Python爬虫——Python 岗位分析报告
前两篇我们分别爬取了糗事百科和妹子图网站,学习了 Requests, Beautiful Soup 的基本使用。不过前两篇都是从静态 HTML 页面中来筛选出我们需要的信息。这一篇我们来学习下如何来获取 Ajax 请求返回的结果。
欢迎关注公号【智能制造社区】学习更多原创智能制造及编程知识。
Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门(一)——爬取糗百
本篇以拉勾网为例来说明一下如何获取 Ajax 请求内容
本文目标
- 获取 Ajax 请求,解析 JSON 中所需字段
- 数据保存到 Excel 中
- 数据保存到 MySQL, 方便分析
简单分析
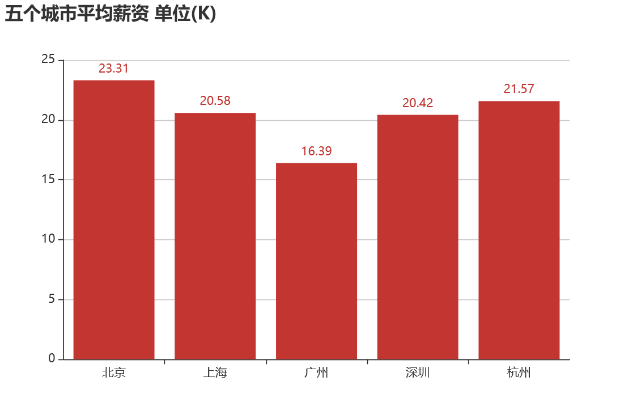
五个城市 Python 岗位平均薪资水平
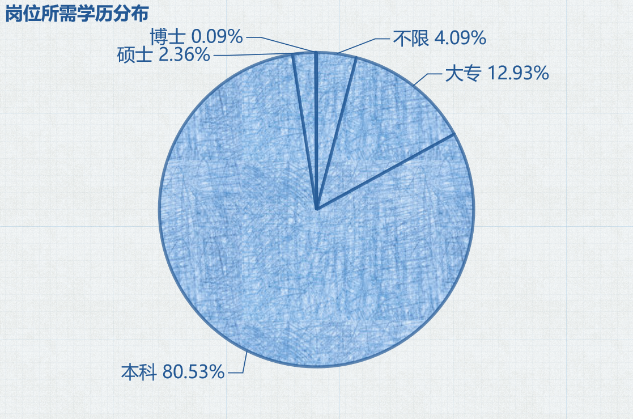
Python 岗位要求学历分布
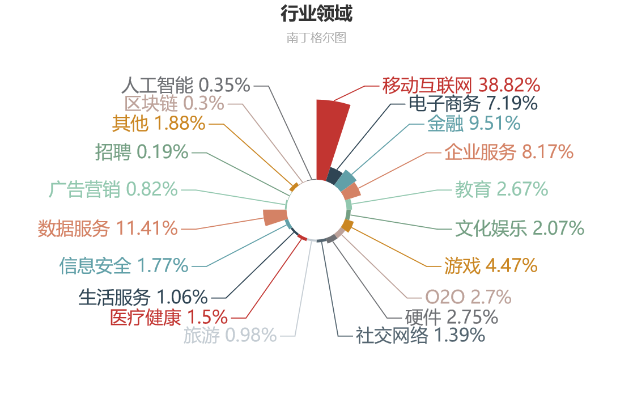
Python 行业领域分布
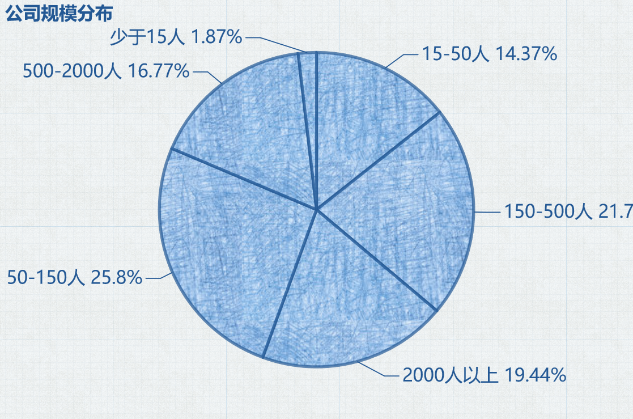
Python 公司规模分布
查看页面结构
我们输入查询条件以 Python 为例,其他条件默认不选,点击查询,就能看到所有 Python 的岗位了,然后我们打开控制台,点击网络标签可以看到如下请求:
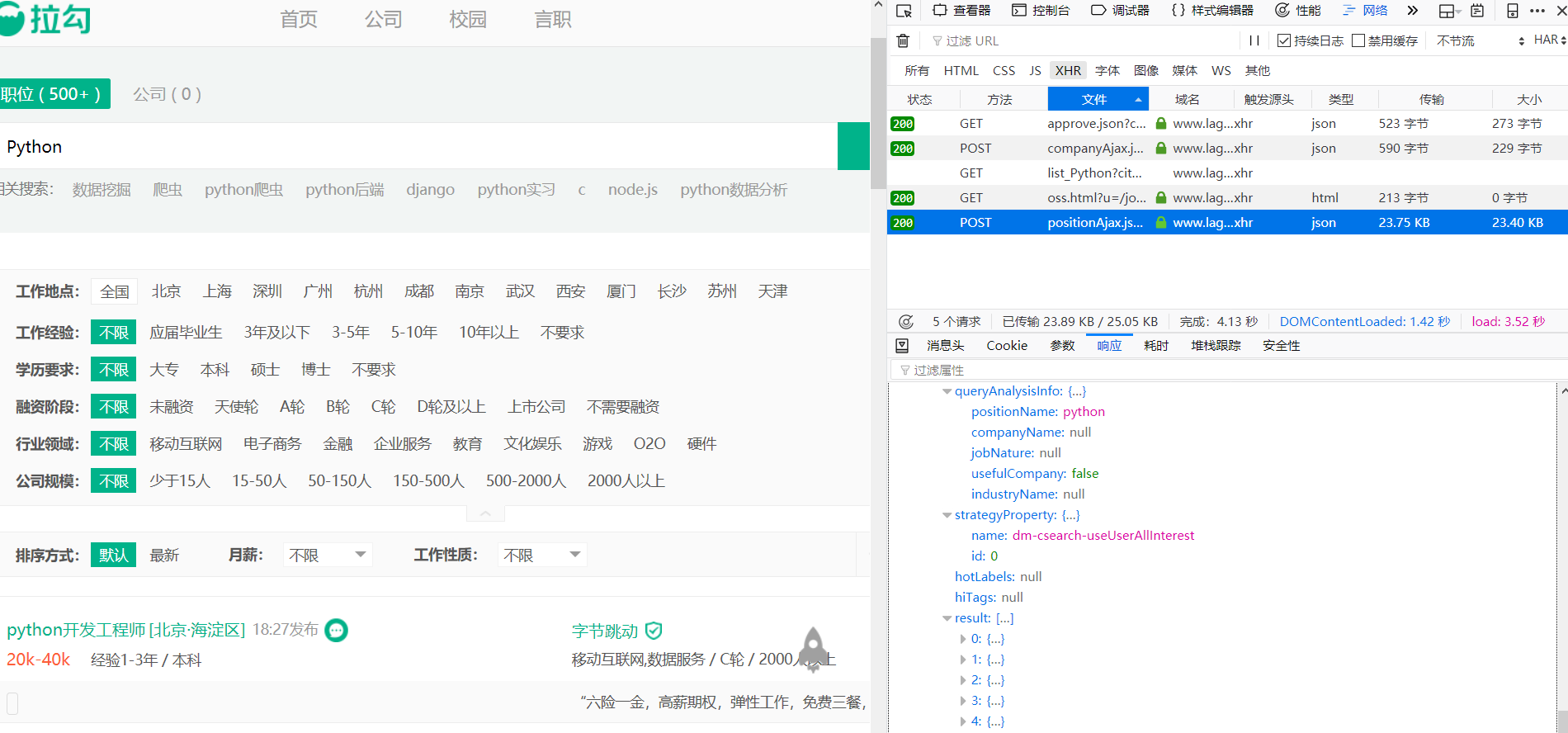
从响应结果来看,这个请求正是我们需要的内容。后面我们直接请求这个地址就好了。从图中可以看出 result 下面就是各个岗位信息。
到这里我们知道了从哪里请求数据,从哪里获取结果。但是 result 列表中只有第一页 15 条数据,其他页面数据怎么获取呢?
分析请求参数
我们点击参数选项卡,如下:
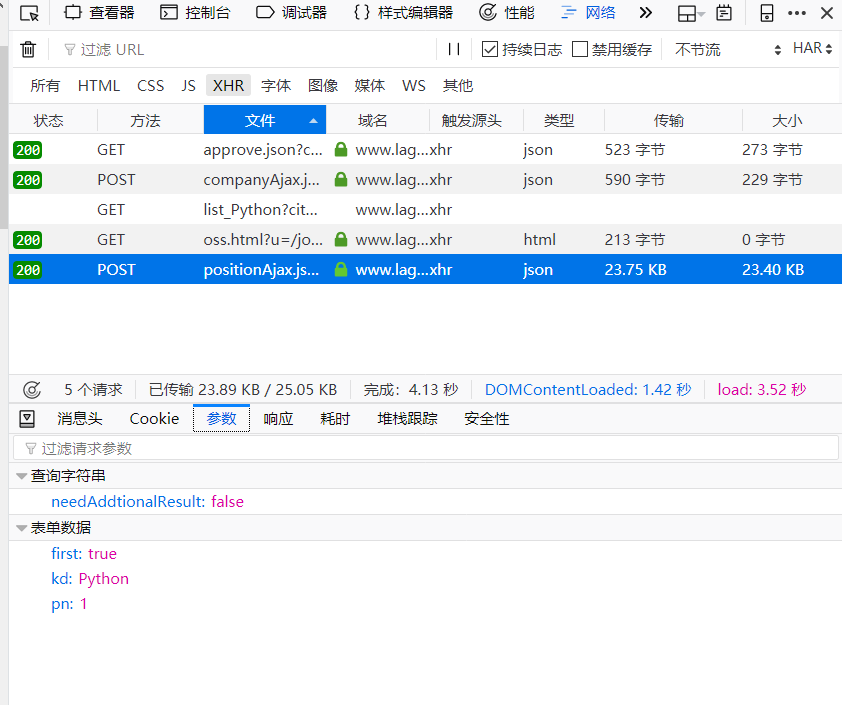
发现提交了三个表单数据,很明显看出来 kd 就是我们搜索的关键词,pn 就是当前页码。first 默认就行了,不用管它。剩下的事情就是构造请求,来下载 30 个页面的数据了。
构造请求,并解析数据
构造请求很简单,我们还是用 requests 库来搞定。首先我们构造出表单数据 data = {'first': 'true', 'pn': page, 'kd': lang_name} 之后用 requests 来请求url地址,解析得到的 Json 数据就算大功告成了。由于拉勾对爬虫限制比较严格,我们需要把浏览器中 headers 字段全部加上,而且把爬虫间隔调大一点,我后面设置的为 10-20s,然后就能正常获取数据了。
import requests
def get_json(url, page, lang_name):
headers = {
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Content-Length': '23',
'Origin': 'https://www.lagou.com',
'X-Anit-Forge-Code': '0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7'
}
data = {'first': 'false', 'pn': page, 'kd': lang_name}
json = requests.post(url, data, headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i.get('companyShortName', '无'))
info.append(i.get('companyFullName', '无'))
info.append(i.get('industryField', '无'))
info.append(i.get('companySize', '无'))
info.append(i.get('salary', '无'))
info.append(i.get('city', '无'))
info.append(i.get('education', '无'))
info_list.append(info)
return info_list
获取所有数据
了解了如何解析数据,剩下的就是连续请求所有页面了,我们构造一个函数来请求所有 30 页的数据。
def main():
lang_name = 'python'
wb = Workbook()
conn = get_conn()
for i in ['北京', '上海', '广州', '深圳', '杭州']:
page = 1
ws1 = wb.active
ws1.title = lang_name
url = 'https://www.lagou.com/jobs/positionAjax.json?city={}&needAddtionalResult=false'.format(i)
while page < 31:
info = get_json(url, page, lang_name)
page += 1
import time
a = random.randint(10, 20)
time.sleep(a)
for row in info:
insert(conn, tuple(row))
ws1.append(row)
conn.close()
wb.save('{}职位信息.xlsx'.format(lang_name))
if __name__ == '__main__':
main()
完整代码
import random
import time
import requests
from openpyxl import Workbook
import pymysql.cursors
def get_conn():
'''建立数据库连接'''
conn = pymysql.connect(host='localhost',
user='root',
password='root',
db='python',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
return conn
def insert(conn, info):
'''数据写入数据库'''
with conn.cursor() as cursor:
sql = "INSERT INTO `python` (`shortname`, `fullname`, `industryfield`, `companySize`, `salary`, `city`, `education`) VALUES (%s, %s, %s, %s, %s, %s, %s)"
cursor.execute(sql, info)
conn.commit()
def get_json(url, page, lang_name):
'''返回当前页面的信息列表'''
headers = {
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Content-Length': '23',
'Origin': 'https://www.lagou.com',
'X-Anit-Forge-Code': '0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7'
}
data = {'first': 'false', 'pn': page, 'kd': lang_name}
json = requests.post(url, data, headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i.get('companyShortName', '无')) # 公司名
info.append(i.get('companyFullName', '无'))
info.append(i.get('industryField', '无')) # 行业领域
info.append(i.get('companySize', '无')) # 公司规模
info.append(i.get('salary', '无')) # 薪资
info.append(i.get('city', '无'))
info.append(i.get('education', '无')) # 学历
info_list.append(info)
return info_list # 返回列表
def main():
lang_name = 'python'
wb = Workbook() # 打开 excel 工作簿
conn = get_conn() # 建立数据库连接 不存数据库 注释此行
for i in ['北京', '上海', '广州', '深圳', '杭州']: # 五个城市
page = 1
ws1 = wb.active
ws1.title = lang_name
url = 'https://www.lagou.com/jobs/positionAjax.json?city={}&needAddtionalResult=false'.format(i)
while page < 31: # 每个城市30页信息
info = get_json(url, page, lang_name)
page += 1
time.sleep(random.randint(10, 20))
for row in info:
insert(conn, tuple(row)) # 插入数据库,若不想存入 注释此行
ws1.append(row)
conn.close() # 关闭数据库连接,不存数据库 注释此行
wb.save('{}职位信息.xlsx'.format(lang_name))
if __name__ == '__main__':
main()
GitHub 地址:https://github.com/injetlee/Python/tree/master/爬虫集合
如果你想要爬虫获取的岗位信息,请关注公号【智能制造专栏】后台留言发送 "python岗位"。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号