会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
initial_h
https://github.com/initial-h
博客园
首页
新随笔
管理
上一页
1
2
3
4
5
6
···
12
下一页
2023年7月31日
Experience Replay Optimization
摘要: 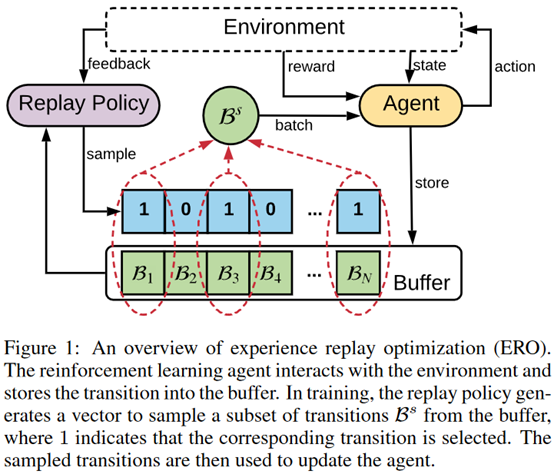 **发表时间:**2019 (IJCAI 2019) **文章要点:**这篇文章提出experience rep
阅读全文
posted @ 2023-07-31 09:05 initial_h
阅读(73)
评论(0)
推荐(0)
2023年7月29日
Improved deep reinforcement learning for robotics through distribution-based experience retention
摘要:  **发表时间:**2016(IROS 2016) **文章要点:**这篇文章提出了experience repl
阅读全文
posted @ 2023-07-29 08:25 initial_h
阅读(40)
评论(0)
推荐(0)
2023年7月27日
The importance of experience replay database composition in deep reinforcement learning
摘要:  **发表时间:**2015(Deep Reinforcement Learning Workshop, NIPS
阅读全文
posted @ 2023-07-27 11:12 initial_h
阅读(41)
评论(0)
推荐(0)
2023年7月25日
Selective Experience Replay for Lifelong Learning
摘要: 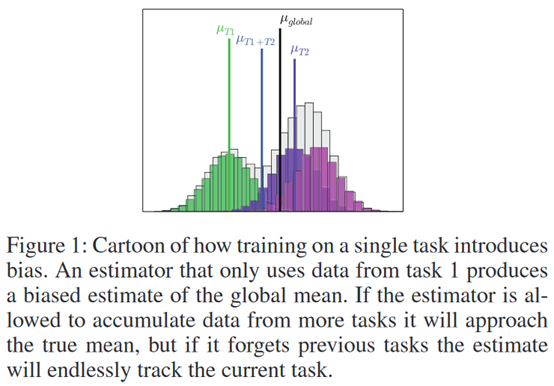 **发表时间:**2018(AAAI 2018) **文章要点:**这篇文章想解决强化学习在学多个任务时候的遗忘
阅读全文
posted @ 2023-07-25 23:47 initial_h
阅读(115)
评论(0)
推荐(0)
2023年7月17日
Reverb: A Framework For Experience Replay
摘要: 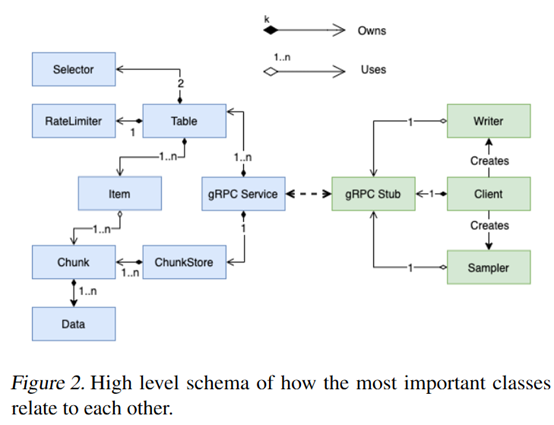 **发表时间:**2021 **文章要点:**这篇文章主要是设计了一个用来做experience replay的框
阅读全文
posted @ 2023-07-17 10:24 initial_h
阅读(50)
评论(0)
推荐(0)
2023年7月13日
TOPOLOGICAL EXPERIENCE REPLAY
摘要: 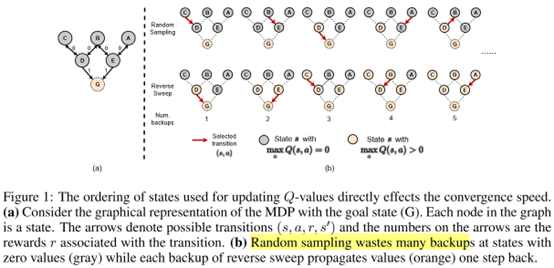 **发表时间:**2022(ICLR 2022) **文章要点:**这篇文章指出根据TD error来采样是低效的
阅读全文
posted @ 2023-07-13 23:30 initial_h
阅读(76)
评论(0)
推荐(0)
2023年7月10日
Regret Minimization Experience Replay in Off-Policy Reinforcement Learning
摘要: **发表时间:**2021 (NeurIPS 2021) **文章要点:**理论表明,更高的hindsight TD error,更加on policy,以及更准的target Q value的样本应该有更高的采样权重(The theory suggests that data with highe
阅读全文
posted @ 2023-07-10 12:53 initial_h
阅读(161)
评论(0)
推荐(0)
2023年7月7日
Effective Diversity in Population-Based Reinforcement Learning
摘要: 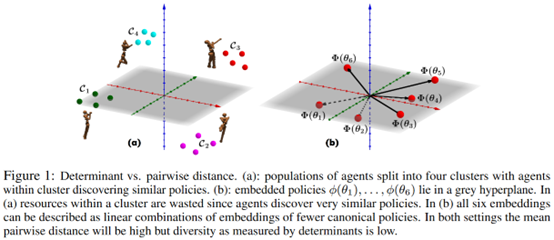 **发表时间:**2020 (NeurIPS 2020) **文章要点:**这篇文章提出了Diversity v
阅读全文
posted @ 2023-07-07 08:46 initial_h
阅读(64)
评论(0)
推荐(0)
2023年7月3日
MODEL-AUGMENTED PRIORITIZED EXPERIENCE REPLAY
摘要: 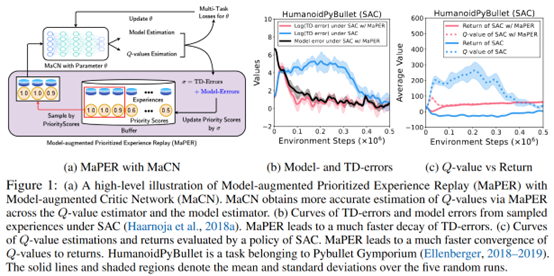 **发表时间:**2022(ICLR 2022) **文章要点:**这篇文章想说Q网络通常会存在under- or
阅读全文
posted @ 2023-07-03 11:25 initial_h
阅读(77)
评论(0)
推荐(0)
2023年7月2日
Remember and Forget for Experience Replay
摘要: **发表时间:**2019(ICML 2019) **文章要点:**这篇文章想说如果replay的经验和当前的policy差别很大的话,对更新是有害的。然后提出了Remember and Forget Experience Replay (ReF-ER)算法,(1)跳过那些和当前policy差别很大
阅读全文
posted @ 2023-07-02 12:15 initial_h
阅读(51)
评论(0)
推荐(0)
2023年6月25日
LEARNING TO SAMPLE WITH LOCAL AND GLOBAL CONTEXTS FROM EXPERIENCE REPLAY BUFFERS
摘要:  **发表时间:**2021(ICLR 2021) **文章要点:**这篇文章想说,之前的experience r
阅读全文
posted @ 2023-06-25 11:57 initial_h
阅读(58)
评论(0)
推荐(0)
2023年6月23日
Prioritized Sequence Experience Replay
摘要: 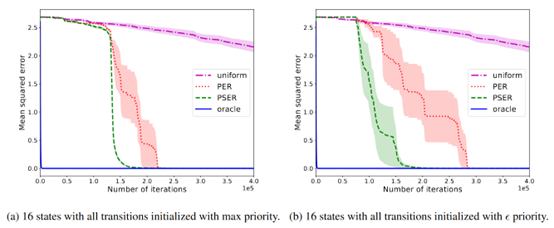 **发表时间:**2020 **文章要点:**这篇文章提出了Prioritized Sequence Exper
阅读全文
posted @ 2023-06-23 12:34 initial_h
阅读(128)
评论(0)
推荐(0)
2023年6月9日
Revisiting Fundamentals of Experience Replay
摘要: 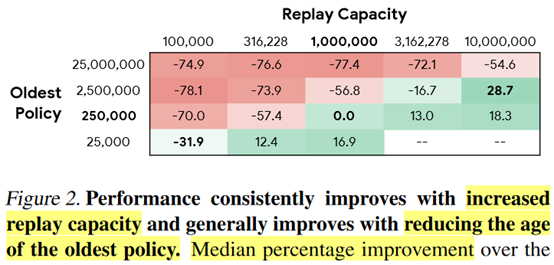 **发表时间:**2020(ICML2020) **文章要点:**这篇文章研究了experience repla
阅读全文
posted @ 2023-06-09 12:22 initial_h
阅读(96)
评论(0)
推荐(0)
2023年6月4日
Revisiting Prioritized Experience Replay: A Value Perspective
摘要: 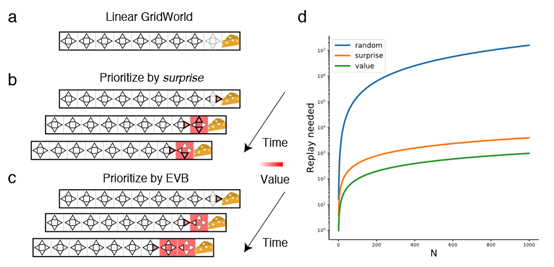 **发表时间:**2021 **文章要点:**这篇文章想说Prioritized experience repla
阅读全文
posted @ 2023-06-04 13:12 initial_h
阅读(37)
评论(0)
推荐(0)
2023年6月2日
Muesli: Combining Improvements in Policy Optimization
摘要: 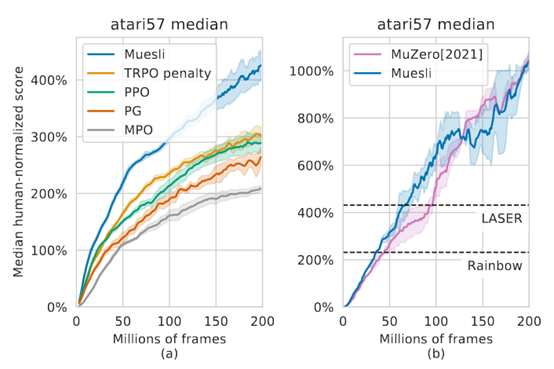 **发表时间:**2021(ICML 2021) **文章要点:**这篇文章提出一个更新policy的方式,结合
阅读全文
posted @ 2023-06-02 22:36 initial_h
阅读(42)
评论(0)
推荐(0)
上一页
1
2
3
4
5
6
···
12
下一页
公告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号