Snowflake雪花算法
学习地址:https://www.bilibili.com/video/BV18E411x7eT?p=149
源码分享:https://github.com/mobiwusihuan288/SpringCloud2020
集群高并发情况下如何保证分布式唯一全局ID生成?
唯一ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识,如在美团点评的金融、支付、餐饮、酒店;猫眼电影等产品的系统中数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。
ID生成规则部分硬性要求
全局唯一
不能出现重复的ID号,既然是唯一标识,这是最基本的要求
趋势递增
在MySQL的InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用Btree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
单调递增
保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
信息安全
如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,需要ID无规则不规则,让竞争对手不好猜。
含时间戳
这样就能够在开发中快速了解这个分布式ID的生成时间
分布式系统中,有一些需要使用全局唯一ID的场景,生成ID的基本要求
-
在分布式的环境下必须全局且唯一。
-
一般都需要单调递增,因为一般唯一ID都会存到数据库,而Innodb的特性就是将内容存储在主键索引树上的叶子节点,而且是从左往右,递增的,所以考虑到数据库性能,一般生成的ID也最好是单调递增。为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID
般是无序的 -
可能还会需要无规则,因为如果使用唯一ID作为订单号这种,为了不然别人知道一天的订单量是多少,就需要这个规则。
ID号生成系统的可用性要求
高可用
发一个获取分布式ID的请求,服务器就要保证99.999%的情况下给我创建一个唯一分布式ID。
低延迟
发一个获取分布式ID的请求,服务器就要快,极速。
高QPS
假如并发一口气10万个创建分布式ID请求同时杀过来,服务器要顶的住且一下子成功创建10万个分布式ID。
UUID
UUID(Universally Unique ldentifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:
550e8400-e29b-41d4-a716-446655440000
性能非常高:本地生成,没有网络消耗
如果只考虑唯一性,OK,但是入数据库性能差
为什么无序的UUID会导致入库性能变差呢?
-
无序,无法预测他的生成顺序,不能生成递增有序的数字。
首先分布式ID一般都会作为主键,但是安装MySQL官方推荐主键要尽量越短越好,UUID每-一个都很长,所以不是很推荐。 -
主键,ID作为主键时在特定的环境会存在一-些问题。
比如做DB主键的场景下,UUID就非常不适用MySQL官方有明确的建议主键要尽量越短越好36个字符长度的UUID不符合要求.

-
索引,B+树索引的分裂
既然分布式ID是主键,然后主键是包含索引的,然后MySQL的索引是通过b+树来实现的,每一次新的UUID数据的插入,为了查询的优化,都会对索引底层的b+树进行修改,因为UUID数据是无序的,所以每一次UUID数据的插入都会对主键底层的b+树进行很大的修改,这一点很不好。插入完全无序,不但会导致一些中间节点产生分裂,也会白白创造出很多不饱和的节点,这样大大降低了数据库插入的性能。
数据库自增主键
单机
在分布式里面,数据库的自增ID机制的主要原理是:数据库自增ID和MySQL数据库的replace into实现的。
这里的replace into跟insert功能类似,不同点在于:replace into 首先尝试插入数据列表中,如果发现表中已经有此行数据(根据主键或唯一 索引判断)则先删除,再插入。否则直接插入新数据。
REPLACEINTO的含义是插入一条记录,如果表中唯一索引的值遇到冲突,则替换老数据。
CREATE TABLE t_test(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
stub CHAR(1) NOT NULL DEFAULT '',
UNIQUE KEY stub (stub)
)
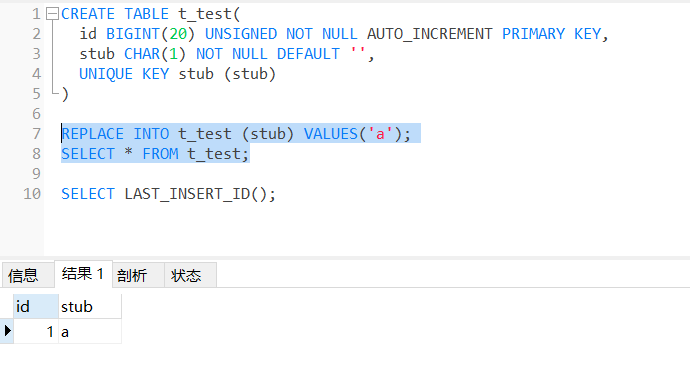
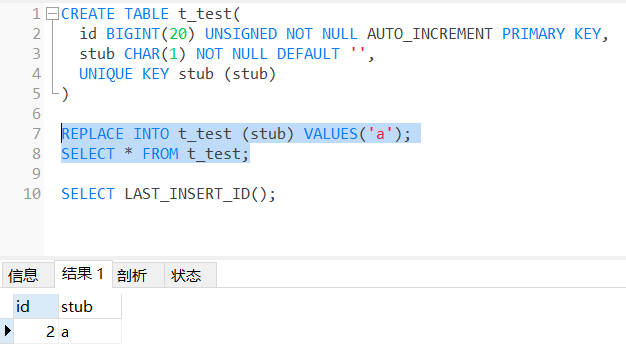
REPLACE INTO t_test (stub) VALUES('a');
SELECT * FROM t_test;
SELECT LAST_INSERT_ID();
集群分布式
那数据库自增ID机制适合作分布式ID吗?答案是不太适合
-
系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台机器发号是1,2,3,4,5 (步长是1),这个时候需要扩容机器一台。 可以这样做:把第二台机器的初始值设置得比第一台超过很多,貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
-
数据库压力还是很大,每次获取ID都得读写一次数据库,非常影响性能,不符合分布式ID里面的延迟低和要高QPS的规则(在高并发下,如果都去数据库里面获取id,那是非常影响性能的)
基于Redis生成全局ID策略
因为Redis是单线的天生保证原子性,可以使用原子操作INCR和INCRBY来实现。
集群分布式
注意:在Redis集群情况下,同样和MySQL一样需要设置不同的增长步长,同时key一定要设置有效期
可以使用Redis集群来获取更高的吞吐量。
假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。
各个Redis生成的ID为: .
A: 1,6,11,16,21
B: 2,7,12,17,22
C: 3,8,13,18,23
D: 4,9,14,19,24
E: 5,10,15,20,25
Snowflake
源码地址:https://github.com/twitter-archive/snowflake
Twitter的分布式自增ID算法snowflake
而Twitter的Snowflake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra(由Facebook开发一套开源分布式NoSQL数据库系统)因为Cassandra没有顺序ID生成机制,所以开发了这样一套全局唯一ID生成服务。
Twitter的分布式雪花算法SnowFlake,经测试Snowflake每秒能够产生26万个自增可排序的ID
-
Twitter的SnowFlake 生成ID能够按照时间有序生成
-
SnowFlake 算法生成ID的结果是一个64bit大小的整数, 为一个Long 型(转换成字符串后长度最多19)。
-
分布式系统内不会产生ID碰撞(由datacenter和workerld作区分)并且效率较高。
结构

号段解析:
1bit
不用,因为二进制中最高位是符号位,1表示负数, 0表示正数。
生成的ID一般都是用整数,所以最高位固定为0。
41bit
时间戳,用来记录时间戳,亳秒级。
41位可以表示2^{41}-1个数字,
如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是: 0至2^{41}-1, 减1是因为可表示的数值范围是从0开始算的,而不是1。
也就是说41位可以表示2*<41}-1个毫秒的值,转化成单位年则是(2^{41}-1)/(1000 * 60 * 60 * 24 *365)= 69年
10bit
工作机器id,用来记录工作机器id。
可以部署在2^{10} = 1024个节点,包括5位datacenterld和5位workerld
5位(bit) 可以表示的最大正整数是2^{5}-1 =31,即可以用0、1、2、3、... 31这32个数字,来表示不同的datecenterld或workerld。
12bit
序列号,序列号,用来记录同亳秒内产生的不同id.
12位(bit) 可以表示的最大正整数是2^{12}-1 = 4095, 即可以用0、1、2、3、... 4094这4095个数字,来表示同一机器同一时间截(亳秒)内产生的4095个ID序号。
优点
-
亳秒数在高位,自增序列在低位,整个ID都是趋势递增的。
-
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
-
可以根据自身业务特性分配bit位,非常灵活。
缺点
-
依赖机器时钟,如果机器时钟回拨,会导致重复ID生成
-
在单机上是递增的,但是由于设计到分布式环境,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况(此缺点可以认为无所谓,一般分布式ID只要求趋势递增,并不会严格要求递增,90%的需求都只要求趋势递增)
Snowflake实践:Hutool
hutool:https://github.com/looly/hutool
cloud-consumer-order80
重点依赖(cloud-api-commons已导入)
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.1.0</version>
</dependency>
Util
@Slf4j
@Component
public class IdGeneratorSnowflake {
private long workerId = 0;
private long datacenterId = 1;
private Snowflake snowflake = IdUtil.createSnowflake(workerId, datacenterId);
@PostConstruct
public void init() {
try {
workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());
log.info("当前机器的workerId:{}", workerId);
} catch (Exception e) {
e.printStackTrace();
log.warn("当前机器的workerId获取失败", e);
workerId = NetUtil.getLocalhostStr().hashCode();
}
}
public synchronized long snowflake() {
return snowflake.nextId();
}
public synchronized long snowflake(long workerId, long datacenterId) {
Snowflake snowflake = IdUtil.createSnowflake(workerId, datacenterId);
return snowflake.nextId();
}
}
Service
@Service
public class OrderService {
@Autowired
private IdGeneratorSnowflake idGenerator;
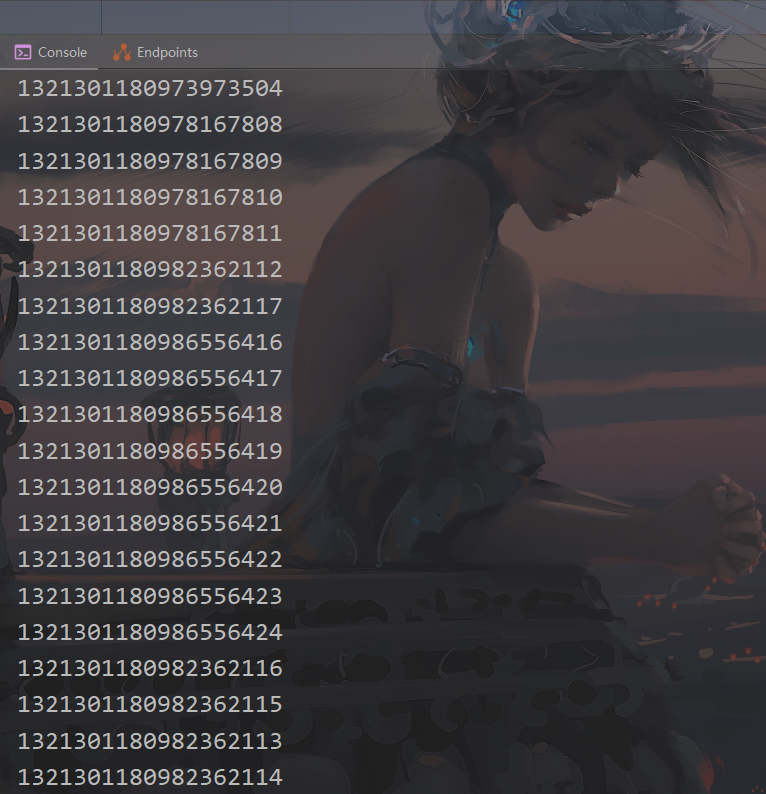
public String getIDBySnowFlake() {
ExecutorService threadPool = Executors.newFixedThreadPool(5);
for (int i = 0; i < 20; i++) {
threadPool.submit(() -> {
System.out.println(idGenerator.snowflake());
});
}
threadPool.shutdown();
return "hello snowflake";
}
}
Controller
@RestController
@Slf4j
public class OrderController {
@Autowired
private OrderService orderService;
@RequestMapping("/snowflake")
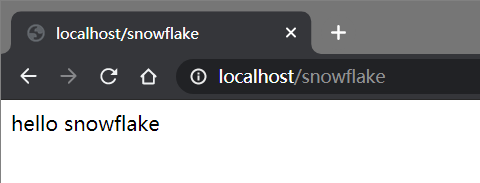
public String index() {
return orderService.getIDBySnowFlake();
}
}
测试
http://localhost/snowflake

 浙公网安备 33010602011771号
浙公网安备 33010602011771号