


常数,变量和运算
一、常数
int f() { return 0x123; /* 291 */ } int g() { return -1; } int h() { return 0x1234; /* 4660 */ } int i() { return 0xbb8; /* 3000 */ }
在C中看这些常数如何被装入计算机中,首先看0x123,十进制表示为291,正好可以被addi的立即数表示,反汇编结果如下:

而return -1也是如此,1也可以用立即数表示,0xfff表示-1,可以通过一条addi指令表示出来。

0x1234超过12位立即数表示范围了。所以通过lui和addi一起来操作。lui装入0x1,放在高20为,然后再用addi装载剩余的234,

0xbb8也是要分成前后两端分别装入。这里要注意,我们的addi立即数并没办法满足0xbb8的大小,而lui的0x1(4096)又大于0xbb8,所以我们只能进行负数操作,先用lui加载一个高20位的1(4096),而后用addi加载个负数,最后得到0xbb8.

结论:

而对于64位的常数在RV64装入来说:
long long j() { return 0x1234567800000000; } long long k() { return 0x1234567887654321; }
对于long j()来说:
通过li addi
先把先前非0的装载到a0中,a0 = (0x12345678 >> 3)
而后通过后续指令 -> a0 = a0 << 35;

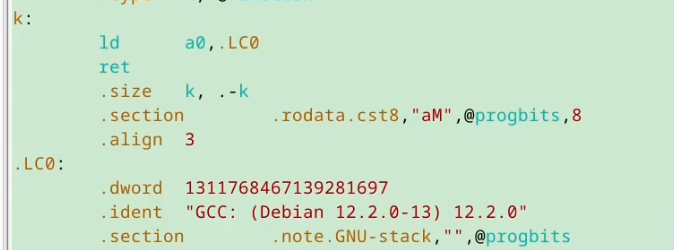
对于long k()来说:
对于一个复杂的64为常数,编译器直接把它放到内存中,其中LC0就是0x123456...的十进制表示。 ld a0,LC0 就是直接加载LC0寄存器的值。

在64位常数在RV32中的装入,只需要用两个32位寄存器联合存放一个64位数据。
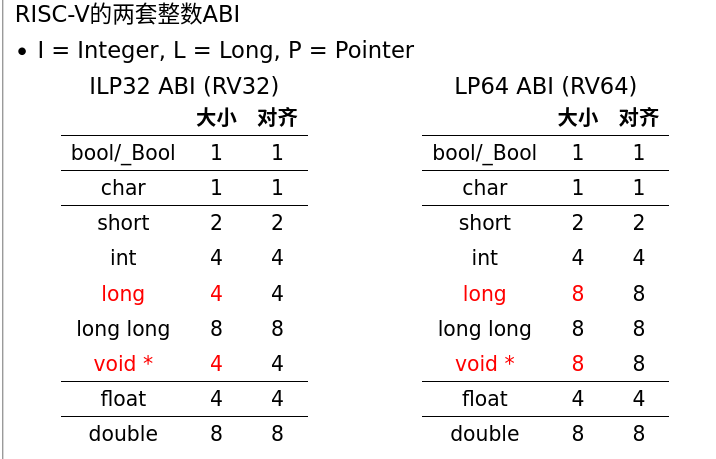
变量的大小与对齐的具体规定实在RISCV的两套整数ABI中,其中RV32是在ILP32 ABI中定义,64位是在LP64 ABI定义的。
在变量分配过程中,把常用的放在寄存器中,寄存器在RV32中只有32个,其中内存的访问速度比较慢,但是容量非常大(8~32G)

所有变量都分配在内存空间,需要访问在读入寄存器。
对于程序的内存分布来说,分为静态数据取,堆区和栈区。
堆和栈是动态区,随着变量的增加而增加。其
其中全局变量分在data区,例如
#include <stdio.h> #include <stdlib.h> int g; void f(int n) { static int sl; int l, *h = malloc(4); printf("n = %2d, &g = %p, &sl = %p, &l = %p, h = %p\n", n, &g, &sl, &l, h); if (n < 5) f(n + 1); } int main() { f(1); printf("===\n"); f(1); return 0; }
中的static int s1;就放在data区,int g也是全部变量,也放在data区。
非静态局部变量,也就是int l,就放在stack区。最后一类是动态变量,需要malloc就是动态分配的,也就是在堆区。

关于RV变量的访问,示例代码如下:
#define def(type, name) \ volatile type name ## _a; \ volatile type name ## _b; \ void f_##name () { name ## _a = name ## _b; } def(_Bool, _Bool) def(char, char) def(signed char, signed_char) def(short, short) def(unsigned short, unsigned_short) def(int, int) def(unsigned int, unsigned_int) def(long, long) def(long long, long_long) def(void *, void_) def(float, float) def(double, double)
rv32gcc -O2 -S a.c rv64gcc -O2 -S a.c
发现不同类型的变量访问指令:
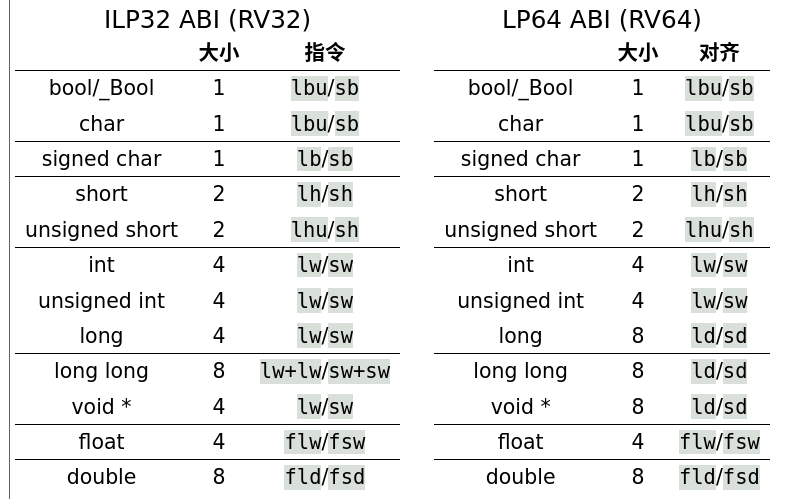
对于变量分配不对齐,会降低访问效率:
不对齐即addr(n) % align(n) != 0, 如int变量分配在地址0x13
硬件支持不对齐访存: 电路更复杂, 且需要两个周期以上 软件支持不对齐访存: 抛异常, 效率很低
运算和指令
对于C运算符,RV指令有对应关系
+, -, *, /, % add, sub, mul, div, rem = mv, 访存指令 &, |, ^ and, or, xor ~ xori r, r, -1 <<, >> sll, srl, sra ! sltiu r, r, 1 <, > slt
而对于编译优化来说,之前我们在编译过程中常用的 -O
-O0 - 每次计算前先从内存读出变量, 每次计算后马上写回内存 -O1 - 开始计算前从内存读出变量, 计算过程在寄存器中进行, 计算全部结束后再写回内存 -O2 - 编译器直接把结果算好了😂
对于有符号数和无符号数来说:
#include <stdint.h> int32_t add1( int32_t a, int32_t b) { return a + b; } uint32_t add2(uint32_t a, uint32_t b) { return a + b; } int32_t cmp1( int32_t a, int32_t b) { return a < b; } int32_t cmp2(uint32_t a, uint32_t b) { return a < b; } int32_t shr1( int32_t a, int32_t b) { return a >> b; } uint32_t shr2(uint32_t a, int32_t b) { return a >> b; } int64_t zext1( int32_t a) { return a; } uint64_t zext2(uint32_t a) { return a; }
add1和add2的反汇编代码一样,结论: 在RISC-V硬件看来, 有符号加法和无符号加法的行为完全一致,可以使用同一个加法器模块进行计算
在比较的行为来说,有符号数为slt,无符号为sltu。
右移 有符号sra,无符号 srl
二、条件分支.
相较于C代码,对于RV指令对应如下

对于循环来说,循环的机器级表示 = 一条往回跳的条件跳转指令
int f(int n) { int y = 0; for (int i = 0; i < n; i ++) { y += i; } return y; }
跳转 = 继续循环
不跳转 = 退出循环
警惕未定义行为
整数加法溢出为未定义行为
例如:
#include <stdio.h> #include <limits.h> int foo(int x) { return (x + 1) > x; } int main() { printf("INT_MAX=%d, cmp: %d%d\n", INT_MAX, (INT_MAX + 1) > INT_MAX, foo(INT_MAX)); return 0; } gcc -w a.c && ./a.out gcc -w -O2 a.c && ./a.out clang -w a.c && ./a.out clang -w -O2 a.c && ./a.out
表面上语义等价的代码, 运行结果却不同
原因: 有符号整数加法溢出是UB
不同机器可能采用不同的有符号数表示方法(原码, 反码, 补码…)
C标准难以统一定义有符号整数加法溢出的确切行为
如32位的原码和反码无法表示-2147483648
于是就UB了, 编译器可以任意处理
而对于移位来说:
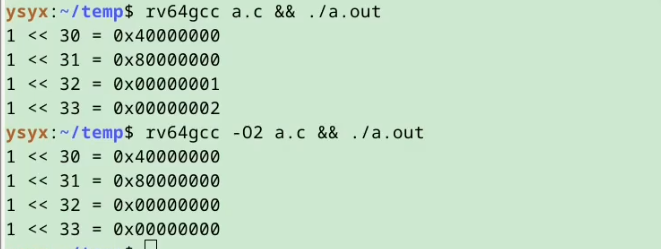
#include <stdio.h> int main() { int i = 30; printf("1 << %d = 0x%08x\n", i, 1 << i); i ++; printf("1 << %d = 0x%08x\n", i, 1 << i); i ++; printf("1 << %d = 0x%08x\n", i, 1 << i); i ++; printf("1 << %d = 0x%08x\n", i, 1 << i); i ++; return 0; }
是否采用-O2编译, 得到不同结果
结果如下:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界