RTFM了解异常号的含义 0 - Instruction address misaligned 1 - Instruction access fault 2 - Illegal Instruction 3 - Breakpoint 4 - Load address misaligned 5 - Load access fault 6 - Store/AMO address misaligned 7 - Store/AMO access fault 8 - Environment call from U-mode 9 - Environment call from S-mode 11 - Environment call from M-mode 12 - Instruction page fault 13 - Load page fault 15 - Store/AMO page fault
从异常状态返回
若诊断问题不大,P可以继续执行,则需要从异常处理程序返回P。那么返回需要先回复之前为P保存的状态(恢复寄存器就行)
- RISC架构通过load指令将M中保存的内容恢复到R,然后返回P
- 但是异常处理程序和P事两个不同的程序,不可以通过ret/jal返回
- jalr指令需要先把返回地址写入一个寄存器,但是那样会改变P的状态,如果返回后P需要用这个寄存器,就会报错。
所以综上,我们需要添加一条特殊的返回指令mret,即跳转到mepc中存放的地址
uintptr_t mepc, mcause; // 读取 mepc 寄存器的值(异常发生时的程序计数器值) asm volatile ("csrr %0, mepc" : "=r"(mepc)); // 读取 mcause 寄存器的值(异常原因) asm volatile ("csrr %0, mcause" : "=r"(mcause)); // 打印异常原因和异常发生时的程序计数器值 printf("exception mcause = %p at mepc = %p\n", mcause, mepc); // 仅限于演示,没有恢复其他寄存器 // 检查异常原因是否为2(通常表示非法指令异常) if (mcause == 2) { // 更新 mepc 寄存器的值为 mepc + 4(跳过导致异常的指令) asm volatile ("csrw mepc, %0; mret" : : "r"(mepc + 4)); } while (1);
硬件实现异常处理
在单周期实现异常
实现异常处理我们得先
-
实现CSR
-
添加CSR的读写指令,而后在指令异常时注意通用寄存器GPR和CSR之间的数据交换。
-
实现异常的触发,在译码时要检查非法指令,识别ecall指令等,识别到异常事件后,我们还需要通过电路更新mmepc,,mcause等CSR,而后跳转到mevec中存放的地址
-
实现mret指令,即跳转到mepc中存放的地址
异常处理的状态机模型
在异常处理状态下,状态机模型又需要改变了,状态机模型需要加一个扩展(CSR),也就是:
R = {PC, GPR,CSR},M无需扩展,注意在这里指令的执行并不是always成功了,定义一个函数
f_ex : S->{0,1},给定任意状态S:
- f_ex(S) = 0,则按照当前指令的语义进行状态转移
- f_ex\(S)= 1,则执行一条特殊指令raise_intr异常号,并更新状态如下
CSR[mepc] <- PC CSR[mcause] <- 异常号 PC <- CSR[mtvec]
说白了,模型状态机一旦异常(f_ex(S)=1),就是把各种异常号,异常的pc值存到CSR寄存器中
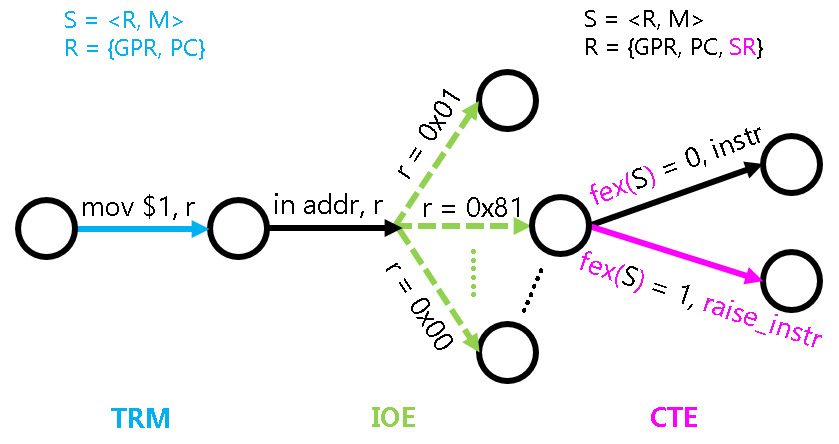
异常的真实调用
在现代计算机中都支持多用户多任务,但是多个程序可能竞争相同资源,没有协调者,解决方案就是:
- 硬件提供特权级保护
什么意思呢,就是资源管理程序放在高特权级(其实这就是操作系统的本质啦),用户程序放在低特权级:只能执行普通指令进行计算,发起系统调用请求提供服务。
就是用户自己处理不了异常,需要有一个指令来告知系统:我处于异常状态,让系统救一下。
发起系统调用
唯一的合法方式就是:自陷类异常,即执行一条无条件触发异常的指令
- riscv中 ecall指令
- 操作系统可以根据mcause 得知该异常是合法的请求(通过异常号)
为了让用户程序指定请求的是那种服务,系统调用也需要参数,就是通过寄存器来传递的! - 操作系统的异常处理函数一别到系统调用请求后,从Context结构中读出系统调用参数(AM)
- RISCV Linux约定采用a7寄存器传递系统调用号,a0,a1 ...分别传递1 2...个参数
am-kernels/kernels/yield-os/yield-os.c 实现了操作系统原型:
对回调函数进行巧妙的修改:
- 保存当前程序上下文
- 返回另一个程序的上下文
程序A发生异常->保存A的context->异常处理-> 回复B的Context ->从异常返回
这样就实现了从A到B的效果。
又看了两天代码,思路有些不清晰,想着写下来正好梳理下思路。
就拿讲义中的simple_trap来举例,main函数中初始化CTE,初始化CTE:
bool cte_init(Context*(*handler)(Event, Context*)) { // 把__am_asm_trap的地址写入到mtvec寄存器中,也就是触发异常就执行__am_asm_trap asm volatile("csrw mtvec, %0" : : "r"(__am_asm_trap)); // 注册回调函数 user_handler = handler; return true; }
在mainargs中选择便会传入simple_trap的参数,具体如下列代码。IOE CTE的宏展开都是初始化。其中CTE(simple_trap)就是
#define IOE ({ ioe_init(); }) #define CTE(h) ({ Context *h(Event, Context *); cte_init(h); }) CASE('i', hello_intr, IOE, CTE(simple_trap));
后续还需要用到的有__am_irq_handle() 和__am_asm_trap:
Context* __am_irq_handle(Context *c) { if (user_handler) { //事件初始化为0 Event ev = {0}; //根据异常号打包成不同的事件类型,这里统一设置成error switch (c->mcause) { default: ev.event = EVENT_ERROR; break; } //传回之前注册的回调函数,判断是否为空 c = user_handler(ev, c); assert(c != NULL); } return c; }
__am_asm_trap: //堆栈指针sp向下移动CONTEXT_SIZE,为保存上下文腾出空间 addi sp, sp, -CONTEXT_SIZE //保存所有寄存器的内容push到堆栈中 //这里宏展开后就是sw x1 (1*4)(sp) //sw x3(3*4)(sp)~ sw x31(31*4)(sp) 就是把寄存器的内容放到栈上 //x0 永远为0,所以不需要存或恢复 x2寄存器就是sp自己,不需要通过宏展开保存 MAP(REGS, PUSH) //把这三个CSR寄存器读到 t0 t1 t2 (t0 t1 t1的值之前已经保存了) csrr t0, mcause csrr t1, mstatus csrr t2, mepc //将读取到的三个寄存器值存储到堆栈对应的偏移量 STORE t0, OFFSET_CAUSE(sp) STORE t1, OFFSET_STATUS(sp) STORE t2, OFFSET_EPC(sp) # set mstatus.MPRV to pass difftest li a0, (1 << 17) or t1, t1, a0 csrw mstatus, t1 //sp移动到a0,跳转并链接到_am_irq_handle的中断处理函数 mv a0, sp jal __am_irq_handle //从 __am_riq_handle返回后,会把上面存的在取出来 //把sp+偏移量的地址内容存到t1,t2 LOAD t1, OFFSET_STATUS(sp) LOAD t2, OFFSET_EPC(sp) //t1 t2写到这两个CSR寄存器中 csrw mstatus, t1 csrw mepc, t2 //宏展开后就是一堆load指令,和 PUSH类似,也忽略了x0 x2 MAP(REGS, POP) addi sp, sp, CONTEXT_SIZE mret
当选择i后,一系列异常相关的操作就开始了:
- 初始化IOE -> 初始化CTE(注册回调函数等)-> hello_intr() -> yield(实现自陷操作,触发异常)-> 读取mtvec -> 开始__am_asm_trap -> 寄存器内容写入栈 -> __am_iqr_handle() -> 给事件状态赋值(这里统一为ev.event = EVENT_ERROR) -> 进入handle_function(putch(y))->从栈中恢复内容到寄存器
讲义中不断输出y是因为他while循环咯,自陷一次就输出一次y咯
while (1) { for (volatile int i = 0; i < 10000000; i++) ; yield(); }
在上下文切换中其实也用到了上面的流程,只不过是有A B两个进程,在自陷的时候把指针从A指向B,在从B指向A罢了~。这只是个笼统的描述,根据讲义来说,切换进程AB的基本原理就是:
- 在进程A的运行过程中触发系统调用,自陷后进入内核,根据__am_asm_trap()的代码,A的上下文结构(Context)会被高存到A的栈上,在系统调用处理完毕后,在恢复到原来的内容。
- 如果在A的系统调用结束后,将栈指针切换到另一个进程B的栈上,那么接下来的操作就会恢复B的上下文结构(B保存的栈内容),于是从__am_asm_trap()返回后,我们已经在运行进程B了。
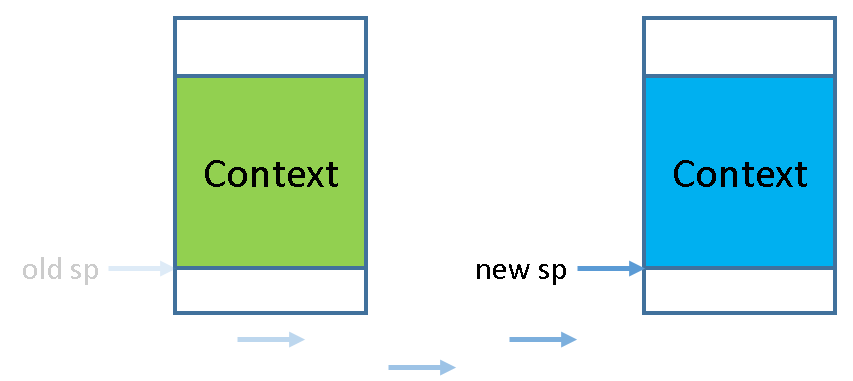
可以从上图可知本质上就是栈指针的切换,那么问题是我们怎么找到别的进程的上下文结构呢?栈指针那么大,每次保存上下文结构的时候都不是固定的,这时候需要用到一个进程控制块
typedef union { uint8_t stack[STACK_SIZE]; struct { Context *cp; }; } PCB;
在上下文切换的时候就只需要把PCB中的cp指针返回给CTE的__am_irq_handle()函数即可。那么我们还需要一些操作来切换进程并运行起来。这里我们用的是kcontext
Context* kcontext(Area kstack, void (*entry)(void *), void *arg);
其中kstack是栈的范围, entry是内核线程的入口, arg则是内核线程的参数. 此外, kcontext()要求内核线程不能从entry返回, 否则其行为是未定义的. 你需要在kstack的底部创建一个以entry为入口的上下文结构, 然后返回这一结构的指针.
我们要记住kcontext的目的是什么,是切换进程并运行起来呀。我们可以先看下native如何实现的,在根据kcontext函数目的,讲义提示很简单就写出来了。
所以到目前为止的流程是:
- main函数初始化cte,回调函数schedule,同时利用kcontext为两个任务创建上下文,
- main函数中的yield触发异常进入__am_asm_trap(),
- __am_asm_trap()保存当前上下文并调用__am_irq_handle()
- __am_irq_handle()中执行回调函数 scheldule切换任务,返回了下个任务的上下文
static Context *schedule(Event ev, Context *prev) { current->cp = prev; current = (current == &pcb[0] ? &pcb[1] : &pcb[0]); return current->cp; } - __am_asm_trap()恢复新切换的上下文并返回任务函数f


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界