Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门
听说你写代码没动力?本文就给你动力,爬取妹子图。如果这也没动力那就没救了。
GitHub 地址: https://github.com/injetlee/Python/blob/master/%E7%88%AC%E8%99%AB%E9%9B%86%E5%90%88/meizitu.py
公众号:【智能制造社区】。欢迎关注,分享智能制造与编程那些事。
爬虫成果
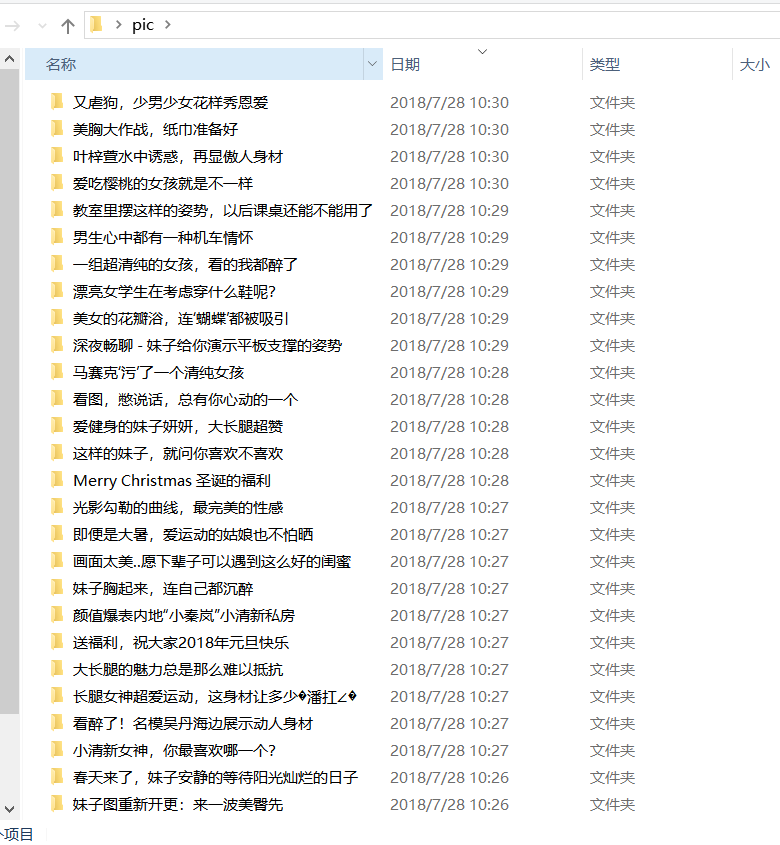
当你运行代码后,文件夹就会越来越多,如果爬完的话会有2000多个文件夹,20000多张图片。不过会很耗时间,可以在最后的代码设置爬取页码范围。
本文目标
- 熟悉 Requests 库,Beautiful Soup 库
- 熟悉多线程爬取
- 送福利,妹子图
网站结构
我们从 http://meizitu.com/a/more_1.html 这个链接进去,界面如图一所示
图一:
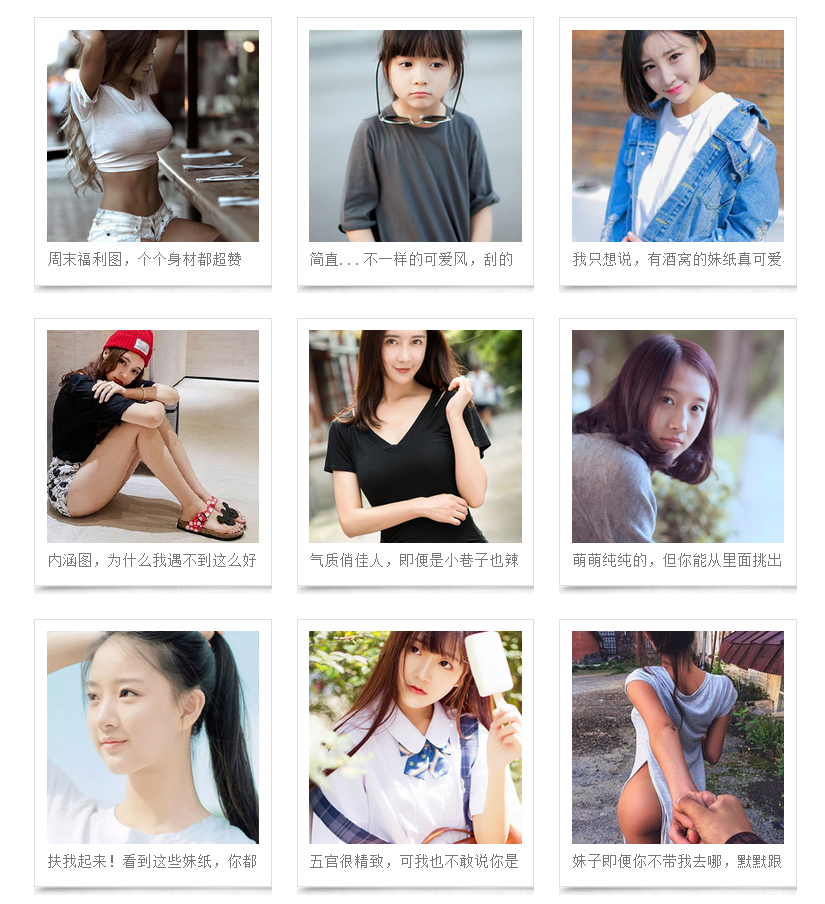
可以看到是一组一组的套图,点击任何一组图片会进入到详情界面,如图二所示
图二:

可以看到图片是依次排开的,一般会有十张左右的图片。
实现思路
看了界面的结构,那么我们的思路就有了。
- 构造 url 链接,去请求图一所示的套图列表界面,拿到每一个页面中的套图列表。
- 分别进入每个套图中去,下载相应的图片。
代码说明
-
下载界面的函数,利用 Requests 很方便实现。
def download_page(url): ''' 用于下载页面 ''' headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"} r = requests.get(url, headers=headers) r.encoding = 'gb2312' return r.text -
获取图一所示的所有套图列表,函数中 link 表示套图的链接,text表示套图的名字
def get_pic_list(html): ''' 获取每个页面的套图列表,之后循环调用get_pic函数获取图片 ''' soup = BeautifulSoup(html, 'html.parser') pic_list = soup.find_all('li', class_='wp-item') for i in pic_list: a_tag = i.find('h3', class_='tit').find('a') link = a_tag.get('href') # 套图链接 text = a_tag.get_text() # 套图名字 get_pic(link, text) -
传入上一步中获取到的套图链接及套图名字,获取每组套图里面的图片,并保存,我在代码中注释了。
def get_pic(link, text): ''' 获取当前页面的图片,并保存 ''' html = download_page(link) # 下载界面 soup = BeautifulSoup(html, 'html.parser') pic_list = soup.find('div', id="picture").find_all('img') # 找到界面所有图片 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"} create_dir('pic/{}'.format(text)) for i in pic_list: pic_link = i.get('src') # 拿到图片的具体 url r = requests.get(pic_link, headers=headers) # 下载图片,之后保存到文件 with open('pic/{}/{}'.format(text, pic_link.split('/')[-1]), 'wb') as f: f.write(r.content) time.sleep(1)
完整代码
完整代码如下,包括了创建文件夹,利用多线程爬取,我设置的是5个线程,可以根据自己机器自己来设置一下。
import requests
import os
import time
import threading
from bs4 import BeautifulSoup
def download_page(url):
'''
用于下载页面
'''
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"}
r = requests.get(url, headers=headers)
r.encoding = 'gb2312'
return r.text
def get_pic_list(html):
'''
获取每个页面的套图列表,之后循环调用get_pic函数获取图片
'''
soup = BeautifulSoup(html, 'html.parser')
pic_list = soup.find_all('li', class_='wp-item')
for i in pic_list:
a_tag = i.find('h3', class_='tit').find('a')
link = a_tag.get('href')
text = a_tag.get_text()
get_pic(link, text)
def get_pic(link, text):
'''
获取当前页面的图片,并保存
'''
html = download_page(link) # 下载界面
soup = BeautifulSoup(html, 'html.parser')
pic_list = soup.find('div', id="picture").find_all('img') # 找到界面所有图片
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"}
create_dir('pic/{}'.format(text))
for i in pic_list:
pic_link = i.get('src') # 拿到图片的具体 url
r = requests.get(pic_link, headers=headers) # 下载图片,之后保存到文件
with open('pic/{}/{}'.format(text, pic_link.split('/')[-1]), 'wb') as f:
f.write(r.content)
time.sleep(1) # 休息一下,不要给网站太大压力,避免被封
def create_dir(name):
if not os.path.exists(name):
os.makedirs(name)
def execute(url):
page_html = download_page(url)
get_pic_list(page_html)
def main():
create_dir('pic')
queue = [i for i in range(1, 72)] # 构造 url 链接 页码。
threads = []
while len(queue) > 0:
for thread in threads:
if not thread.is_alive():
threads.remove(thread)
while len(threads) < 5 and len(queue) > 0: # 最大线程数设置为 5
cur_page = queue.pop(0)
url = 'http://meizitu.com/a/more_{}.html'.format(cur_page)
thread = threading.Thread(target=execute, args=(url,))
thread.setDaemon(True)
thread.start()
print('{}正在下载{}页'.format(threading.current_thread().name, cur_page))
threads.append(thread)
if __name__ == '__main__':
main()
好了,之后运行,我们的爬虫就会孜孜不倦的为我们下载漂亮妹子啦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号